Train with Amazon SageMaker
Overview
Amazon SageMaker makes it easy to train machine learning (ML) models by providing everything you need to tune and debug models and execute training experiments.
Features
Experiment management and tracking
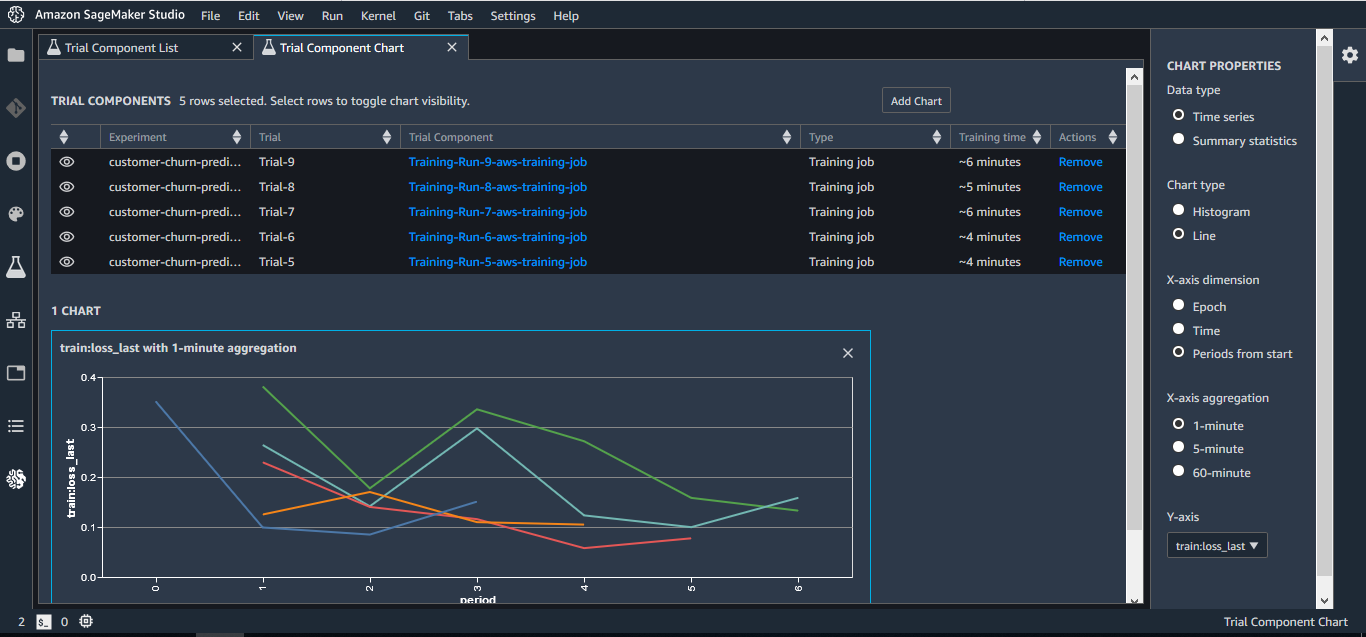
Machine learning is an iterative process based on continuous experimentation, for instance, trying new learning algorithms or tweaking algorithm’s hyperparameters, all the while observing the impact of such incremental changes on model performance and accuracy. Over time this explosion of data makes it harder to track the best performing models, observations and lessons learned during the course of experimentation, and also the exact ingredients and recipe that went into creating those models in the first place.
Amazon SageMaker Experiments helps you track, evaluate, and organize training experiments in an easy and scalable manner. SageMaker Experiments comes within the Amazon SageMaker Studio as well as a Python SDK with deep Jupyter integrations.
With Amazon SageMaker Experiments, you can organize thousands of training experiments, log experiment artifacts such as datasets, hyperparameters, and metrics, and reproduce experiments. Because SageMaker Experiments integrates with SageMaker Studio, you can visualize models and quickly and easily evaluate the best models. You can also record and maintain a running log of notes and comments as the experiments progress, and easily click-and-share their experiments across team members. SageMaker Experiments also preserves the full lineage of the experiments, so if a model begins to deviate from its intended outcome, you can go back in time and inspect its artifacts.
Analyze and debug with complete insights
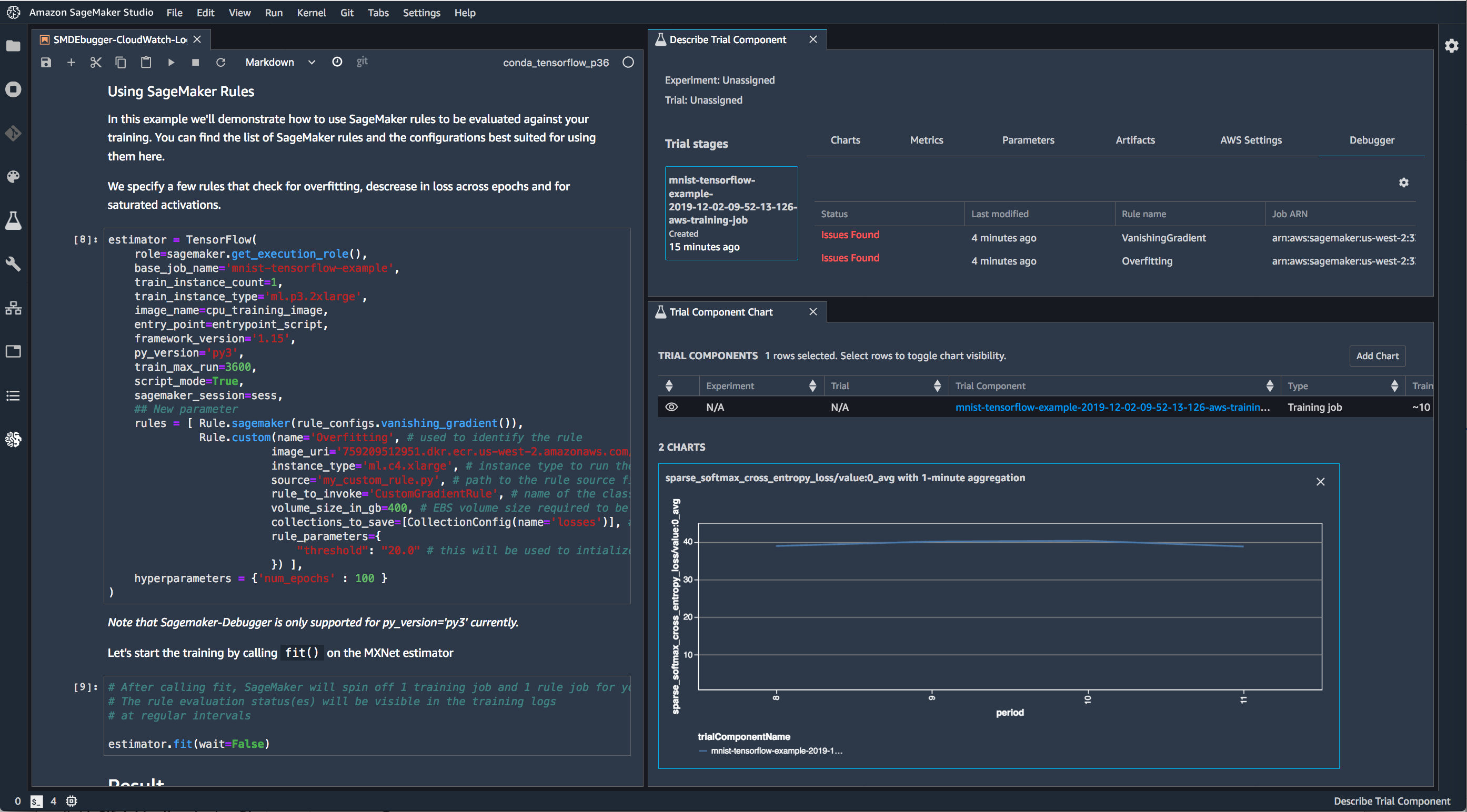
It is challenging to get complete insight and visibility into the ML training process. There is no easy way to ensure that your model is progressively learning the correct values for its parameters. For example, when training a computer vision model using a convolutional neural network, you might have to run the training job for hours. During this time, there is no visibility into how the different ML model parameters are affecting the model training and whether the training process is yielding desired results.
Amazon SageMaker Debugger provides full visibility into the training process. SageMaker Debugger makes the inspection easy by providing a visual interface for developers to analyze the debug data, and also by providing visual indicators about potential anomalies in the training process.
SageMaker Debugger automatically detects and alerts you to commonly occurring errors - such as gradient values getting too large or too small. You can also use the Debugger SDK to automatically detect new classes of model-specific errors, or interactively analyze training runs in a SageMaker Notebook. As a result, debugging effort for machine learning models can be reduced from days to minutes. Data collected by SageMaker Debugger remains in your own account, enabling its use for the most privacy-sensitive applications.
SageMaker Debugger produces real-time performance metrics of your models. These include training and validation loss (which represents the error of the model, should be as low as possible), confusion matrices (for classification models, this represents the false positive and negative predictions and how they change during training), and learning gradients (reviewing learning curves of models during training are used to diagnose problems with learning, such as an underfit or overfit model, as well as whether the training and validation datasets are suitably representative.) These metrics can be viewed and visualized in notebooks inside Amazon SageMaker Studio.
SageMaker Debugger will also provide warnings and remediation advice when common training problems are detected. For example, if your model has learned all it can from the data and is not improving, but is still being trained (which takes time and costs money), SageMaker Debugger will help identify this early so that you can terminate training. It can also identify common data validation issues, such as if your network weights are consistently being set to zero, as well as identify if your model is starting to overfit the data.
One-click training
Training models is easy with Amazon SageMaker. When you’re ready to train in SageMaker, simply specify the location of your data in Amazon S3, and indicate the type and quantity of SageMaker ML instances you need, and get started with a single click. SageMaker sets up a distributed compute cluster, performs the training, outputs the result to Amazon S3, and tears down the cluster when complete.
When you specify the location of your data in Amazon S3, SageMaker will take your algorithm and run it on a training cluster isolated within its own software-defined network, configured to your needs. When you choose the instance type including Amazon EC2 P3dn, the most powerful GPU based instance in the cloud, SageMaker will create your cluster in an auto-scaling group. SageMaker will also attach EBS volumes to each node, set up the data pipelines, and start training with your TensorFlow, MXNet, Pytorch, Chainer or your framework script, built-in or custom algorithm. Once finished, the results are stored in S3 and the cluster is automatically torn down.
To make it easy to conduct training at scale, we’ve optimized how training data streams from Amazon S3. Through the API, you can specify if you’d like all of the data to be sent to each node in the cluster, or if you’d like SageMaker to manage the distribution of data across the nodes depending on the needs of your algorithm. Combined with the built-in algorithms, the scalability of training that’s possible with Amazon SageMaker can dramatically reduce the time and cost of training runs.
Automatic Model Tuning
Amazon SageMaker can automatically tune your model by adjusting thousands of different combinations of algorithm parameters to arrive at the most accurate predictions the model is capable of producing.
When you’re tuning your model to be more accurate, you have two big levers to pull, modifying the data inputs you provide the model (for example, taking the log of a number), and adjusting the parameters that define model behavior. These are called hyperparameters, and finding the right values can be difficult. Typically, you’ll start with something random and iterate through adjustments as you begin to see what effect the changes have. It can be a long cycle depending on how many hyperparameters your model has.
SageMaker makes this easy by offering Automatic Model Tuning as an option during training. Automatic model tuning uses machine learning to quickly tune your model to be as accurate as possible. This capability lets you skip the tedious trial-and-error process of manually adjusting hyperparameters. Instead, Automatic model tuning performs hyperparameter optimization over multiple training runs by discovering interesting features in your data and learning how those features interact to affect accuracy. You save days-or even weeks-of time spent maximizing the quality of your trained model.
You simply specify the number of training jobs through the API or console, and SageMaker handles the rest by using machine learning to tune your model. It works by learning what effects different types of data have on a model and applying that knowledge across many copies of the model to quickly seek out the best possible outcome. As a developer or data scientist, this means you only really need to be concerned with the adjustments you want to make to the data you feed the model, which greatly reduces the number of things to worry about during training.
Managed spot training
You can reduce the costs of training your machine learning models by up to 90% using Managed Spot Training. Managed spot training uses Amazon EC2 Spot instances, which is spare EC2 capacity, so your training jobs run at much lower costs compared to Amazon EC2 On-Demand instances. Amazon SageMaker manages the training jobs so they are run as and when compute capacity becomes available. As a result, you don’t have to poll continuously for capacity and managed spot training eliminates the need to build additional tooling to manage interruptions. Managed spot training works with automatic model tuning, the built-in algorithms and frameworks that come with Amazon SageMaker, and custom algorithms.