We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Build a centralized audit data collection for Amazon RDS for PostgreSQL using Amazon S3 and Amazon Athena
Database audits are one of the important compliance requirements that organizations need to meet. You might be required to capture, store, and retain the audit data for the long term. You also need to meet your organization’s information security regulations and standards.
In this post, we show you how to capture and store audit data from an
Solution overview
The following diagram shows the solution architecture, which uses the following Amazon Web Services services to analyze PostgreSQL audit files:
- Amazon Athena
-
Amazon CloudWatch - Amazon Web Services Glue
-
Amazon Kinesis Data Firehose -
Amazon Web Services Lambda - Amazon S3
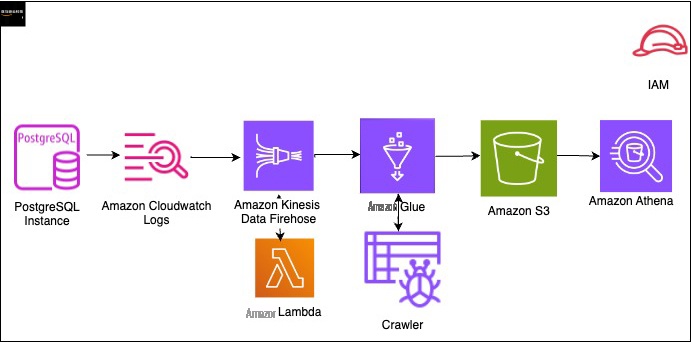
The high-level steps to implement this solution are as follows:
-
Create
Amazon Web Services Identity and Access Management (IAM) roles. - Create a Lambda function to decrypt the streams.
- Create an S3 bucket for storing the files generated by Kinesis Data Firehose.
- Enable Amazon RDS to write to CloudWatch Logs.
- Create a Firehose delivery stream.
- Create a subscription filter.
- Set up an Amazon Web Services Glue database, crawler, and table.
- Run Athena queries to identify database performance issues.
Prerequisites
To follow along with this post, you must have the following prerequisites:
- An Amazon Web Services account with proper privileges to create and configure the necessary infrastructure.
-
An RDS for PostgreSQL database. For instructions, refer to
Create and Connect to a PostgreSQL Database . -
Auditing set up for the PostgreSQL database. For instructions, refer to
Logging at the session and object level with the pgAudit extension . - The necessary roles to interact with the services. We provide more details in the following section.
Because this solution involves setting up and using Amazon Web Services resources, it will incur costs in your account. Refer to
Create IAM roles
You can create your IAM roles using the IAM console, the
You need three roles:
,
, and
CWLtofirehose-lambda-exec-role
. The
CWLtoKinesisFirehoseRole
allows CloudWatch Logs to stream data to Kinesis Data Firehose. See the following code:
The
FirehosetoS3Role
allows Kinesis Data Firehose to write to Amazon S3. See the following code:
The
CWLtofirehose-lambda-exec-role
is the Lambda execution role. See the following code:
Create a Lambda function
We create the Lambda function to decrypt the streams and push the records to Amazon S3 via Kinesis Data Firehose. Then we add a layer to the function for the logger. To create the function on the Lambda console, complete the following steps:
- On the Lambda console, choose Functions in the navigation pane.
- Choose Create function .
-
Name your function
CWLtofirehose. - Choose the runtime Python 3.10.
-
Choose the existing role
CWLtofirehose-lambda-exec-role. - Enter the following code and create your function:
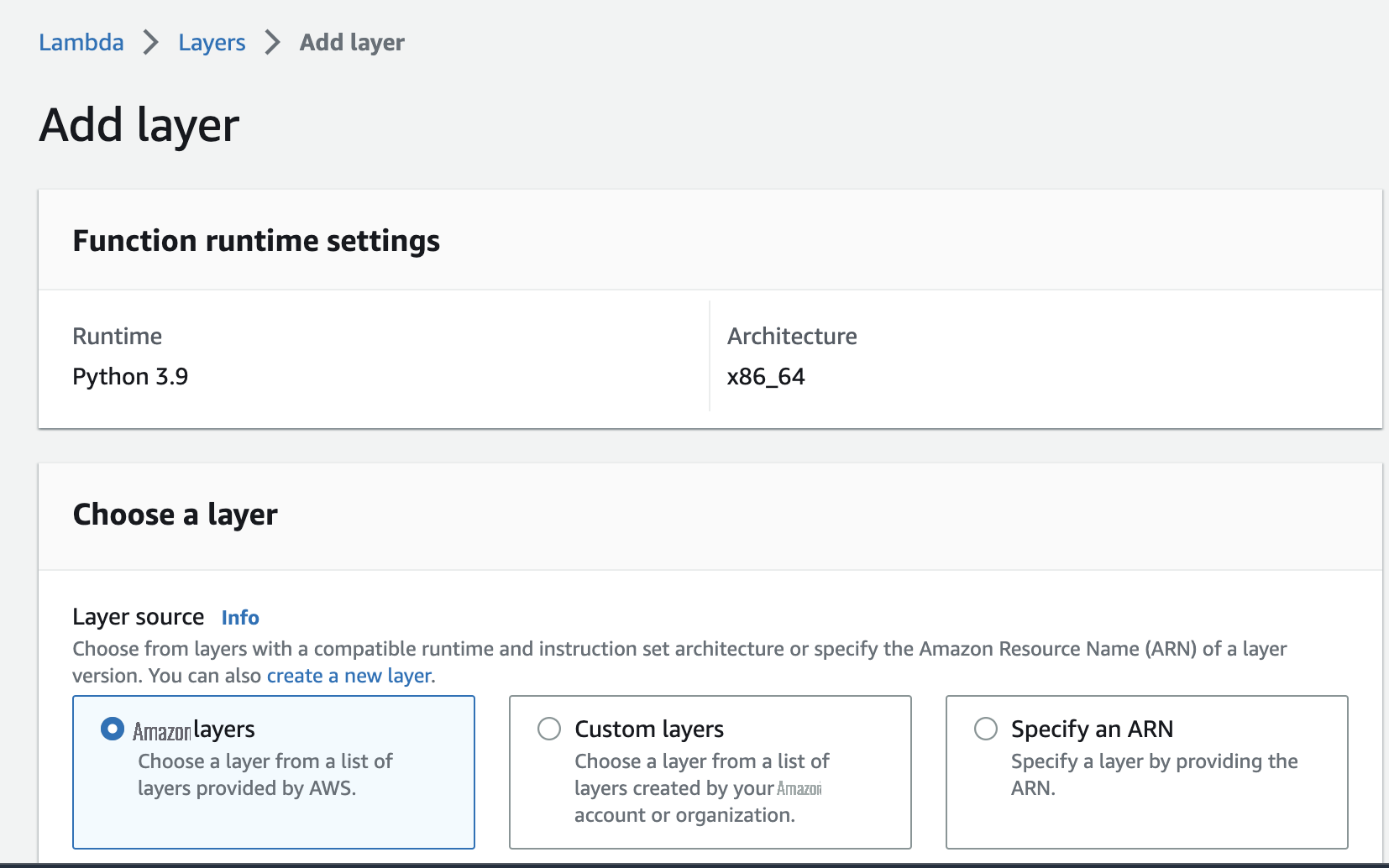
- On the Lambda console, choose Layers in the navigation pane.
- Choose Add layer .
-
For
Layer source
, select
Amazon Web Services layers
.
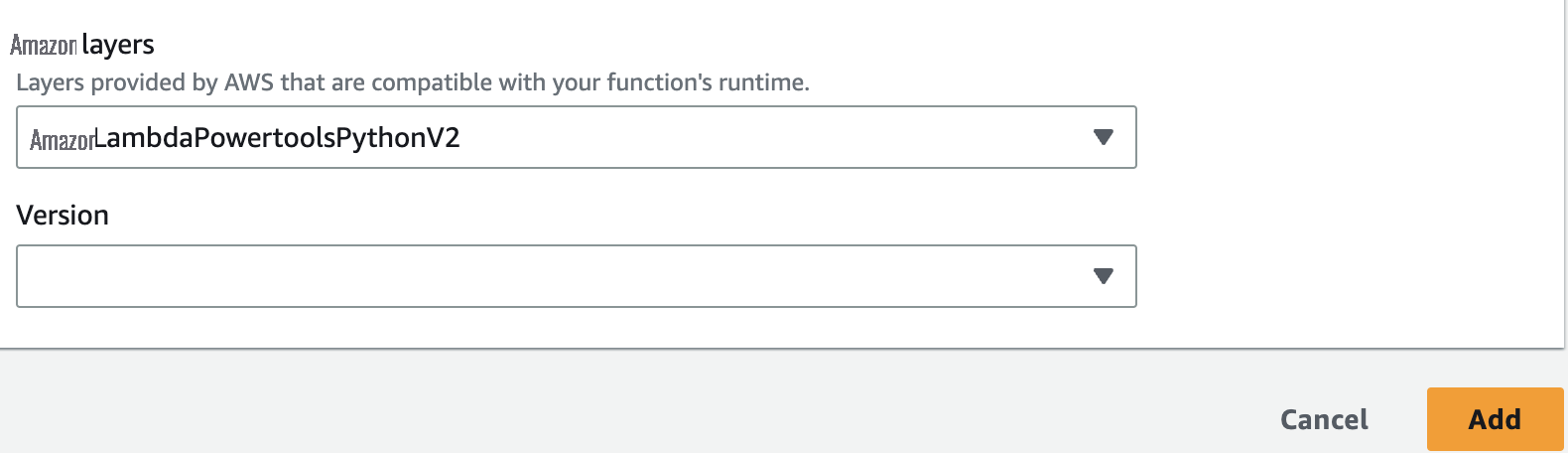
-
For
Amazon Web Services layers
, choose the layer
AWSLambdaPowertoolsPythonV2. -
Choose
Add
.
Create an S3 bucket
Next, we create a bucket to store the audit files generated by Kinesis Data Firehose. For instructions on creating your S3 bucket, refer to
Enable Amazon RDS to write to CloudWatch Logs
To enable Amazon RDS to write to CloudWatch Logs, complete the following steps:
- On the Amazon RDS console, choose Databases in the navigation pane.
-
Choose the instance that you want to publish logs to CloudWatch for, then choose
Modify
.

-
In the
Log exports
section, select the log types that you want to publish.

Create a Firehose delivery stream
Create the Firehose delivery stream with the following steps:
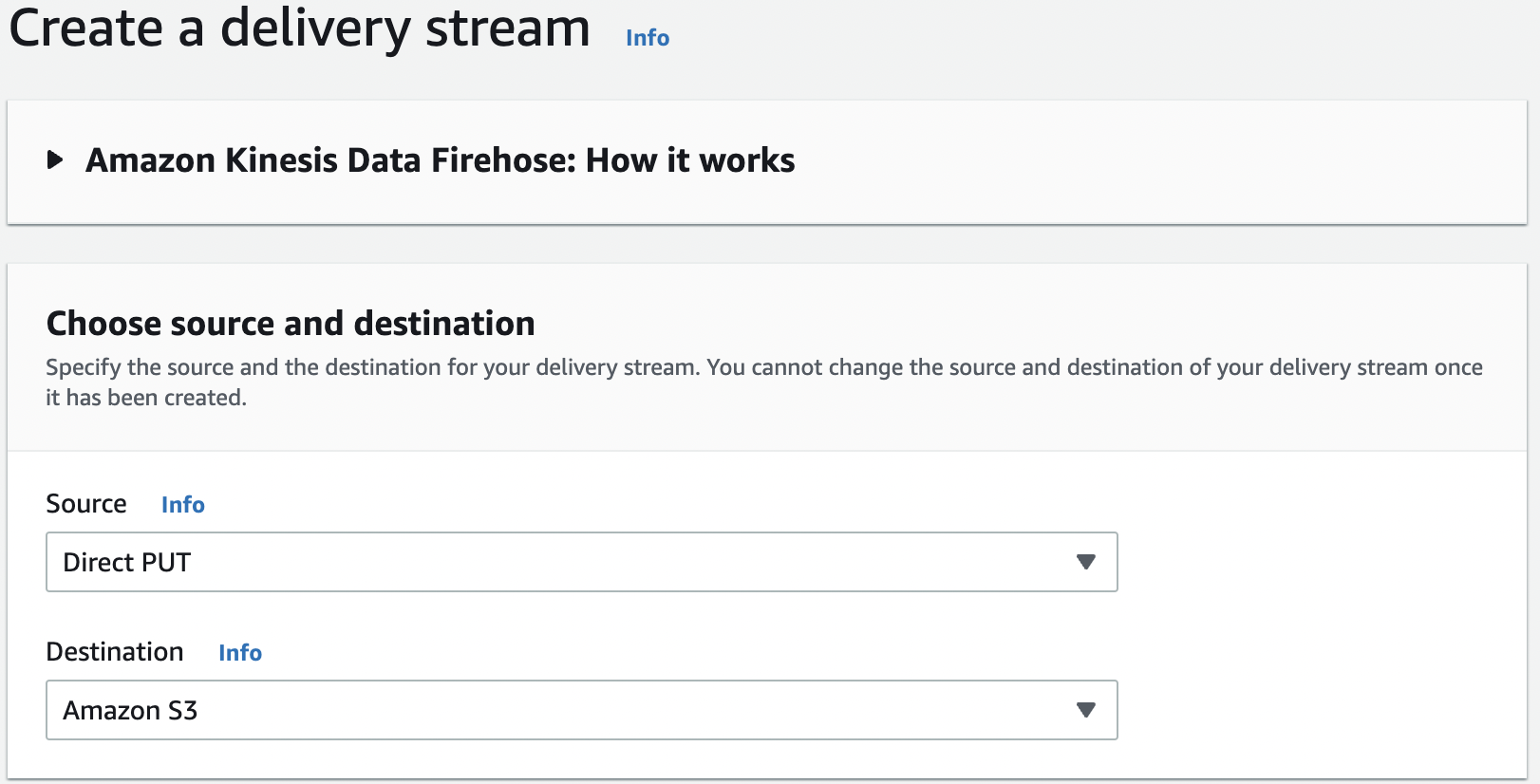
- On the Kinesis Data Firehose console, choose Create a delivery stream .
-
Choose your source and destination.
- For Delivery stream name , enter a name.
- For Data transformation , select Enabled .
-
For
Amazon Web Services Lambda function
, enter your function ARN.

- For Buffer size , enter your preferred buffer size for your function.
- For Buffer interval , enter your preferred buffer interval for your function.
-
For
Record format conversion
, select
Disabled
.

- For S3 bucket , enter the name of your S3 bucket.
- For Dynamic partitioning , select Disabled .
-
For
S3 bucket prefix
, enter an optional prefix.

-
Under
S3 buffer hints
, choose your preferred buffer and interval.
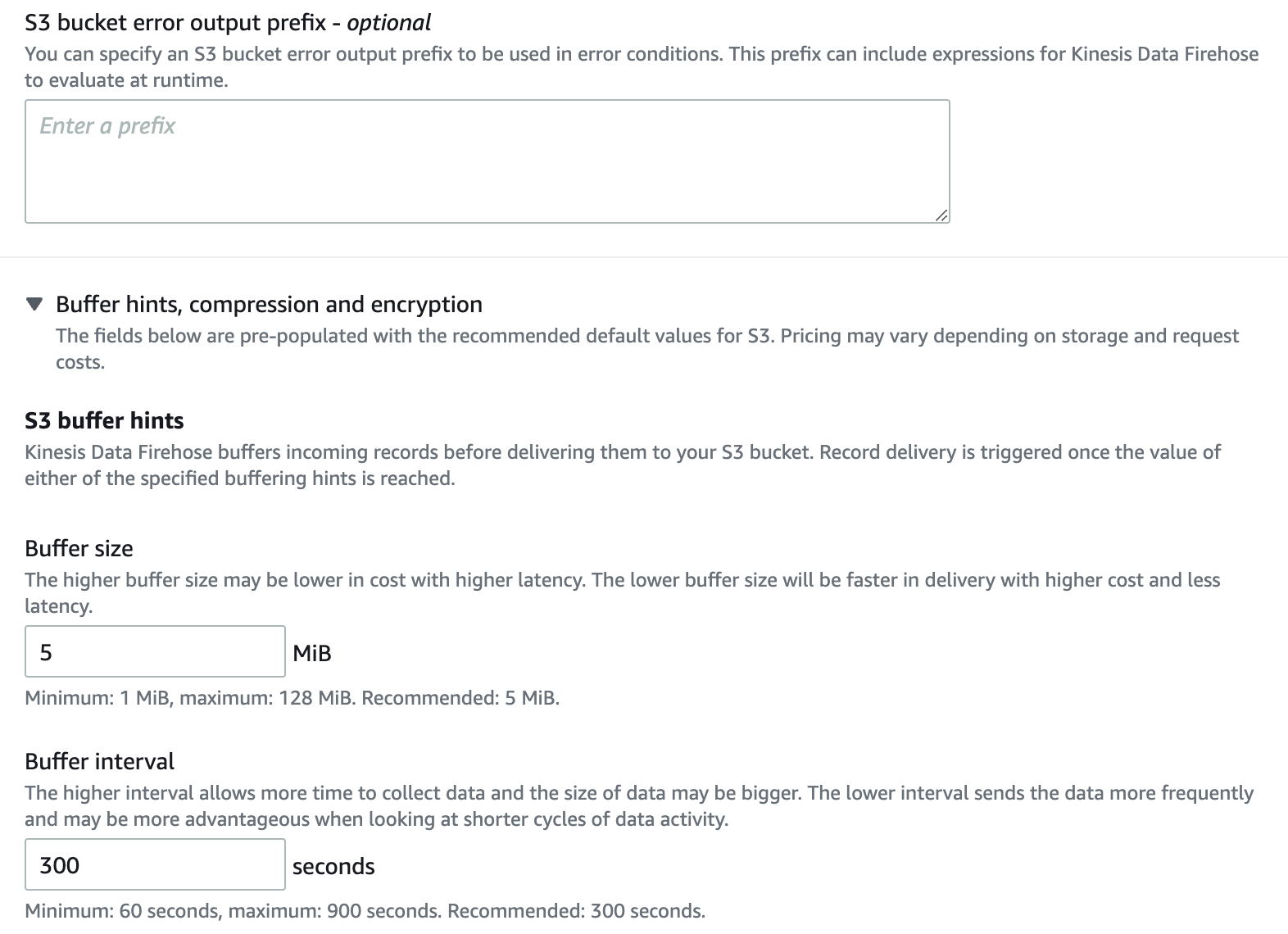
- For Compression for data records , select Disabled .
-
For
Encryption for data records
, select
Disabled
.
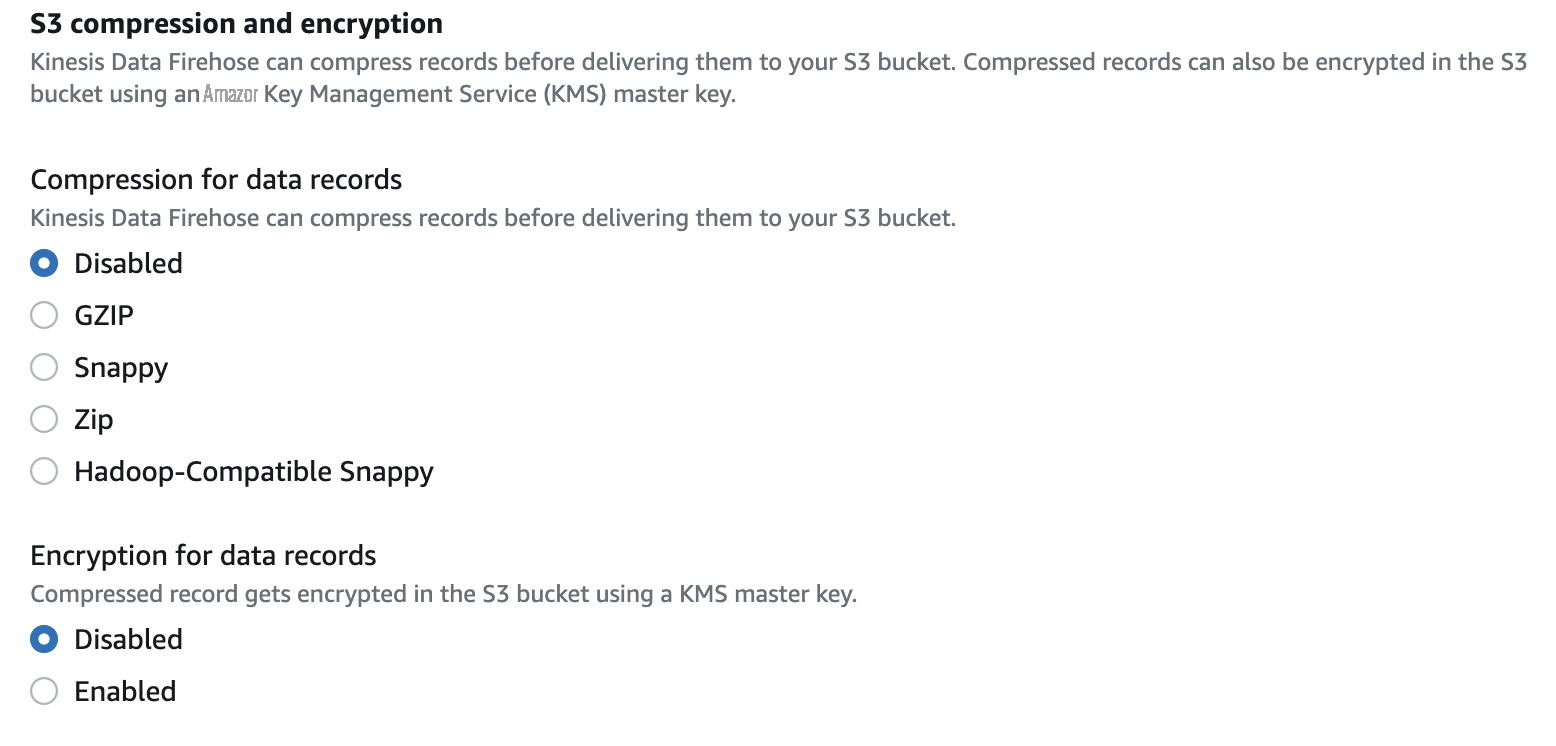
- For Source record backup in Amazon S3 , select Disabled .
-
Expand
Advanced settings
and for
Amazon CloudWatch error logging
, select
Enabled
.
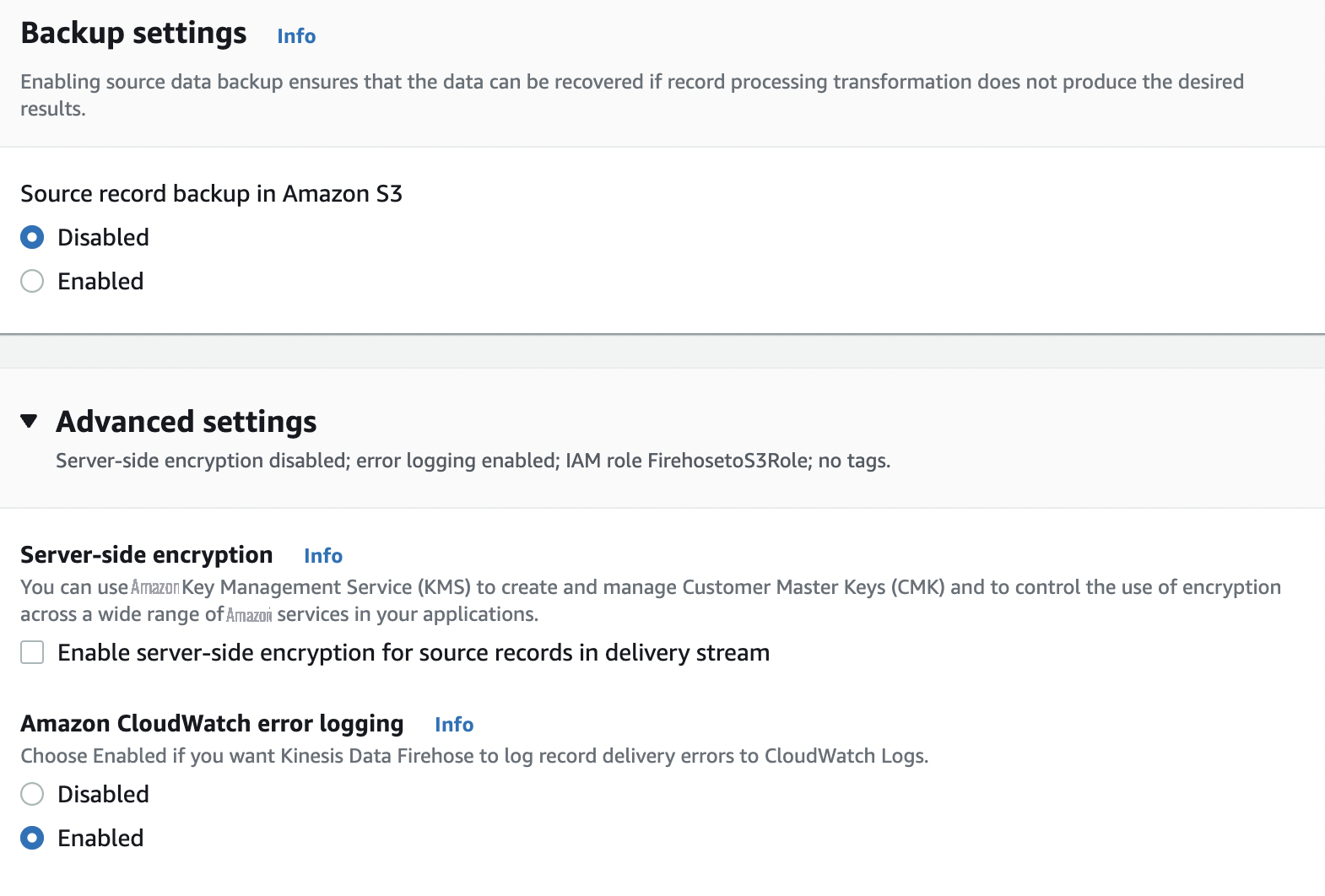
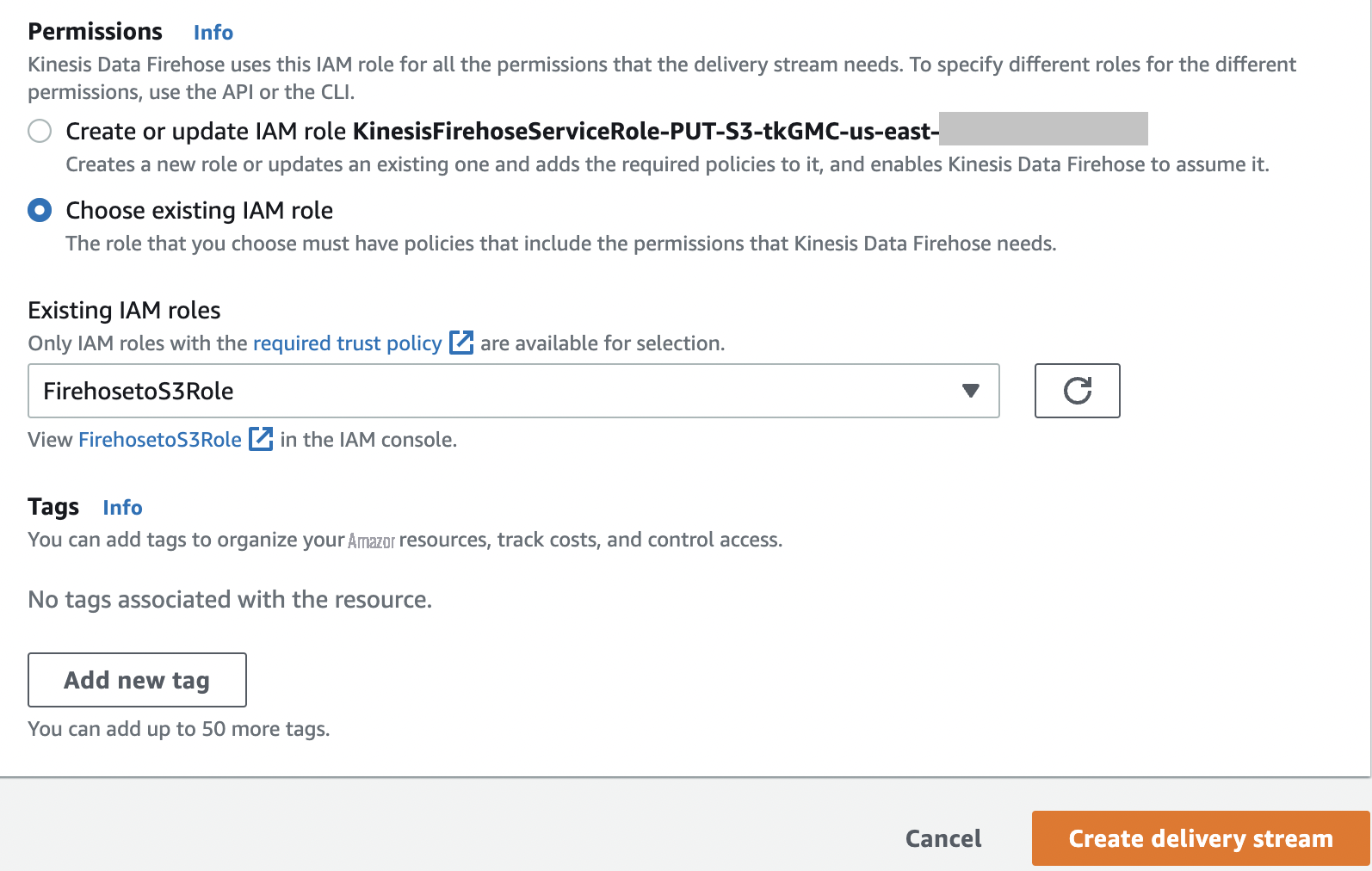
- Under Permissions , select Choose an existing role .
-
Choose the role
FirehosetoS3Role. -
Choose
Create delivery stream
.
To view your log group, choose
Log groups
in the CloudWatch console navigation pane. The CloudWatch log groups have an audit file; for example,
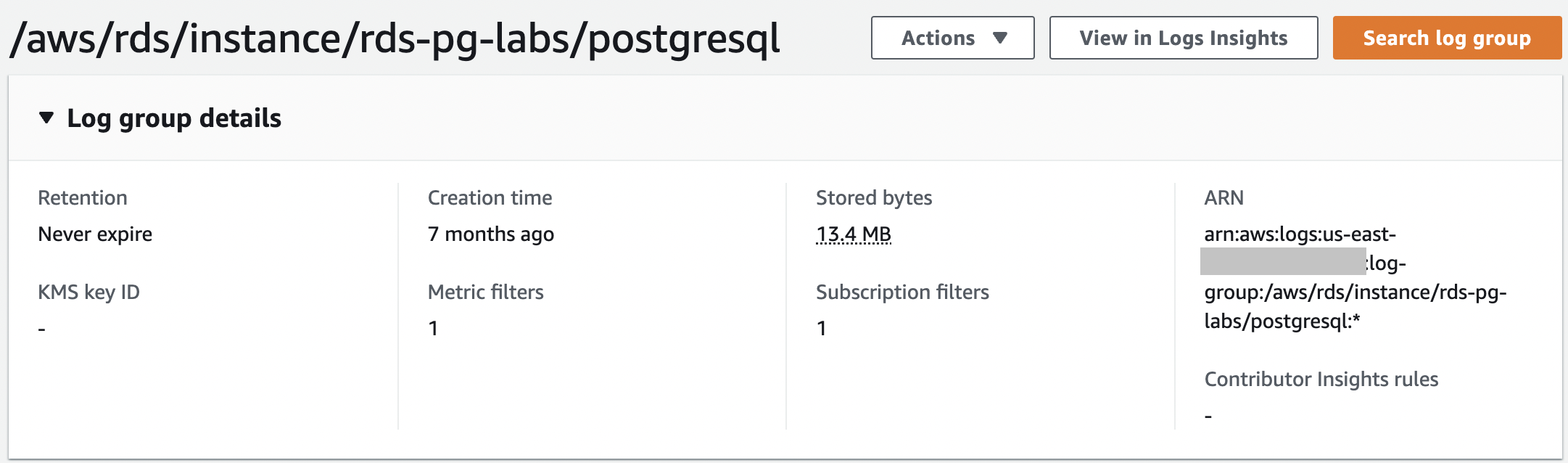
Create a subscription filter
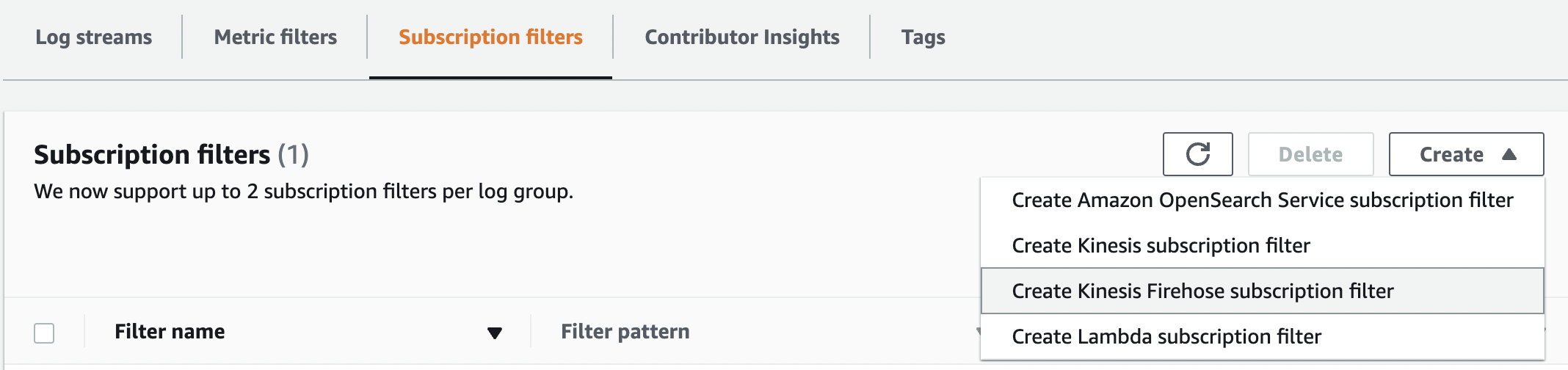
To create your Kinesis Data Firehose subscription filter, complete the following steps:
- On the Kinesis Data Firehose console, navigate to the Subscription filters tab.
-
On the
Create
menu, choose
Create Kinesis Firehose subscription filter
.
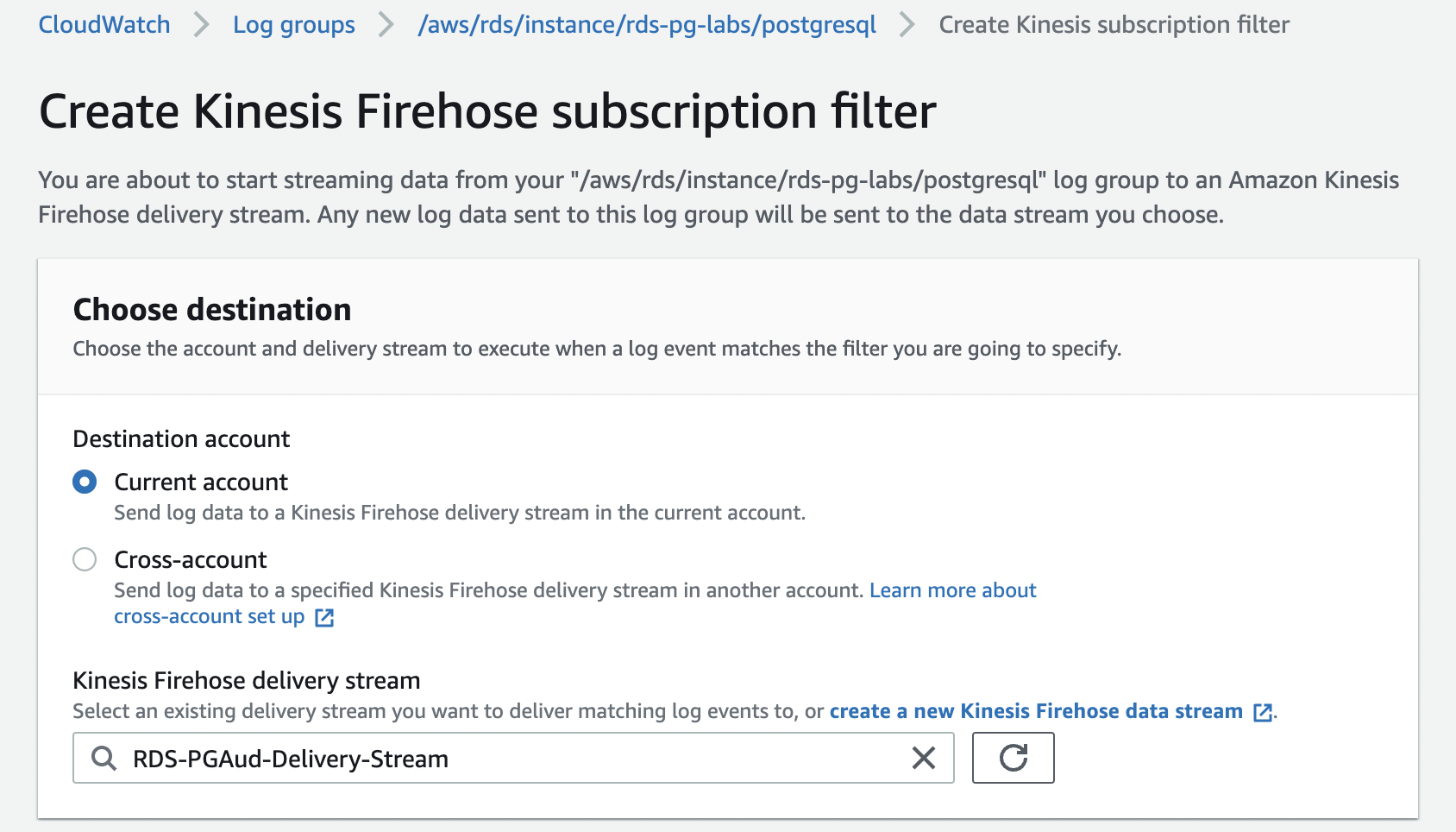
- For Destination account , select Current account .
-
For
Kinesis Firehose delivery stream
, enter the name of your delivery stream.
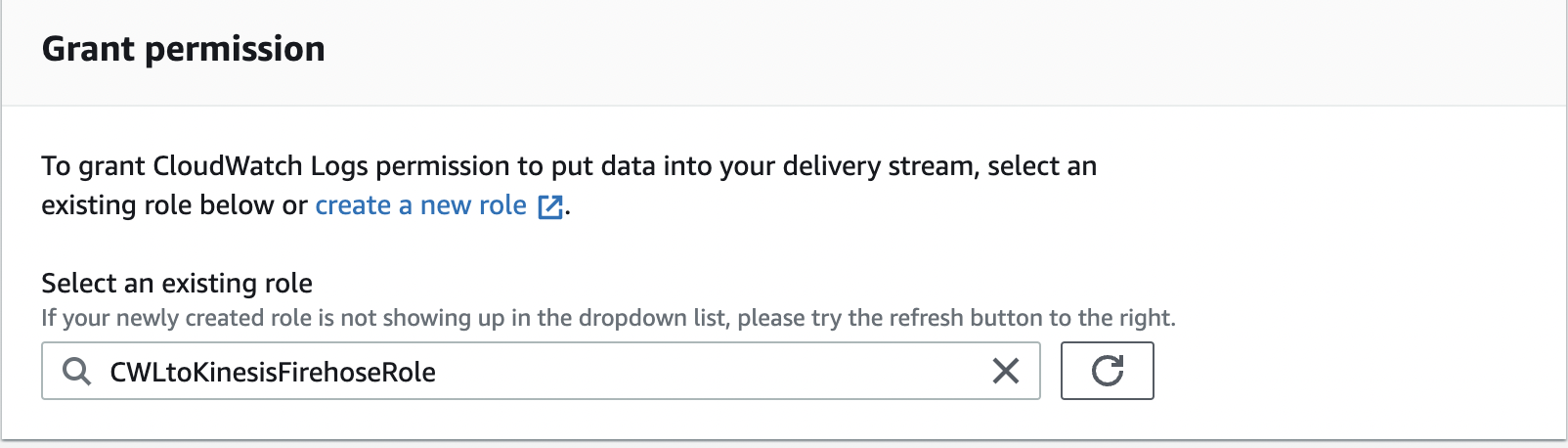
-
For
Select an existing role
, choose the role
CWLtoKinesisFirehoseRole.
- For Log format ¸ choose Other .
-
For
Subscription filter pattern
, enter
AUDIT. -
For
Subscription filter name
, enter a name.
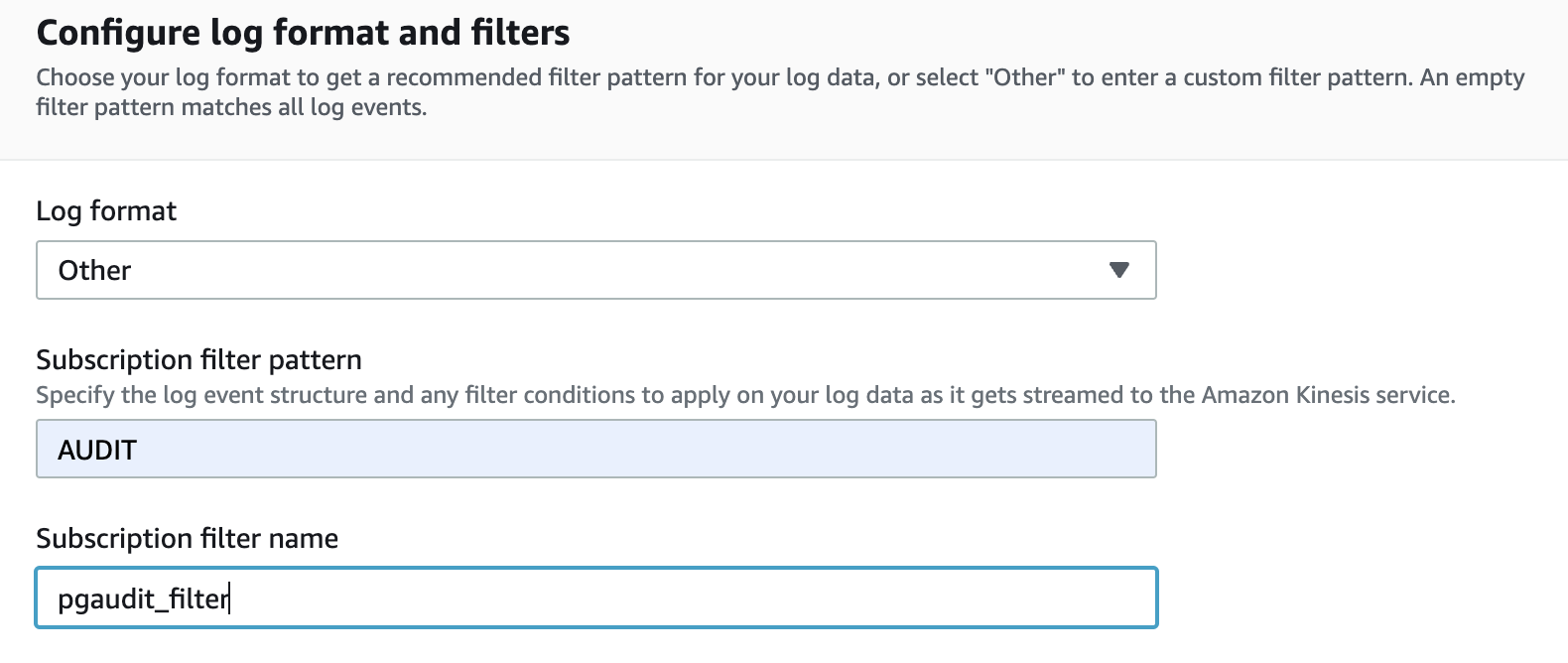
- For Log event messages , enter your log data.
-
Choose
Start streaming
.
Set up an Amazon Web Services Glue database, crawler, and table
You should now have your CloudWatch metrics stream configured and metrics flowing to your S3 bucket. In this step, we configure the Amazon Web Services Glue database, crawler, table, and table partitions.
-
On the Amazon Web Services Glue
console , choose Add database . -
Enter a name for your database, such as
pgaudit_db.
Now that we have our Amazon Web Services Glue database in place, we set up the crawler. - In the navigation pane, choose Crawlers .
- Choose Add crawler .
-
Enter a name for your crawler, such as
pgaudit_crawler. - Choose Next .
- For Add a data store , choose S3.
- For Include path , enter the S3 path to the folders or files that you want to crawl.
- Choose Next .
- For Add another data store , choose No .
- For Choose IAM role , choose an existing role with the necessary permissions or let Amazon Web Services Glue create a role for you.
-
In the
Create a schedule for this crawler
section, for
Frequency
, choose
Daily
.
You can also choose to run the crawler on demand. - Enter your start hour and minute information.
- Choose Next .
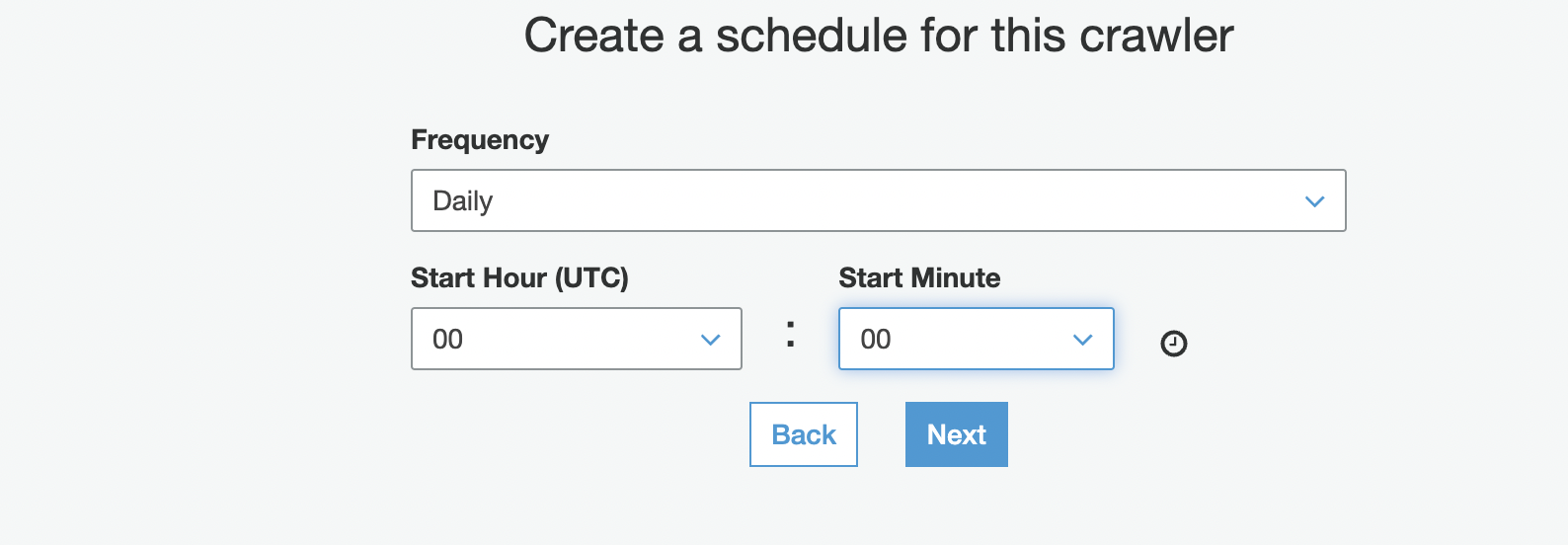
For more information about configuring crawlers, see
When this crawler runs, it automatically creates an Amazon Web Services Glue table. It also creates the table schema and partitions based on the folder structure in the S3 bucket.
Run Athena queries to identify database performance issues
Now that we have created a database and table using Amazon Web Services Glue, we’re ready to analyze and find useful insights about our database. We use Athena to run SQL queries to understand the usage of the database and identify underlying issues, if any. Athena is a serverless interactive query service that makes it easy to analyze data using standard SQL. You pay only for the queries that you run. For more information, refer to
To test our solution, run the following query:
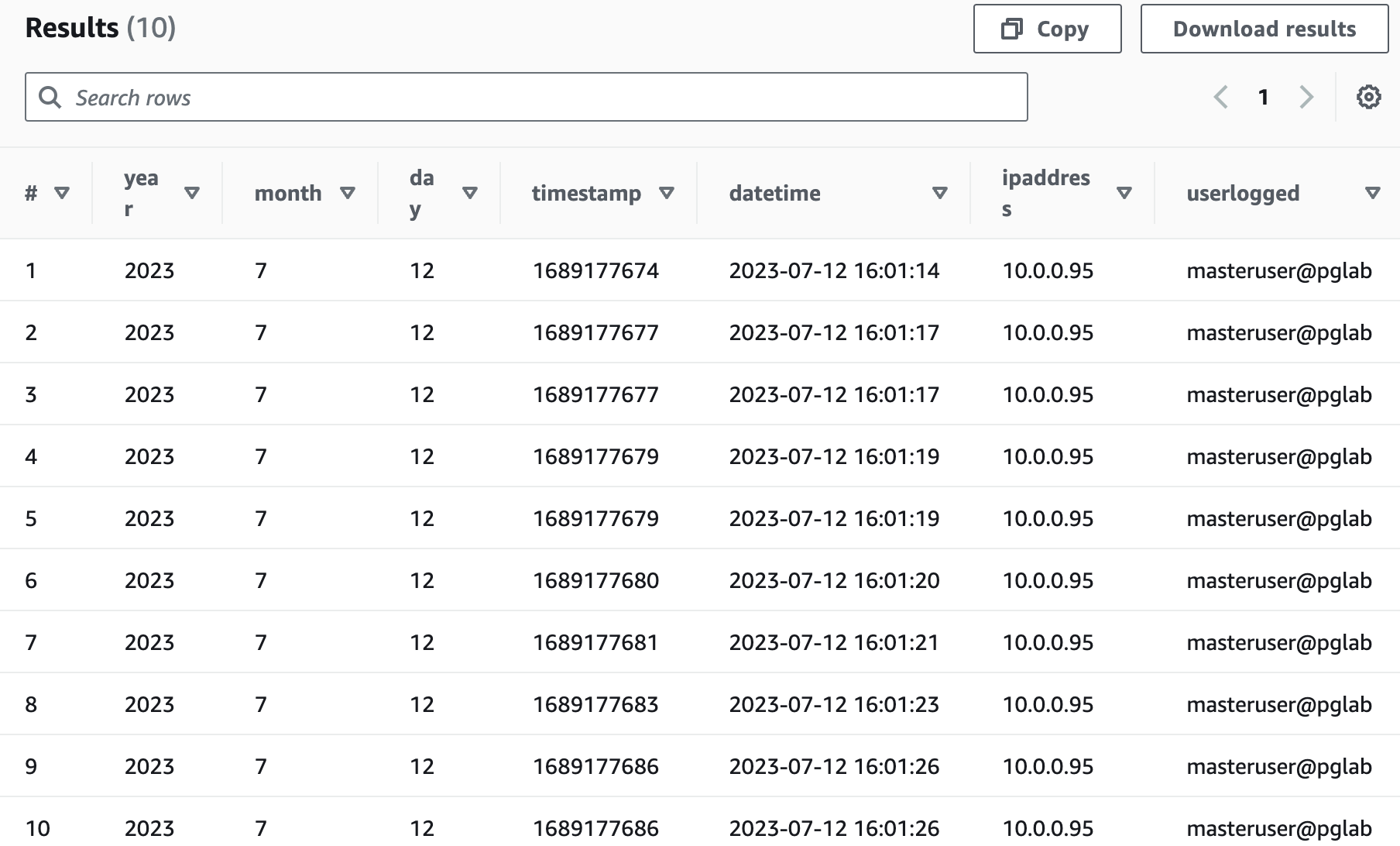
Run the following query:
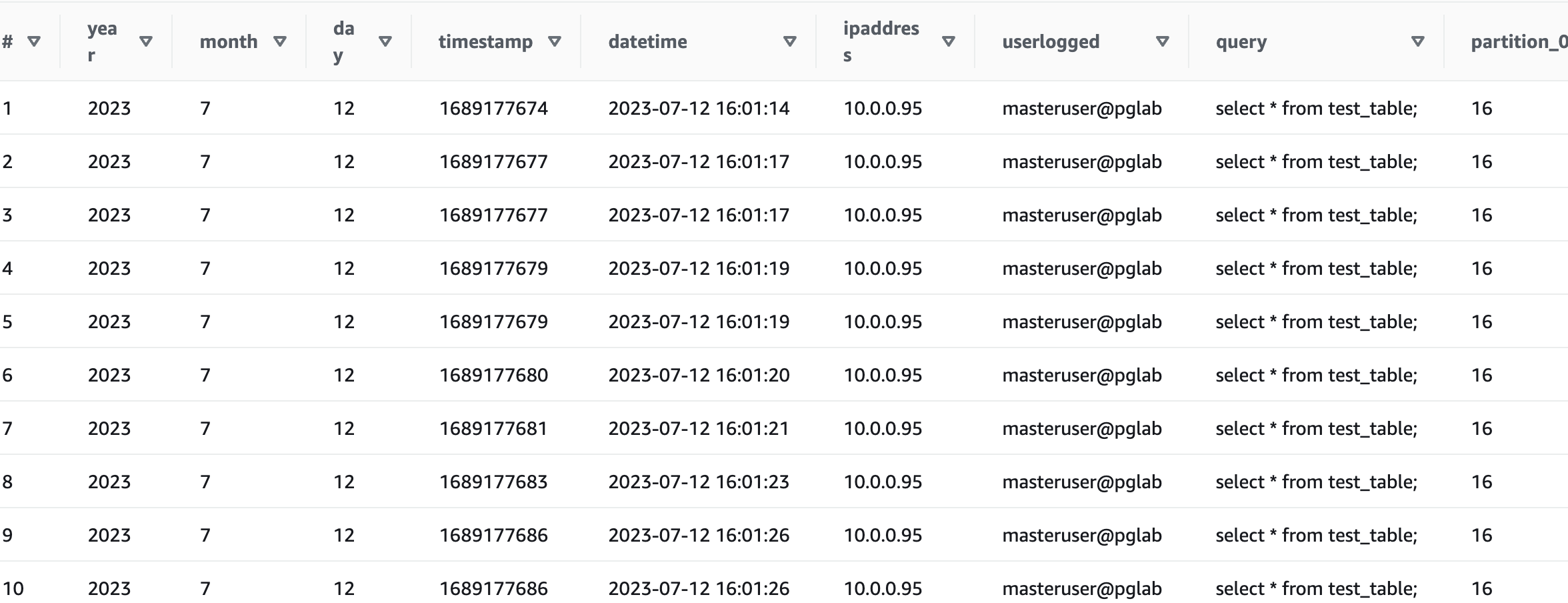
Clean up
To avoid ongoing costs, delete the resources you created as part of this post.
-
Delete the IAM role . - Delete the Lambda function.
-
Delete the S3 bucket . -
Delete the RDS for PostgreSQL instance . - Delete the Firehose delivery stream.
-
Delete the Amazon Web Services Glue database .
Conclusion
In this post, we demonstrated how you can capture and store audit data from RDS for PostgreSQL databases and store it in Amazon S3, process it using Amazon Web Services Glue, and query it using Athena. This solution can help you generate reports for auditing. This solution also works for
If you have any comments or questions about this post, share them in the comments.
About The Authors
 Kavita Vellala
is a Senior Database Consultant with Amazon Web Services and brings vast experience of database technologies. Kavita has worked on the database engines like Oracle, SQL Server, PostgreSQL, MySQL, Couchbase and Amazon Redshift. At Amazon Web Services, she helps empower customers with their digital transformation and accelerate migration of their database workload to the Amazon Web Services Cloud. She enjoys adapting innovative AI and ML technologies to help companies solve new problems, and to solve old problems more efficiently and effectively.
Kavita Vellala
is a Senior Database Consultant with Amazon Web Services and brings vast experience of database technologies. Kavita has worked on the database engines like Oracle, SQL Server, PostgreSQL, MySQL, Couchbase and Amazon Redshift. At Amazon Web Services, she helps empower customers with their digital transformation and accelerate migration of their database workload to the Amazon Web Services Cloud. She enjoys adapting innovative AI and ML technologies to help companies solve new problems, and to solve old problems more efficiently and effectively.
 Sharath Lingareddy
is Sr. Database Architect with the Professional Services team at Amazon Web Services. He has provided solutions using Oracle, PostgreSQL, MySQl DynamoDB, Amazon RDS and Aurora. His focus area is homogeneous and heterogeneous migrations of on-premise databases to Amazon RDS and Aurora PostgreSQL.
Sharath Lingareddy
is Sr. Database Architect with the Professional Services team at Amazon Web Services. He has provided solutions using Oracle, PostgreSQL, MySQl DynamoDB, Amazon RDS and Aurora. His focus area is homogeneous and heterogeneous migrations of on-premise databases to Amazon RDS and Aurora PostgreSQL.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.