We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Perform minor/major version upgrades for Amazon Aurora MySQL Global Database with minimum downtime
Amazon Aurora combines the performance and availability of commercial databases with the simplicity and cost-effectiveness of open source databases. An Aurora DB cluster consists of one or more DB instances connected to a shared and distributed Aurora storage volume.
Amazon Aurora Global Database is designed for globally distributed applications, allowing a single Aurora database to span multiple Amazon Web Services Regions. It replicates your data with no impact on database performance, enables fast local reads with low latency in each Region, and provides disaster recovery from Region-wide outages.
The steps for performing engine major version upgrades of Aurora MySQL Global Database can involve removing all secondary Regions from the global cluster, upgrading the engine version of the primary Region to a higher version, and then recreating secondary Regions. At the time of this writing, in-place minor version upgrades aren’t supported for Aurora MySQL Global Database. During this process, the global cluster temporarily exists without any secondary Regions. Therefore, you don’t have access to global capabilities until you complete the upgrade and recreate the secondary Regions.
Depending on the role and importance of the cluster, you might only be able to afford a very brief downtime, and you will need the downtime window to be controlled and predictable. In such a scenario, you can deploy a replica of clusters running side by side. You can then perform engine version upgrades (or other maintenance) on the replica of the production cluster without impacting the availability of the original cluster. You can also replicate data from the original cluster to the replica until you’re ready for the new cluster to take over. This approach is often referred to as blue/green deployment.
As of this writing, Aurora Global Database doesn’t support the managed Aurora blue/green deployment feature, but you can still build a self-managed solution implementing the same concepts.
In this post, we show how you can use the blue/green deployment technique to perform engine version upgrades for Aurora MySQL global database clusters with minimal downtime. The approach described in this post enables you to keep your global cluster topology intact and retain access to global capabilities throughout the process. Although this post focuses on version upgrades, you can use a similar approach for other types of database maintenance or change management.
Solution overview
In the blue/green deployment technique, the blue environment represents the current database serving production traffic. The green environment is a mirror copy of the blue environment.
You can make version changes on the green environment without impacting the blue environment. Meanwhile, any data changes made by the production applications in the blue environment are continually replicated to the green environment using MySQL binary log replication. After the green environment is upgraded to a new version and ready to take over, you switch production traffic from blue to green. The duration of the switchover determines the application downtime. In practice, switchover time depends on two main factors: replication lag and how quickly you can reconfigure your applications to use green instead of blue.
Optionally, you can implement a rollback capability by configuring replication in the opposite direction after the switchover, essentially creating a new blue/green setup with the cluster roles reversed. However, this must be tested carefully – down-level binlog replication is not officially supported by MySQL and not guaranteed to work in all use cases, so you must thoroughly test this capability with your specific application before implementing it in production.
Let’s review the steps you will go through to implement the solution. The following diagram shows four key steps in the upgrade and multi-Region deployment process.
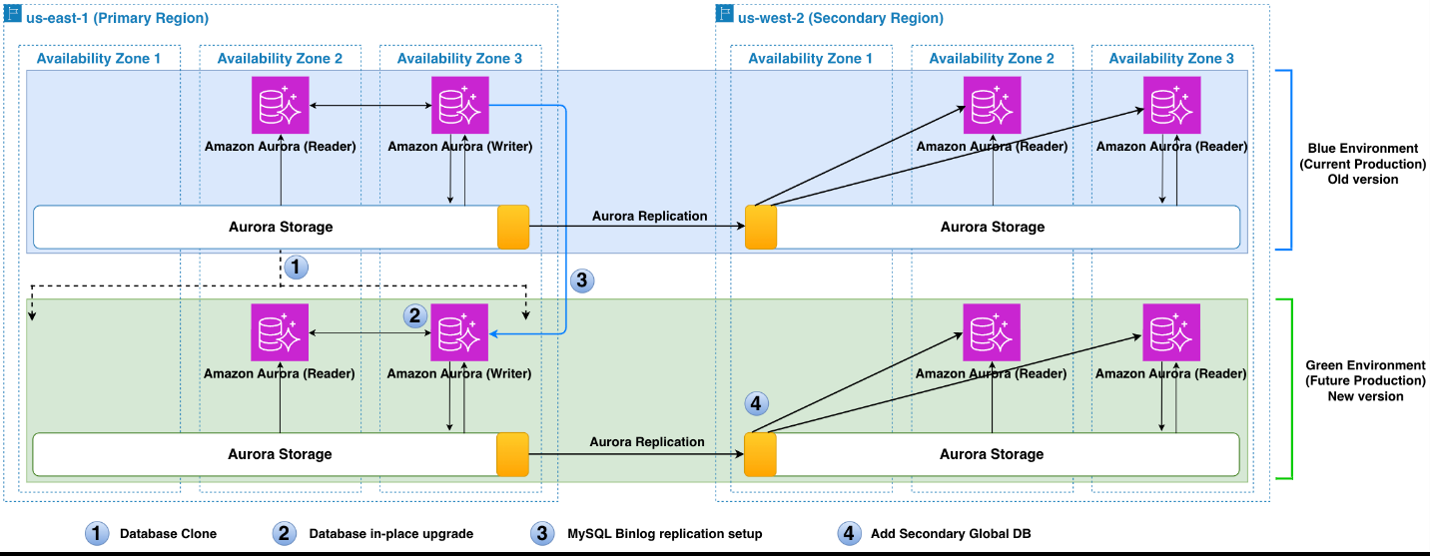
The steps are as follows:
- Use fast database cloning to copy the active cluster (blue) to a new cluster (green) using the same engine version. You can also use a snapshot or a point-in-time restore instead, but clones are much faster and more cost-effective thanks to their shallow copy implementation.
- Perform an in-place major/minor version upgrade on the green cluster.
- Set up MySQL binary log replication between the blue and green environments to keep green in sync with blue.
- Make adjustments in the green environment to match the blue environment in terms of the instance topology and other configuration. During the planned downtime window, switch the applications over from the blue environment to the green environment.
These steps describe the mechanics of the blue/green deployment process. You can use the same general approach for both minor and major version upgrades, but keep in mind that the blue/green technique doesn’t eliminate the need for upgrade testing and validation. Major upgrades in particular will require additional validation steps before you can confidently switch over from blue to green.
Prerequisites
Before getting started, review Aurora MySQL major version upgrade paths to confirm that the current version of Amazon Aurora MySQL-Compatible Edition allows you to perform an in-place major version upgrade. Make sure that Auto Minor Version Upgrade is disabled on the blue cluster to prevent unexpected version changes while you’re going through the blue/green deployment process.
The solution requires binary logging to be enabled in the blue environment. If the blue cluster is already running with binary logs enabled, make sure it’s using a MIXED or ROW binlog format.
If you’re concerned about the performance impact of binary logging, review additional materials regarding binlog improvements in Aurora version 2 and binlog-related innovations introduced in Aurora version 3.
Enabling binary logging requires a reboot, so you might want to do it during a low traffic period or during a planned maintenance window.
To enable binary logging in the blue environment, complete the following steps:
- Create a custom cluster-level parameter group for the Aurora MySQL cluster. You will use it to enable and configure the necessary binlog settings. You can also reuse an existing custom group, if you have one.
- Open the custom parameter group and set the static parameter
binlog_formattoMIXEDorROW. Do not useSTATEMENT. Refer to Binary Logging Formats and Advantages and Disadvantages of Statement-Based and Row-Based Replication for more details.

- Double-check that
sync_binlogandinnodb_flush_log_at_trx_commitparameters are both set to 1. - Reboot the Aurora writer DB instance for
binlog_formatto take effect. - After the Aurora writer DB instance reboots, connect to the database and validate binlog configuration. You should be able to see the binlog file name and position as shown in the following example:
mysql> show global variables like 'binlog_format';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
1 row in set (0.02 sec)
mysql> show master status;
+----------------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+----------------------------+----------+--------------+------------------+-------------------+
| mysql-bin-changelog.000001 | 154 | | | |
+----------------------------+----------+--------------+------------------+-------------------+
1 row in set (0.02 sec)The next step is to change the binary log retention period. The blue environment must retain binary logs while you complete the remaining setup steps (cloning the blue environment, performing the upgrade, setting up replication). Unless configured otherwise, Aurora MySQL-Compatible removes binary logs on its own accord, which might not give you enough time to complete those steps. Therefore, you should preconfigure the retention period to avoid premature binlog removal.
- Check the existing configuration. A value of
NULLindicates that the binlog retention period is not explicitly configured:
mysql> call mysql.rds_show_configuration;
+------------------------+-------+------------------------------------------------------------------------------------------------------+
| name | value | description |
+------------------------+-------+------------------------------------------------------------------------------------------------------+
| binlog retention hours | NULL | binlog retention hours specifies the duration in hours before binary logs are automatically deleted. |
+------------------------+-------+------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)
Query OK, 0 rows affected (0.03 sec)- Change the binary log retention period using the
rds_set_configurationstored procedure:
mysql> call mysql.rds_set_configuration('binlog retention hours',24);
Query OK, 0 rows affected (0.04 sec)Although this example uses a 24-hour binary log retention period, you should choose a retention value that aligns with your specific backup and replication requirements. Longer retention periods can consume significant storage space on your instance and potentially impact performance, especially for write-heavy workloads.
- Validate the binary log retention after the change:
mysql> call mysql.rds_show_configuration;
+------------------------+-------+------------------------------------------------------------------------------------------------------+
| name | value | description |
+------------------------+-------+------------------------------------------------------------------------------------------------------+
| binlog retention hours | 24 | binlog retention hours specifies the duration in hours before binary logs are automatically deleted. |
+------------------------+-------+------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
Query OK, 0 rows affected (0.01 sec)Before proceeding, make sure that your network and security configuration allows replication connections from green to blue. For example, if you use the same security group for green as that of blue, make sure that the security group allows MySQL traffic from itself. If the two environments use different security groups, make sure MySQL traffic is permitted from the green environment to the blue environment.
Although the replication stream flows from blue to green, the green environment initiates a replication connection. That’s why your security configuration must allow connections from green to blue.
You’re now ready to create your green environment and use it for a version upgrade.
Perform a version upgrade for Aurora Global Database with blue/green deployment
In this section, we describe the steps involved in preparing your Aurora MySQL global database for a version upgrade using a blue/green approach. To minimize the binlogs accumulated before setting up replication, choose a low traffic window to perform the following operations.
Create a fast database clone from the blue environment
Create a fast database clone from the primary Region of the Aurora global database cluster. Use the same virtual private cloud (VPC) and subnet for the clone. In blue/green terms, the existing cluster you cloned is the blue environment, and the newly created clone is the green environment, as shown in the following screenshot.
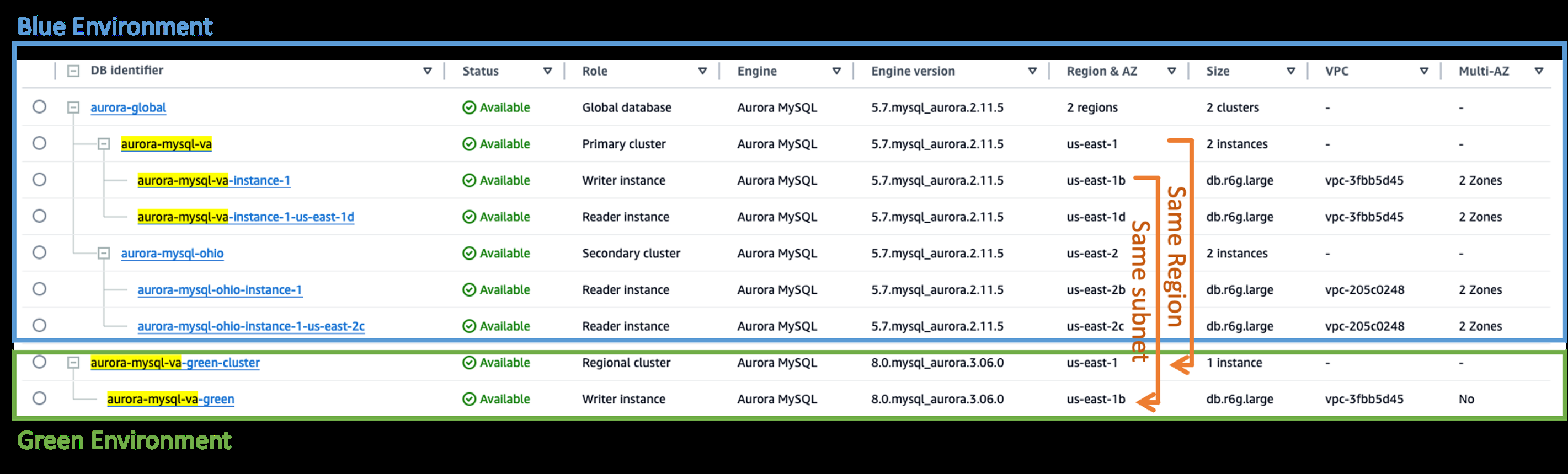
When the clone (green environment) is ready, you can find the MySQL binary log file name and position on the Logs & events tab of its writer instance. Make a note of those binlog coordinates to use later to configure replication.
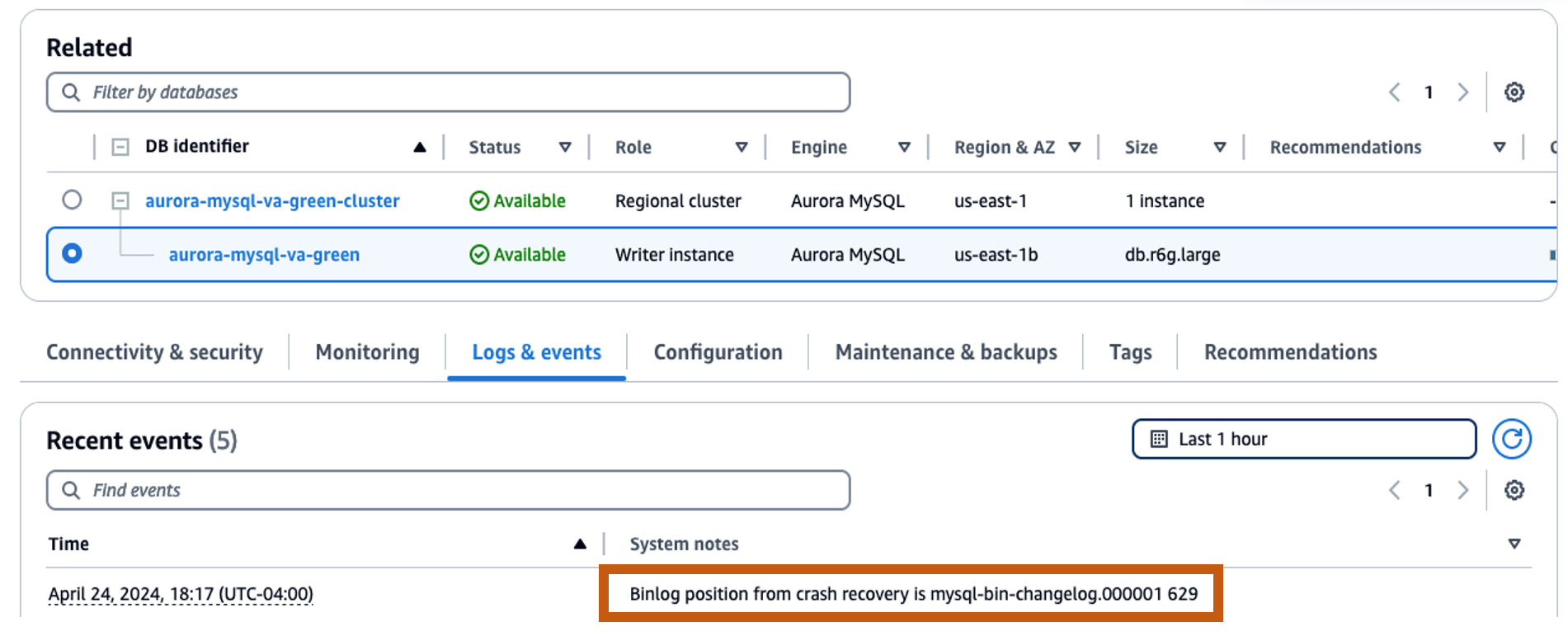
Remember that at the time of this writing, in-place minor version upgrades aren’t supported for Aurora MySQL Global Database. If you’re following this process to perform a minor version upgrade, don’t add secondary Regions to the Aurora clone (green environment) just yet. You will add them later, after completing the upgrade and setting up replication.
There are two more things to take care of at this point:
- Make the necessary adjustments in the green environment to align it with the blue environment in terms of parameters, features, and other configurations. If you’re performing a major version upgrade and your blue environment uses custom database parameters, create parameter groups for the new Aurora MySQL-Compatible version and preconfigure them with your custom settings (to the extent that they apply to the newer major version).
- Decide whether binary logging should be enabled in the green environment. You will need it for the blue/green rollback capability (optional), or if you’re already using binlogs in the blue environment for other reasons, such as downstream change data capture (CDC) integration with other services.
Perform an in-place version upgrade in the green environment
You can now perform the Aurora MySQL major version in-place upgrade or minor version upgrade either using the Amazon Web Services Management Console or Amazon Web Services Command Line Interface (Amazon Web Services CLI) in the green environment.
If the upgrade fails, check the database logs and troubleshoot the issues encountered. The upgrade failure doesn’t impact the original cluster in the blue environment. Create a new clone and note the binlog coordinates as described in the previous step and reinitiate the upgrade after the issue is fixed.
Set up binary log replication
After the upgrade is successfully complete, set up MySQL binary log replication between the blue and green clusters using the following steps:
- Create a replication database user and configure MySQL replication between the two environments. For Aurora MySQL databases, the
skip_name_resolveDB cluster parameter is set to 1 (ON) and can’t be modified, so you must use an IP address (such as 31.0.0/255.255.0.0) or a wildcard (%) for the host instead of a domain name. Connect to the blue environment cluster endpoint and create the replication user using the following code:
mysql> CREATE USER 'repl_user'@'IP_address' IDENTIFIED BY 'password';- Grant the
REPLICATION CLIENTandREPLICATION SLAVEprivileges to the user:
mysql> GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'repl_user'@'IP_address';- Connect to the green environment cluster endpoint and configure MySQL replication by using the
rds_set_external_sourceprocedure (in Aurora MySQL-Compatible version 3) or themysql.rds_set_external_masterprocedure (in Aurora MySQL-Compatible version 2). Use the MySQL binlog file name and position coordinates you noted earlier (after you created the clone):
mysql> CALL mysql.rds_set_external_source ('aurora-mysql-va.cluster-xxxxxx.us-east-1.rds.amazonaws.com', 3306, 'repl_user', 'password', 'mysql-bin-changelog.000001', 629, 0);- Start replication using the
rds_start_replicationprocedure:
mysql> CALL mysql.rds_start_replication;- Validate replication status by using the
SHOW REPLICA STATUSstatement, and make sure the replication process is up and running without any errors. Double-check that theSlave_IO_RunningandSlave_SQL_Runningfields both show Yes, as shown in the following example:
mysql> pager egrep "Slave_IO_Running|Slave_SQL_Running|Error"
PAGER set to 'egrep "Slave_IO_Running|Slave_SQL_Running|Error"'
mysql> show REPLICA status\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Error:
Last_IO_Error:
Last_SQL_Error:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
mysql> nopager
PAGER set to stdoutThe green environment/cluster is now configured as a binary log replica.
- Set the replica as
read_only.
Although you’re not using the green environment for application traffic yet, you can take additional precautions to prevent users or applications from directly changing data on green (which would break replication). You can do that by setting the read_only parameter to 1 in the cluster parameter group used by the green environment. The read_only setting is a dynamic parameter that doesn’t require a reboot to take effect. When set to 1, the parameter prevents regular database users from running data-modifying statements, but it won’t block changes made by the replication threads.
You can verify the parameter value from any database connection on green:
mysql> show global variables like 'read_only';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| read_only | ON |
+---------------+-------+Prepare for blue/green switchover
After successfully establishing binlog replication from the blue to green environment, the next critical steps involve comprehensive testing of the green environment, including application functionality, performance benchmarking, and database cache prewarming. Additionally, it’s essential to mirror the blue cluster’s topology in the green environment while validating the overall readiness for the switchover by comparing performance metrics between both environments.
Perform application testing for the green environment
The complexity of this step depends on whether you’re performing a minor or major version upgrade. Minor upgrades can often be done with limited testing, but you should still review release notes very carefully. Major upgrades almost always require a substantial application testing and validation effort.
You can use the green environment itself for read-only application testing, but shouldn’t use the green environment for write testing, because it would interfere with replication. You can use a separate non-production environment or an Aurora clone of the green environment for more comprehensive testing with read/write traffic as a best practice.
Although the green environment is actively replicating production changes from the blue environment, those changes are streamlined through a limited number of replication threads (or even a single thread). As a result, the green cluster’s performance metrics won’t reflect resource usage, throughput, and concurrency characteristics of the production workload, and they can’t be used for performance comparisons between the blue and green environments.
For proper, comprehensive read/write testing, you will likely need a separate environment with a test suite, workload mirroring, or other techniques to simulate production traffic.
Capture performance data from the blue environment
For major version upgrades, it’s a good idea to baseline the performance of the existing (blue) environment before switching over. This performance data can be used later for troubleshooting and optimizing database performance, in case the new database version exhibits a different performance profile. For general performance troubleshooting, refer to Troubleshooting Amazon Aurora MySQL database performance.
We also recommend capturing key instance-level and cluster-level Amazon CloudWatch metrics that can be used for comparison and troubleshooting later on. In addition, data from Amazon RDS Performance Insights can help you identify existing top SQL statements, top waits, average query runtime (query latency), calls per second (query throughput), and more. Consider capturing this data as part of your baselining effort.
Recreate the blue cluster topology in the green environment
At this point, your green environment is upgraded and you’re replicating all data changes from the blue environment, all without impacting the availability of the blue environment. You can now add secondary Regions to your green environment to match the existing topology of your blue environment.
Confirm readiness for switchover
In preparation for the blue/green switchover, monitor replication status and replication lag between the two environments. You can use the SHOW SLAVE STATUS or SHOW REPLICA STATUS commands directly, or observe the lag through the AuroraBinlogReplicaLag CloudWatch metric. This metric tracks the Seconds_Behind_Master field from SHOW SLAVE STATUS (for Aurora MySQL-Compatible version 2) or SHOW REPLICA STATUS (for Aurora MySQL-Compatible version 3). If you’re experiencing high replication lag that could prevent you from finding a suitable switchover window, refer to Amazon Aurora MySQL replication issues for troubleshooting tips.
The lower the replication lag, the less time you will have to wait for replication to catch up during the switchover. A lag of 0 seconds is ideal.
Before the production database switchover, double-check that you completed all the prior steps to align both environments in terms of instance topology, database parameters, features, and other configurations. Confirm that the green environment is fully prepared and preconfigured to take over.
If you require a rollback capability (the ability to switch back from green to blue), confirm that binary logging is enabled on the green environment with a retention period of a few hours (as described earlier). Without binary logs on green, it will be impossible to initiate replication in the reverse direction.
Prewarm the database cache in the green environment
If the application is very sensitive to database performance, you can prewarm the database cache (buffer pool) on the green cluster by running your top SELECT queries. If your application supports read/write splitting and can tolerate the replication lag, you can also consider using the green environment for read-only traffic as a way to prewarm the caches.
Perform the blue/green switchover
Before proceeding, double-check that replication is still up and running without errors, and that replication lag is at or close to 0. For best results, perform switchover during a planned maintenance window, or plan your switchover window during a period of low activity.
Remember never to write to both environments at the same time. Replication doesn’t automatically overwrite or recover from write conflicts, and it might be difficult or impossible to reconcile the conflicts manually.
Stop write traffic in the blue environment
Verify that the green environment is still in read-only mode, as described earlier. Now, stop the application traffic and make sure that all the write activities are complete on the blue environment.
There are several ways to stop application traffic, from stopping the application itself to using the read_only parameter on the blue environment to disallow application writes, although the latter option will likely result in the application encountering query errors. Whichever method you choose, the ultimate goal is to prevent writes on the blue environment during the switchover.
For best results, you can isolate the blue environment from write traffic by using the read_only parameter or by using security group rules.
Stop replication in the green environment
Before you stop the replication process, make sure all binlog events are replicated and applied on the green cluster. The file names and positions must match, as shown in the following example.
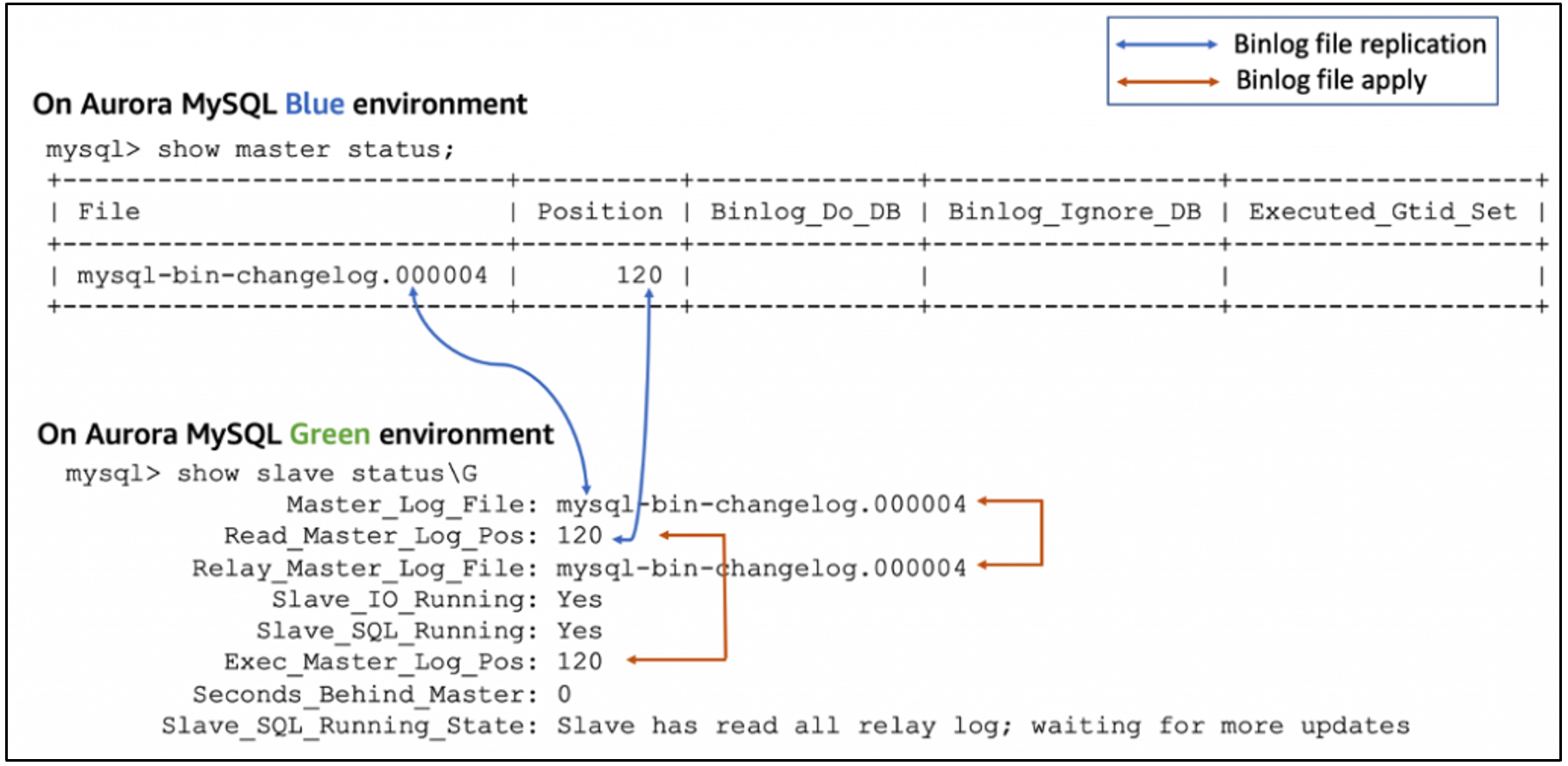
In addition to the binary log positions, look for the following values in the replication status output:
- Slave_IO_Running – Yes
- Slave_SQL_Running – Yes
- Seconds_Behind_Master – 0
- Slave_SQL_Running_State – Slave has read all relay logs; waiting for more updates
If there is any replication lag, wait until replication catches up. After that happens, you’re ready to stop the replication process.
- Connect to the green cluster.
- Stop replication using the
rds_stop_replicationprocedure:
mysql> call mysql.rds_stop_replication;- Remove replication configuration the using
rds_reset_external_sourceprocedure:
mysql> call mysql.rds_reset_external_source;- If you want to configure reverse replication for fallback purposes, or have downstream CDC integrations reading binary logs from blue, obtain binary log coordinates from the green environment. These coordinates can be used to configure reverse blue/green replication, or to reposition CDC integrations:
mysql> show master status;- Put the green environment in read/write mode by changing the
read_onlydatabase parameter to 0 (or OFF). Apply the change immediately. - Verify that the
read_onlyis set to OFF on green:
mysql> show global variables like 'read_only';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| read_only | OFF |
+---------------+-------+At this point, there’s no application traffic on either blue or green, replication is stopped, and the green environment is ready to start taking traffic.
Perform the application switchover
Now that the green environment is ready, you can reconfigure applications to use the green cluster endpoints instead of the blue cluster endpoints. Because you can’t rename a database cluster that is part of a global database, the green environment can’t take over the DNS endpoints from the blue environment. As a result, connectivity reconfiguration must happen at the application layer itself, or you can use a middle layer solution such as a proxy or a self-managed custom Amazon Route 53 endpoint.
If using a DNS-based switchover solution, make sure your applications are capable of recognizing DNS changes without additional delay. For best practices for endpoint connections, see Working with Amazon Aurora MySQL.
Perform post-switchover tasks
In this section, we cover additional topics such as rollback with reverse replication and backup management after the switchover.
Implement rollback capability using reverse replication
You can set up reverse replication between the new environment (formerly green) and the old environment (formerly blue). However, it’s crucial to note that down-level replication is not officially supported by MySQL and may not work in all cases – thorough testing with your specific application is absolutely essential before implementing this approach. This can be done using the MySQL binlog file coordinates captured during the switchover process, after stopping application traffic on blue and disabling replication on green. This essentially creates a new blue/green setup, but with the cluster roles reversed.
There are two main variants of the rollback/reverse replication technique:
- Replicate back to the old blue environment – This approach allows you to roll back to the previous cluster. Although MySQL doesn’t officially support replication from a newer to an older major version, such replication setups are possible and quite common. You might require additional steps (such as configuration changes) to deal with version differences.
- Roll forward to a clone of the old blue environment – In this approach, you leave the original blue environment intact, and instead you replicate to a clone of that environment. The original environment can be used as an additional recovery option, or you can leave it running for other reasons.
The following diagram compares these approaches.
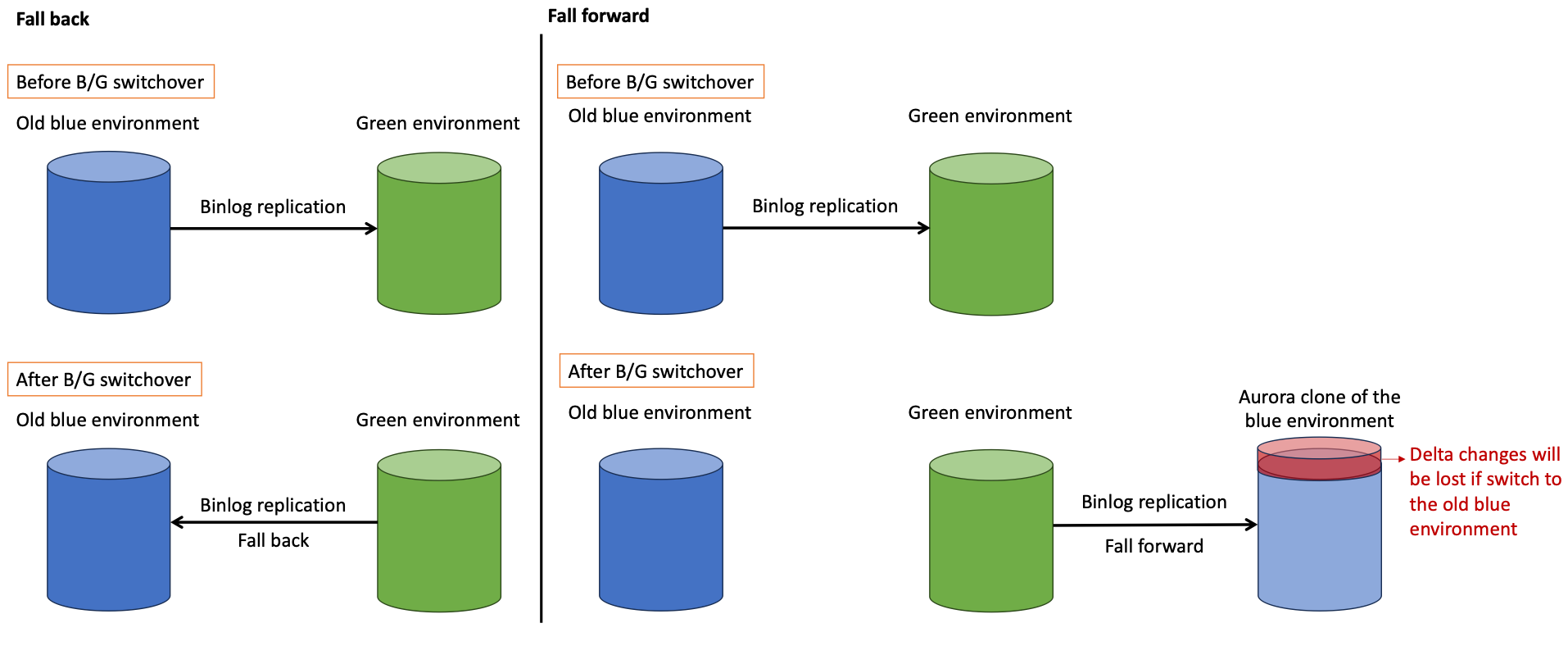
Consider running additional post-switchover tests and application health checks in the newly promoted environment (formerly green) so that if you do need to switch back, you can make that decision as quickly as possible.
Backup considerations
The blue/green switchover process doesn’t move any cluster-specific resources such as automated backups. Automated database backups taken from the original blue environment will remain associated with that environment, and the new environment will produce its own backups. If you have a specific requirement for the number of days covered by backups from both environments, but you don’t want to keep the original cluster running for cost reasons, you can stop the cluster and delete manual snapshots (taken manually or using an Amazon Backup plan) that are no longer needed. If you need to restore the original cluster to a specific point in time while the original cluster is deleted, use retaining automated backups. Automated backups that you retain for more than one day after cluster deletion are charged. Manual snapshots are not affected by cluster deletion: they’re retained until you delete them. Delete snapshots in a timely manner if they are no longer required, especially when the cluster is deleted for cost reasons. For more information, see the Amazon Aurora pricing page.
Clean up
When you’re sure you no longer need the resources in the old blue environment, you can delete them. However, if you’re not ready to delete the old resources yet but want to reduce the total cost, you can remove secondary Regions from the blue cluster and then stop database instances in the remaining Region.
After all the blue cluster resources are deleted, you might also want to remove any additional items associated with that environment (for example, database logs files exported to CloudWatch Logs).
Summary
In this post, we discussed the steps and best practices for Aurora MySQL global database minor and major version upgrades using a self-managed blue/green approach. The solution allows you to perform database upgrades, as well as a variety of other maintenance tasks, in a controlled manner and with minimum downtime.
Let us know your feedback in the comments section.
About the Authors
 Ranjini Menon is an Associate Specialist Solutions Architect in Databases based in London. She has experience in relational databases, ERP consulting, and data engineering, and is passionate about helping customers in their journey to the Amazon Web Services Cloud with a focus on database migration and modernization.
Ranjini Menon is an Associate Specialist Solutions Architect in Databases based in London. She has experience in relational databases, ERP consulting, and data engineering, and is passionate about helping customers in their journey to the Amazon Web Services Cloud with a focus on database migration and modernization.
 Wanchen Zhao is a Senior Database Specialist Solutions Architect at Amazon Web Services. Wanchen specializes in Amazon RDS and Amazon Aurora, and is a subject matter expert for Amazon DMS. Wanchen works with ISV partners to design and implement database migration and modernization strategies and provides assistance to customers for building scalable, secure, performant, and robust database architectures in the Amazon Web Services Cloud.
Wanchen Zhao is a Senior Database Specialist Solutions Architect at Amazon Web Services. Wanchen specializes in Amazon RDS and Amazon Aurora, and is a subject matter expert for Amazon DMS. Wanchen works with ISV partners to design and implement database migration and modernization strategies and provides assistance to customers for building scalable, secure, performant, and robust database architectures in the Amazon Web Services Cloud.
 Rajesh Matkar is a Principal Partner Database Specialist Solutions Architect, previously worked at Amazon Web Services. He worked with Amazon Web Services Technology and Consulting partners to provide guidance and technical assistance on database projects, helping them improve the value of their solutions.
Rajesh Matkar is a Principal Partner Database Specialist Solutions Architect, previously worked at Amazon Web Services. He worked with Amazon Web Services Technology and Consulting partners to provide guidance and technical assistance on database projects, helping them improve the value of their solutions.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.