We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Retrain ML models and automate batch predictions in Amazon SageMaker Canvas using updated datasets
You can now retrain machine learning (ML) models and automate batch prediction workflows with updated datasets in
After the model is trained, you may want to run predictions on it. Running batch predictions on an ML model enables processing multiple data points simultaneously instead of making predictions one by one. Automating this process provides efficiency, scalability, and timely decision-making. After the predictions are generated, they can be further analyzed, aggregated, or visualized to gain insights, identify patterns, or make informed decisions based on the predicted outcomes. Canvas now supports setting up an automated batch prediction configuration and associating a dataset to it. When the associated dataset is refreshed, either manually or on a schedule, a batch prediction workflow will be triggered automatically on the corresponding model. Results of the predictions can be viewed inline or downloaded for later review.
In this post, we show how to retrain ML models and automate batch predictions using updated datasets in Canvas.
Overview of solution
For our use case, we play the part of a business analyst for an ecommerce company. Our product team wants us to determine the most critical metrics that influence a shopper’s purchase decision. For this, we train an ML model in Canvas with a customer website online session dataset from the company. We evaluate the model’s performance and, if needed, retrain the model with additional data to see if it improves the performance of the existing model or not. To do so, we use the auto update dataset capability in Canvas and retrain our existing ML model with the latest version of training dataset. Then we configure automatic batch prediction workflows—when the corresponding prediction dataset is updated, it automatically triggers the batch prediction job on the model and makes the results available for us to review.
The workflow steps are as follows:
-
Upload the downloaded customer website online session data to
Amazon Simple Storage Service (Amazon S3) and create a new training dataset Canvas. For the full list of supported data sources, refer toImporting data in Amazon SageMaker Canvas . -
Build ML models and analyze their performance metrics. Refer to the steps on how to
build a custom ML Model in Canvas andevaluate a model’s performance . - Set up auto update on the existing training dataset and upload new data to the Amazon S3 location backing this dataset. Upon completion, it should create a new dataset version.
- Use the latest version of the dataset to retrain the ML model and analyze its performance.
-
Set up
automatic batch predictions on the better performing model version and view the prediction results.
You can perform these steps in Canvas without writing a single line of code.
Overview of data
The dataset consists of feature vectors belonging to 12,330 sessions. The dataset was formed so that each session would belong to a different user in a 1-year period to avoid any tendency to a specific campaign, special day, user profile, or period. The following table outlines the data schema.
| Column Name | Data Type | Description |
Administrative
|
Numeric | Number of pages visited by the user for user account management-related activities. |
Administrative_Duration
|
Numeric | Amount of time spent in this category of pages. |
Informational
|
Numeric | Number of pages of this type (informational) that the user visited. |
Informational_Duration
|
Numeric | Amount of time spent in this category of pages. |
ProductRelated
|
Numeric | Number of pages of this type (product related) that the user visited. |
ProductRelated_Duration
|
Numeric | Amount of time spent in this category of pages. |
BounceRates
|
Numeric | Percentage of visitors who enter the website through that page and exit without triggering any additional tasks. |
ExitRates
|
Numeric | Average exit rate of the pages visited by the user. This is the percentage of people who left your site from that page. |
Page Values
|
Numeric | Average page value of the pages visited by the user. This is the average value for a page that a user visited before landing on the goal page or completing an ecommerce transaction (or both). |
SpecialDay
|
Binary | The “Special Day” feature indicates the closeness of the site visiting time to a specific special day (such as Mother’s Day or Valentine’s Day) in which the sessions are more likely to be finalized with a transaction. |
Month
|
Categorical | Month of the visit. |
OperatingSystems
|
Categorical | Operating systems of the visitor. |
Browser
|
Categorical | Browser used by the user. |
Region
|
Categorical | Geographic region from which the session has been started by the visitor. |
TrafficType
|
Categorical | Traffic source through which user has entered the website. |
VisitorType
|
Categorical | Whether the customer is a new user, returning user, or other. |
Weekend
|
Binary | If the customer visited the website on the weekend. |
Revenue
|
Binary | If a purchase was made. |
Revenue is the target column, which will help us predict whether or not a shopper will purchase a product or not.
The first step is to
Prerequisites
For this walkthrough, complete the following prerequisite steps:
- Split the downloaded CSV that contains 20,000 rows into multiple smaller chunk files.
This is so that we can showcase the dataset update functionality. Ensure all the CSV files have the same headers, otherwise you may run into schema mismatch errors while creating a training dataset in Canvas.

-
Create an S3 bucket and upload
online_shoppers_intentions1-3.csvto the S3 bucket.
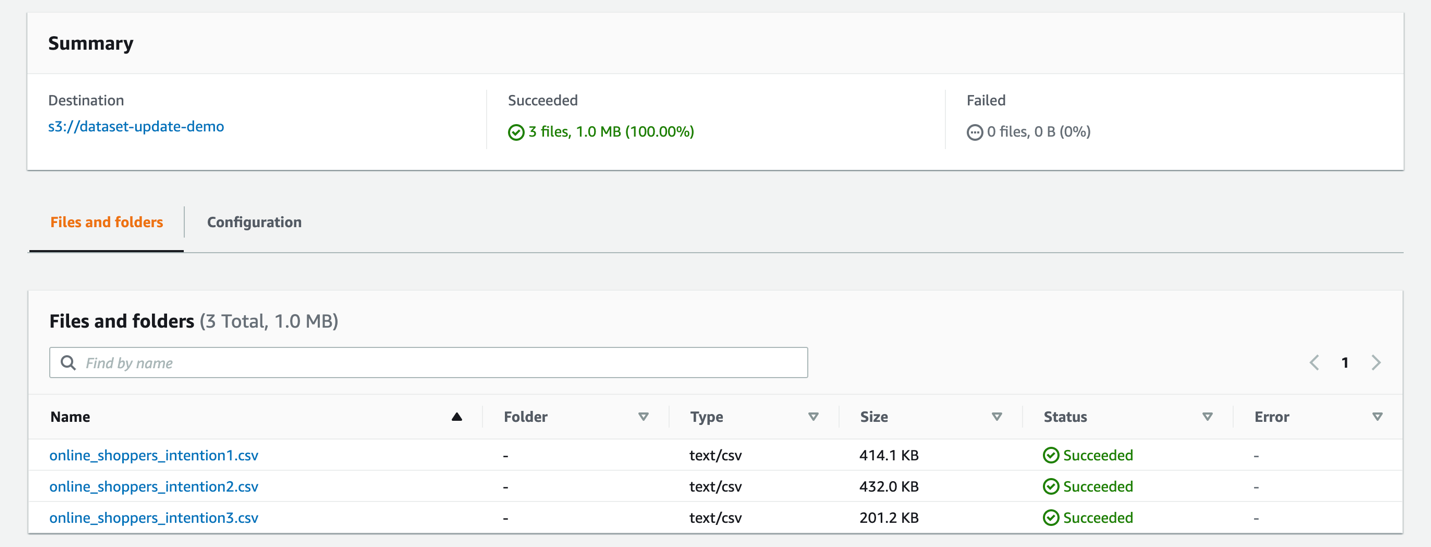
- Set aside 1,500 rows from the downloaded CSV to run batch predictions on after the ML model is trained.
-
Remove the
Revenuecolumn from these files so that when you run batch prediction on the ML model, that is the value your model will be predicting.
Ensure all the
predict*.csv
files have the same headers, otherwise you may run into schema mismatch errors while creating a prediction (inference) dataset in Canvas.

-
Perform the necessary steps to
set up a SageMaker domain and Canvas app .
Create a dataset
To create a dataset in Canvas, complete the following steps:
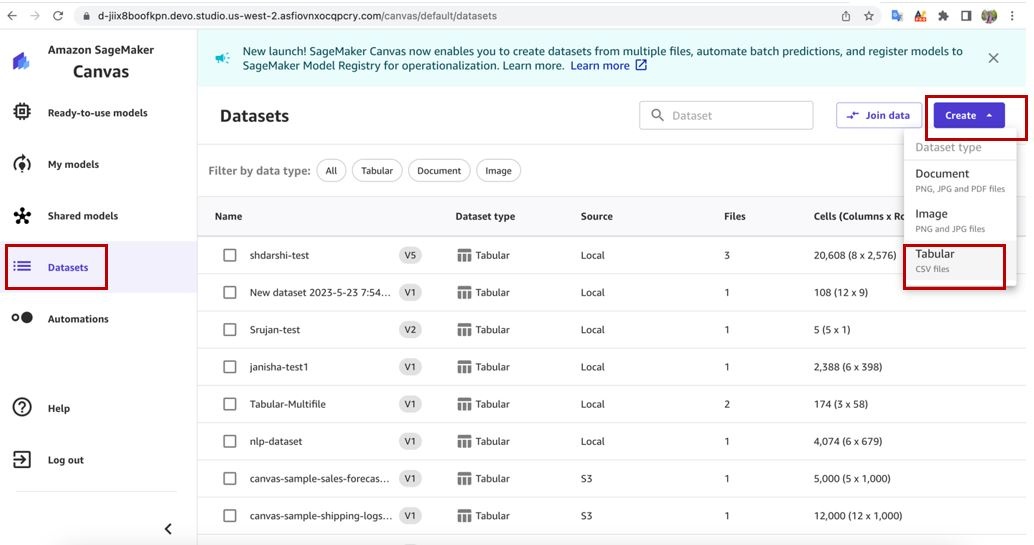
- In Canvas, choose Datasets in the navigation pane.
-
Choose
Create
and choose
Tabular
.
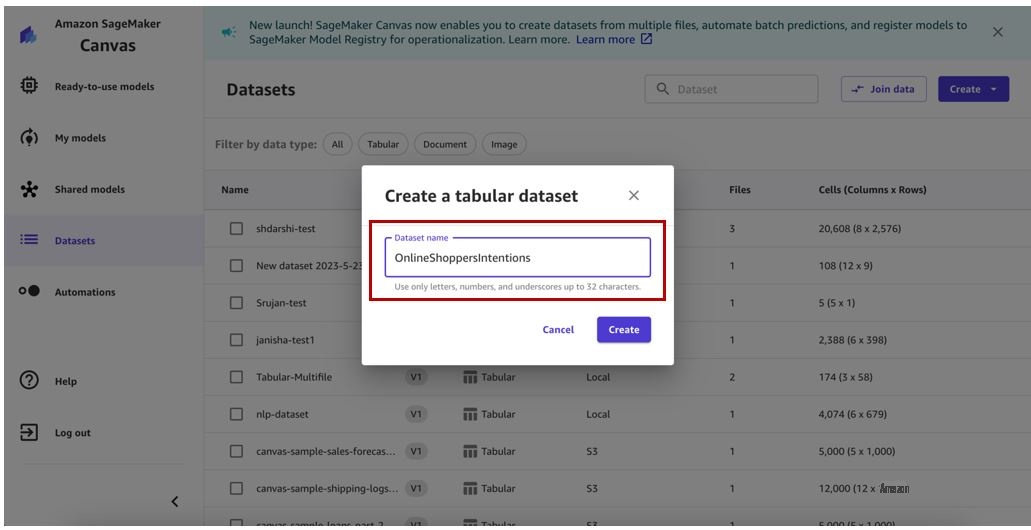
-
Give your dataset a name. For this post, we call our training dataset
OnlineShoppersIntentions. -
Choose
Create
.
- Choose your data source (for this post, our data source is Amazon S3).
Note that as of this writing, the dataset update functionality is only supported for Amazon S3 and locally uploaded data sources.
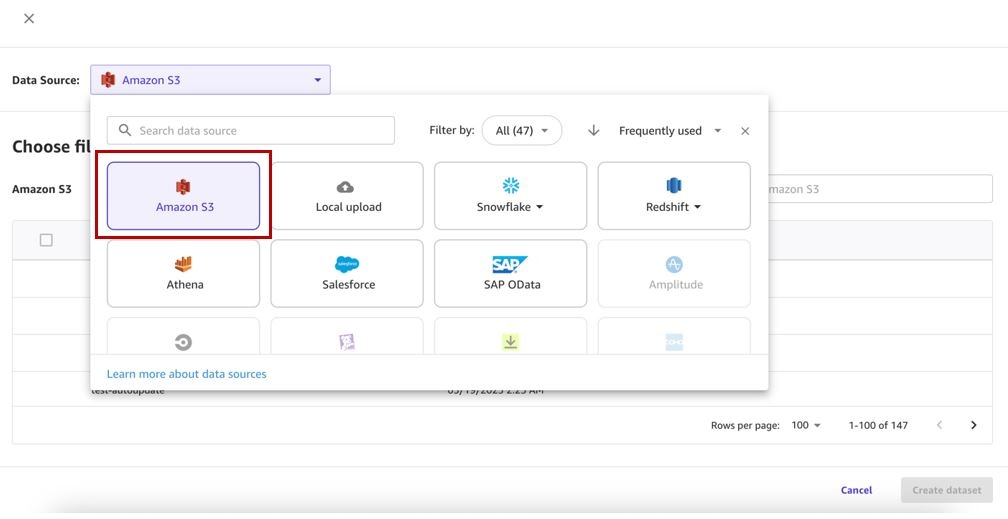
- Select the corresponding bucket and upload the CSV files for the dataset.
You can now create a dataset with multiple files.
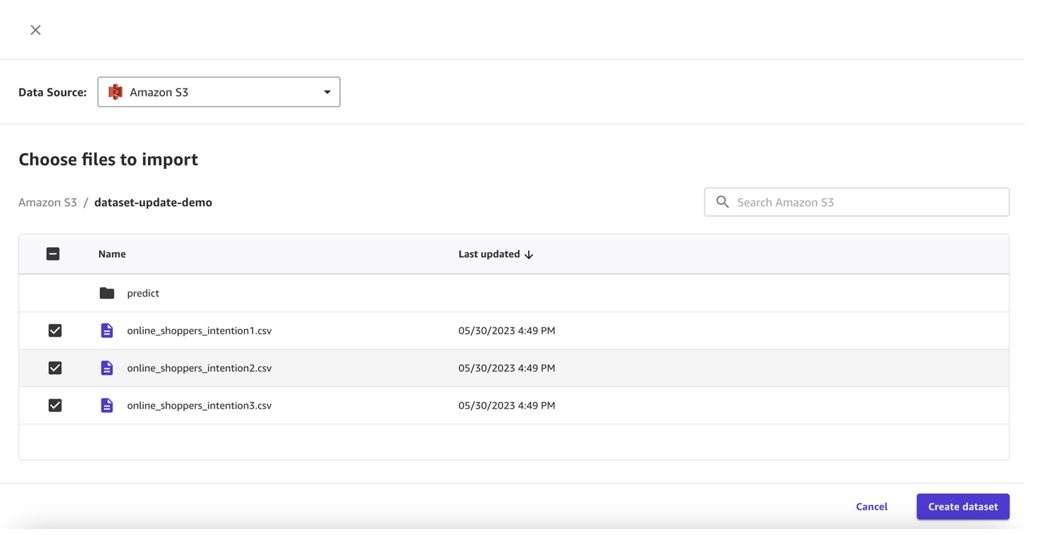
- Preview all the files in the dataset and choose Create dataset .
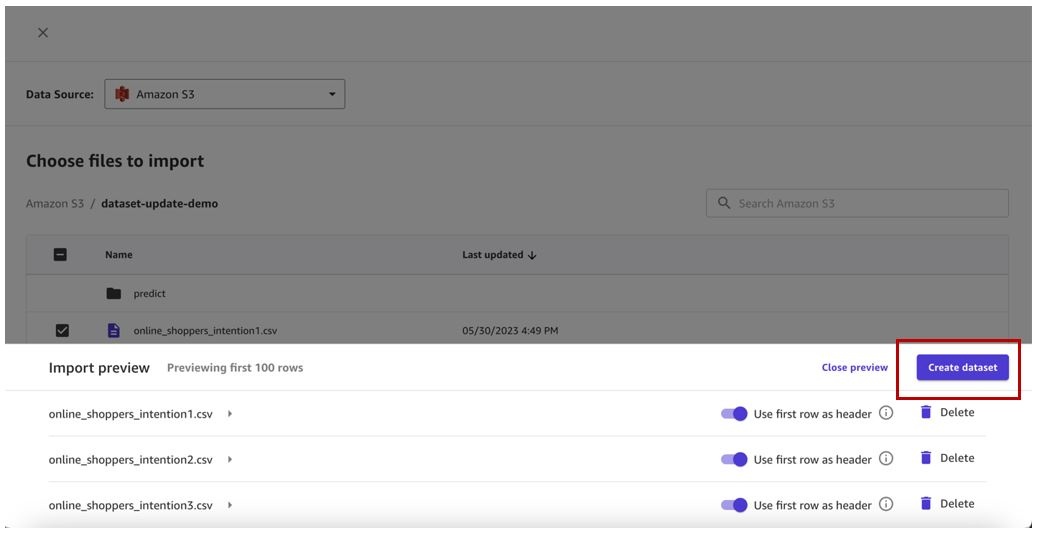
We now have version 1 of the
OnlineShoppersIntentions
dataset with three files created.
- Choose the dataset to view the details.

The Data tab shows a preview of the dataset.
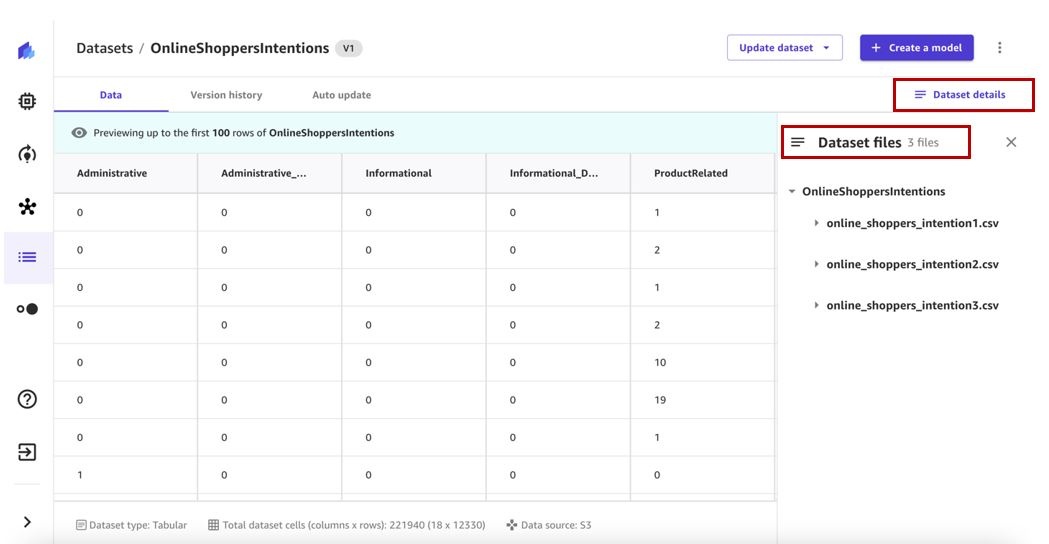
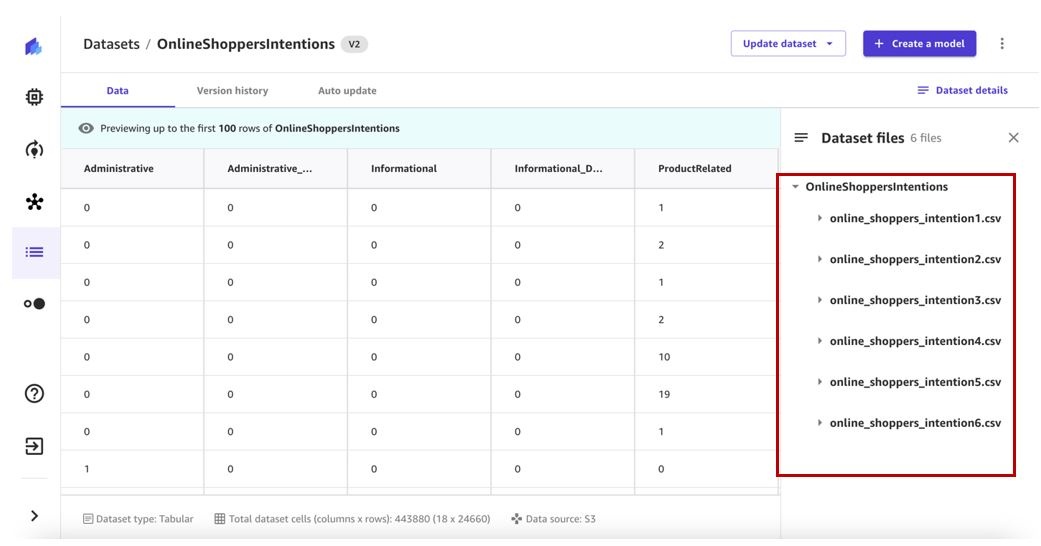
- Choose Dataset details to view the files that the dataset contains.
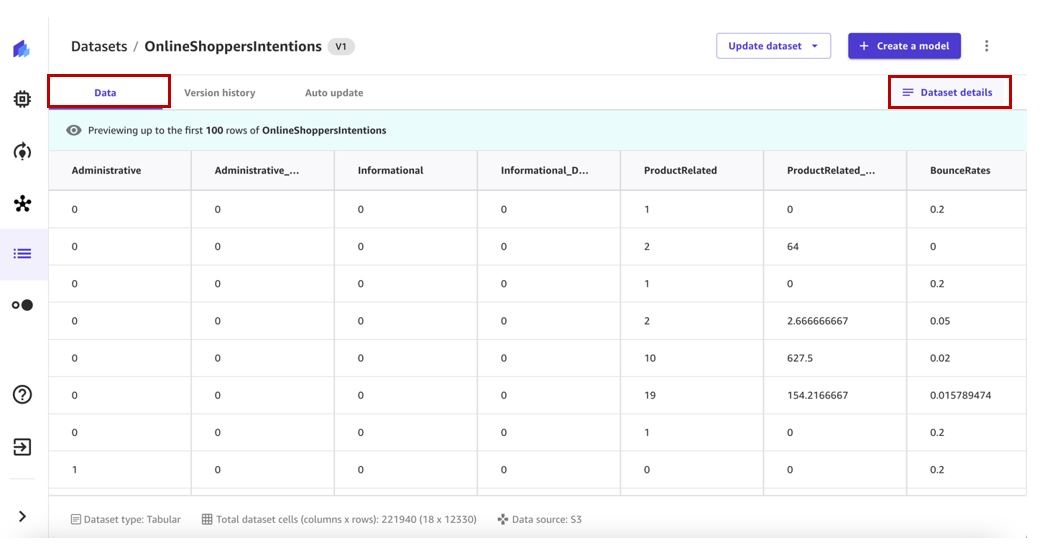
The Dataset files pane lists the available files.
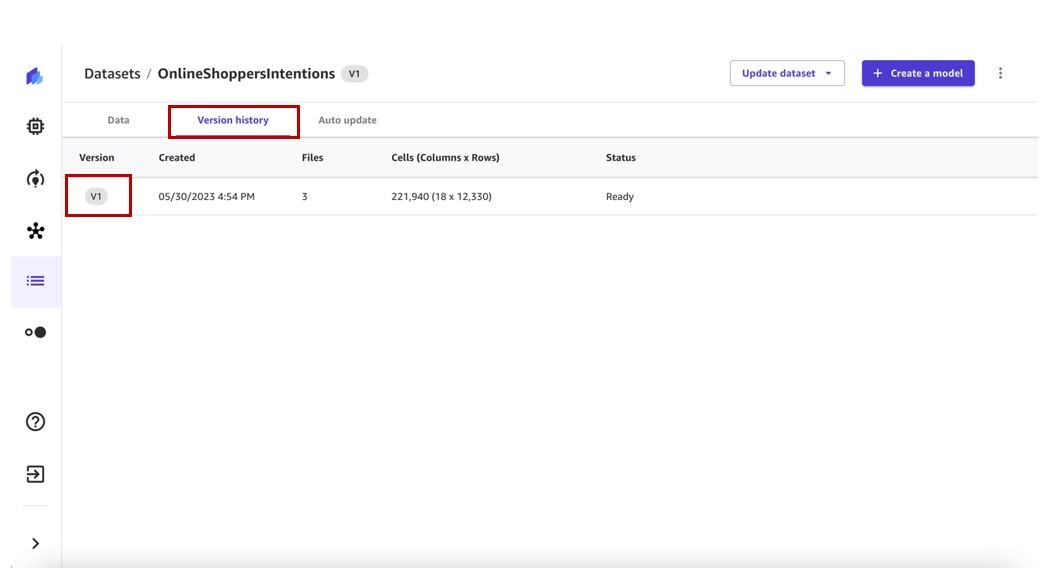
- Choose the Version History tab to view all the versions for this dataset.
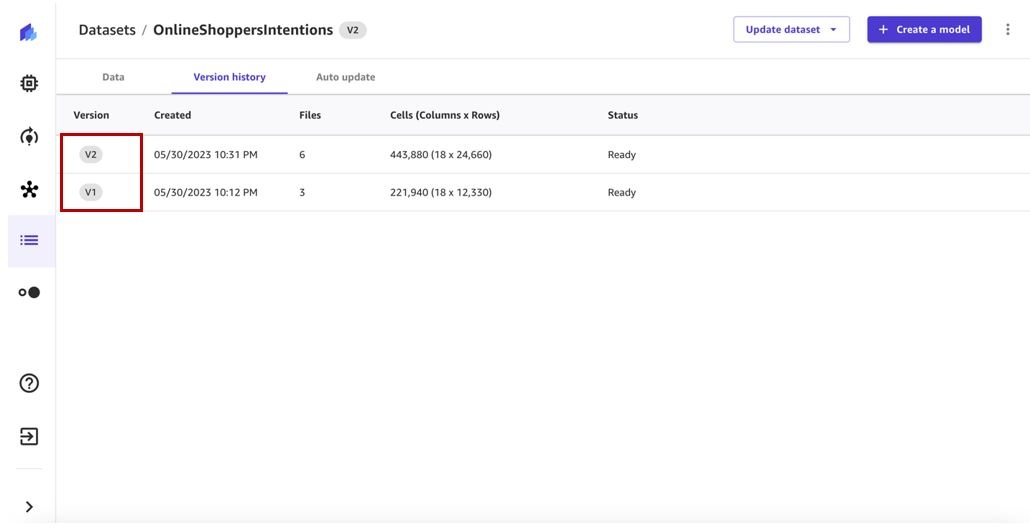
We can see our first dataset version has three files. Any subsequent version will include all the files from previous versions and will provide a cumulative view of the data.
Train an ML model with version 1 of the dataset
Let’s train an ML model with version 1 of our dataset.
- In Canvas, choose My models in the navigation pane.
- Choose New model .
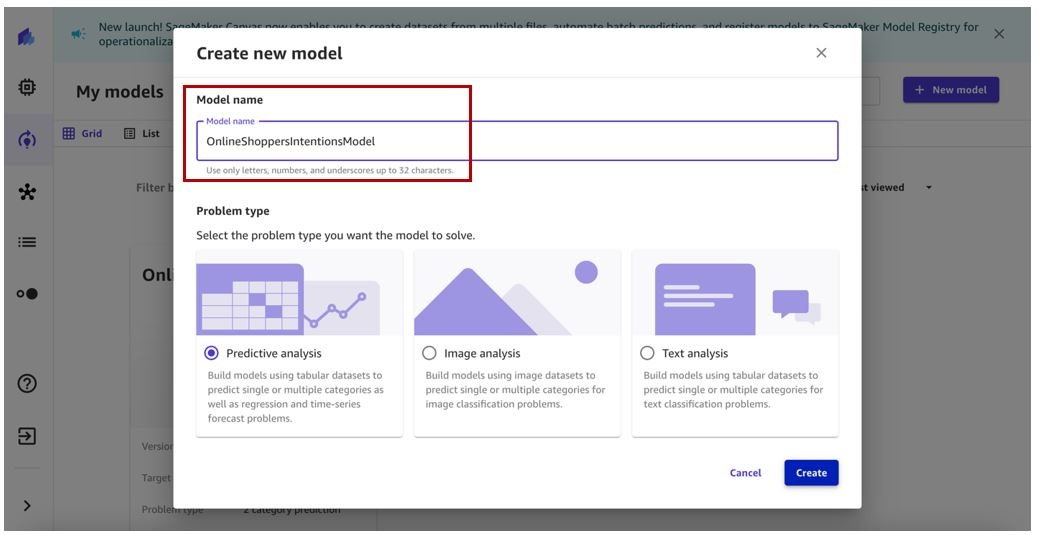
-
Enter a model name (for example,
OnlineShoppersIntentionsModel), select the problem type, and choose Create .
-
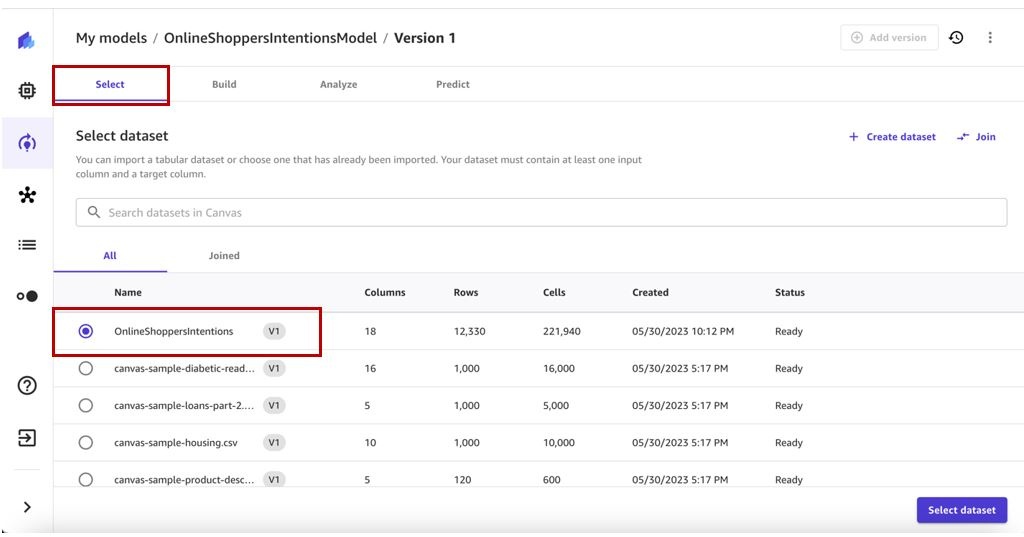
Select the dataset. For this post, we select the
OnlineShoppersIntentionsdataset.
By default, Canvas will pick up the most current dataset version for training.
- On the Build tab, choose the target column to predict. For this post, we choose the Revenue column.
- Choose Quick build .
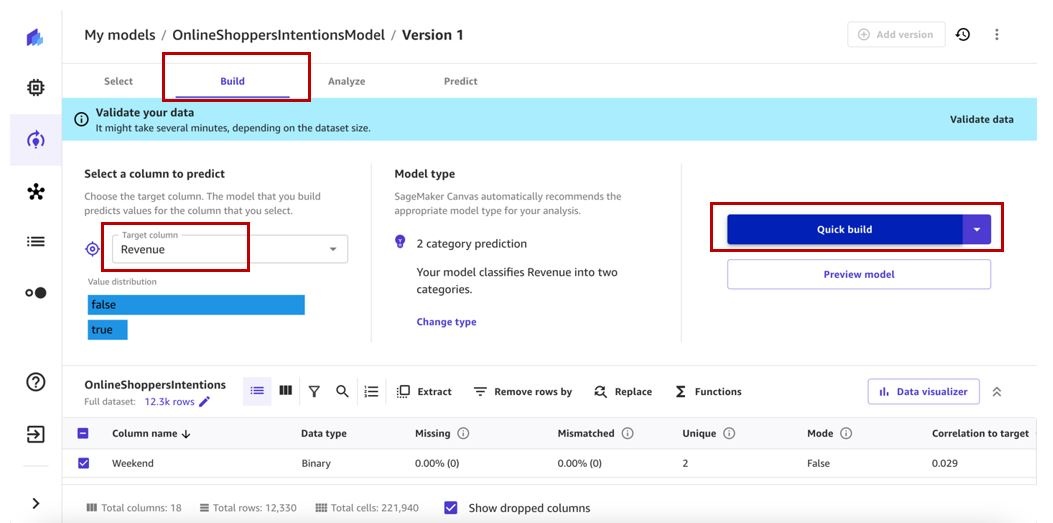
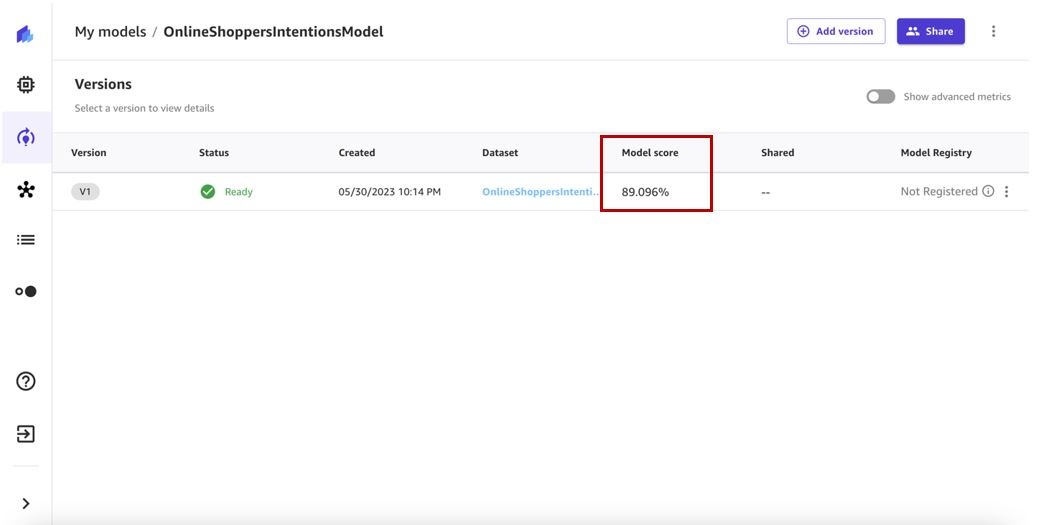
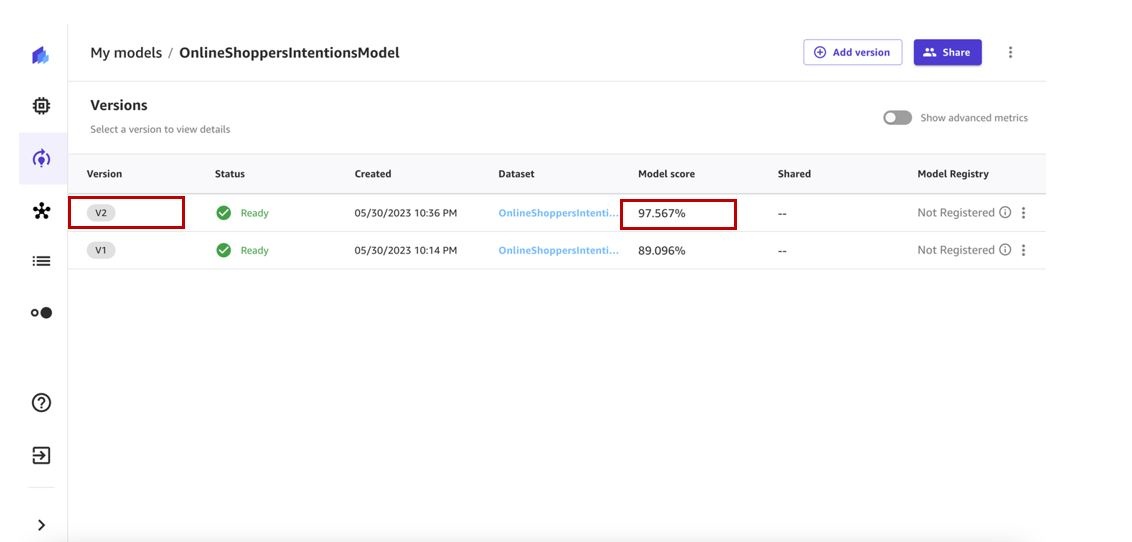
The model training will take 2–5 minutes to complete. In our case, the trained model gives us a score of 89%.
Set up automatic dataset updates
Let’s update on our dataset using the auto update functionality and bring in more data and see if the model performance improves with the new version of dataset. Datasets can be manually updated as well.
-
On the
Datasets
page, select the
OnlineShoppersIntentionsdataset and choose Update dataset . - You can either choose Manual update , which is a one-time update option, or Automatic update , which allows you to automatically update your dataset on a schedule. For this post, we showcase the automatic update feature.
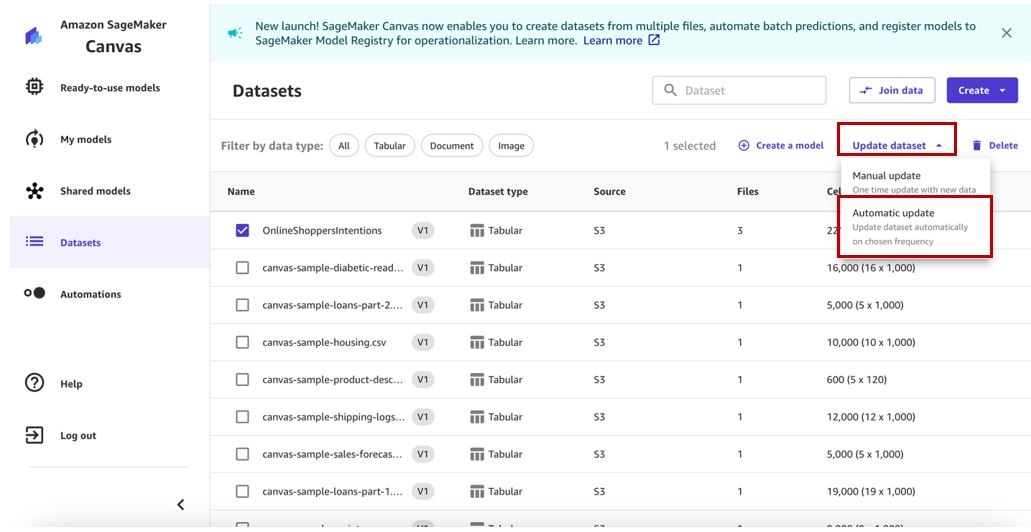
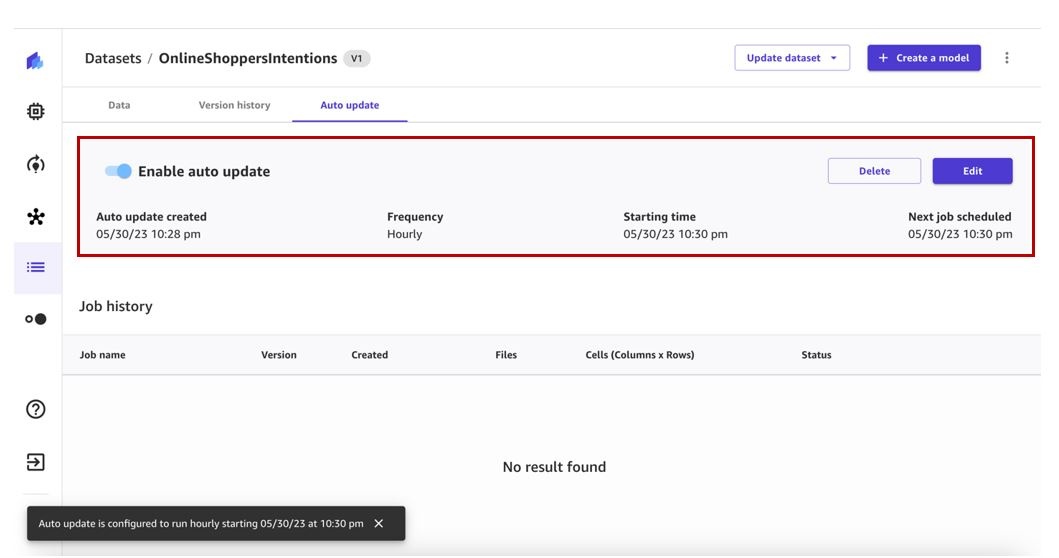
You’re redirected to the Auto update tab for the corresponding dataset. We can see that Enable auto update is currently disabled.
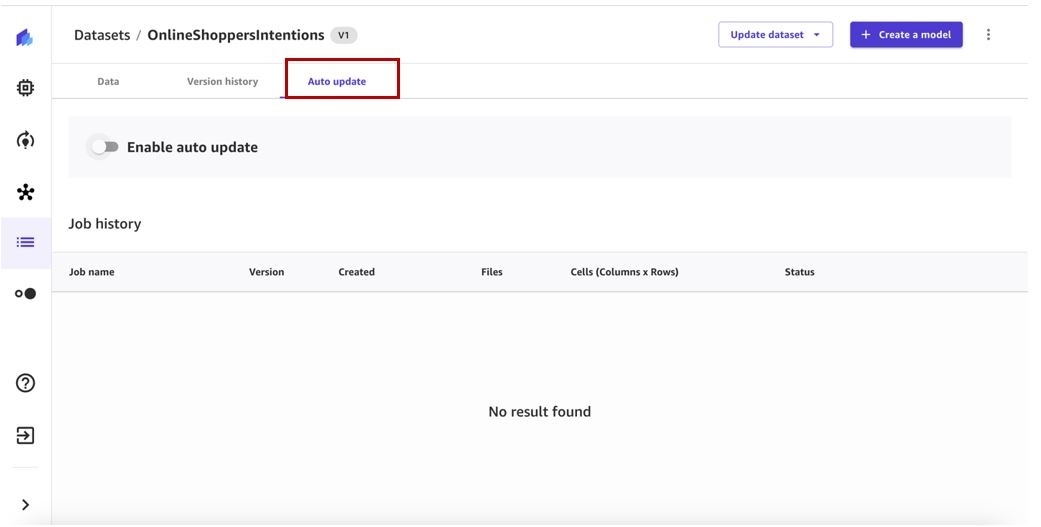
- Toggle Enable auto update to on and specify the data source (as of this writing, Amazon S3 data sources are supported for auto updates).
- Select a frequency and enter a start time.
- Save the configuration settings.
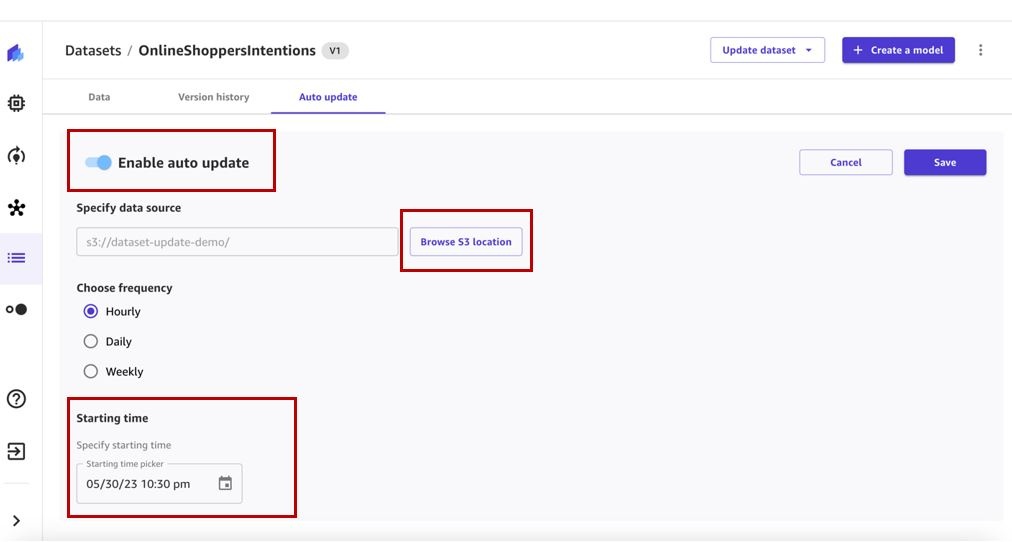
An auto update dataset configuration has been created. It can be edited at any time. When a corresponding dataset update job is triggered on the specified schedule, the job will appear in the Job history section.
-
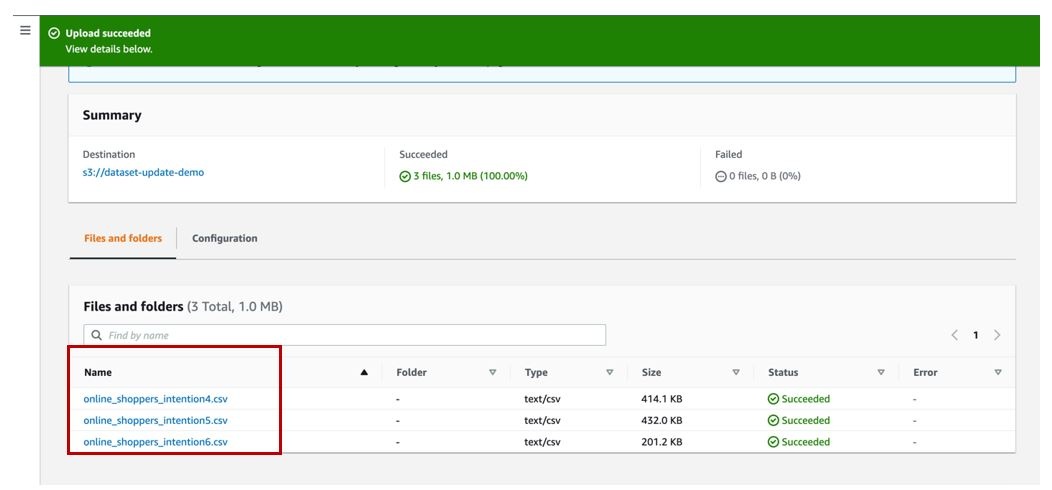
Next, let’s upload the
online_shoppers_intentions4.csv,online_shoppers_intentions5.csv, andonline_shoppers_intentions6.csvfiles to our S3 bucket.
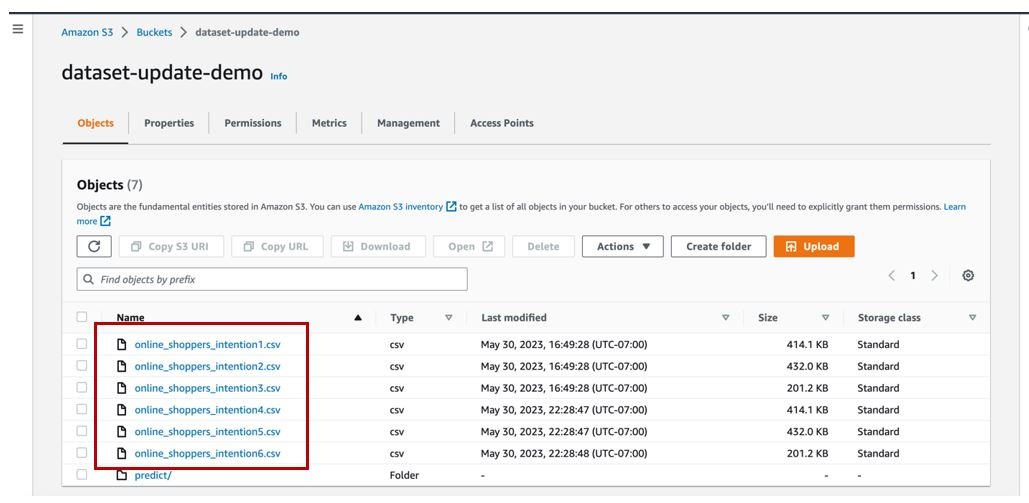
We can view our files in the
dataset-update-demo
S3 bucket.
The dataset update job will get triggered at the specified schedule and create a new version of the dataset.
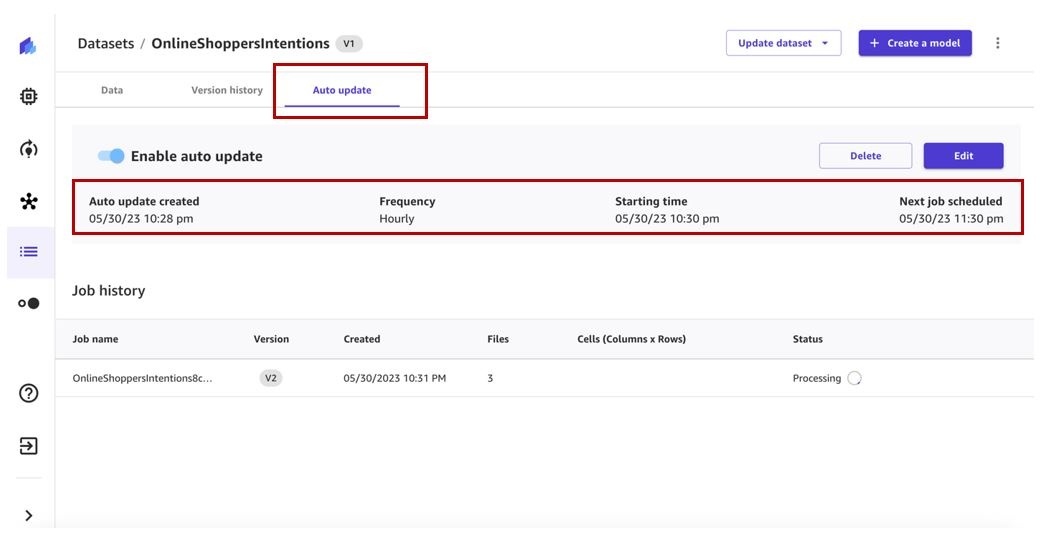
When the job is complete, dataset version 2 will have all the files from version 1 and the additional files processed by the dataset update job. In our case, version 1 has three files and the update job picked up three additional files, so the final dataset version has six files.
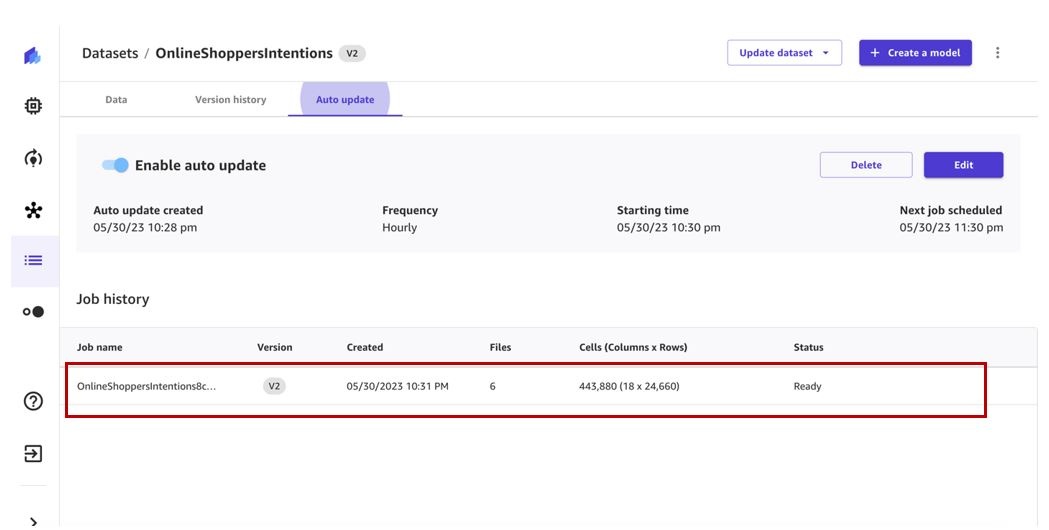
We can view the new version that was created on the Version history tab.
The Data tab contains a preview of the dataset and provides a list of all the files in the latest version of the dataset.
Retrain the ML model with an updated dataset
Let’s retrain our ML model with the latest version of the dataset.
- On the My models page, choose your model.
-
Choose
Add version
.
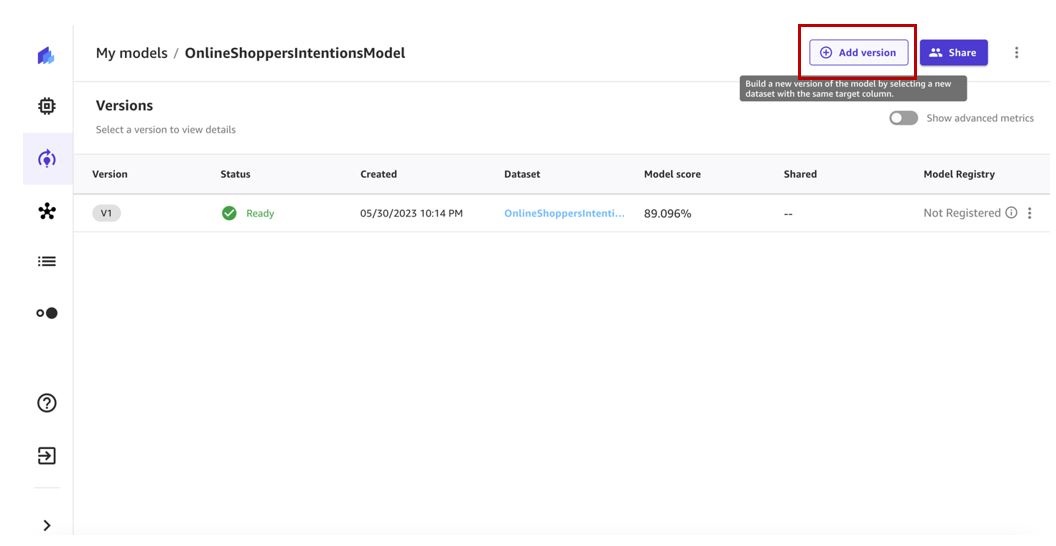
-
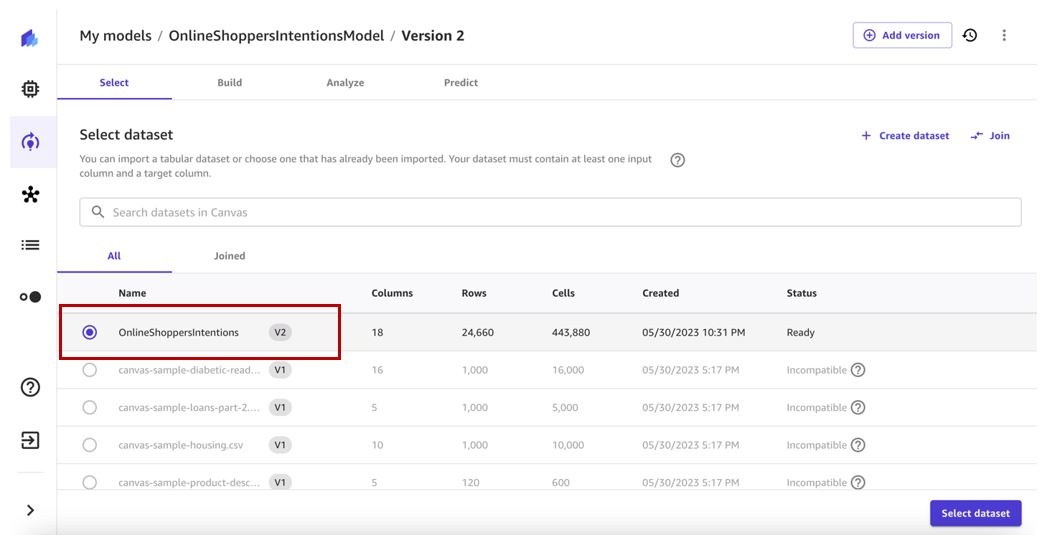
Select the latest dataset version (v2 in our case) and choose
Select dataset
.
-
Keep the target column and build configuration similar to the previous model version.
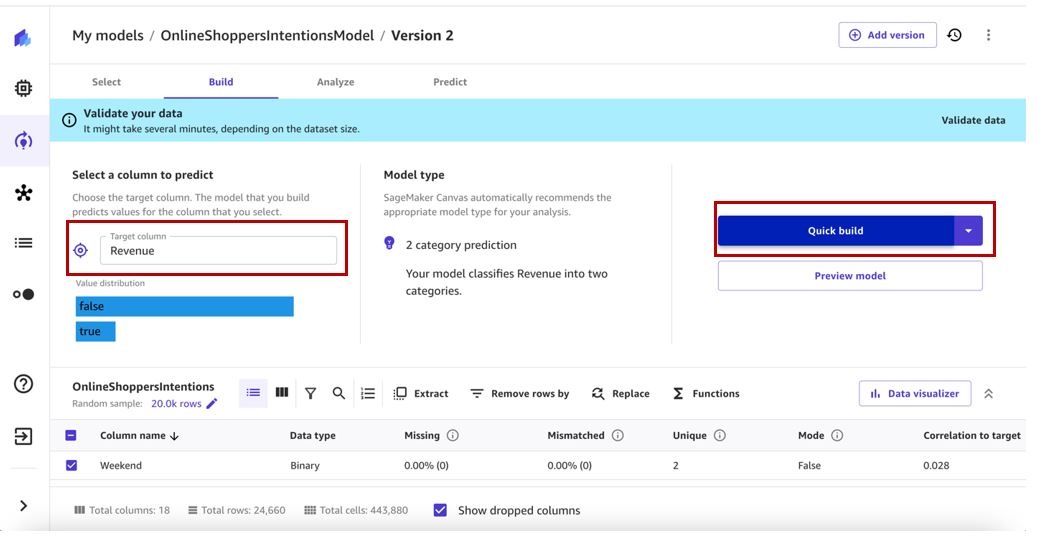
When the training is complete, let’s evaluate the model performance. The following screenshot shows that adding additional data and retraining our ML model has helped improve our model performance.
Create a prediction dataset
With an ML model trained, let’s create a dataset for predictions and run batch predictions on it.
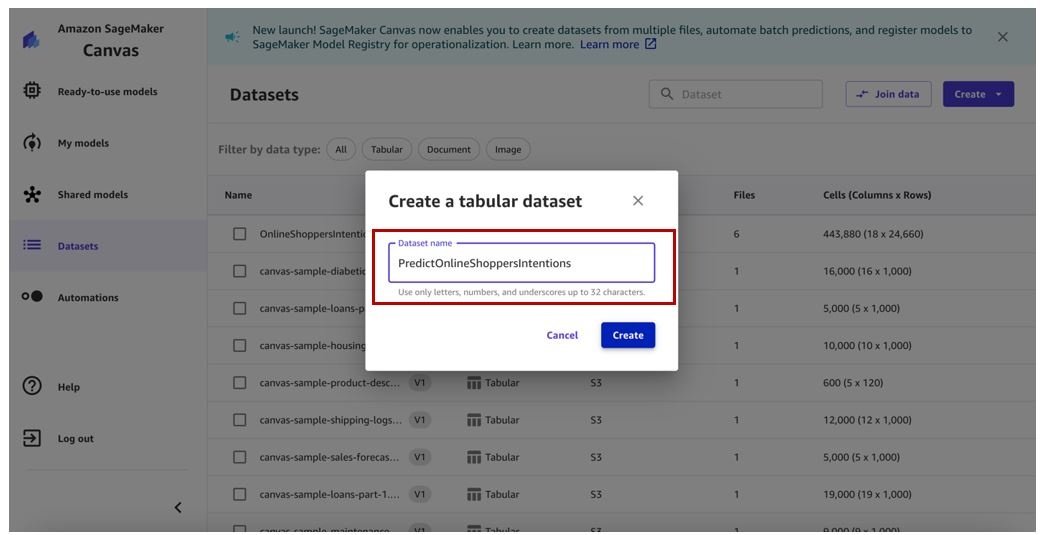
- On the Datasets page, create a tabular dataset.
-
Enter a name and choose
Create
.
-
In our S3 bucket, upload one file with 500 rows to predict.
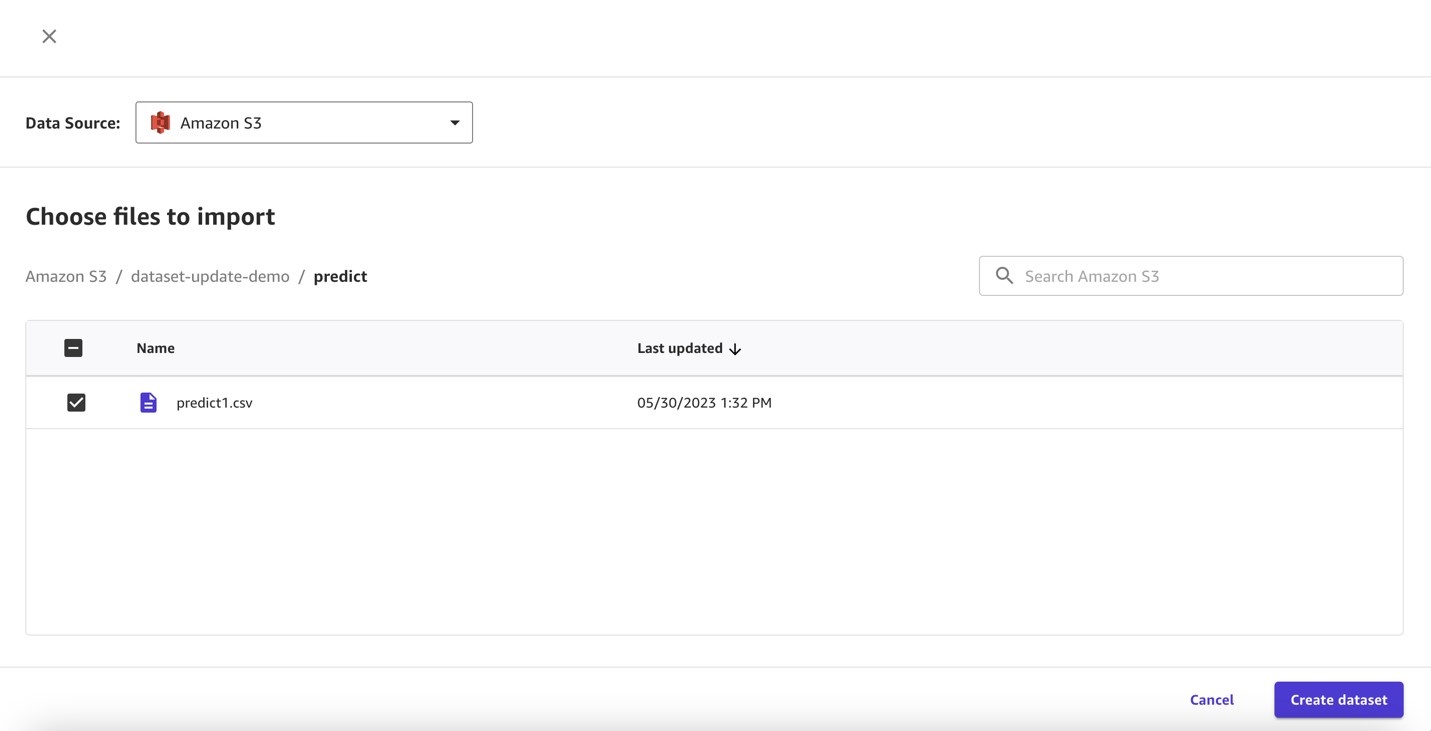
Next, we set up auto updates on the prediction dataset.
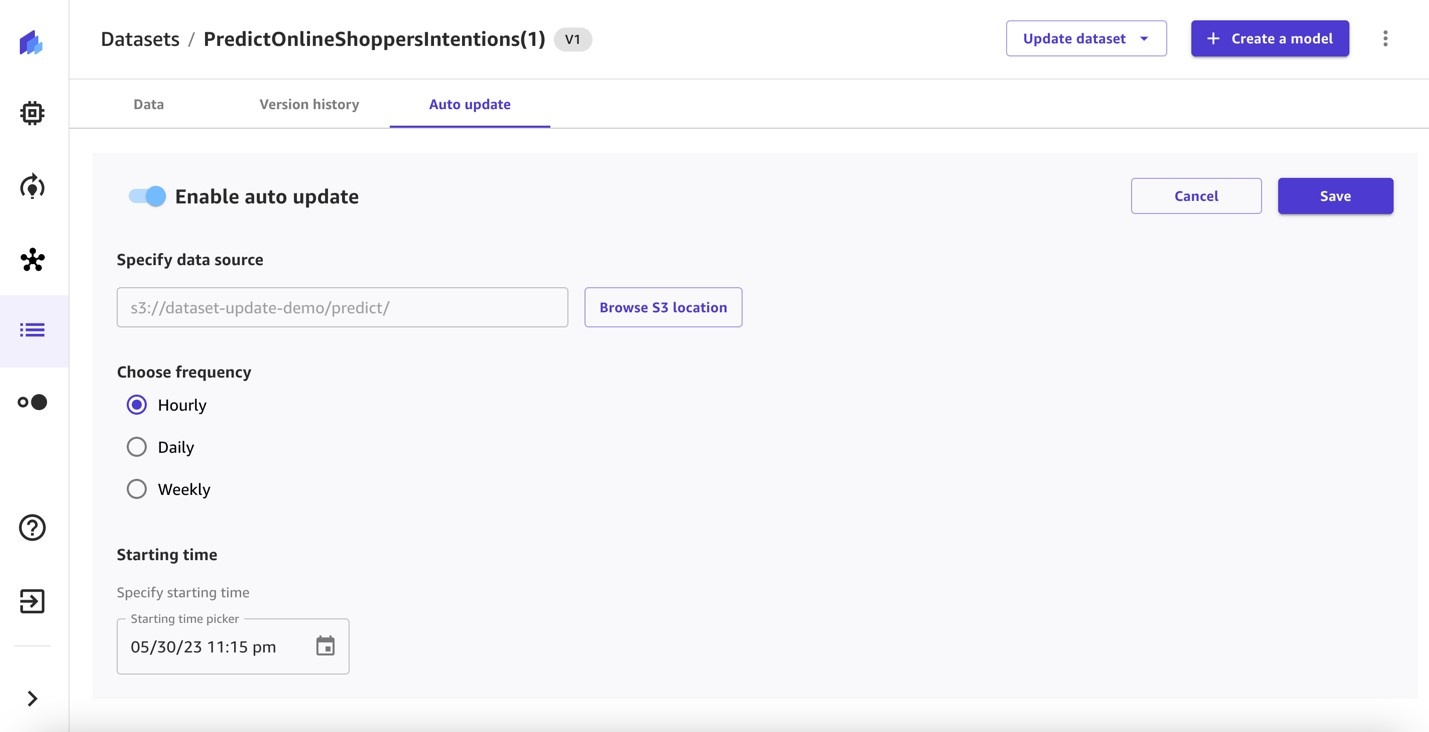
- Toggle Enable auto update to on and specify the data source.
- Select the frequency and specify a starting time.
-
Save the configuration.
Automate the batch prediction workflow on an auto updated predictions dataset
In this step, we configure our auto batch prediction workflows.
- On the My models page, navigate to version 2 of your model.
-
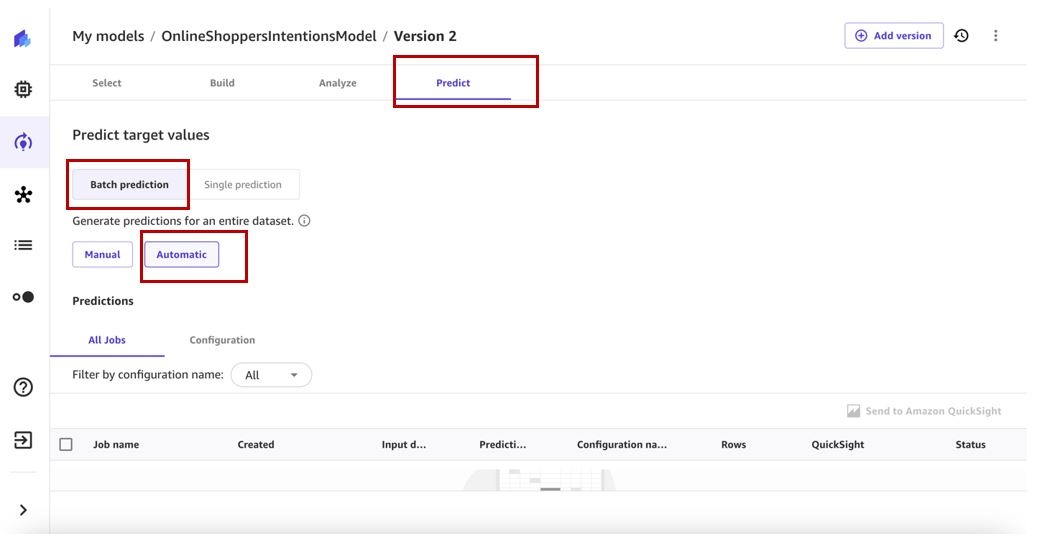
On the
Predict
tab, choose
Batch prediction
and
Automatic
.
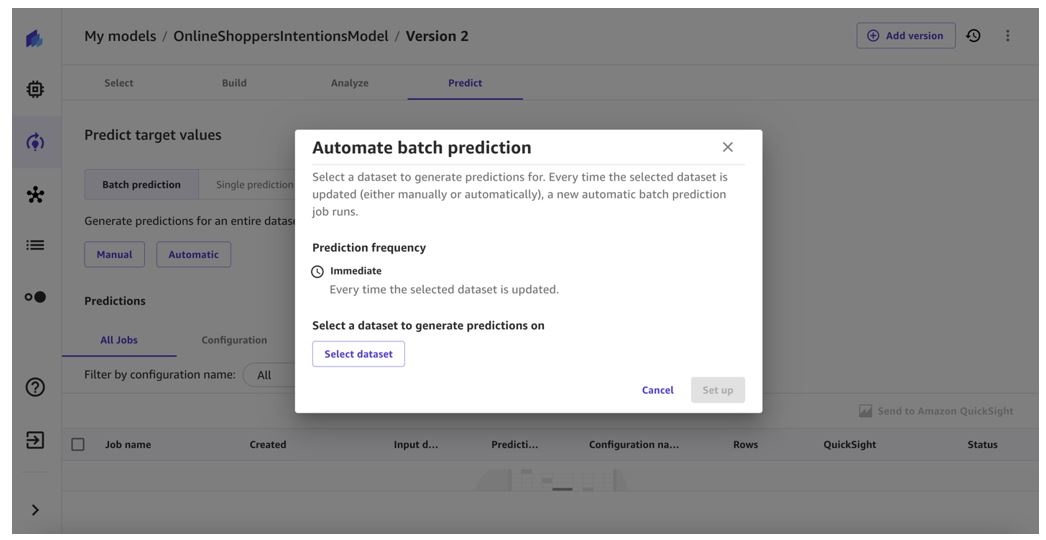
-
Choose
Select dataset
to specify the dataset to generate predictions on.
-
Select the
predictdataset that we created earlier and choose Choose dataset .
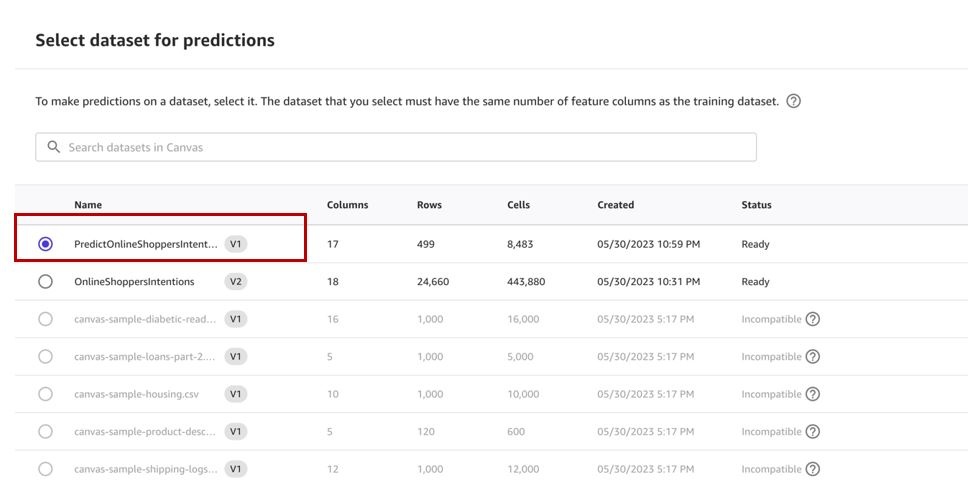
-
Choose
Set up
.
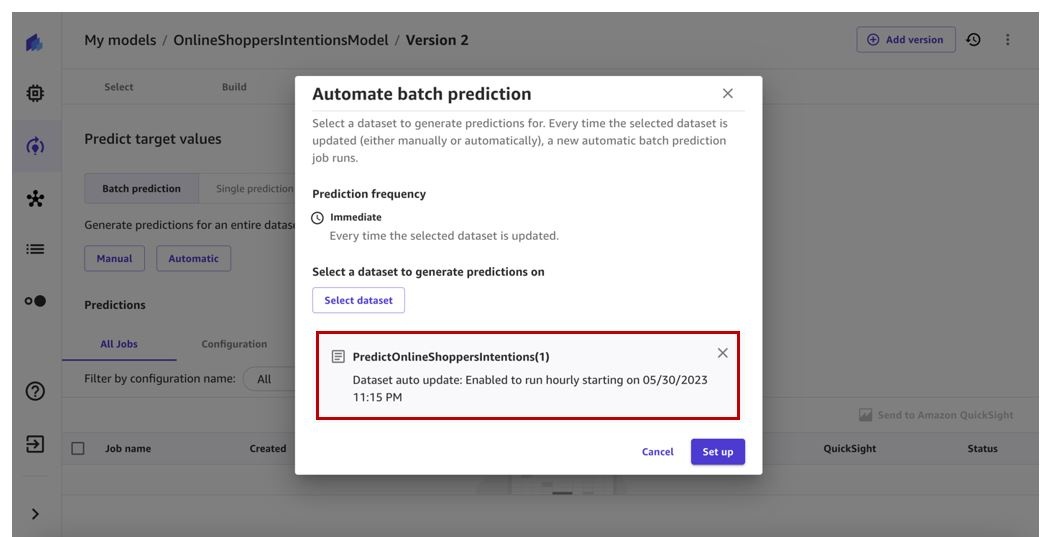
We now have an automatic batch prediction workflow. This will be triggered when the
Predict
dataset is automatically updated.

Now let’s upload more CSV files to the
predict
S3 folder.
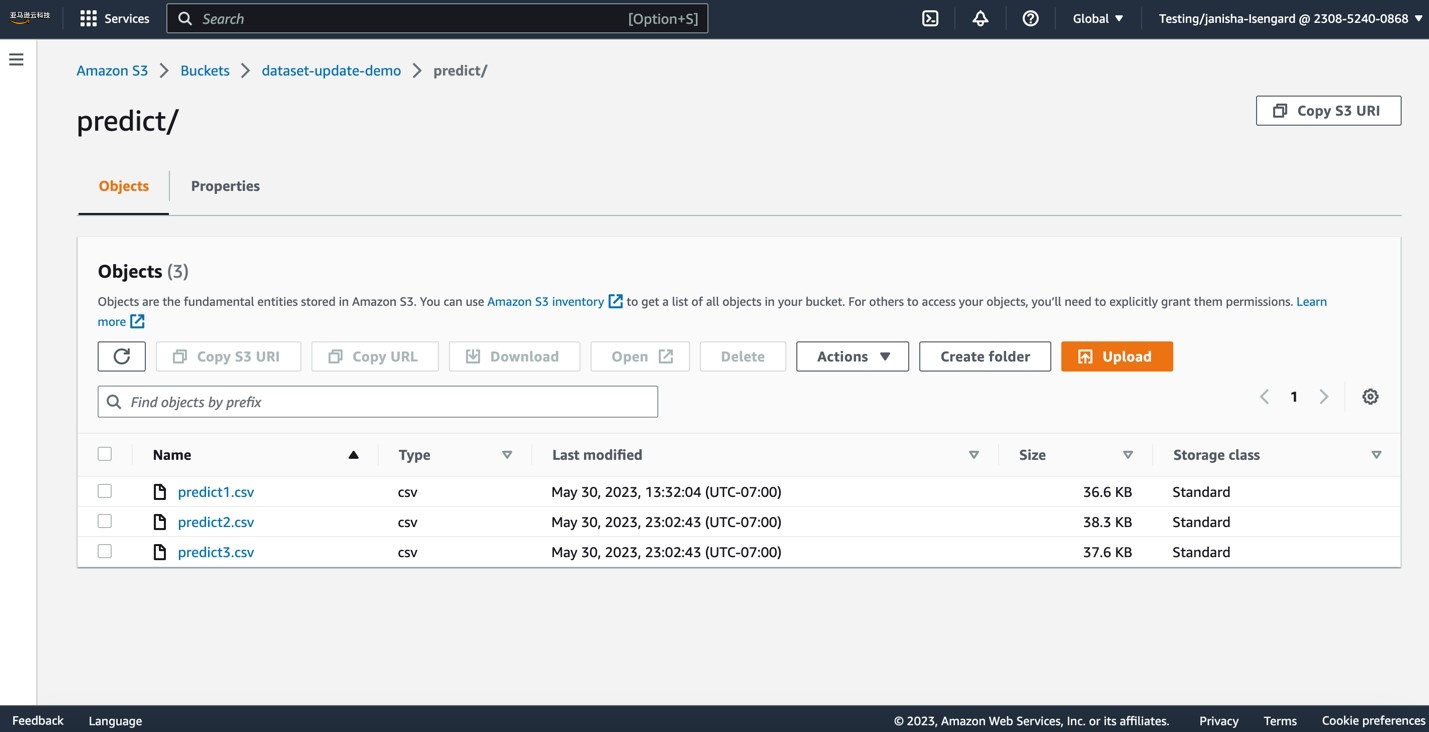
This operation will trigger an auto update of the
predict
dataset.
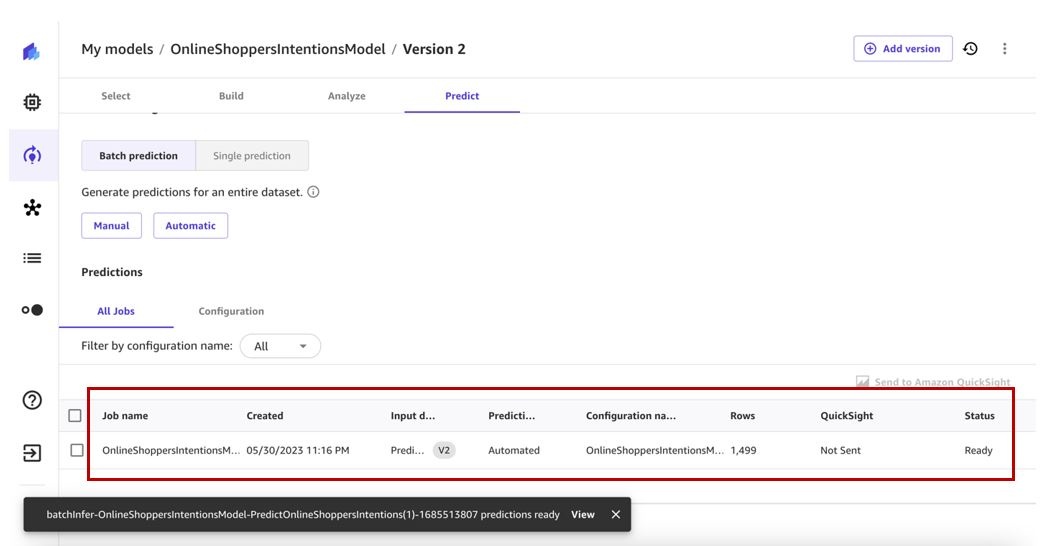
This will in turn trigger the automatic batch prediction workflow and generate predictions for us to view.
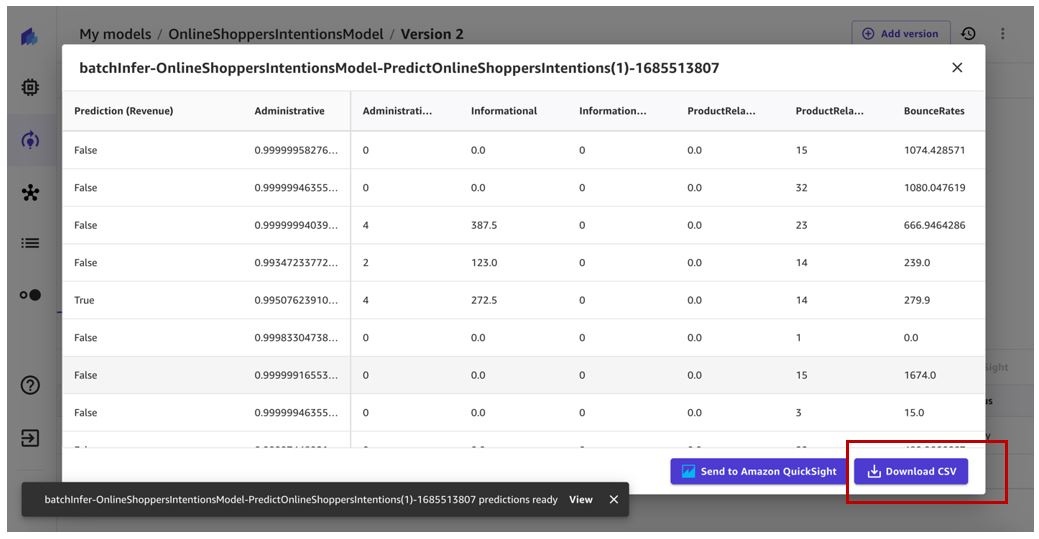
We can view all automations on the Automations page.
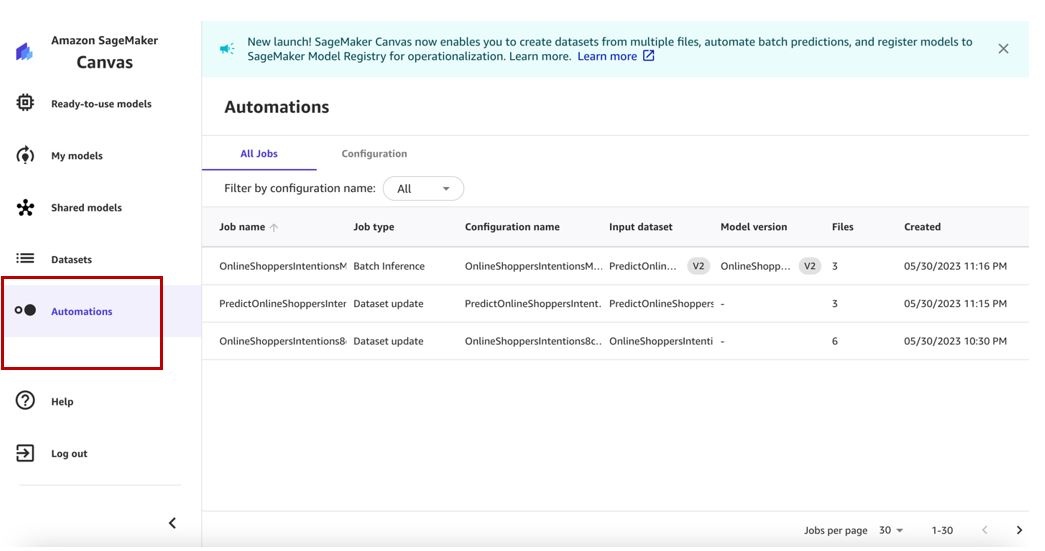
Thanks to the automatic dataset update and automatic batch prediction workflows, we can use the latest version of the tabular, image, and document dataset for training ML models, and build batch prediction workflows that get automatically triggered on every dataset update.
Clean up
To avoid incurring future charges, log out of Canvas. Canvas bills you for the duration of the session, and we recommend logging out of Canvas when you’re not using it. Refer to
Conclusion
In this post, we discussed how we can use the new dataset update capability to build new dataset versions and train our ML models with the latest data in Canvas. We also showed how we can efficiently automate the process of running batch predictions on updated data.
To start your low-code/no-code ML journey, refer to the
Special thanks to everyone who contributed to the launch.
About the Authors
 Janisha Anand
is a Senior Product Manager on the SageMaker No/Low-Code ML team, which includes SageMaker Canvas and SageMaker Autopilot. She enjoys coffee, staying active, and spending time with her family.
Janisha Anand
is a Senior Product Manager on the SageMaker No/Low-Code ML team, which includes SageMaker Canvas and SageMaker Autopilot. She enjoys coffee, staying active, and spending time with her family.
 Prashanth
is a Software Development Engineer at Amazon SageMaker and mainly works with SageMaker low-code and no-code products.
Prashanth
is a Software Development Engineer at Amazon SageMaker and mainly works with SageMaker low-code and no-code products.
 Esha Dutta
is a Software Development Engineer at Amazon SageMaker. She focuses on building ML tools and products for customers. Outside of work, she enjoys the outdoors, yoga, and hiking.
Esha Dutta
is a Software Development Engineer at Amazon SageMaker. She focuses on building ML tools and products for customers. Outside of work, she enjoys the outdoors, yoga, and hiking.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.