We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Enabling and validating additional checksums on existing objects in Amazon S3
Verifying data integrity during a data migration or data transfer is a data durability best practice that ensures your data is error-free and not corrupt as it reaches its destination. One way to verify the integrity of your data is through checksums, which you can basically think of as a digital fingerprint for data that you can use to track any change in data during transmission or at rest. Many media and entertainment organizations, as well as government agencies, use checksums for end-to-end data integrity verification and to maintain evidential chain of custody.
In this blog, we’ll dive into how to add additional checksums to existing Amazon S3 objects, how to add additional checksums to newly created objects that are uploaded without enabling additional checksums, and how to validate local file integrity with the checksum information computed by Amazon S3 to verify data integrity between the two files.
With this guidance, you can use this information to confidently verify the integrity of data transferred and stored in Amazon S3 for its entire lifetime. This capability is important as you can verify assets are not altered when copied, you can accelerate integrity checking of data, and you can confirm that every byte is transferred without alteration, allowing you to maintain end-to-end data integrity.
Adding and validating checksums for existing Amazon S3 objects
Amazon S3 recently added
As mentioned in the intro, in this blog post we focus on three key areas:
- Adding checksums to existing objects in Amazon S3.
- Integrating an automated mechanism to add checksums to subsequent uploads that do not specify a checksum.
- Verifying the checksums for objects in Amazon S3 against the original on-premises data.
And with that, let’s get started.
Part 1: Adding checksums to existing objects in Amazon S3
There are two scenarios for adding checksums for data uploaded without specifying a checksum algorithm. In both cases we’ll make use of the
Part 1a: Prepare environment
To prepare the environment, we create a new bucket and upload a file via the Amazon Web Services Management Console. This is just to create a mock example, so we can retrospectively add checksums to the objects.
- Create a bucket in Amazon S3.
a. Sign in to the
b. Then, select
Create bucket
.
c. In the
Bucket name
box of the
General configuration
section, type a bucket name.
-
-
The bucket name you choose must be unique among all existing bucket names in Amazon S3. One way to help ensure uniqueness is to prefix your bucket names with the name of your organization. Bucket names must comply with certain rules. For more information, view the
bucket restrictions and limitations in the Amazon S3 user guide .
-
The bucket name you choose must be unique among all existing bucket names in Amazon S3. One way to help ensure uniqueness is to prefix your bucket names with the name of your organization. Bucket names must comply with certain rules. For more information, view the
d. Select an
Amazon Web Services Region
.
e. Navigate down the page and keep all other default selections as they are.
f. Choose the
Create bucket
button. When Amazon S3 successfully creates your bucket, the console displays your empty bucket in the
Buckets
panel.
- Create a folder.
a. In the
Buckets
section, choose the name of the new bucket that you just created.
b. Then, in the
Objects
section, select the
Create folder
.
c. In the
Folder
section, in the
Folder name
area, name the new folder
data
.
d. Keep the
Server-side encryption
selection as
Amazon S3-managed keys (SSE-S3)
and then select
Create folder
.
3. Upload some data files to the new Amazon S3 bucket.
a. In the
Objects
section, Select the
Name
of the data folder.
b. Then, select the
Upload
button.
c. On the
Upload
page select the
Add files
.
d. Follow the
e. Once files have been uploaded, choose the
Upload
button.
f. You will then see that an
Upload: status
page indicating if your upload has been completed successfully. If your upload succeeded, select the
Close
button.
Once you have uploaded data into the new bucket, select the object in the
Objects
section of the same
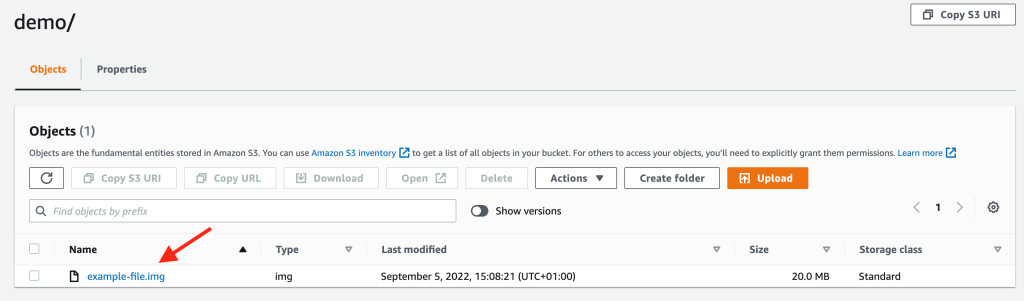
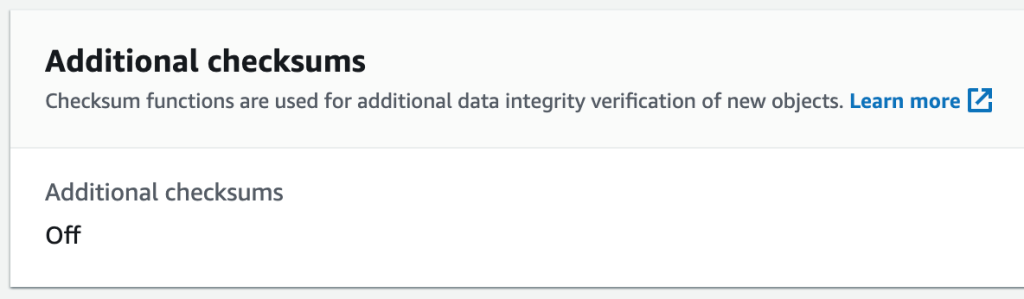
You will then be presented with another page with additional specifics on your object. Navigate down to the Additional checksums section and you will see Additional checksums are set to off .
Part 1b: Adding checksums to existing objects
We are now going to set up some resources we’ll use during the rest of the walkthrough. For example, we’ll set up an
Run:
git clonehttps://github.com/aws-samples/amazon-s3-checksum-verification cd amazon-s3-checksum-verification
This downloads the code to your local machine.
To add checksums to all our existing Amazon S3 objects, we use
- Create a CSV file containing the following details:
Examplebucket,objectkey1
e.g.
s3-integrity-demo,data/filename.img
- When preparing the environment, upload the file to the root of the bucket you created in part 1a above.
Note:
If you are doing this at scale, we suggest you
Once you have a manifest file (either the CSV we created above or an Amazon S3 Inventory manifest), we create an Amazon S3 Batch Operations job using the steps below.
-
Sign in to the Amazon Web Services Management Console and open the Amazon
S3 console . - When in the Amazon S3 console, choose Batch Operations on the left navigation pane. Then, choose the Create job button. Next, choose the Amazon Web Services Region where you want to create your job.
-
In the
Manifest
section under
Manifest format
, choose
CSV
as the type of manifest format. If you choose
Amazon S3 inventory report
, enter the path to the manifest.json object that Amazon S3 generated as part of the CSV-formatted inventory report. Optionally, you can add the desired
Manifest object version ID
for the manifest object if you want to use a version other than the most recent. If you choose
CSV
, in the
Manifest object
section, enter the path to a CSV-formatted manifest object. The manifest object must follow the format described in the console, for further details see the
documentation on supported formats . You can optionally include the version ID for the manifest object if you want to use a version other than the most recent. Then, choose Next . - Complete the form as follows:
a. Under
Operation
, select
copy
.
b. For the
Destination
in the
Copy Destination
area, enter the bucket name you created earlier without the prefix, e.g.,
c. Check,
I acknowledge that existing objects with the same name will be overwritten
.
d. Select
Replace with a new checksum function
under the
Additional checksums
section, and choose your algorithm of choice, e.g.,
SHA256
. Then, select
Next
.
5. Uncheck
Generate completion report
.
6. Select
Choose from existing IAM roles
and select the role containing
S3BatchRole…
7. For
Review
, verify the settings. If you need to make changes, choose
Previous
. Otherwise, choose
Create Job
.
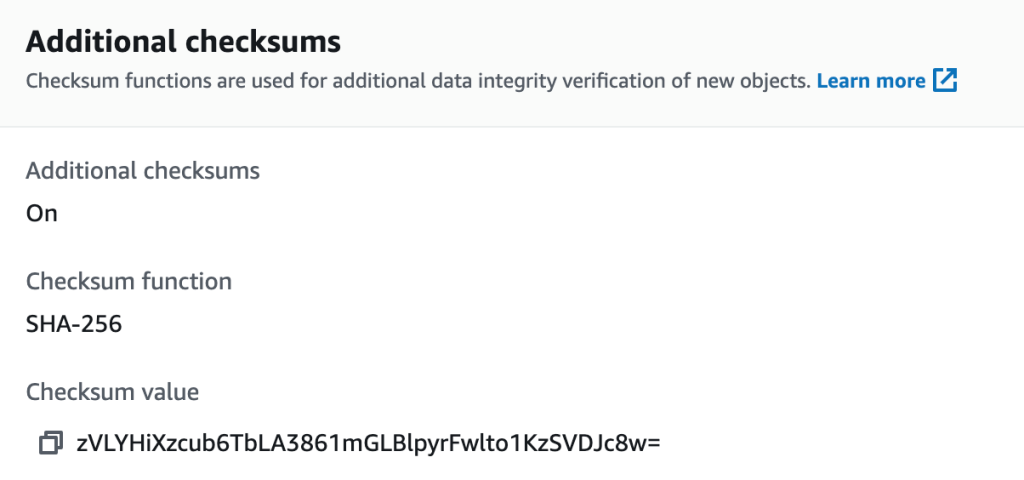
Once the job has been created, select it and choose Run job . Upon job completion, you can validate the results by selecting the object you originally uploaded in the Amazon S3 console. Here you will be able to see the object has additional checksums enabled, which algorithm has been used to calculate the checksum, and what checksum value was computed.
Part 2: Automatically enabling checksums on newly uploaded objects
To add checksums to newly uploaded data, we configure an Amazon S3 event to invoke our previously created Lambda function for any objects that are added to the bucket.
-
Sign in to the Amazon Web Services Management Console and open the Amazon
S3 console . - In the Buckets section, select the name of the bucket that you want to enable events for. Note, you must select the object name directly instead of the radio button. Then, choose Properties .
- Navigate down the page to the Event notifications section and choose Create event notification .
- In the General configuration section, specify a descriptive Event name for your event notification. Enter the folder name you created for the Prefix , e.g., data .
- In the Event types section, select put and post . By making these selections, this will only enable checksums on new and updated Amazon S3 objects.
- Navigate further down the page to the Destination section. Keep the defaults in that section as is. In the Lambda function drop down menu, choose the Lambda function containing ChecksumLambda…
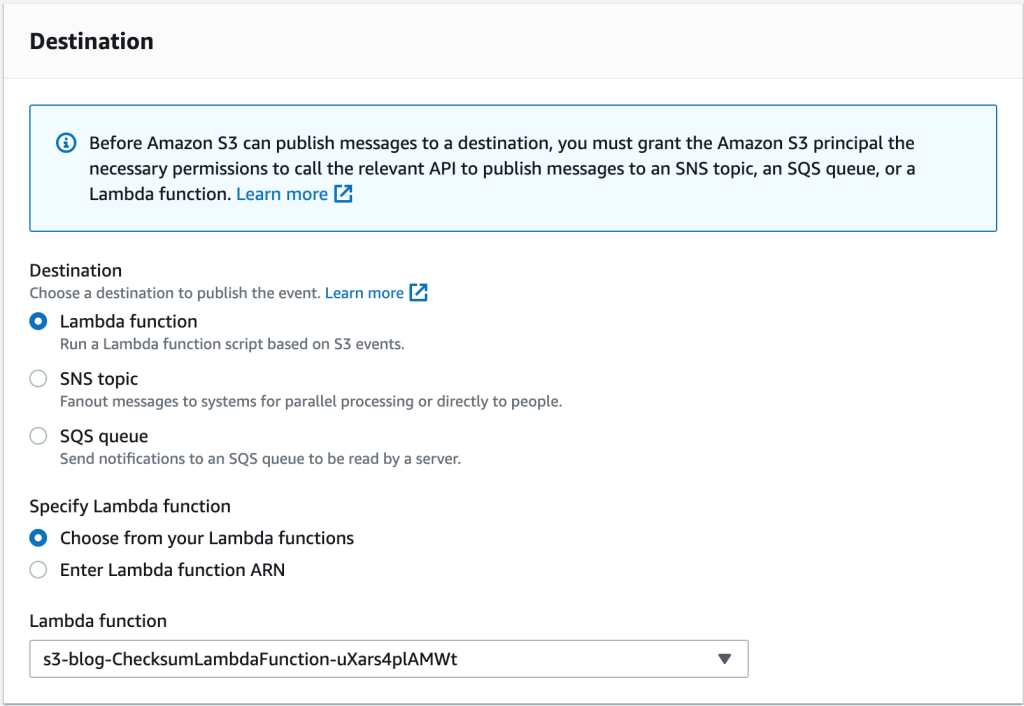
7. Select Save Changes .
Now when an object is uploaded to Amazon S3, the Lambda function will perform a copy-object operation, during which it will add the additional checksum based on the algorithm specified during the deployment of the initial CloudFormation script in part 1b above. You can test this by uploading a new file to the data folder and checking that checksums are successfully enabled.
Part 3: Validating local files match the hashes generated by Amazon S3
We have now completed two procedures to apply additional checksums.
- Adding checksums to existing objects using a batch process.
- Adding an automated mechanism to add checksums to newly ingested data uploaded without specifying a checksum.
Now, we will cover how the checksum information can be used to validate the data in Amazon S3 against the local copy of our data.
In this example we use a simple python script to query the checksum details in Amazon S3 and use this information to perform the same actions against our local files to validate the data matches.
- Clone the code from Github and enter the repo:
git clonehttps://github.com/aws-samples/amazon-s3-checksum-verification cd amazon-s3-checksum-verification
- Install the python packages the script needs:
pip install -r requirements.txt
-
Configure Amazon Web Services cli credentials following
this guide . - Run the following command to check file integrity.
./integrity-check.py --bucketName <your bucketname> --objectName <prefix/objectname-in-s3> --localFileName <local file name>
- You should see a confirmation confirming the data matches. For example:
PASS: Checksum match! - s3Checksum: GgECtUetQSLtGNuZ+FEqrbkJ3712Afvx63E2pzpMKnk= | localChecksum: GgECtUetQSLtGNuZ+FEqrbkJ3712Afvx63E2pzpMKnk=
The integrity-check.py function queries the Amazon S3 object metadata using the
Cleaning up
The only ongoing charges from this exercise are the Amazon S3 storage costs for the files in S3 and charges for Lambda invocations if you continue to upload further objects. If you do not want to incur any additional charges, you should delete the S3 bucket and the CloudFormation script that were created for the testing.
Conclusion
As assets are migrated and used across workflows, customers want to make sure the files are not altered by network corruption, hard drive failure, or other unintentional issues. Customers migrating large volumes of data to Amazon S3 should perform data integrity checks as a durability best practice.
In this post, we have shown you how to:
- Add additional checksums to existing Amazon S3 objects.
- Add additional checksums to newly created objects that are uploaded without enabling additional checksums.
- Validate local file integrity with the checksum information computed by Amazon S3 to verify data integrity between the two files.
To summarize, Amazon S3 uses checksum values to verify the integrity of data that you upload to or download from Amazon S3. We encourage you use this information to confidently verify the integrity of data transferred and stored in Amazon S3 for its entire lifetime in order to maintain end-to-end data integrity.
For more detail on the additional checksum feature, we recommend reading the
Thank you for reading this post. If you have any comments or questions, leave them in the comments section.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.