We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Processing large records with Amazon Kinesis Data Streams
In today’s digital era, data is abundant and constantly flowing. Businesses across industries are seeking ways to harness this wealth of information to gain valuable insights and make real-time decisions. To meet this need, Amazon Web Services offers
Data streaming technologies like Kinesis Data Streams are designed to efficiently process and manage continuous streams of data in real time at large scale. The individual pieces of data within these streams are often referred to as records . In scenarios like large file processing or performing image, audio, or video analytics, your record may exceed 1 MB. You may struggle to ingest such a large record with Kinesis Data Streams because, as of this writing, the service has a 1 MB upper limit for maximum data record size.
In this post, we show you some different options for handling large records within Kinesis Data Streams and the benefits and disadvantages of each approach. We provide some sample code for each option to help you get started with any of these approaches with your own workloads.
Understanding the default behavior of Kinesis Data Streams
You can send records to Kinesis Data Streams using the
Each shard, which holds your data, can handle writing up to 1 MB per second. Let’s consider a scenario where you define a partition key and attempt to send a data record that exceeds 1 MB in size. Based on the explanation so far, the service will reject this request because the record size is over 1 MB. To help you understand better, we experimented by trying to send a record of 1.5 MB to a stream, and the outcome was the following exception message:
Strategies for handling large records
Now that we understand the behavior of the
PutRecord
and
PutRecords
APIs, let’s discuss strategies you can use to overcome this situation. One thing to keep in mind is that there is no single best solution; in the following sections, we discuss some of the approaches that you can evaluate based on your use case:
-
Store large records in
Amazon Simple Storage Service (Amazon S3) with a reference in Kinesis Data Streams - Split one large record into multiple records
- Compress your large records
Let’s discuss these points one by one.
Store large records in Amazon S3 with a reference in Kinesis Data Streams
A useful approach for storing large records involves utilizing an alternative storage solution while employing a reference within Kinesis Data Streams. In this context, Amazon S3 stands out as an excellent choice due to its exceptional durability and cost-effectiveness. The procedure involves uploading the record as an object to an S3 bucket and subsequently writing a reference entry in Kinesis Data Streams. This entry incorporates an attribute that serves as a pointer, indicating the location of the object within Amazon S3.
With this approach, you can generate a
The following diagram illustrates the architecture of this solution.
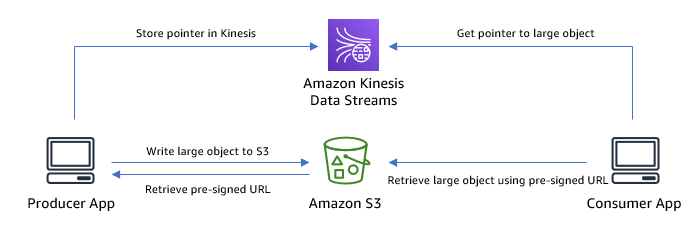
The following is the sample code to write data to Kinesis Data Streams using this approach:
If you are using an
An inherent benefit of adopting this technique is the capability to store data in Amazon S3, accommodating an extensive range of sizes per individual object. This method helps you reduce the costs of using Kinesis Data Streams because it uses less storage space and requires fewer read and write throughput for item access. This optimization is achieved by storing just the URL within Kinesis Data Streams. However, it’s important to acknowledge that accessing the sizable object necessitates an additional call to Amazon S3, thereby introducing higher latency for clients as they manage the additional request.
Split one large record into multiple records
Splitting large records into smaller ones in Kinesis Data Streams brings advantages like faster processing, improved throughput, efficient resource use, and more straightforward error handling. Let’s say you have a large record that you want to split into smaller chunks before sending them to a Kinesis data stream. First, you need to set up a Kinesis producer. Suppose you have a large record as a string. You can split it into smaller chunks of a predefined size. For this example, let’s say you’re splitting the record into chunks of 100 characters each. After you split that, loop through the record chunks and send each chunk as a separate message to a Kinesis data stream. The following is the sample code:
Ensure that all chunks of a given message are directed to a single partition, thereby guaranteeing the preservation of their order. In the final chunk, include metadata within the header indicating the conclusion of the message during production. This enables consumers to identify the ultimate chunk and facilitates seamless message reconstruction. The drawback of this method is that it adds complexity to the client-side tasks of dividing and putting back together the different parts. Therefore, these functions need thorough testing to prevent any loss of data.
Compress your large records
Applying data compression prior to transmitting it to Kinesis Data Streams has numerous advantages. This approach not only reduces the data’s size, enabling swifter travel and more efficient utilization of network resources, but also leads to cost savings in terms of storage expenses while optimizing overall resource consumption. Additionally, this practice simplifies storage and data retention. By using compression algorithms such as GZIP, Snappy, or LZ4, you can achieve substantial reduction in the size of large records. Compression brings the benefit of simplicity because it’s implemented seamlessly without requiring the caller to make changes to the item or use extra Amazon Web Services services to support storage. However, compression introduces additional CPU overhead and latency on the producer side, and its impact on the compression ratio and efficiency can vary depending on the data type and format. Also, compression can enhance consumer throughput at the expense of some decompression overhead.
Conclusion
For real-time data streaming use cases, it’s essential to carefully consider the handling of large records when using Kinesis Data Streams. In this post, we discussed the challenges associated with managing large records and explored strategies such as utilizing Amazon S3 references, record splitting, and compression. Each approach has its own set of benefits and drawbacks, so it’s crucial to evaluate the nature of your data and the tasks you need to perform. Select the most suitable approach based on your data’s characteristics and your processing task requirements.
We encourage you to try out the approaches discussed in this post and share your thoughts in the comments section.
About the author
 Masudur Rahaman Sayem
is a Streaming Data Architect at Amazon Web Services. He works with Amazon Web Services customers globally to design and build data streaming architectures to solve real-world business problems. He specializes in optimizing solutions that use streaming data services and NoSQL. Sayem is very passionate about distributed computing.
Masudur Rahaman Sayem
is a Streaming Data Architect at Amazon Web Services. He works with Amazon Web Services customers globally to design and build data streaming architectures to solve real-world business problems. He specializes in optimizing solutions that use streaming data services and NoSQL. Sayem is very passionate about distributed computing.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.