We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Working with percolators in Amazon OpenSearch Service
A typical workflow for OpenSearch is to store documents (as JSON data) in an index, and execute searches (also JSON) to find those documents. Percolation reverses that. You store searches and query with documents . Let’s say I’m searching for a house in Chicago that costs < 500K. I could go to the website every day and run my query. A clever website would be able to store my requirements (a query) and notify me when something new (a document) comes up that matches my requirements. Percolation is an OpenSearch feature that enables the website to store these queries and run documents against them to find new matches.
In this post, We will explore how to use percolators to find matching homes from new listings.
Before getting into the details of percolators, let’s explore how search works. When you insert a document, OpenSearch maintains an internal data structure called the “
Indexing and Searching:
Let’s take the above example of a real estate application having the simple schema of type of the house, city, and the price.
- First, let’s create an index with mappings as below
- Let’s insert some documents into the index.
| ID | House_type | City | Price |
| 1 | townhouse | Chicago | 650000 |
| 2 | house | Washington | 420000 |
| 3 | condo | Chicago | 580000 |
- As we don’t have any townhouses listed in Chicago for less than 500K, the below query returns no results.
If you’re curious to know how search works under the hood at high level, you can refer to this
Percolation:
If one of your customers wants to get notified when a townhouse in Chicago is available, and listed at less than $500,000, you can store their requirements as a query in the percolator index. When a new listing becomes available, you can run that listing against the percolator index with a _percolate query. The query will return all matches (each match is a single set of requirements from one user) for that new listing. You can then notify each user that a new listing is available that fits their requirements. This process is called percolation in OpenSearch.
OpenSearch has a dedicated data type called “
Let’s create a percolator index with the same mapping, with additional fields for query and optional metadata. Make sure you include all the necessary fields that are part of a stored query. In our case, along with the actual fields and query, we capture the customer_id and priority to send notifications.
After creating the index, insert a query as below
The percolation begins when a new document gets run against the stored queries.
Run the percolation query with document(s), and it matches the stored query
The above query returns the queries along with the metadata we stored (customer_id in our case) that matches the documents
Percolation at scale
When you have a high volume of queries stored in the percolator index, searching queries across the index might be inefficient. You can consider segmenting your queries and use them as filters to handle the high-volume queries effectively. As we already capture priority, you can now run percolation with filters on priority that reduces the scope of matching queries.
Best practices
- Prefer the percolation index separate from the document index. Different index configurations, like number of shards on percolation index, can be tuned independently for performance.
- Prefer using query filters to reduce matching queries to percolate from percolation index.
-
Consider using a buffer in your ingestion pipeline for reasons below,
- You can batch the ingestion and percolation independently to suit your workload and SLA
-
You can prioritize the ingest and search traffic by running the percolation at off hours. Make sure that you have enough storage in the buffering layer.
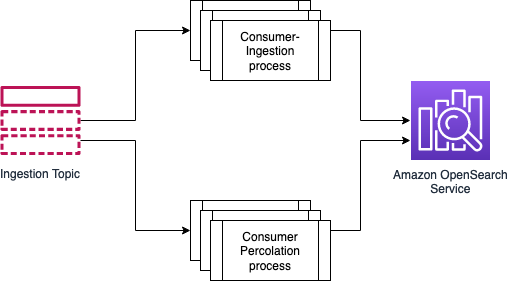
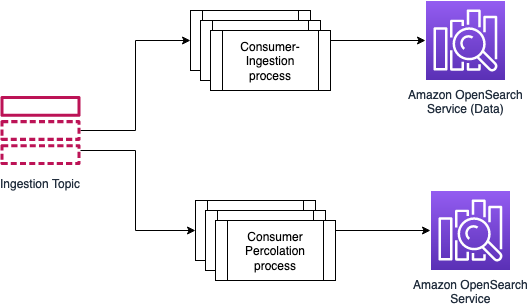
- Consider using an independent cluster for percolation for the below reasons,
-
- The percolation process relies on memory and compute, your primary search will not be impacted.
-
You have the flexibility of scaling the clusters independently.
Conclusion
In this post, we walked through how percolation in OpenSearch works, and how to use effectively, at scale. Percolation works in both managed and serverless versions of OpenSearch. You can follow the
If you have feedback about this post, submit your comments in the comments section.
About the author
 Arun Lakshmanan
is a Search Specialist with Amazon OpenSearch Service based out of Chicago, IL. He has over 20 years of experience working with enterprise customers and startups. He loves to travel and spend quality time with his family.
Arun Lakshmanan
is a Search Specialist with Amazon OpenSearch Service based out of Chicago, IL. He has over 20 years of experience working with enterprise customers and startups. He loves to travel and spend quality time with his family.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.