Amazon Neptune
Fast, reliable graph database built for the cloud
Overview
Graph databases, like Amazon Neptune, are purpose-built to store and navigate relationships. They have advantages over relational databases for use cases like social networking, recommendation engines, and fraud detection, where you need to create relationships between data and quickly query these relationships. There are a number of challenges to building these types of applications using a relational database. You would need multiple tables with multiple foreign keys. SQL queries to navigate this data would require nested queries and complex joins that quickly become unwieldy, and the queries would not perform well as your data size grows over time.
Neptune uses graph structures such as nodes (data entities), edges (relationships), and properties to represent and store data. The relationships are stored as first order citizens of the data model. This allows data in nodes to be directly linked, dramatically improving the performance of queries that navigate relationships in the data. Neptune’s interactive performance at scale effectively enables a broad set of graph use cases.
Benefits
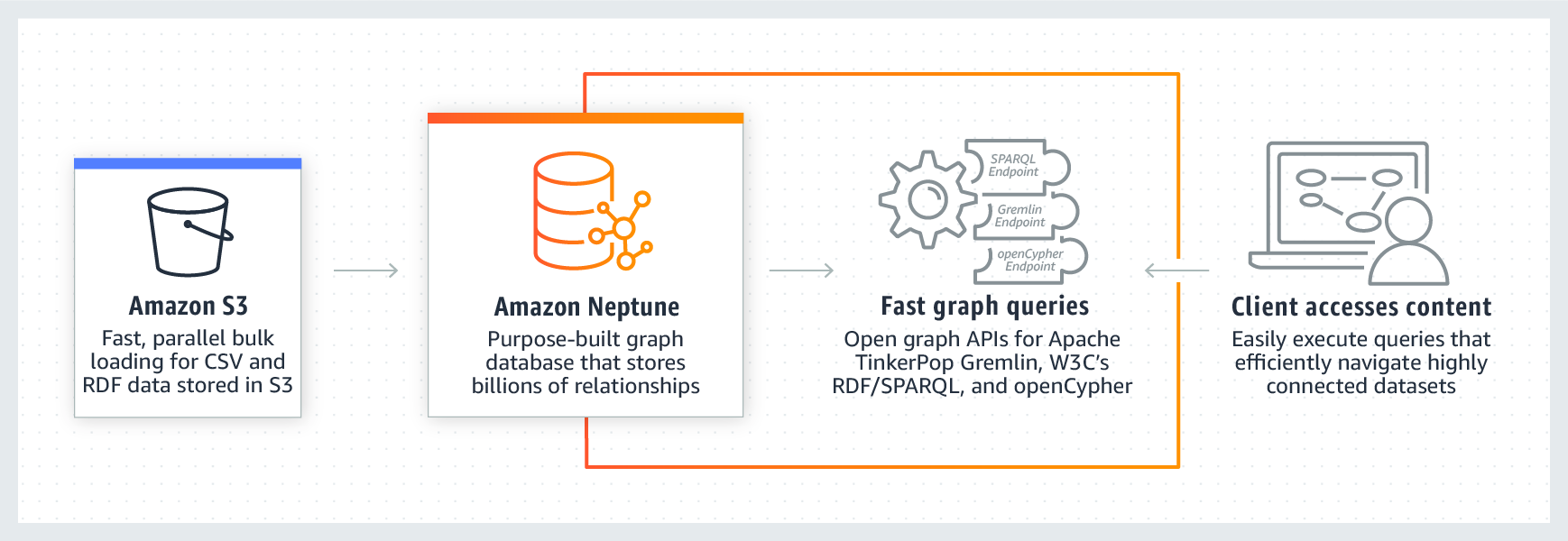
Amazon Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. The core of Amazon Neptune is a purpose-built, high-performance graph database engine optimized for storing billions of relationships and querying the graph with milliseconds latency. Amazon Neptune supports popular graph models Property Graph and W3C's RDF, and their respective query languages Apache TinkerPop Gremlin and SPARQL, allowing you to easily build queries that efficiently navigate highly connected datasets. Neptune powers graph use cases such as recommendation engines, fraud detection, knowledge graphs, drug discovery, and network security.Amazon Neptune is highly available, with read replicas, point-in-time recovery, continuous backup to Amazon S3, and replication across Availability Zones. Neptune is secure with support for HTTPS encrypted client connections and encryption at rest. Neptune is fully managed, so you no longer need to worry about database management tasks such as hardware provisioning, software patching, setup, configuration, or backups.
Amazon Neptune supports open graph APIs for both Gremlin and SPARQL, and provides high performance for both of these graph models and their query languages. It lets you choose the Property Graph model and its open source query language, Apache TinkerPop Gremlin or the W3C standard Resource Description Framework (RDF) model and its standard query language, SPARQL.
With Amazon Neptune, you don’t need to worry about database management tasks such as hardware provisioning, software patching, setup, configuration, or backups. Neptune automatically and continuously monitors and backs up your database to Amazon S3, enabling granular point-in-time recovery. You can monitor database performance using Amazon CloudWatch.
Amazon Neptune is a purpose-built, high-performance graph database. It is optimized for processing graph queries. Neptune supports up to 15 low latency read replicas across three Availability Zones to scale read capacity and execute more than one-hundred thousand graph queries per second. You can easily scale your database deployment up and down from smaller to larger instance types as your needs change.
Amazon Neptune provides multiple levels of security for your database, including network isolation using Amazon VPC, support for IAM authentication for endpoint access, HTTPS encrypted client connections, encryption at rest using keys you create and control through Amazon Key Management Service (KMS). On an encrypted Neptune instance, data in the underlying storage is encrypted, as are the automated backups, snapshots, and replicas in the same cluster.
When to Use Graph Databases
Graph databases, like Amazon Neptune, are purpose-built to store and navigate relationships. They have advantages over relational databases for use cases like social networking, recommendation engines, and fraud detection, where you need to create relationships between data and quickly query these relationships. There are a number of challenges to building these types of applications using a relational database. You would need multiple tables with multiple foreign keys. SQL queries to navigate this data would require nested queries and complex joins that quickly become unwieldy, and the queries would not perform well as your data size grows over time.
Neptune uses graph structures such as nodes (data entities), edges (relationships), and properties to represent and store data. The relationships are stored as first order citizens of the data model. This allows data in nodes to be directly linked, dramatically improving the performance of queries that navigate relationships in the data. Neptune’s interactive performance at scale effectively enables a broad set of graph use cases.
How It Works
Use Cases
Customers












Social Networking
Recommendation Engines
Fraud Detection
Knowledge Graphs
Life Sciences
Network/IT Operations