We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Use the reverse token filter to enable suffix matching queries in OpenSearch
In this post, we show how you can implement a suffix-based search. To find a document with the movie name “saving private ryan” for example, you can use the prefix “saving” with a prefix-based query. Occasionally, you also want to match suffixes as well, such as matching “Harry Potter Goblet of Fire” with the suffix “Fire” To do that, first reverse the string “eriF telboG rettoP yrraH” with the
Solution overview
Text analysis involves transforming unstructured text, such as the content of an email or a product description, into a structured format that is finely tuned for effective searching. An analyzer enables the implementation of full-text search using tokenization, which entails breaking down a text into smaller fragments known as tokens, with these tokens commonly representing individual words. To implement a reversed field search, the analyzer does the following.
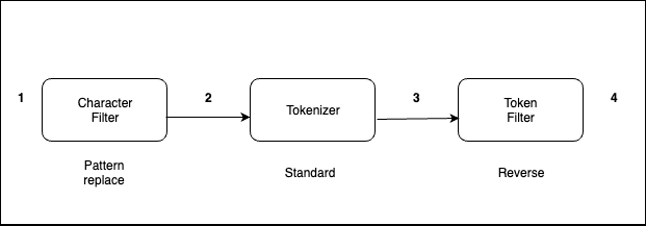
The analyzer processes text in the following order:
-
Use a character filter to replace
-with_. For example, from “My Driving License Number Is 123-456-789” to “My Driving License Number Is 123_456_789.” - The standard tokenizer splits texts into tokens. For example, from “My Driving License Number Is 123_456_789” to “[ my, driving, license, number, is, 123, 456, 789 ].”
- The reverse token filter reverses each token in a stream. For example, from [ my, driving, license, number, is, 123, 456, 789 ] to [ ym, gnivird, esnecil, rebmun, si, 321, 654, 987 ].
The standard analyzer (default analyzer) breaks down input strings into tokens based on word boundaries and removes most punctuation marks. For additional information about analyzers, refer
Indexing and searching
Every document is a collection of fields, each having its own specific data type. When you create a mapping for your data, you create a mapping definition, which contains a list of fields that are pertinent to the document. To know more about index mappings refer to
Let’s take the example of an analyzer with the reverse token filter applied on the text field.
-
First, create an index with mappings as shown in the following code. The new field ‘
reverse_title’ is derived from ‘title’ field for suffix search and original field ‘title’ will be used for normal search.
- Insert some documents into the index:
-
Run the following query to perform a suffix/reverse search on derived field ‘
reverse_title’ for “Fire”:
The following code shows our results:
-
For non-reverse search you can use original field ‘
title’.
The following code shows our result.
The query returns a document with the movie name “Harry Potter Goblet of Fire”.
If you’re curious to know how search works at high level, refer to
Conclusion
In this post, you walked through how text analysis works in OpenSearch and how to implement suffix-based search using a reverse token filter effectively.
If you have feedback about this post, submit your comments in the comments section.
About the Authors
 Bharav Patel
is a Specialist Solution Architect, Analytics at Amazon Web Services. He primarily works on Amazon OpenSearch Service and helps customers with key concepts and design principles of running OpenSearch workloads on the cloud. Bharav likes to explore new places and try out different cuisines.
Bharav Patel
is a Specialist Solution Architect, Analytics at Amazon Web Services. He primarily works on Amazon OpenSearch Service and helps customers with key concepts and design principles of running OpenSearch workloads on the cloud. Bharav likes to explore new places and try out different cuisines.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.