We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Introducing Amazon Web Services Lambda response streaming
Today,
You can use Lambda response payload streaming to send response data to callers as it becomes available. This can improve performance for web and mobile applications. Response streaming also allows you to build functions that return larger payloads and perform long-running operations while reporting incremental progress.
In traditional request-response models, the response needs to be fully generated and buffered before it is returned to the client. This can delay the
Other applications may have large payloads, like images, videos, large documents, or database results. Response streaming lets you transfer these payloads back to the client without having to buffer the entire payload in memory. You can use response streaming to send responses larger than Lambda’s 6 MB response payload limit up to a soft limit of 20 MB.
Response streaming currently supports the Node.js 14.x and subsequent managed runtimes. You can also implement response streaming using custom runtimes. You can progressively stream response payloads through
Writing response streaming enabled functions
Writing the handler for response streaming functions differs from typical Node handler patterns. To indicate to the runtime that Lambda should stream your function’s responses, you must wrap your function handler with the
streamifyResponse()
decorator. This tells the runtime to use the correct stream logic path, allowing the function to stream responses.
This is an example handler with response streaming enabled:
exports.handler = awslambda.streamifyResponse(
async (event, responseStream, context) => {
responseStream.setContentType(“text/plain”);
responseStream.write(“Hello, world!”);
responseStream.end();
}
);
The
streamifyResponse
decorator accepts the following additional parameter,
responseStream
, besides the default node handler parameters,
event
, and
context
.
The new
responseStream
object provides a stream object that your function can write data to. Data written to this stream is sent immediately to the client. You can optionally set the
Content-Type
header of the response to pass additional metadata to your client about the contents of the stream.
Writing to the response stream
The
responseStream
object implements Node’s
write()
method to write information to the stream. However, we recommend that you use
wherever possible to write to the stream. This can improve performance, ensuring that a faster readable stream does not overwhelm the writable stream.
An example function using
pipeline()
showing how you can stream compressed data:
const pipeline = require("util").promisify(require("stream").pipeline);
const zlib = require('zlib');
const { Readable } = require('stream');
exports.gzip = awslambda.streamifyResponse(async (event, responseStream, _context) => {
// As an example, convert event to a readable stream.
const requestStream = Readable.from(Buffer.from(JSON.stringify(event)));
await pipeline(requestStream, zlib.createGzip(), responseStream);
});Ending the response stream
When using the
write()
method, you must end the stream before the handler returns. Use
responseStream.end()
to signal that you are not writing any more data to the stream. This is not required if you write to the stream with
pipeline()
.
Reading streamed responses
Response streaming introduces a new
InvokeWithResponseStream
API. You can read a streamed response from your function via a Lambda function URL or use the Amazon Web Services SDK to call the new API directly.
Neither API Gateway nor Lambda’s target integration with Application Load Balancer support chunked transfer encoding. It therefore does not support faster TTFB for streamed responses. You can, however, use response streaming with API Gateway to return larger payload responses, up to API Gateway’s 10 MB limit. To implement this, you must configure an
HTTP_PROXY
integration between your API Gateway and a Lambda function URL, instead of using the
LAMBDA_PROXY
integration.
You can also configure CloudFront with a function URL as origin. When streaming responses through a function URL and CloudFront, you can have faster TTFB performance and return larger payload sizes.
Using Lambda response streaming with function URLs
You can configure a function URL to invoke your function and stream the raw bytes back to your HTTP client via chunked transfer encoding. You configure the Function URL to use the new
InvokeWithResponseStream
API by changing the invoke mode of your function URL from the default
BUFFERED
to
RESPONSE_STREAM
.
RESPONSE_STREAM
enables your function to stream payload results as they become available if you wrap the function with the
streamifyResponse()
decorator. Lambda invokes your function using the
InvokeWithResponseStream
API. If
InvokeWithResponseStream
invokes a function that is not wrapped with
streamifyResponse()
, Lambda does not stream the response. However, this response is subject to the
InvokeWithResponseStream
API endpoint’s 20MB soft limit rather than a 6 MB size limit.
Using
InvokeMode
property:
MyFunctionUrl:
Type: AWS::Lambda::Url
Properties:
TargetFunctionArn: !Ref StreamingFunction
AuthType: AWS_IAM
InvokeMode: RESPONSE_STREAMUsing generic HTTP client libraries with function URLs
Each language or framework may use different methods to form an HTTP request and parse a streamed response. Some HTTP client libraries only return the response body after the server closes the connection. These clients do not work with functions that return a response stream. To get the benefit of response streams, use an HTTP client that returns response data incrementally. Many HTTP client libraries already support streamed responses, including the Apache
HttpClient
for Java, Node’s built-in
http
client, and Python’s
requests
and
urllib3
packages. Consult the documentation for the HTTP library that you are using.
Example applications
There are a number of example Lambda streaming applications in the
Clone the repository and explore the examples. The README file in each pattern folder contains additional information.
git clone https://github.com/aws-samples/serverless-patterns/
cd serverless-patternsTime to first byte using write()
-
To show how streaming improves time to first bite, deploy the
lambda-streaming-ttfb-write-sam pattern. - Use Amazon Web Services SAM to deploy the resources to your Amazon Web Services account. Run a guided deployment to set the default parameters for the first deployment.
- Enter a Stack Name and accept the initial defaults.
-
Use
curlwith your Amazon Web Services credentials to view the streaming response as the URL usesAmazon Web Services Identity and Access Management (IAM) for authorization. Replace the URL and Region parameters for your deployment.
cd lambda-streaming-ttfb-write-samsam deploy -g --stack-name lambda-streaming-ttfb-write-sam
For subsequent deployments you can use
sam deploy
.
Amazon Web Services SAM deploys a Lambda function with streaming support and a function URL.
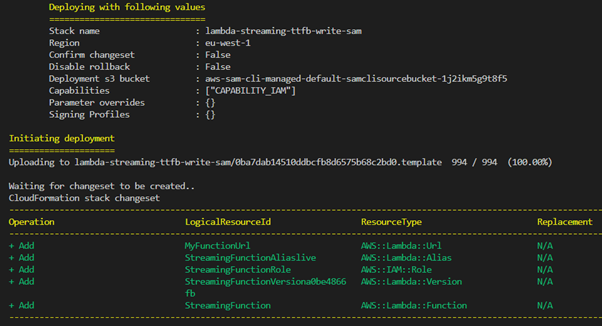
Amazon Web Services SAM deploy –g
Once the deployment completes, Amazon Web Services SAM provides details of the resources.
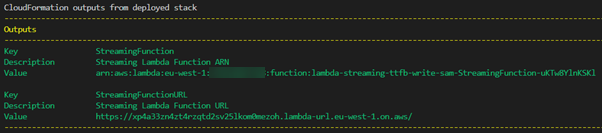
Amazon Web Services SAM resources
The Amazon Web Services SAM output returns a Lambda function URL.
curl --request GET https://<url>.lambda-url.<Region>.on.aws/ --user AKIAIOSFODNN7EXAMPLE:wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY --aws-sigv4 'aws:amz:<Region>:lambda'You can see the gradual display of the streamed response.
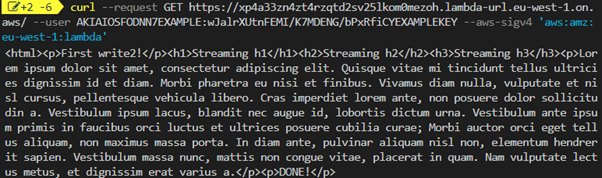
Using curl to stream response from write () function
Time to first byte using pipeline()
-
To try an example using
pipeline(), deploy thelambda-streaming-ttfb-pipeline-sam pattern. - Use Amazon Web Services SAM to deploy the resources to your Amazon Web Services account. Run a guided deployment to set the default parameters for the first deploy.
- Enter a Stack Name and accept the initial defaults.
-
Use
curlwith your Amazon Web Services credentials to view the streaming response. Replace the URL and Region parameters for your deployment.
cd ..
cd lambda-streaming-ttfb-pipeline-samsam deploy -g --stack-name lambda-streaming-ttfb-pipeline-samcurl --request GET https://<url>.lambda-url.<Region>.on.aws/ --user AKIAIOSFODNN7EXAMPLE:wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY --aws-sigv4 'aws:amz:<Region>:lambda'You can see the pipelined response stream returned.
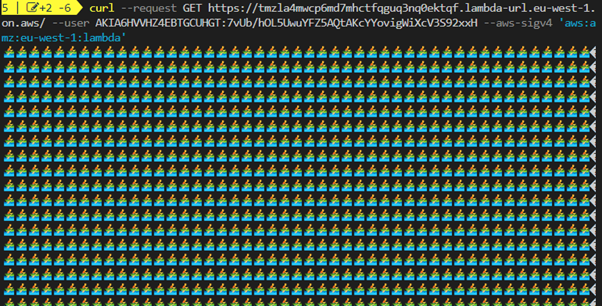
Using curl to stream response from function
Large payloads
-
To show how streaming enables you to return larger payloads, deploy the
lambda-streaming-large-sam application. Amazon Web Services SAM deploys a Lambda function, which returns a 7 MB PDF file which is larger than Lambda’s non-stream 6 MB response payload limit. -
The Amazon Web Services SAM output returns a Lambda function URL. Use
curlwith your Amazon Web Services credentials to view the streaming response.
cd ..
cd lambda-streaming-large-sam
sam deploy -g --stack-name lambda-streaming-large-samcurl --request GET https://<url>.lambda-url.<Region>.on.aws/ --user AKIAIOSFODNN7EXAMPLE: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY --aws-sigv4 'aws:amz:<Region>:lambda' -o SVS401-ri22.pdf -w '%{content_type}'
This downloads the PDF file
SVS401-ri22.pdf
to your current directory and displays the content type as
application/pdf
.
You can also use API Gateway to return a large payload with an
HTTP_PROXY
integration with a Lambda function URL.
Invoking a function with response streaming using the Amazon Web Services SDK
You can use the Amazon Web Services SDK to stream responses directly from the new Lambda
InvokeWithResponseStream
API. This provides additional functionality such as handling midstream errors. This can be helpful when building, for example, internal microservices. Response streaming is supported with the
The SDK response returns an event stream that you can read from. The event stream contains two event types.
PayloadChunk
contains a raw binary buffer with partial response data received by the client.
InvokeComplete
signals that the function has completed sending data. It also contains additional metadata, such as whether the function encountered an error in the middle of the stream. Errors can include unhandled exceptions thrown by your function code and function timeouts.
Using the Amazon Web Services SDK for Javascript v3
-
To see how to use the Amazon Web Services SDK to stream responses from a function, deploy the
lambda-streaming-sdk-sam pattern. - Enter a Stack Name and accept the initial defaults.
cd ..
cd lambda-streaming-sdk-sam
sam deploy -g --stack-name lambda-streaming-sdk-samAmazon Web Services SAM deploys three Lambda functions with streaming support.
- HappyPathFunction : Returns a full stream.
- MidstreamErrorFunction : Simulates an error midstream.
- TimeoutFunction : Function times out before stream completes.
npm install @aws-sdk/client-lambda
node index.mjsYou can see each function and how the midstream and timeout errors are returned back to the SDK client.

Streaming midstream error
Streaming timeout error
Quotas and pricing
Streaming responses incur an additional cost for network transfer of the response payload. You are billed based on the number of bytes generated and streamed out of your Lambda function over the first 6 MB. For more information, see
There is an initial maximum response size of 20 MB, which is a soft limit you can increase. The first 6MB of the response payload is streamed without any bandwidth constraints. Beyond 6MB, there is a maximum bandwidth throughput limit of 16 Mbps (2 MB/s).
Conclusion
Today,
There are a number of example Lambda streaming applications in the
Lambda response streaming support is also available through many
For more serverless learning resources, visit
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.