Amazon Glue
Simple, scalable, and serverless data integration
Overview
Amazon Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. Amazon Glue provides all of the capabilities needed for data integration so that you can start analyzing your data and putting it to use in minutes instead of months.
Data integration is the process of preparing and combining data for analytics, machine learning, and application development. It involves multiple tasks, such as discovering and extracting data from various sources; enriching, cleaning, normalizing, and combining data; and loading and organizing data in databases, data warehouses, and data lakes. These tasks are often handled by different types of users that each use different products.
Amazon Glue provides both visual and code-based interfaces to make data integration easier. Users can easily find and access data using the Amazon Glue Data Catalog. Data engineers and ETL (extract, transform, and load) developers can create and run ETL workflows. Data analysts and data scientists can use Amazon Glue DataBrew to visually enrich, clean, and normalize data without writing code.
Benefits
Faster Data Integration
Different groups across your organization can use Amazon Glue to work together on data integration tasks, including extraction, cleaning, normalization, combining, loading, and running scalable ETL workflows. This way, you reduce the time it takes to analyze your data and put it to use from months to minutes.
No Servers to Manage
Amazon Glue runs in a serverless environment. There is no infrastructure to manage, and Amazon Glue provisions, configures, and scales the resources required to run your data integration jobs. You pay only for the resources your jobs use while running.
Automate Your Data Integration at Scale
Amazon Glue automates much of the effort required for data integration. Amazon Glue crawls your data sources, identifies data formats, and suggests schemas to store your data. It automatically generates the code to run your data transformations and loading processes. You can use Amazon Glue to easily run and manage thousands of ETL jobs or to combine and replicate data across multiple data stores using SQL.
How It Works
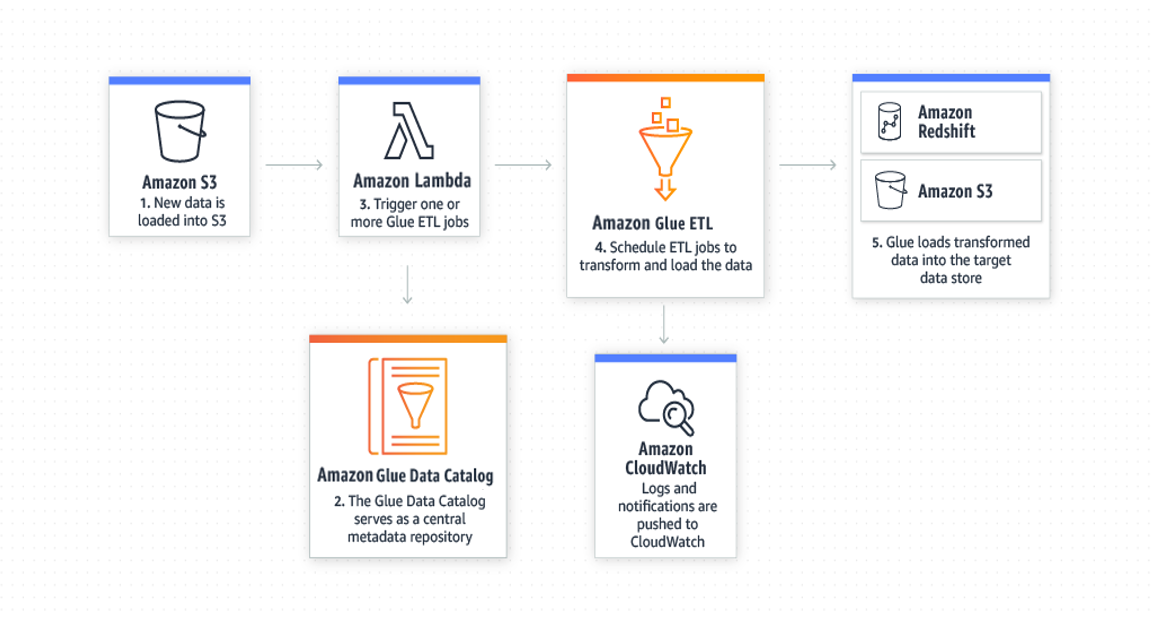
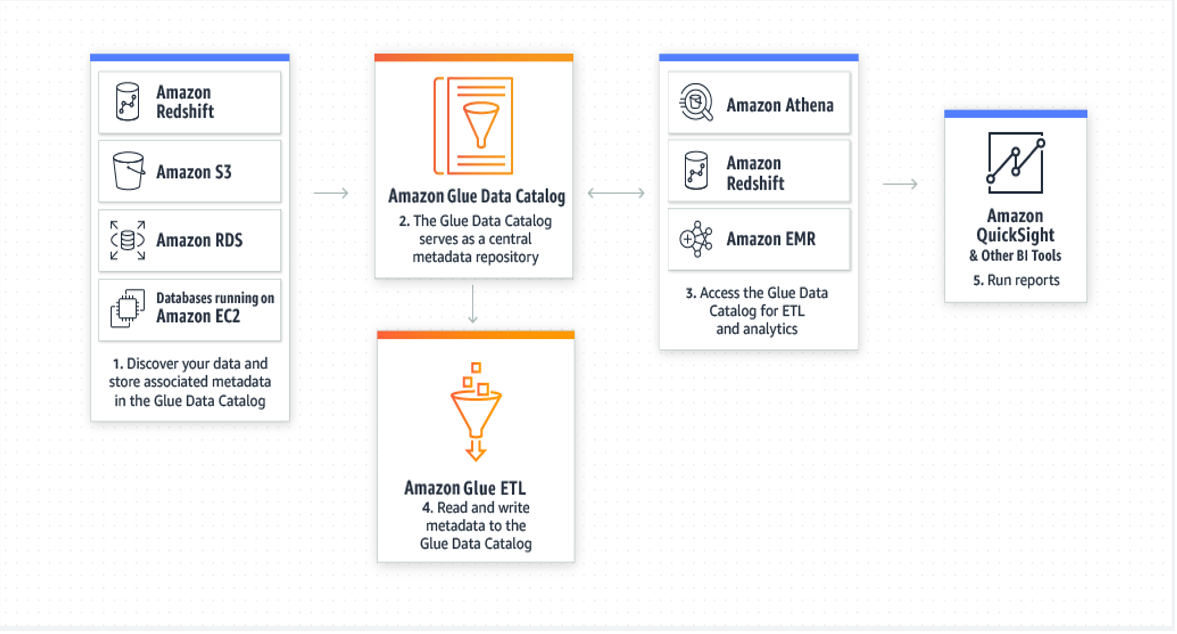
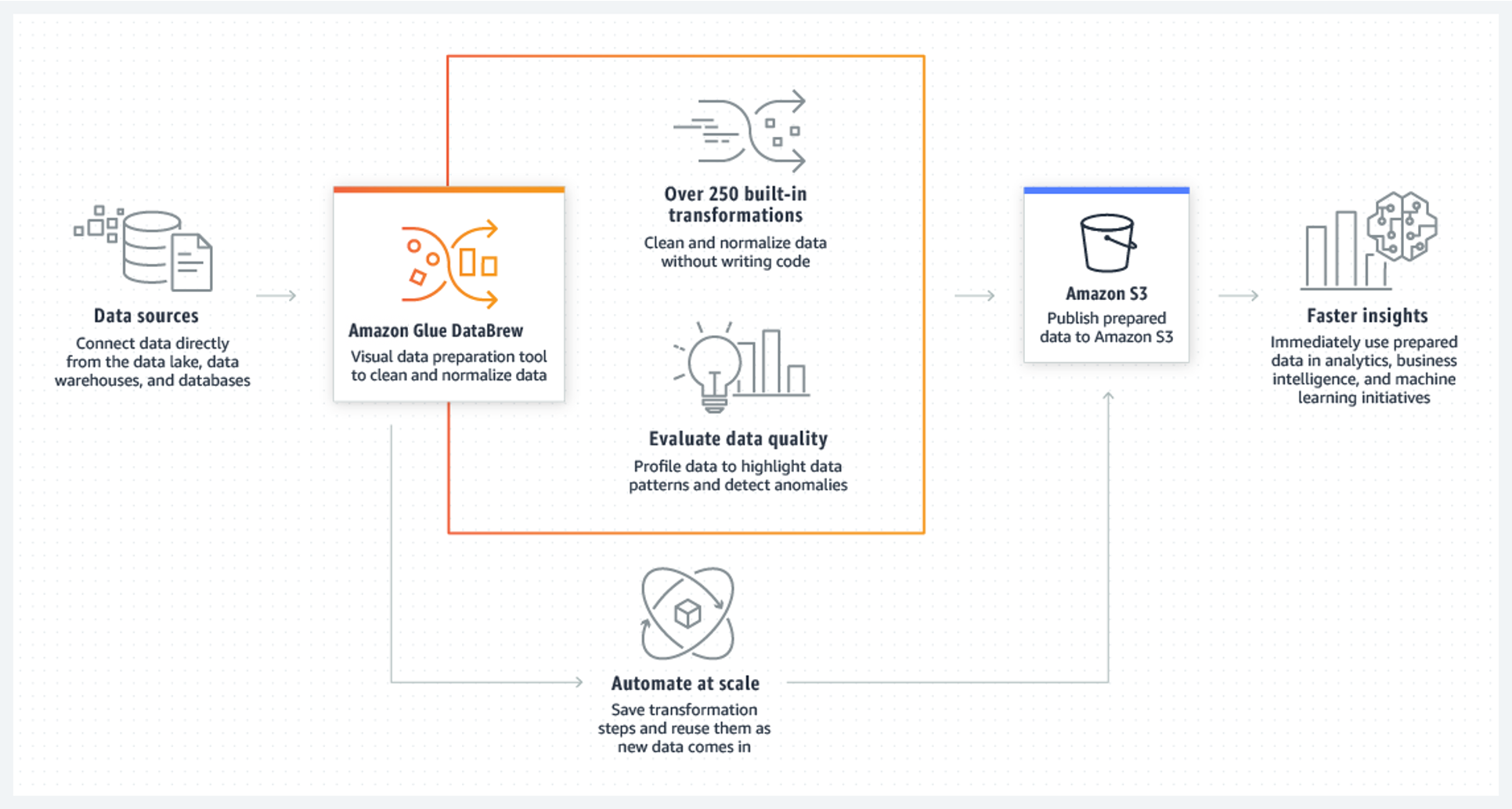
How to Get Started
Find out How It Works
Learn more about the key features of Amazon Glue.
Sign up for a Free Account
Pay nothing or try for free while learning the fundamentals and building on Amazon Web Services.
Connect With an Expert
From development to enterprise-level programs, get the right support at the right time.