We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Introducing the Cloud Shuffle Storage Plugin for Apache Spark
Apache Spark utilizes in-memory caching and optimized query execution for fast analytic queries against your datasets, which are split into multiple Spark partitions on different nodes so that you can process a large amount of data in parallel. In Apache Spark,
No space left on device
or
MetadataFetchFailedException
error when there isn’t enough disk space left on the executor and there is no recovery. Such Spark jobs can’t typically succeed without adding additional compute and attached storage, wherein compute is often idle, and results in additional cost.
In 2021, we launched
Today, we’re pleased to release
We’re also excited to announce the release of software binaries for the Cloud Shuffle Storage Plugin for Apache Spark under the Apache 2.0 license. You can
Understanding a shuffle operation in Apache Spark
In Apache Spark, there are two types of transformations:
-
Narrow transformation
– This includes
map,filter,union, andmapPartition, where each input partition contributes to only one output partition. -
Wide transformation
– This includes
join,groupBykey,reduceByKey, andrepartition, where each input partition contributes to many output partitions.Spark SQL queries includingJOIN,ORDER BY,GROUP BYrequire wide transformations.
A wide transformation triggers a shuffle, which occurs whenever data is reorganized into new partitions with each key assigned to one of them. During a shuffle phase, all Spark map tasks write shuffle data to a local disk that is then transferred across the network and fetched by Spark reduce tasks. The volume of data shuffled is visible in the Spark UI. When shuffle writes take up more space than the local available disk capacity, it causes a
No space left on device
error.
To illustrate one of the typical scenarios, let’s use the query q80.sql from the standard TPC-DS 3 TB dataset as an example. This query attempts to calculate the total sales, returns, and eventual profit realized during a specific time frame. It involves multiple wide transformations (shuffles) caused by
left outer join
and
group by
.
Let’s run the following query on Amazon Web Services Glue 3.0 job with 10 G1.X workers where a total of 640GB of local disk space is available:
The following screenshot shows
the Executor tab
in the Spark UI.

The following screenshot shows the status of Spark jobs included in the Amazon Web Services Glue job run.
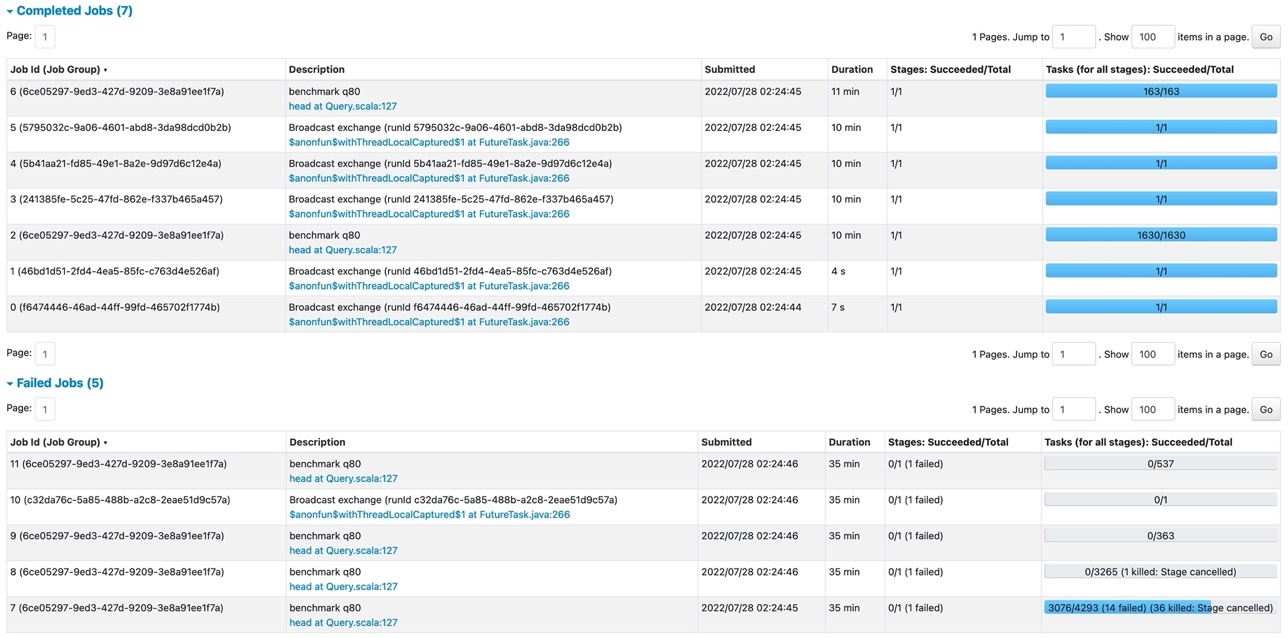
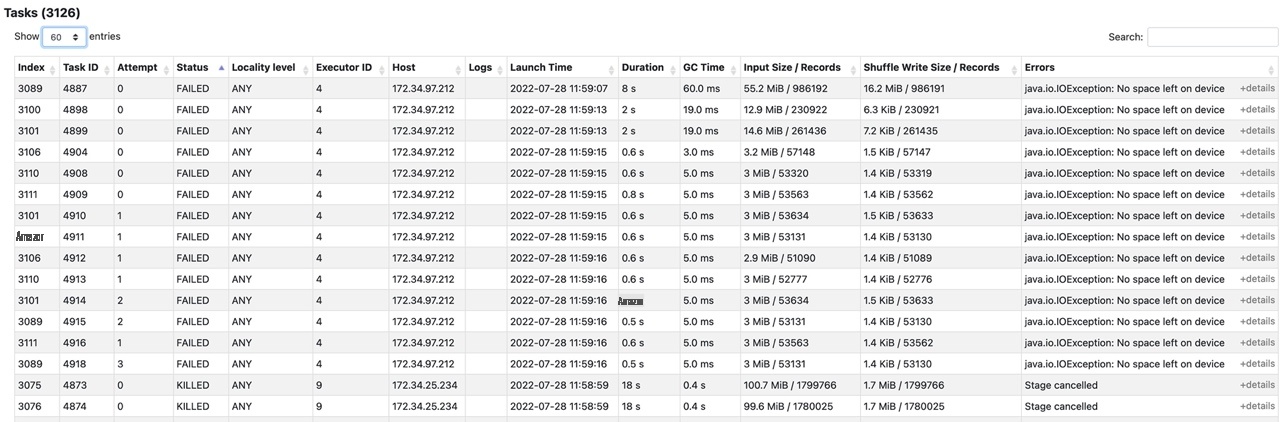
In the failed Spark job (job ID=7), we can see the failed Spark stage in the Spark UI.

There was 167.8GiB shuffle write during the stage, and 14 tasks failed due to the error
java.io.IOException: No space left on device
because the host 172.34.97.212 ran out of local disk.
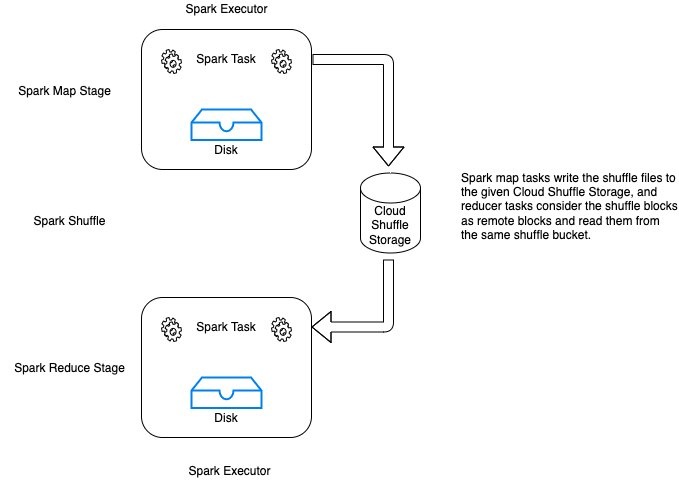
Cloud Shuffle Storage for Apache Spark
Cloud Shuffle Storage for Apache Spark allows you to store Spark shuffle files on Amazon S3 or other cloud storage services. This gives complete elasticity to Spark jobs, thereby allowing you to run your most data intensive workloads reliably. The following figure illustrates how Spark map tasks write the shuffle files to the Cloud Shuffle Storage. Reducer tasks consider the shuffle blocks as remote blocks and read them from the same shuffle storage.
This architecture enables your serverless Spark jobs to use Amazon S3 without the overhead of running, operating, and maintaining additional storage or compute nodes.
The following Glue job parameters enable and tune Spark to use S3 buckets for storing shuffle data. You can also enable at-rest encryption when writing shuffle data to Amazon S3 by using
| Key | Value | Explanation |
|---|---|---|
--write-shuffle-files-to-s3
|
TRUE
|
This is the main flag, which tells Spark to use S3 buckets for writing and reading shuffle data. |
--conf
|
spark.shuffle.storage.path=s3://<shuffle-bucket>
|
This is optional, and specifies the S3 bucket where the plugin writes the shuffle files. By default, we use –TempDir/shuffle-data. |
The shuffle files are written to the location and create files such as following:
s3://<shuffle-storage-path>/<Spark application ID>/[0-9]/<Shuffle ID>/shuffle_<Shuffle ID>_<Mapper ID>_0.data
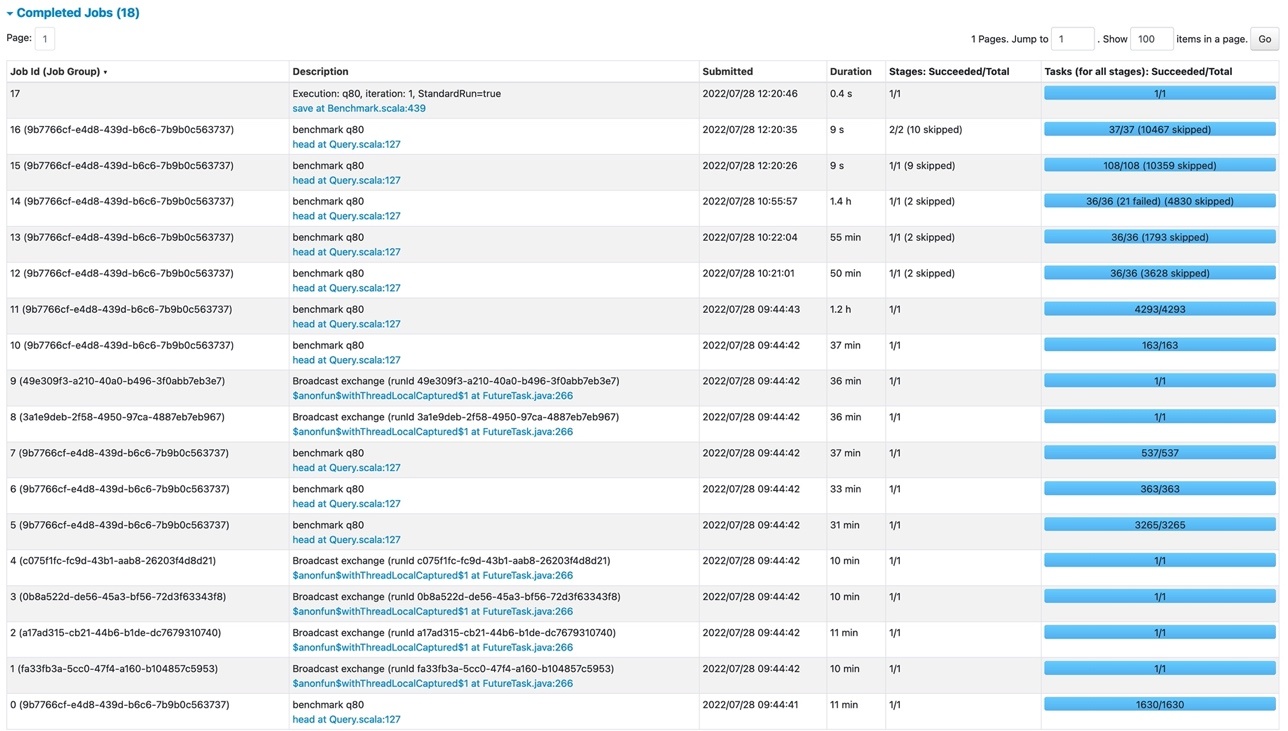
With the Cloud Shuffle Storage plugin enabled and using the same Amazon Web Services Glue job setup, the TPC-DS query now succeeded without any job or stage failures.
Software binaries for the Cloud Shuffle Storage Plugin
You can now also download and use the plugin in your own Spark environments and with other cloud storage services. The plugin binaries are available for use under the Apache 2.0 license.
Bundle the plugin with your Spark applications
You can bundle the plugin with your Spark applications by adding it as a dependency in your Maven pom.xml as you develop your Spark applications, as shown in the follwoing code. For more details on the plugin and Spark versions, refer to
You can alternatively download the binaries from Amazon Web Services Glue Maven artifacts directly and include them in your Spark application as follows:
Submit the Spark application by including the JAR files on the classpath and specifying the two Spark configs for the plugin:
The following Spark parameters enable and configure Spark to use an external storage URI such as Amazon S3 for storing shuffle files; the URI protocol determines which storage system to use.
| Key | Value | Explanation |
|---|---|---|
spark.shuffle.storage.path
|
s3://<shuffle-storage-path>
|
It specifies an URI where the shuffle files are stored, which much be a valid Hadoop FileSystem and be configured as needed |
spark.shuffle.sort.io.plugin.class
|
com.amazonaws.spark.shuffle.io.cloud.ChopperPlugin
|
The entry class in the plugin |
Other cloud storage integration
This plugin comes with out-of-the box support for Amazon S3 and can also be configured to use other forms of cloud storage such as
gs://
for Google Cloud Storage instead of
s3://
for Amazon S3, add the FileSystem JAR files for the service, and set the appropriate authentication configurations.
For more information about how to integrate the plugin with Google Cloud Storage and Microsoft Azure Blob Storage, refer to
Best practices and considerations
Note the following considerations:
-
This feature replaces local shuffle storage with Amazon S3. You can use it to address common failures with price/performance benefits for your serverless analytics jobs and pipelines. We recommend enabling this feature when you want to ensure reliable runs of your data-intensive workloads that create a large amount of shuffle data or when you’re getting
No space left on deviceerror. You can also use this plugin if your job encounters fetch failuresorg.apache.spark.shuffle.MetadataFetchFailedExceptionor if your data is skewed. -
We recommend setting
S3 bucket lifecycle policies on the shuffle bucket (spark.shuffle.storage.s3.path) in order to clean up old shuffle data automatically. -
The shuffle data on Amazon S3 is encrypted by default. You can also encrypt the data with your own
Amazon Web Services Key Management Service (Amazon Web Services KMS) keys.
Conclusion
This post introduced the new Cloud Shuffle Storage Plugin for Apache Spark and described its benefits to independently scale storage in your Spark jobs without adding additional workers. With this plugin, you can expect jobs processing terabytes of data to run much more reliably.
The plugin is available in Amazon Web Services Glue 3.0 and 4.0 Spark jobs in all Amazon Web Services Glue supported Regions. We’re also releasing the plugin’s software binaries under the Apache 2.0 license. You can use the plugin in Amazon Web Services Glue or other Spark environments. We look forward to hearing your feedback.
About the Authors





The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.