We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Venmo’s process of migrating to Amazon DocumentDB (with MongoDB compatibility)
This is a guest post authored by Kushal Shah, Member of Technical Staff 2, Database Engineer at PayPal Inc., and Puneeth Melavoy, Senior Software Engineer at Venmo. The content and opinions in this post are those of the third-party author.
Refer
But we’re just getting started. We want to take that magic of sending money with Venmo and cascade it into every place where people use money. That means connecting people to their money in the most intuitive and fun way possible, and then connecting people with each other.
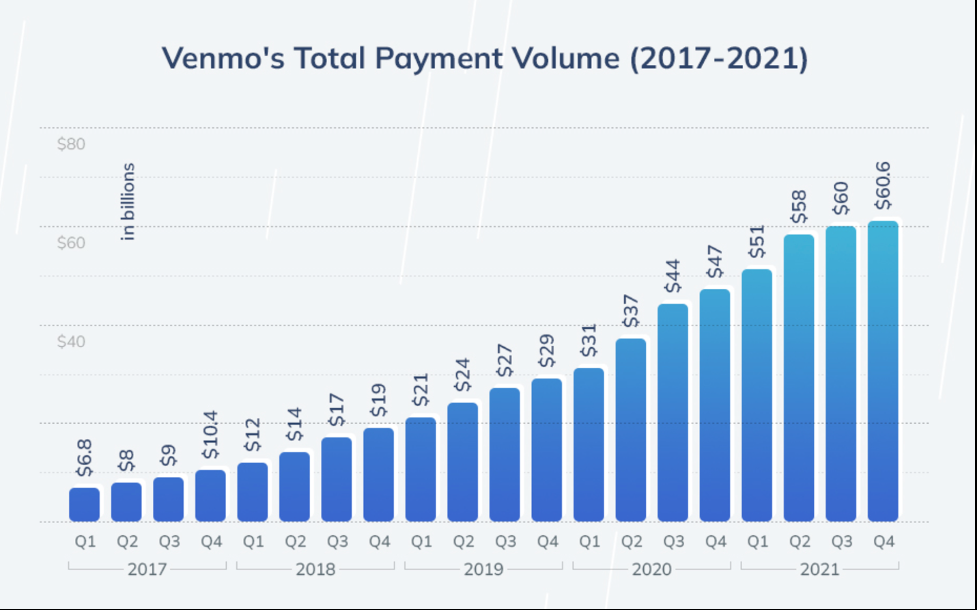
Venmo had 44% YoY Total Payment Volume growth in 2021. Traffic growth and new product features resulted in many scalability challenges, including for our data stores. One of these data stores was MongoDB, which plays a key role in our application stack, because it’s being used for customer-facing use cases like payment transaction risk analysis as well as internal tools like a customer support portal.
With growth and the deployment of new features, we had to scale our existing document database cluster both horizontally and vertically from time to time. To be prepared for additional growth and to give the best performance to our users, we started investigating solutions for scale. Some of the options we considered were:
- Implementing sharding for some of our biggest collections on MongoDB and scale horizontally
- Migrating collections to another key-value store
Both options would require some remodeling and, after considering all the factors, we decided to migrate 35 collections to
- Application and functional compatibility
- Data migration strategy
- Cutover planning
- Rollback strategy
In this post, we discuss in detail our approach of migrating 35 collections from our source document database to Amazon DocumentDB with almost zero downtime. In this post, we share our migration strategy, the challenges we faced, and lessons learned.
Application and functional compatibility
For any migration from one data store to another, it’s important to research and validate application requirements and logic to determine if updates or workarounds are needed for any functionality. Since Amazon DocumentDB is compatible with the Apache 2.0 open source MongoDB 3.6,
For our usage, the only update we had to make was for sparse indexes. Amazon DocumentDB supports sparse indexes, but requires the
$exists
clause on the fields the index covers. If you omit
$exists
, Amazon DocumentDB doesn’t use the sparse index. Because of this, we either modified our application code to use the
$exists
clause in the queries or updated the index type.
Data migration strategy
Before starting the data migration, we created the new collections in Amazon DocumentDB as well as pre-created indexes using the
For most of the collections, the online migration approach worked well for us. In this approach, we used
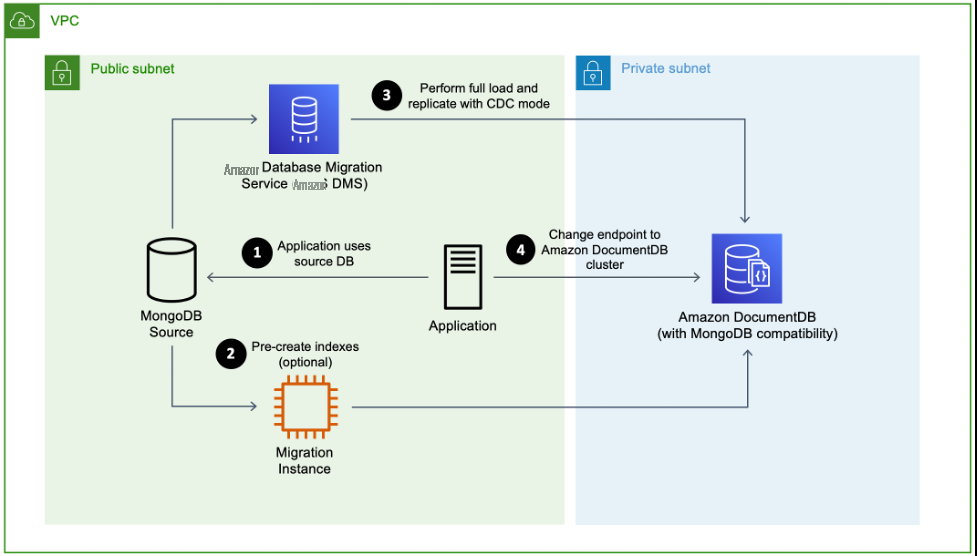
Online Migration Approach
The following diagram illustrates the hybrid migration migration approach and its workflow.
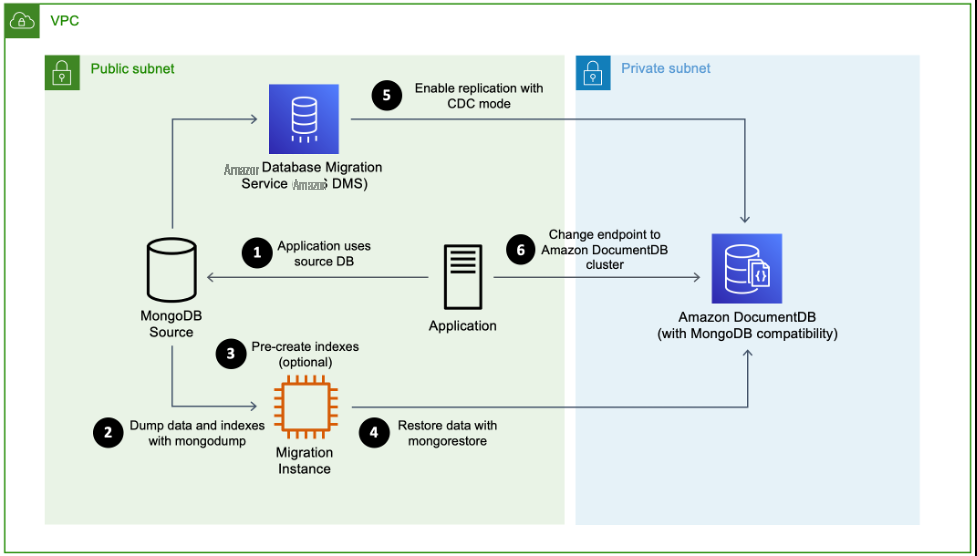
Hybrid Migration Approach
Cutover planning
Amazon DocumentDB uses a different underlying implementation than other document databases and can exhibit different performance characteristics. We verified that we don’t use any of the cases specifically called out as not being supported on Amazon DocumentDB, but we still wanted to guard against performance regressions in the migration. Although we ran our performance tests against Amazon DocumentDB for both read and write scenarios, the performance tests environment doesn’t have 100% coverage of our functionality. There is a possibility of read regressions, so we ramped up reads early and separately to guard against this.
Since we decided to ramp reads first, we needed to be aware of any read-after-write use cases and impact on these use cases due to data latency between the source and Amazon DocumentDB. Based on the read use case requirement, we divided the collections into two different scenarios:
- Collections with no read-after-write use case
- Collections with read-after-write use case
Based on the scenario the collections fell under, we used a different cutover strategy. Also, instead of migrating all the collections at one time, we gradually migrated collections in groups of 3–5 collections at a time.
Collections with no read-after-write use case
66% of the collections fell under this scenario, where the collection either didn’t have a read-after-write use case, or the data latency between the source and Amazon DocumentDB via the Amazon Web Services DMS pipeline was within the required SLA (Service Level Agreement) for the respective collection.
For these collections, we first migrated all the read traffic to Amazon DocumentDB to validate any performance regressions on Amazon DocumentDB before the cutover of write traffic to Amazon DocumentDB. For validating read performance, we relied on metrics like read latency, average query runtime, and others. After validating read performance, we cut over write traffic to Amazon DocumentDB. The following diagram illustrates this process.
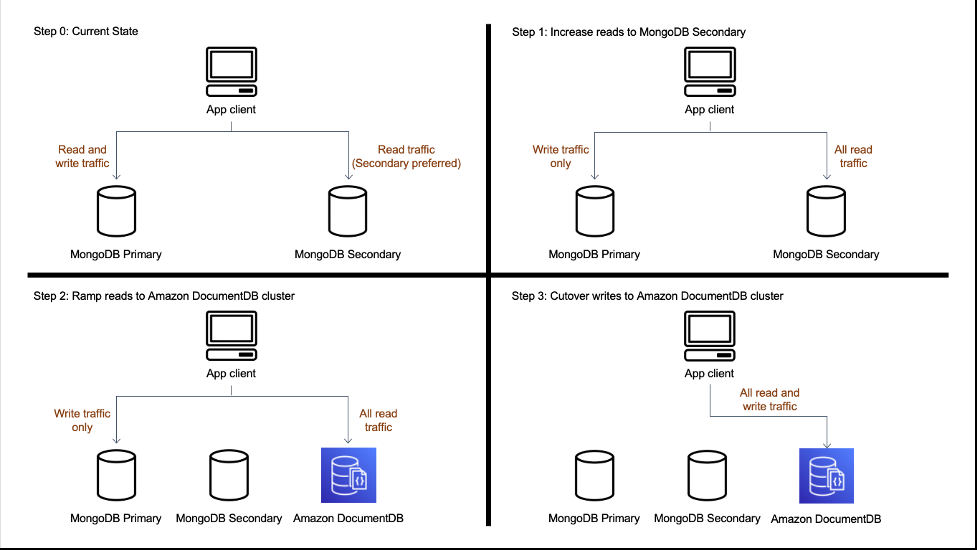
Scenario 1
Collections with read-after-write use case
34% of the collections fell under this scenario, where the collection either had a read-after-write use case, or the replication lag between the source and Amazon DocumentDB via the Amazon Web Services DMS pipeline was a bit higher than the required SLA for the respective collection.
For these collections, we first only migrated 1% of read traffic to Amazon DocumentDB. Doing this introduced the prospect of inconsistent reads after writes, but we accepted that in order to get full read performance regression coverage. After validating read performance, we cut over the remaining read and write traffic to Amazon DocumentDB simultaneously because of the read-after-write constraint. The following diagram illustrates this process.
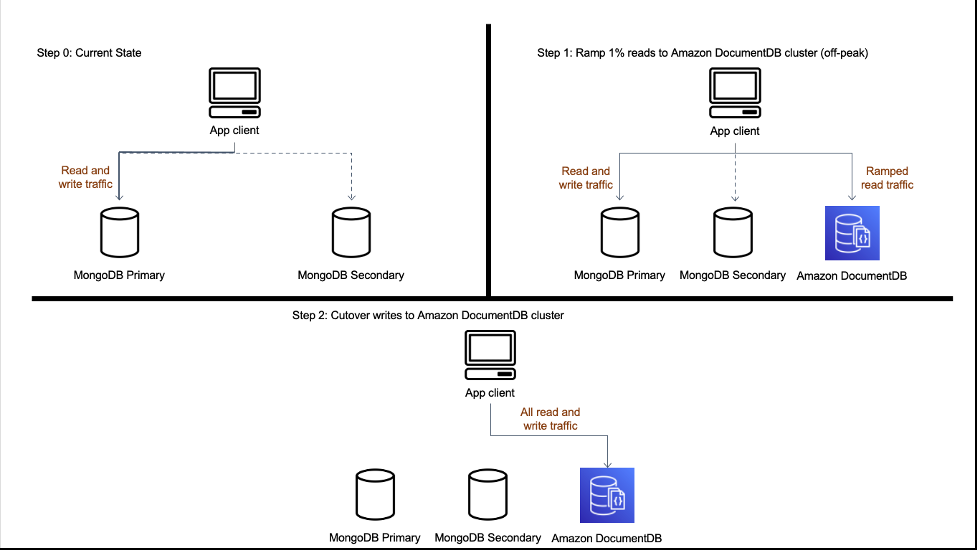
Scenario 2
For two of the collections, we had to stay away from ramping up 1% read traffic to Amazon DocumentDB because we had observed a comparatively high number of errors during our testing. For those two collections, we performed extensive testing for validating read performance in the non-production environment and simultaneously migrated 100% of read and write traffic to Amazon DocumentDB.
By splitting the collections into different cutover scenarios, we were able to cut over all the collection traffic to Amazon DocumentDB without any observed impact to customer-facing applications. Furthermore, we didn’t observe any impact to internal tools that rely on these collections.
Rollback strategy
For any data store migration, it’s particularly important to have a rollback strategy for any unforeseen circumstances. For example, when having a runbook to cut over from your source database to Amazon DocumentDB, you should also have a fully tested and validated runbook to roll back from Amazon DocumentDB to your source database.
We used Amazon Web Services DMS to replicate data from the source to Amazon DocumentDB, but there was no such third-party tool available that could help with replicating data from Amazon DocumentDB to our source database. In case of any unforeseen functional or performance issue, if we had to roll back any collection to the source database, we needed to have all the data replicated from Amazon DocumentDB to the source.
With the lack of third-party tools, we wrote an in-house script to read data from the Amazon DocumentDB change stream and write the recent changes back to the source. We used this script to keep the data in sync from Amazon DocumentDB to the source for at least 48 hours after the write traffic cutover.
Summary
With the migration approach discussed in this post, we were successfully able to migrate all 35 collections from the source database to Amazon DocumentDB with almost zero downtime. By migrating this workload to Amazon DocumentDB, Venmo was able to reduce overall cost by 50%.
If you have any comments or feedback, leave them in the comments section.
About the authors


 Jigar Mandli
is a Senior Technical Account Manager at Amazon Web Services. As part of the Amazon Web Services Enterprise support team, he helps customers plan and build solutions using best practices and keep their environments operationally healthy.
Jigar Mandli
is a Senior Technical Account Manager at Amazon Web Services. As part of the Amazon Web Services Enterprise support team, he helps customers plan and build solutions using best practices and keep their environments operationally healthy.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.