We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Optimized PyTorch 2.0 inference with Amazon Web Services Graviton processors
New generations of CPUs offer a significant performance improvement in machine learning (ML) inference due to specialized built-in instructions. Combined with their flexibility, high speed of development, and low operating cost, these general-purpose processors offer an alternative to other existing hardware solutions.
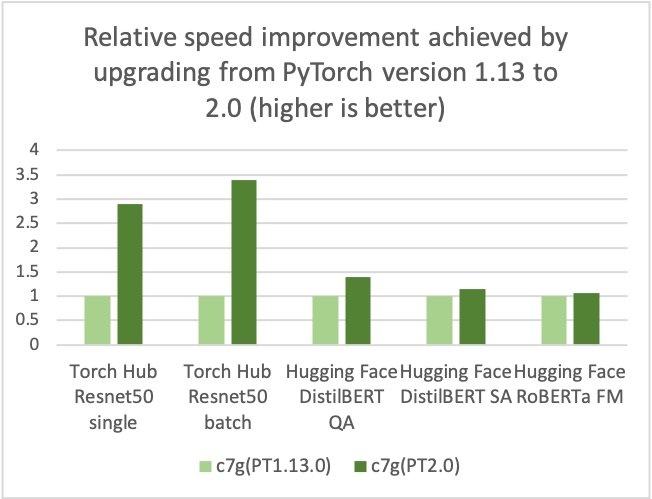
Amazon Web Services, Arm, Meta and others helped optimize the performance of PyTorch 2.0 inference for Arm-based processors. As a result, we are delighted to announce that Amazon Web Services Graviton-based instance inference performance for PyTorch 2.0 is up to 3.5 times the speed for Resnet50 compared to the previous PyTorch release (see the following graph), and up to 1.4 times the speed for BERT, making Graviton-based instances the fastest compute optimized instances on Amazon Web Services for these models.
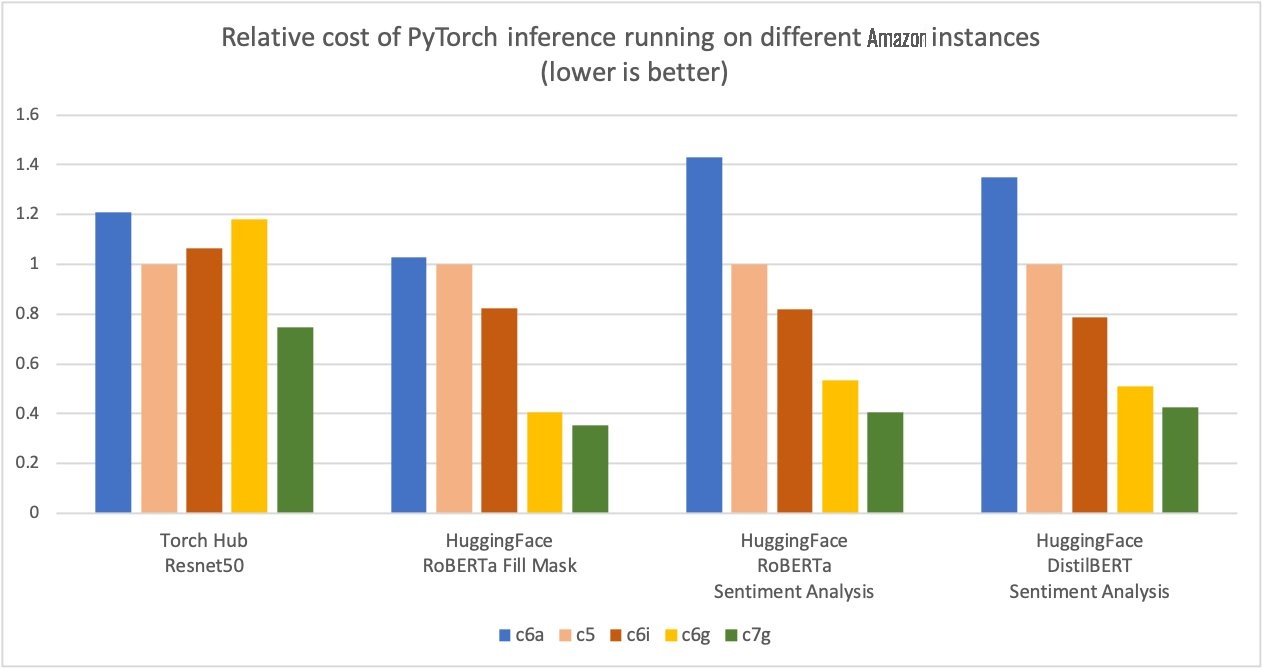
Amazon Web Services measured up to 50% cost savings for PyTorch inference with Amazon Web Services Graviton3-based Amazon Elastic Cloud Compute C7g instances across Torch Hub Resnet50, and multiple Hugging Face models relative to comparable EC2 instances, as shown in the following figure.
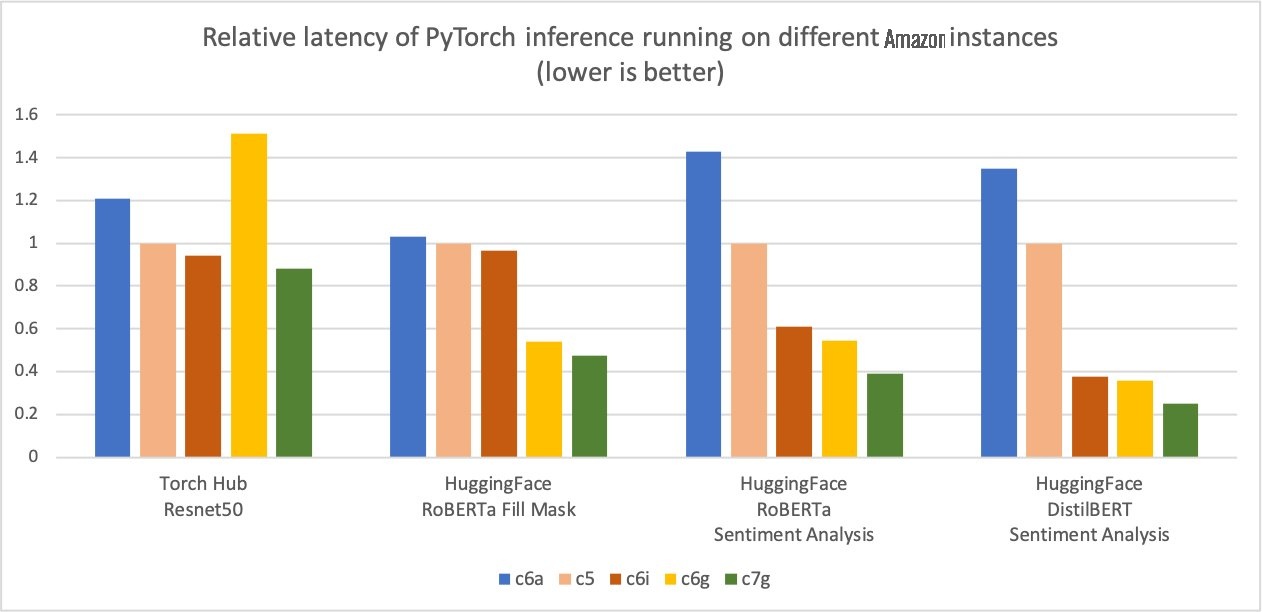
Additionally, the latency of inference is also reduced, as shown in the following figure.
We have seen a similar trend in the price-performance advantage for other workloads on Graviton, for example
Optimization details
The optimizations focused on three key areas:
- GEMM kernels – PyTorch supports Arm Compute Library (ACL) GEMM kernels via the OneDNN backend (previously called MKL-DNN) for Arm-based processors. The ACL library provides Neon and SVE optimized GEMM kernels for both fp32 and bfloat16 formats. These kernels improve the SIMD hardware utilization and reduce the end-to-end inference latencies.
- bfloat16 support – The bfloat16 support in Graviton3 allows for efficient deployment of models trained using bfloat16, fp32, and AMP (Automatic Mixed Precision). The standard fp32 models use bfloat16 kernels via OneDNN fast math mode, without model quantization, providing up to two times faster performance compared to the existing fp32 model inference without bfloat16 fast math support.
- Primitive caching – We also implemented primitive caching for conv, matmul, and inner product operators to avoid redundant GEMM kernel initialization and tensor allocation overhead.
How to take advantage of the optimizations
The simplest way to get started is by using the
Use Amazon Web Services DLCs
To use Amazon Web Services DLCs, use the following code:
If you prefer to install PyTorch via pip, install the PyTorch 2.0 wheel from the official repo. In this case, you will have to set two environment variables as explained in the code below before launching PyTorch to activate the Graviton optimization.
Use the Python wheel
To use the Python wheel, refer to the following code:
Run inference
You can use PyTorch
Benchmarking
You can use the
Conclusion
Amazon Web Services measured up to 50% cost savings for PyTorch inference with Amazon Web Services Graviton3-based Amazon Elastic Cloud Compute C7g instances across Torch Hub Resnet50, and multiple Hugging Face models relative to comparable EC2 instances. These instances are available on SageMaker and Amazon EC2. The
If you find use cases where similar performance gains aren’t observed on Amazon Web Services Graviton, please open an issue on the
About the author
 Sunita Nadampalli
is a Software Development Manager at Amazon Web Services. She leads Graviton software performance optimizations for machine leaning, HPC, and multimedia workloads. She is passionate about open-source development and delivering cost-effective software solutions with Arm SoCs.
Sunita Nadampalli
is a Software Development Manager at Amazon Web Services. She leads Graviton software performance optimizations for machine leaning, HPC, and multimedia workloads. She is passionate about open-source development and delivering cost-effective software solutions with Arm SoCs.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.