We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
New – Fully managed Blue/Green Deployment in Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL
Making updates to databases, such as major upgrades, instance scaling, and changes to parameter settings, is challenging to do with minimal downtime and no business disruption. Even with extensive testing, direct changes to the production environment aren’t necessarily safe or fast. Direct changes can result in extended downtime for the duration of the operation. The alternative—creating a staging environment that mirrors the production environment, setting up stable synchronization between both environments, and then performing a low-downtime switchover—is safer and faster but not straightforward.
For example, to test major version upgrades,
For workloads that require simpler orchestration of creating a staging environment for extensive testing and achieve maximum availability during a major version upgrade, we’re pleased to announce the general availability of Amazon RDS blue/green deployments for
With just a few clicks, you can create a blue/green deployment to create a separate fully managed staging environment (green) that mirrors the production environment (blue). The staging environment clones your production environment’s primary database and in-Region read replicas. Blue/green deployment keeps these two environments in sync using PostgreSQL community provided logical replication.
In as fast as a minute, you can promote the staging environment to be the new production environment with no data loss. During switchover, the blue/green deployments block writes on both the environments so that the green environment is fully synchronized with the production database (blue). The blue/green deployment redirects production traffic to the newly promoted staging environment, all without any code changes to manage your endpoints.
In this post, we walk through an example of creating a blue/green deployment. We also show how to perform major version upgrades using blue/green deployment with minimal downtime and describe the switchover process. Finally, we discuss the best practices for using blue/green deployment.
Solution overview
Blue/green deployment is based on
Prerequisites
To get started, you need to
It is important to note that besides enabling logical replication, depending on your database workload, you are also required to tune the following parameters which are further discussed in best practices section of this post.
You can also modify the parameter group directly from the
If you’re adding this parameter to an existing Amazon Aurora cluster, you need to restart the database for the settings to take effect. We recommend that you make these parameter changes along with in-place minor version upgrade to a blue/green supported engine version, to avoid multiple restarts on your production database. For example, if you have an Amazon Aurora PostgreSQL-compatible instance named
blue-green-inst01
, you can restart it using the following command:
Bootstrap the green cluster
You can create a green cluster using the following command, where the source is the Amazon Resource Name (ARN) of the source production database:
After creation is complete, you now have a staging environment that is ready for test and validation before promoting it to be the new production environment.
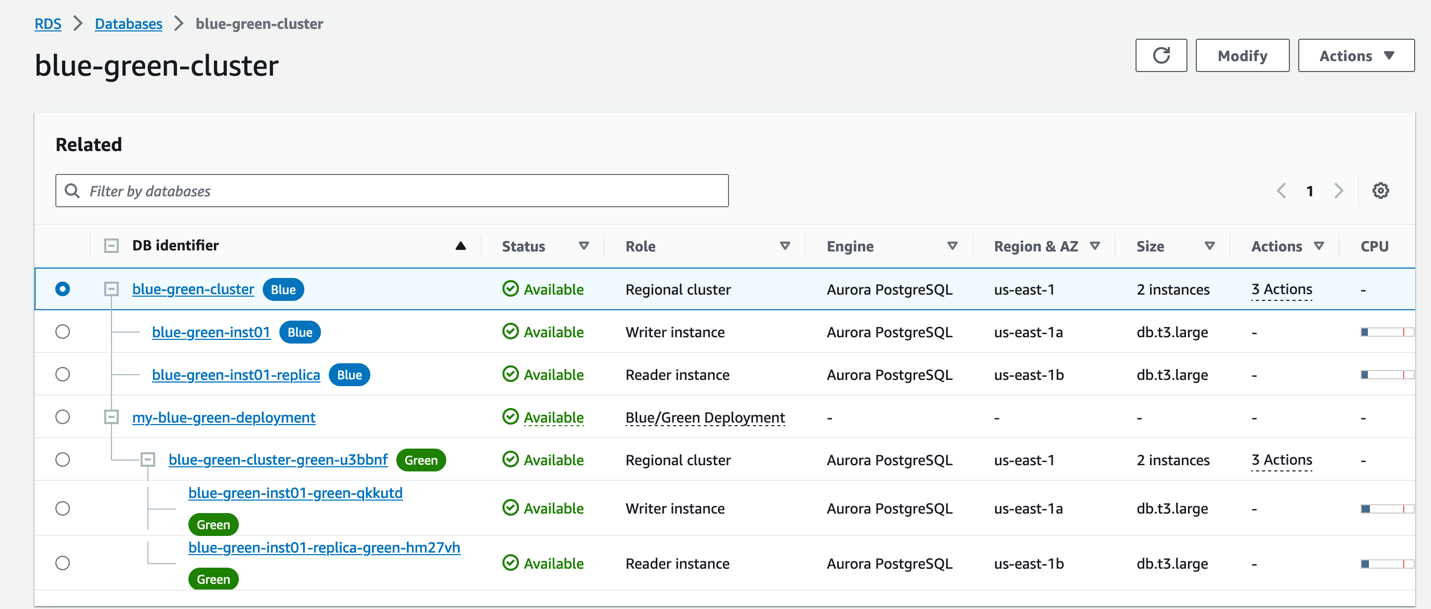
For a step-by-step guide, refer to
Perform a major version upgrade using blue/green deployment
Historically, you had a few options to perform a major version upgrade:
- In-place upgrade – This involves a straightforward and one-click managed workflow. The typical upgrade takes about 10–15 minutes, but it can vary depending number of database objects (tables, schemas, sequences, and so on).
-
Manually creating the staging environment
– Manually created the staging environment either using
native logical replication orAmazon Web Services Database Migration Service (Amazon Web Services DMS) can provide a higher degree of control and low downtime at the expense of considerable planning and orchestration.
For more information about these options, refer to
With blue/green deployment, now you have a straightforward and fully-managed way to perform major version upgrades. You can create the green cluster on the new major version as part of the deployment, or you can upgrade the green cluster manually using an in-place upgrade after a green cluster is ready. Refer to the following guides for
If you want to automatically upgrade the green cluster as part of the deployment, you have to additional parameters such as
--target-engine-version
and
--target-db-parameter-group-name
, as shown in the following example code. Make sure to create a new parameter group called
pg15-blue-green
with your custom settings required for the future production cluster.
The following diagram shows the high-level steps to perform a major version upgrade.
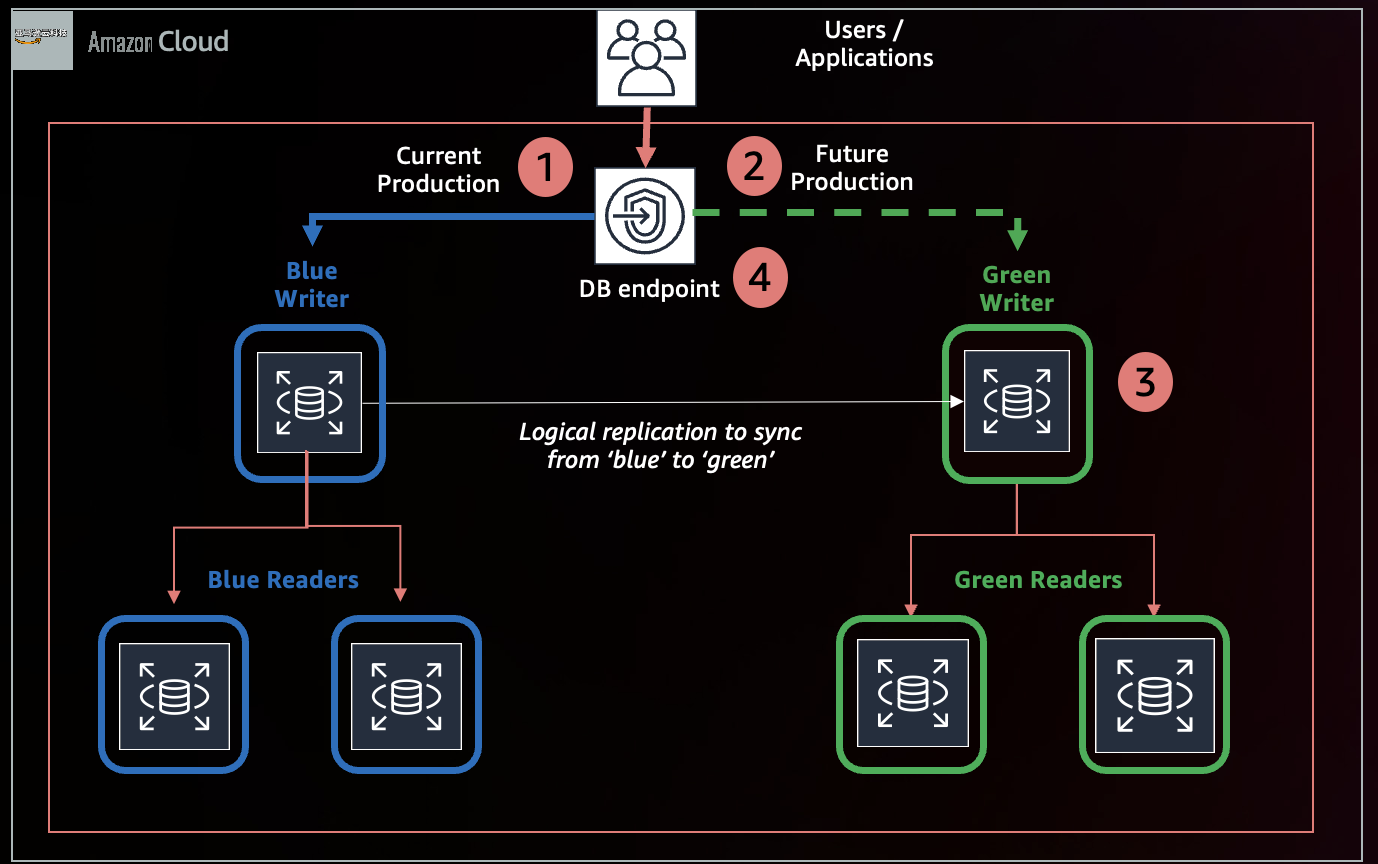
The workflow steps are as follows:
- An existing production cluster serves as the current blue primary.
- When you create a blue/green deployment, it creates a mirrored copy of the current production environment (blue) as the green cluster, which will be a future production environment.
- Amazon RDS performs a major version upgrade on the green cluster. While an in-place major version upgrade is running on the green cluster, there will not be any impact on the blue cluster. The replication will fall behind while the green environment is being upgraded, but it will catch up after the major version upgrade is finished.
- The green cluster is then promoted as the new primary.
Perform a switchover
After the green cluster is upgraded and replication is fully in sync, you can switch over to the green cluster (new production cluster). Amazon RDS performs several checks that act as guardrails to ensure a safe switchover:
- Checks for instance health
- Checks to verify that replication is synced up between the blue and green clusters
- Checks if any DDL activity was performed on the blue cluster (this will prevent you from switching over)
-
Checks for
large objects (this will prevent you from switching over) - Makes sure there are no long-running active writes or long-running DDL running on the blue cluster
- Makes sure the blue primary DB instance isn’t the target of external replication to prevent writes on the blue primary DB instance during switchover
After all checks have passed, Amazon RDS will perform the following actions part of the switchover:
- Amazon RDS stops writes to the blue and green clusters and drops the connections from both clusters.
- Before switching from the blue cluster to the green cluster, Amazon RDS ensures the green cluster is fully synchronized with the blue cluster.
- Amazon RDS increments sequence values in the green environment to match those in the blue environment.
- The green cluster is promoted as the new primary.
-
Amazon RDS renames the DB instances in the green environment to match the corresponding DB instances in the blue environment. At the same time, Amazon RDS renames the blue cluster with the suffic
-old{n}. For example, if your old cluster is namedmydb, then the green cluster will be namedmydband the old blue database will be namedmydb-old1.
Next, we open up the connection to both clusters with the green cluster (new primary), which starts accepting writes. The blue cluster (old primary) will serve read-only queries until it is rebooted to avoid split-brain scenarios.
The following is a sample command to perform a switchover:
If the time for the switchover takes more than the specified
switchover-timeout
, then any changes are rolled back and no changes are made to either environment.
Best practices
In this section, we discuss best practices for using blue/green deployment and the customer experience that is built within blue/green deployment to manage the current
Requirements for primary key
The PostgreSQL logical replication, the blue/green deployment replicates table data based on their replication identity (usually a primary key). If you have any tables without a primary key, any inserts on the table will get replicated. However, updates and deletes on that table will be blocked by the following message:
It’s important to make sure each table has a replication identity such as a primary key or a unique key.
For example, let’s say you have a table without a primary key:
You have a few options. The first option is to create a unique index and use the UNIQUE index as the replication identity or use
The following is an example of using REPLICA IDENTITY FULL:
In the case of REPLICA IDENTITY FULL, all the column values are written to the write ahead log (WAL). Because it adds verbosity to WALs, it is resource-consuming and not recommended to use for heavily updated tables.
In the case of the blue/green deployment, it’s important to ensure all the tables have a replication identity before the green cluster is created. At the time of release of this feature, you will not be able to make any DDL changes on either the blue/green database after the green cluster is bootstrapped.
Handling schema changes (DDL)
In line with the current
Internally, we track any DDL changes applied on the blue cluster. Any DDL activity will be logged in PostgreSQL logs and generate an
It’s worth noting that even if you create a table and later drop it, it will still be flagged as a DDL activity and prevent you from performing a switchover to the green cluster. In such an event, it’s recommended to create a new green cluster.
The following are two ways you can check if any DDL activity was performed on the blue cluster after the green cluster was created:
-
Use the
rds_toolsextension :
If
file_exists
is
t
, this indicates DDL activity was detected.
- Check recent events under Logs and events on the Amazon RDS console. You expect to see an event similar to the following:
Handling a large number of databases and tables
As discussed earlier, blue/green deployment is based on logical replication. Logical replication uses a publish and subscribe model with one or more subscribers subscribing to one or more publications on a publisher node. In one RDS cluster, you can create multiple databases. Logical replication in PostgreSQL is done on a per-database basis, which means there will be at minimum one publication and subscription per database.
As the number of databases increases, there will be more publications and subscriptions and an equal number of logical replication slots. For each additional database that exists, there will be higher CPU and memory resource consumption on the blue cluster, which can impact performance on the current production cluster (blue).
The following are a few key parameters and recommendations:
- max_replication_slots – This must be set to at least the number of subscriptions expected to connect, plus some reserve for table synchronization. There will be one subscription per database, so make sure to set a number greater than the number of databases.
-
max_wal_sender
– This is the maximum number of background processes that the system can support. It’s recommended to set this number slightly higher than
max_replication_slots. - max_logical_replication_worker – You should set this to a number of databases, plus some reserve for the table synchronization workers and parallel apply workers.
-
max_worker_processes
– This is the maximum number of background processes that the system can support. It should be set to at minimum
max_logical_replication_worker+ 1 or higher.
Amazon RDS will check these values as prerequisites before creating the green cluster. If the settings are incompatible, it will fail to create a green cluster.
If you have a large number of tables in a database, the time to replicate and sync will increase based on the
max_logical_replication_worker
setting and the size of the tables.
Memory tuning
In logical replication, the
walsender
process is responsible for decoding changes from the WAL when a transaction is committed. In PostgreSQL version 12 and lower, PostgreSQL maintains an in-memory hash table to track the changes. For each transaction, when maximum changes in memory get more than 4096, rest of the changes get spilled to the disk. It needs to be read back to further process the transactions, which slows down the replication. If you are using PostgreSQL 13 or higher, it’s recommended to tune
FreeableMemory
Sequences
Because sequences aren’t replicated by logical replication, it’s required to synchronize the sequences between the blue and green clusters during the switchover. This operation of synchronizing the sequences is handled by Amazon RDS automatically as part of the switchover process.
Because this operation is performed during the switchover process, if you have a large number of sequences, it could potentially add more time to the switchover process.
Large objects
Large objects (
Materialized views
Materialized views are used to physically store data and can be updated by the REFRESH MATERIALIZED VIEW command. The data of a materialized view on the green cluster may not match the data on the blue cluster. However, you can run REFRESH MATERIALIZED VIEW on the green cluster to update the materialized view to reflect the latest data.
Foreign tables
If you have any foreign tables configured on the blue cluster, those will not get configured on the green cluster. In this case, you have to manually configure foreign tables on the green cluster before switching over.
Extensions
Make sure to update all of your PostgreSQL extensions to the latest version before you create a blue/green deployment so that they can be compatible with a higher major version the green cluster.
If you’re using the
,
, or
extension, which is running DML activity on the database, make sure to disable that on the green cluster. For the
extension, make sure to give the green DB instance access to Amazon S3 through an
or
extensions that have on-going external replication, we recommend that you disable them before creating blue/green deployments.
Cleanup
If you created Blue/Green deployment for Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL cluster in this post and no longer need to use them, you can delete them at this time.
To remove a Blue/Green Deployment, you must first get
BlueGreenDeploymentIdentifier
. For example, to get Blue/Green Identifier from the earlier example, you can run the following command:
Next, use following CLI command to Delete a blue/green deployment and the DB cluster in the green environment. Use the Deployment identifier from the preceding command.
For more options and instruction to delete a blue/green deployment using the Amazon Web Services Management Console please refer
Conclusion
Amazon RDS blue/green deployment copies a production database environment to a separate, synchronized staging environment. With blue/green deployment, you can make changes to the database in the staging environment without affecting the production environment. For example, you can upgrade the major or minor DB engine version and change database parameters. When you are ready, you can promote the staging environment to be the new production database environment, with downtime typically under one minute.
Learn more about Blue/Green Deployments on the
About the Author

The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.