We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Introducing Amazon CloudWatch Internet Monitor
Amazon Web Services has just announced the release of a new internet monitoring service,
Internet Monitor provides continuous observability of internet measurements, such as availability and performance, tailored to your workload footprint on Amazon Web Services. You can use Internet Monitor to get insights into average internet performance metrics over time, and about issues (events) by location and internet service provider (ISP). Using Internet Monitor, you can easily identify which events are impacting end user experience for applications hosted by
Internet Monitor bridges the network path of the internet between your users and your application, creating a complete CloudWatch stack:
-
User experience –
CloudWatch Synthetics andCloudWatch Real User Monitoring (RUM) - Internet health – Internet Monitor
-
Application stack health –
CloudWatch ServiceLens andAmazon Web Services X-Ray -
Resource health –
CloudWatch Metrics andCloudWatch Logs
Internet Monitor components
Before we show you how Internet Monitor works, let’s define some core components and concepts.
- Monitor : A monitor is the container for your configuration that defines the resources to monitor.
- Health event : When Internet Monitor detects significant performance degradation in your traffic, it creates a health event. Each health event includes information about the impacted client locations and network providers (ISPs).
- Performance and availability scores (health scores) : A statistical estimate of the percentage of traffic to your application that is not experiencing a performance or availability drop, respectively. These scores are also available as CloudWatch metrics.
- CloudWatch Logs : For locations and network providers specific to your clients, Internet Monitor publishes measurements to CloudWatch Logs that include performance and availability scores, bytes transferred, and round-trip time (RTT).
How it works
Internet Monitor leverages data that Amazon Web Services is already collecting, between the different Amazon Web Services Regions and edge locations, and the networks from which your customers access your application endpoints. This connectivity data is used internally by Amazon Web Services, to proactively detect connectivity issues across the internet, and then take measures to improve customer experiences.
For every Amazon Web Services Region, we know which portions of the internet communicate with the Region, so that we can actively monitor them. We use both network and higher-level protocol probes, inbound and outbound. With those performance and availability measurements as a baseline, we calculate health scores to raise awareness for you when there are significant problems for your end users in different geographic locations. When you create a monitor, Internet Monitor creates a traffic profile based on your resources, describing user locations and the percentage of traffic to each one. Your traffic profile is then overlayed with the Amazon Web Services baseline performance profile, from which we calculate the performance and availability scores that show estimated drops from the baseline.
Internet Monitor also provides insights and recommendations for improving time to first byte (TTFB), by displaying performance metrics for using different Amazon Web Services services or rerouting your traffic. This can help you understand how your users’ experience could be improved by using Amazon CloudFront, or by rerouting your workload traffic through different Amazon Web Services Regions.
Alerting on health events
After you create a monitor, you have several options for how to be alerted about Internet Monitor health events. What you choose might depend, for example, on your requirements for filtering, historical records types, and actions for when the alarm is triggered. Health event alert options include:
-
CloudWatch Alarms , based on the Internet Monitor events metrics for performance and availability scores - CloudWatch Alarms, based on a metric generated using a metric filter in CloudWatch Logs
-
Amazon EventBridge rules, to filter the health events generated by Internet Monitor
A CloudWatch Alarm is useful when you need additional metrics to track user experience metrics at a more granular level in your application dashboard. You might also opt to use alarms if you need alerts when your users experience impact that doesn’t result in Internet Monitor creating a health event. EventBridge allows you to create event-driven automated responses for events generated by Internet Monitor.
Prerequisites
For the following sections, we assume that you are familiar with fundamental Amazon Web Services networking services, such as VPCs and CloudFront distributions. We also assume that you are familiar with setting up WorkSpaces directories. We won’t focus on defining each service, but will outline the steps required for using them with Internet Monitor. You can find detailed information about Amazon Web Services resources in the corresponding
Internet Monitor setup
Let’s consider a use case where you have a web application hosted in
You can start using Internet Monitor by simply creating a monitor and adding your resources, and then configure CloudWatch alarms to notify you of health events.
Monitoring an EC2-hosted web application
Step 1: Create a monitor in CloudWatch Internet Monitor
To create a monitor, in the CloudWatch console, on the Internet Monitor page, choose Create monitor . Enter a name for your monitor, and then choose Add resources . In our example, we’ll add a VPC, because we have an EC2-hosted web application. On the resources page, select the VPC, and then choose Add . Choose Next , review the configuration, and then choose Create monitor . The monitor takes a few minutes to become active.
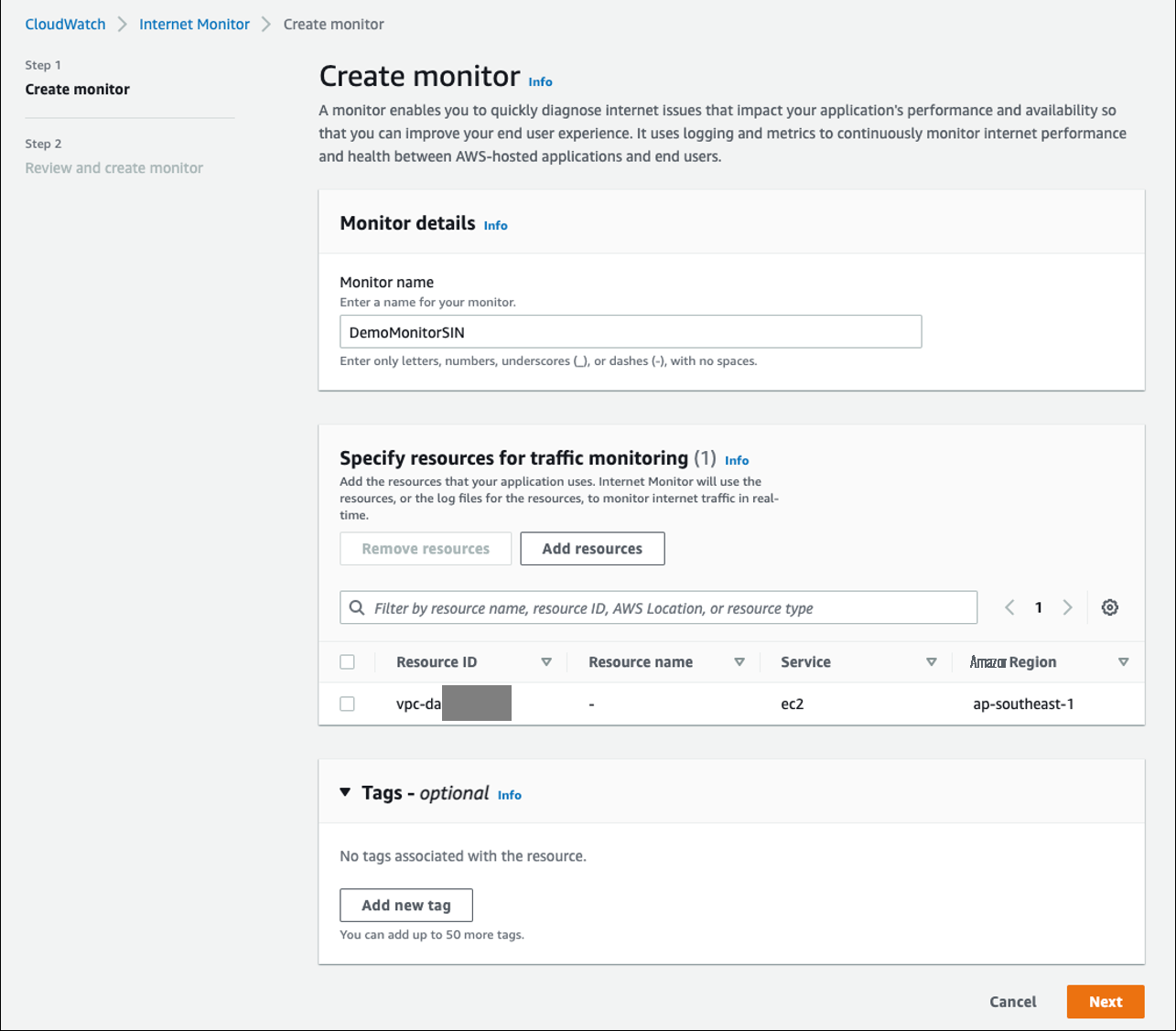
Figure 1 – Creating a monitor in the Internet Monitor console
Depending on your workloads, and their monitoring needs, you might need to create a separate monitor in Internet Monitor for different groups of resources. In our case, we’ll create a separate monitor for WorkSpaces directories.
Step 2: Alerts configuration example
For alerting, we’ll use Amazon EventBridge. Given our example application requirements and user base, we’ll define a threshold for the availability score of 50% and a threshold for the performance score of 50%, and specify the total traffic impacted to be at least 1% of traffic. Our EventBridge rule will create a log, and then send a notification to an SNS queue for events that match the above criteria. (The values here are only intended as an example. You should set thresholds at levels that make sense for your applications and business.)
To configure an events filter, in the Amazon Web Services Management Console, navigate to Amazon EventBridge. Choose Create EventBridge rule , and then enter a relevant name and description. Use the Default event bus for the rule, and for the event source, select Other . Skip the sample event configuration, and then, for the Creation method , choose Custom pattern . We entered the following, for example:
Next, we’ll configure two targets for our events: a new
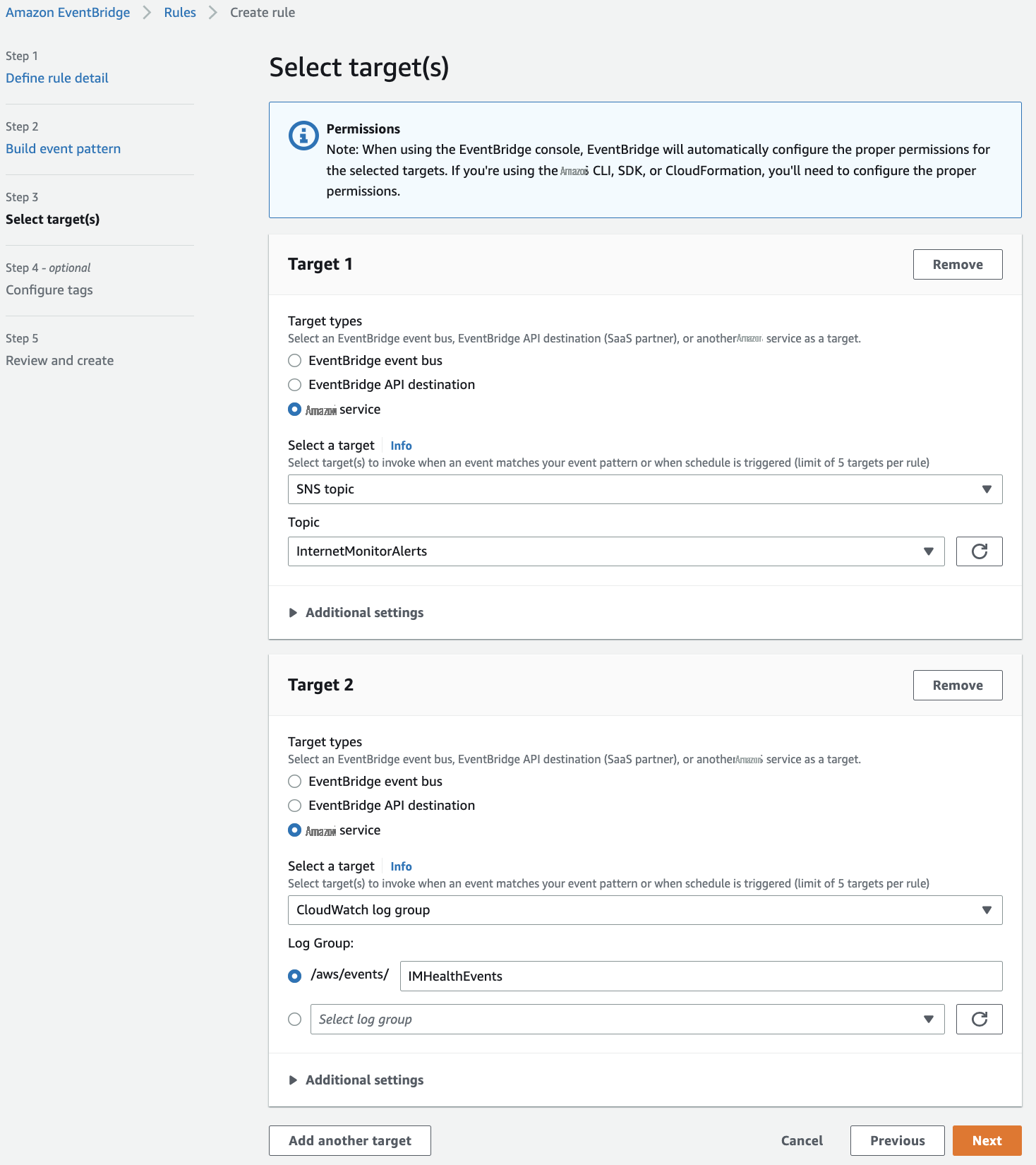
Figure 2 – Configuring EventBridge Rule targets
Monitoring Amazon WorkSpaces directories resources
Step 1: Create a monitor for WorkSpaces directories
We’ll follow the same steps that we completed earlier and create a monitor for our WorkSpaces directories resource. You can choose to group resources in a single monitor, for some resource types, if they have similar monitoring requirements. However, WorkSpaces directories can’t be added to the same monitor as VPCs in Internet Monitor, so we’ll create a new monitor.
Step 2: Alerts configuration example
A critical metric for customers using WorkSpaces directories is round-trip time (RTT). RTT impacts the performance experience for an end user when it’s greater than 100ms. For our use case, we’ll create a custom metric to visualize the RTT for only North American end users. The steps for this are the following:
a) Filter Internet Monitor event logs based on client location.
b) Create a custom CloudWatch metric filter for Internet Monitor event logs.
c) Configure an alarm based on the custom metric.
Let’s look at the configuration flow in more detail.
a) Filter Internet Monitor event logs based on client location
In the CloudWatch Logs console, you can visualize Internet Monitor log data in JSON format in the namespace /aws/internet-monitor/<your-monitor-name>/<granularity> . In our example, with our North America customers, country level granularity is most useful. The log streams inside contain the individual measurement events. Each event contains both geographical and network information for client locations, traffic statistics, availability scores, and performance scores. This is the same information that is aggregated and displayed on the Internet Monitor console.

Figure 3 – Example Internet Monitor event log in JSON format
To filter the Internet Monitor logs, we’ll use the clientLocation.countryCode field with the following setting: {$.clientLocation.countryCode=US || $.clientLocation.countryCode=CA} . This allows us to visualize the log events for client locations in either the US or Canada.
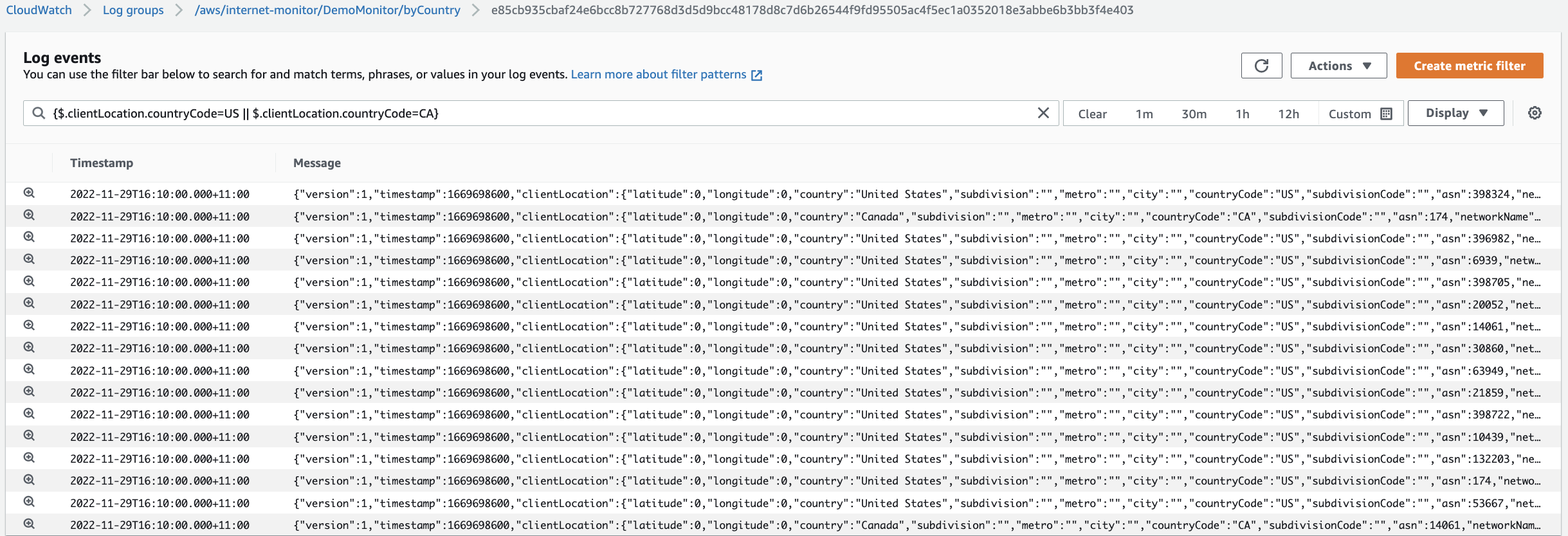 Figure 4 – Internet Monitor log stream filtered to show only events with a client location in North America
Figure 4 – Internet Monitor log stream filtered to show only events with a client location in North America
b) Create a CloudWatch metric filter for Internet Monitor event logs
After logs are filtered based on client location, we choose Create metric filter , and configure the filter metric name and namespace, to group related custom metrics. For this example, we’re generating a metric based on the 90th percentile (p90) RTT value, internetHealth.performance.roundTripTime.p90 . The p90 sensitivity of the metric allows us to alert on anomalies that would be missed if we used the average, and avoids too-frequent triggers.
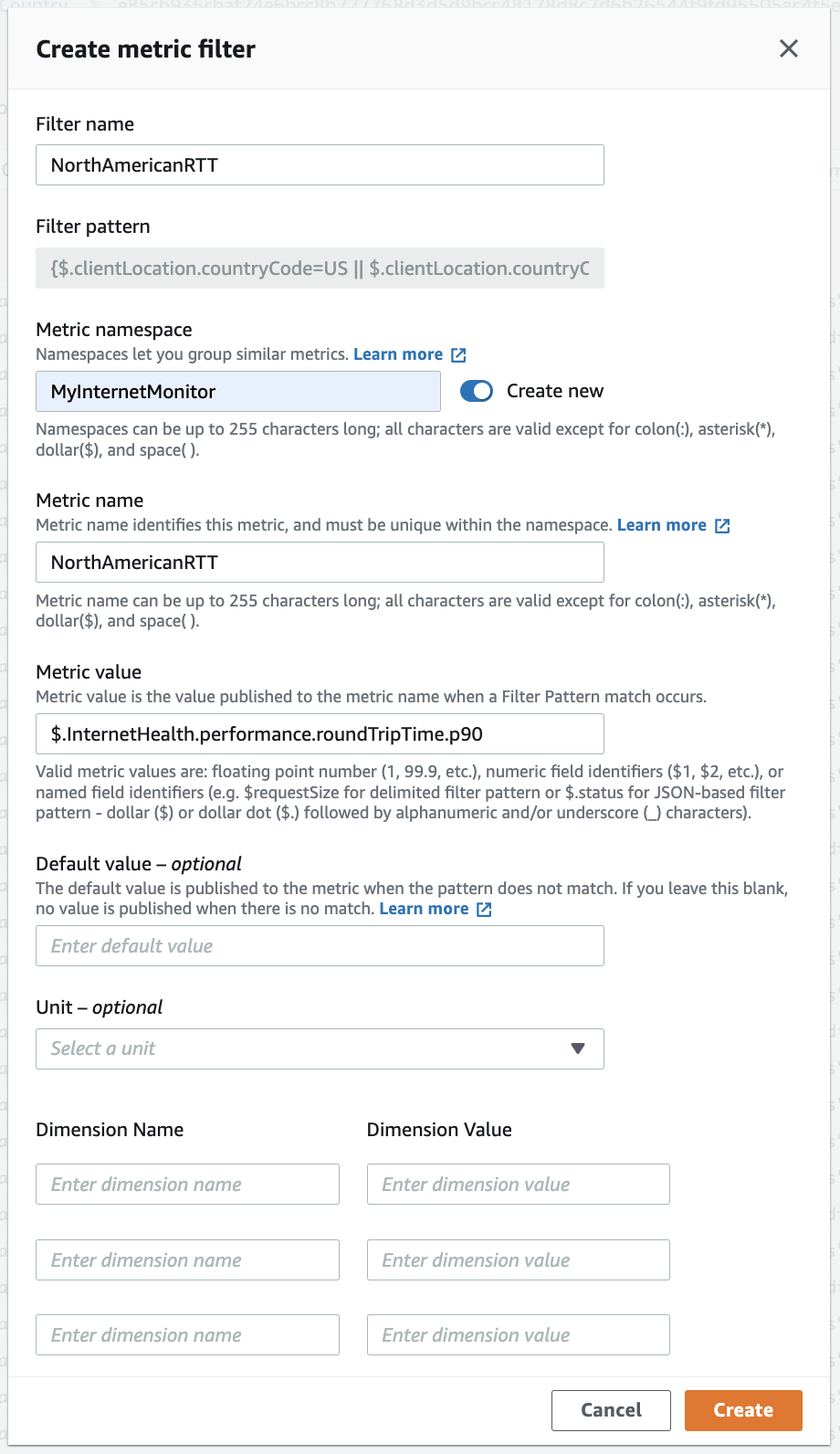
Figure 5 – Creating a metric filter based on Internet Monitor log events using the CloudWatch Logs console
You can use p50, p90, or p95 in your configuration, depending on your requirements. For more details on measurement percentiles, see the
c). Configure an Alarm based on the custom metric
To create an alarm based on our new metric, we will use the CloudWatch Alarms console and select the newly created metric for our monitor. We chose 100ms as the threshold condition for the RTT, as an example. You can also create an alarm that uses anomaly detection instead of a static threshold, for a more accurate user experience analysis. For details on anomaly detection, see the
After we’ve configured the alarm threshold conditions, we select the SNS topic to send alerts to, and then create the alarm, as shown in the following figure.
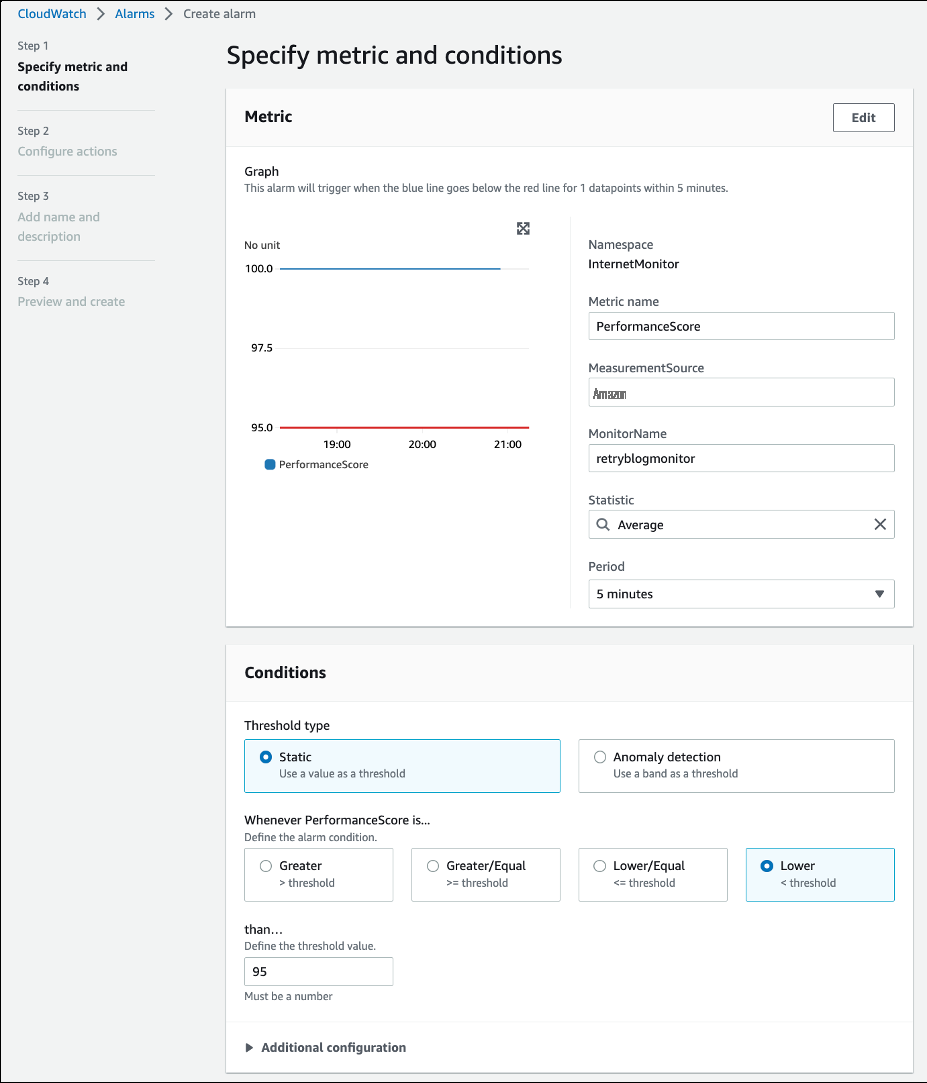
Figure 6 – Specifying an Internet Monitor metric, and configuring threshold in CloudWatch Alarms console
Analyzing an Internet Monitor event
Now imagine that you’ve received an alert that performance or availability has dropped below one of the thresholds that you configured. To start investigating, click through to the Overview tab of the Internet Monitor console for your monitor. The Overview tab displays the availability and performance scores for your monitored resources, as well as related active health events.
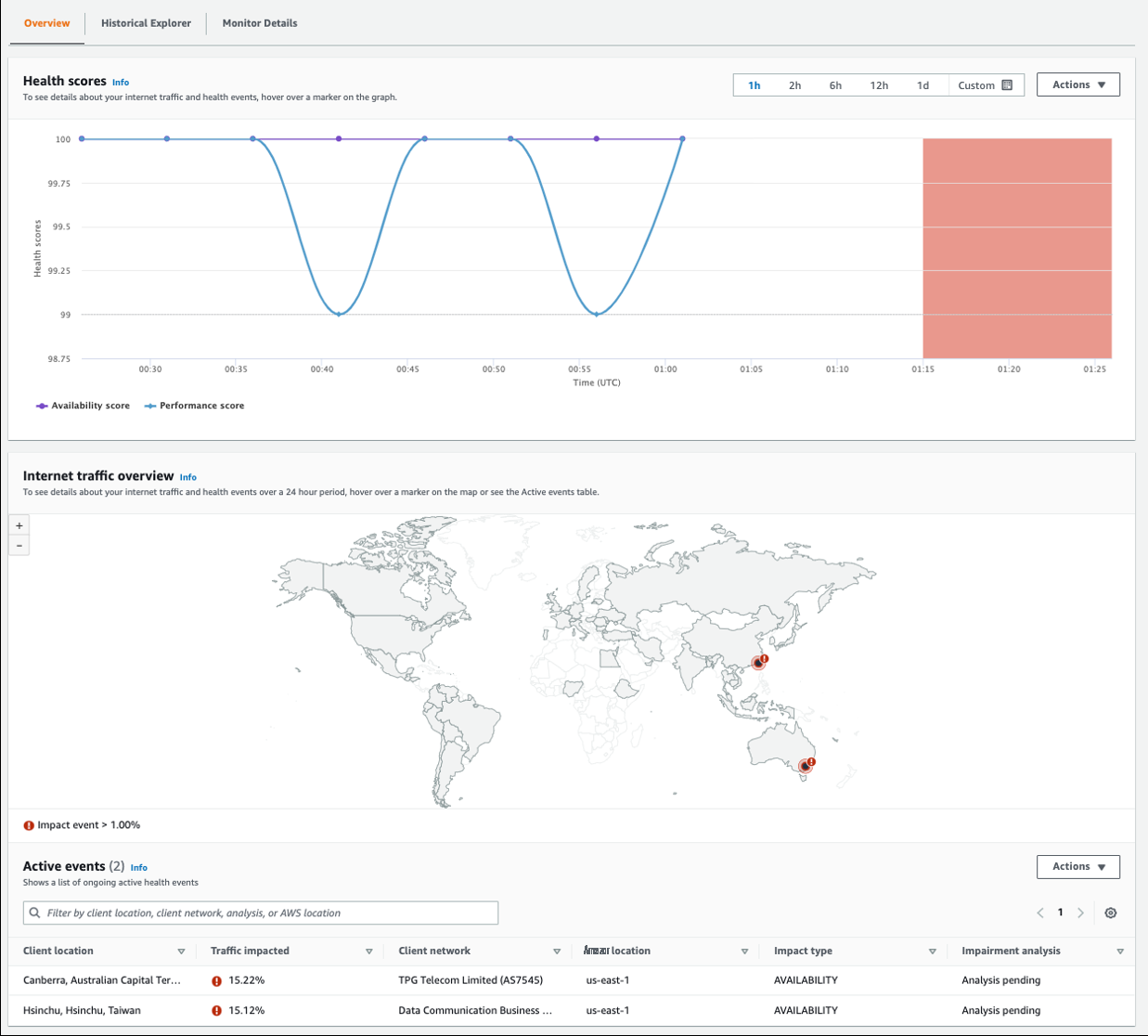
Figure 7 – Internet Monitor console Overview tab with health scores and map indicating health events in Taiwan and Australia
In this example, you can see that there are health events impacting users in Taiwan and Australia. To see more about the health events, you can download details in either CSV or JSON format. Choose Actions , and then select the format you want. The file includes all health events for the timeframe that you’ve chosen, which you can filter to include only those you’re interested in. Looking at a single event, you can see that the event details contain information such as the client location, network service provider name, ASN, percentage of traffic impacted, and more. The following is an example of an event in JSON format:
Here, 15.22% of clients in the location were affected, which was 8.66% of all clients using the application at the time.
To dive deeper into the user experience, navigate to the Historical explorer tab to visualize more performance metrics, filtered by geographies or network providers, and by timeframe.
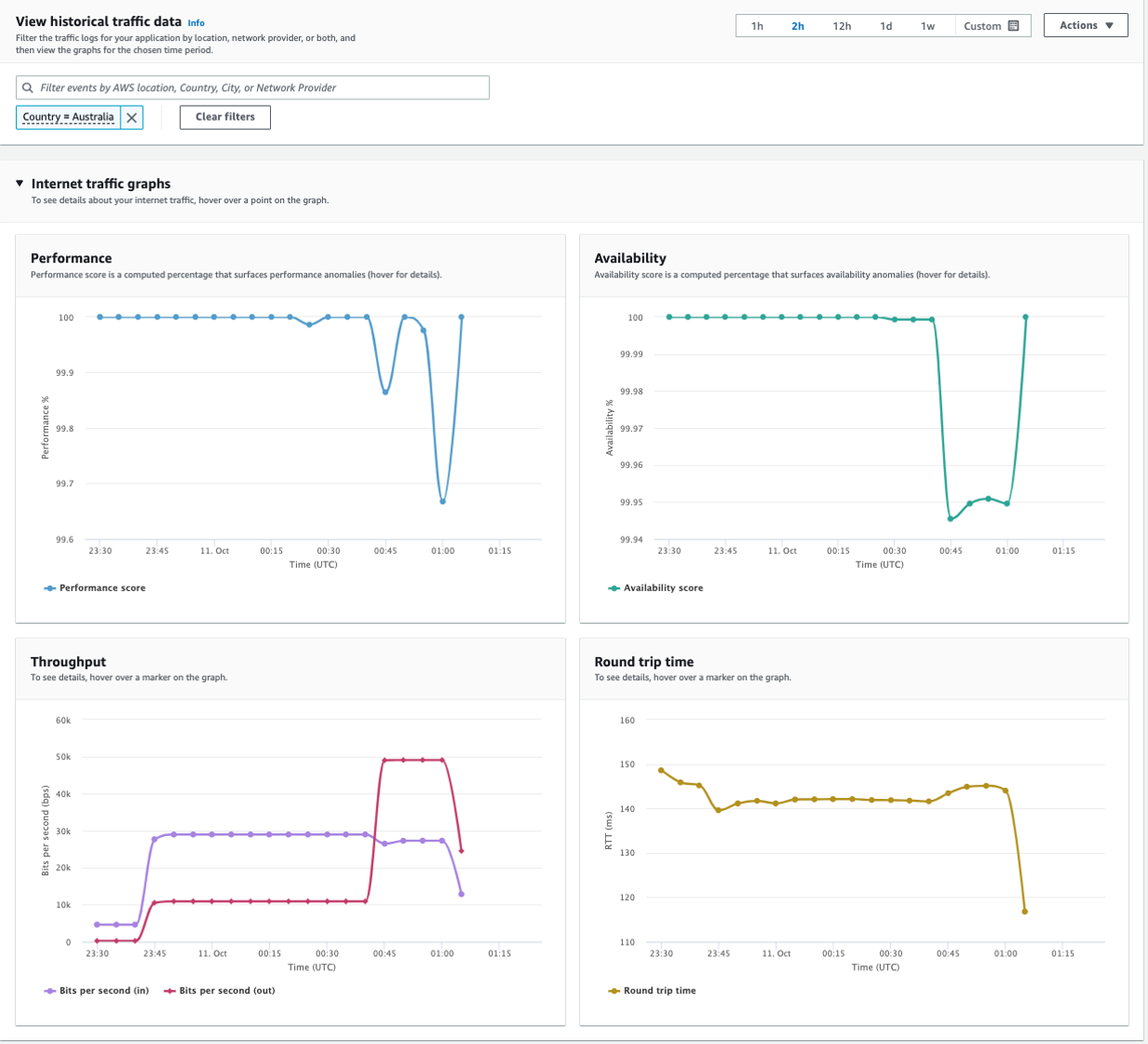
Figure 8 – Internet Monitor Historical explorer tab showing internet traffic graphs filtered to Australia
Using Internet Monitor to optimize application delivery
For events like the one we’re exploring here, which appears to be caused by issues at the client network provider, you have a few possible actions that you can take in the short term:
- If your application is already served from multiple Regions, you might be able to shift impacted traffic to resources in a different Amazon Web Services Region that is reachable by a different internet path.
- Contact the network provider to see if they’re aware of the issue, and working on a resolution. This may not be an option for providers outside of your immediate area.
- Update your own status page or social media, to inform users that issues they’re experiencing in a location are due to internet performance in that area.
- Prepare your customer support to answer questions from your affected customers.
A potential long term approach can be to improve application delivery for your end users, by using a service like Amazon CloudFront, for example, to minimize the internet path that your client traffic is traversing. All traffic from the Amazon Web Services POP nearest to your users and your origin resources or endpoints in an Amazon Web Services Region is carried over the Amazon Web Services global network.
You can use the Traffic insights tab to explore ways to improve your application performance in different locations, sorted by availability and performance scores, or by time to first byte (TTFB). You can also use geographical or network provider filters, to dive further into the data for a particular area.
Under Traffic optimization suggestions , Internet Monitor also provides predictions of estimated TTFB improvements if you switch to using EC2 or CloudFront resources, or route your traffic through other Amazon Web Services Regions or edge locations, for your top combinations of client locations and network providers. Try different options to see what yields the best results for each combination.
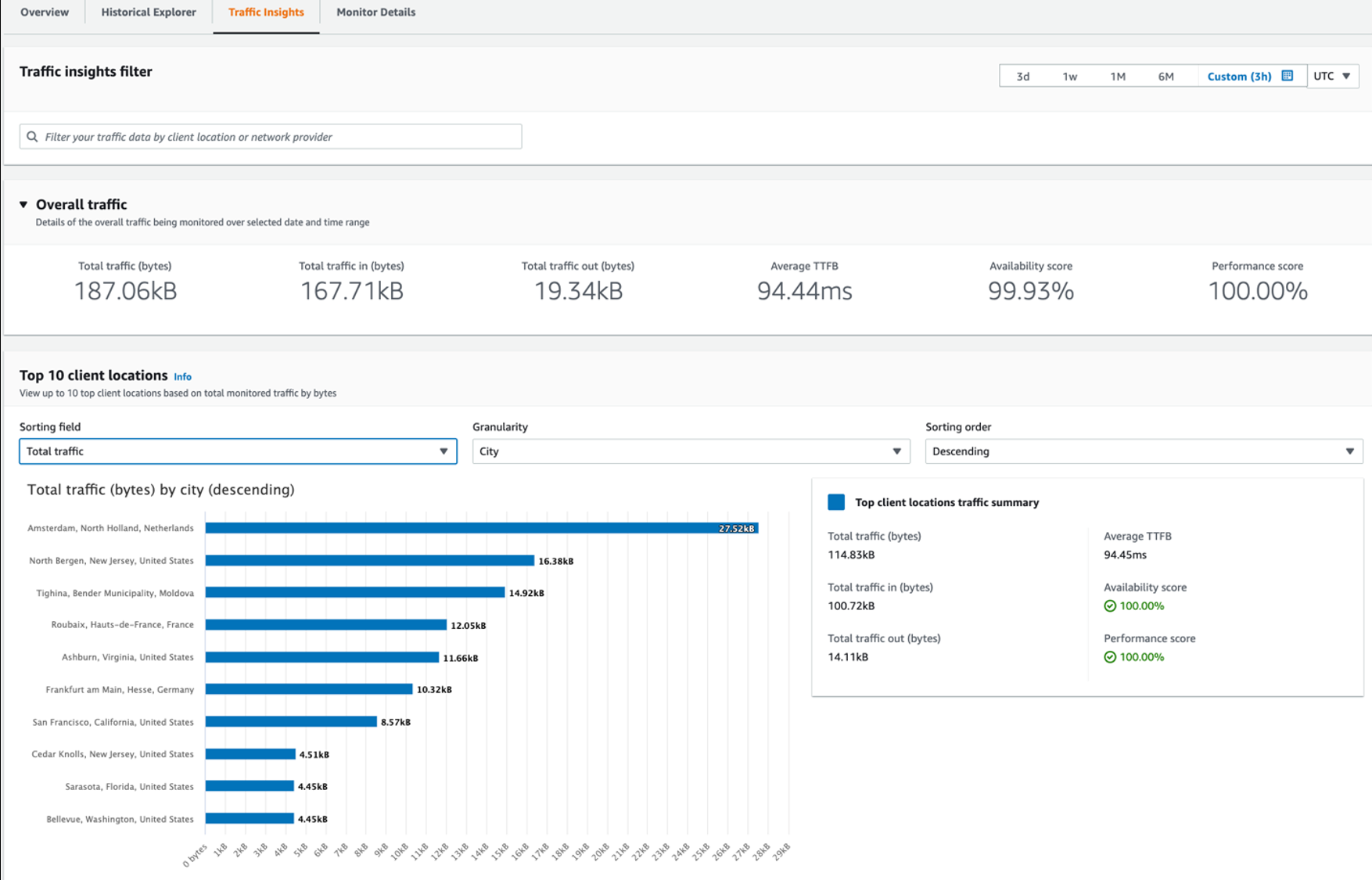
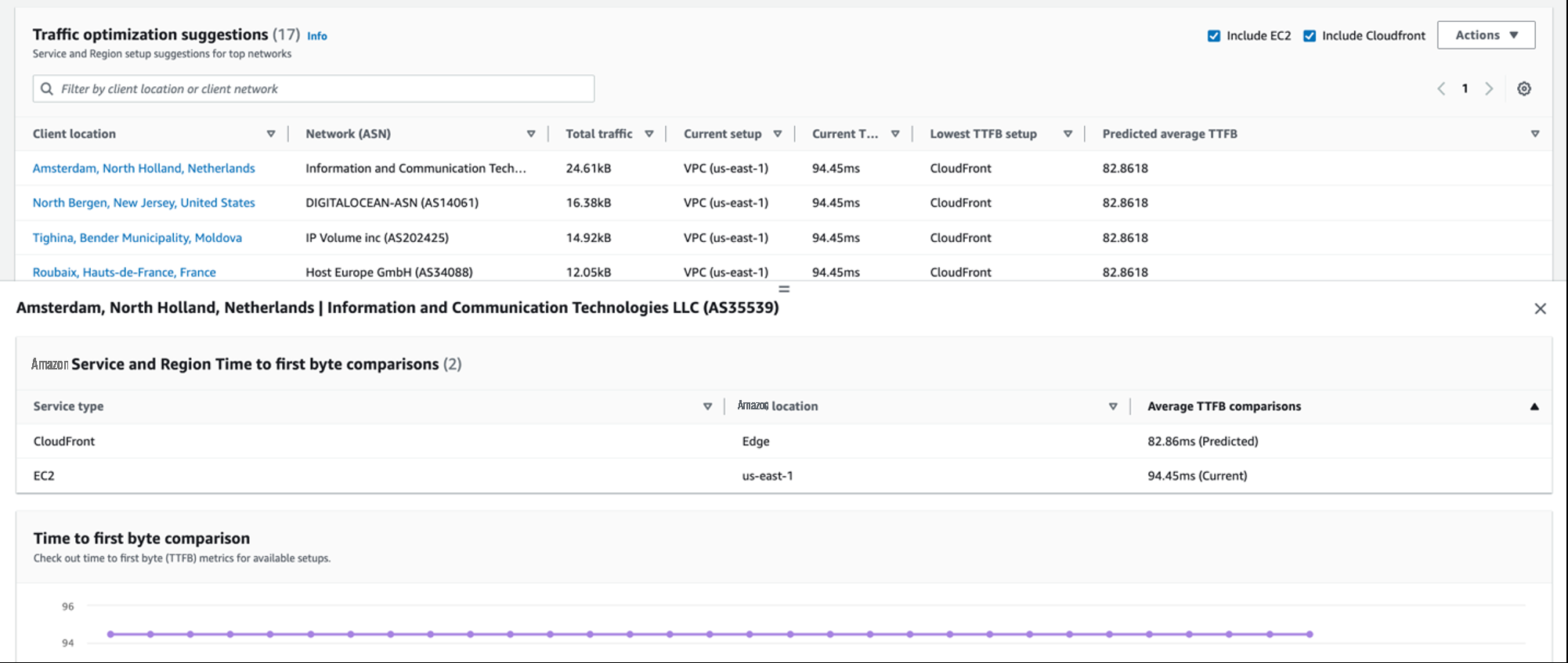
Figure 9 – Internet Monitor Traffic Insights tab showing total traffic by client location graph, and traffic optimization suggestions
Environment clean up
When you’re finished exploring Internet Monitor’s features, be sure you clean up your test environment and delete the resources that you created. Start by deleting your monitor, and then any other resources that you created, including: EventBridge rules, CloudWatch Logs rules, alarms, metrics, log groups, and SNS topics.
Things to know
- If you have a group of applications in a single Amazon Web Services Region with a similar user base, create a single monitor to monitor the aggregate user experience across the group.
- A single monitor in Internet Monitor can monitor resources in multiple Regions.
- If you add VPCs and CloudFront distributions, you can’t also add WorkSpaces directories to the same monitor.
-
Internet Monitor is subject to the regular CloudWatch charges for metrics, logs, and any dashboards, alarms, or insights created. Details are available on the
CloudWatch pricing page . - Amazon Web Services CloudFormation support for Internet Monitor will be available soon.
-
Internet Monitor is currently available in
20 Amazon Web Services Regions .
Conclusion
In this blog post, we introduced Amazon CloudWatch Internet Monitor, a new service that provides visibility into the performance of your internet-facing applications, using the connectivity data that Amazon Web Services captures from its global networking footprint. Internet Monitor helps you make better informed decisions, using factors that impact the experience of your end users that you wouldn’t otherwise be aware of, so that you can optimize your workload deployment strategy. To learn more about Internet Monitor, visit the
About the authors

Alexandra Huides
Alexandra Huides is a Principal Networking Specialist Solutions Architect within Strategic Accounts at Amazon Web Services. She focuses on helping customers with building and developing networking architectures for highly scalable and resilient Amazon Web Services environments. Alex is also a public speaker for Amazon Web Services, and she focuses on helping customers adopt IPv6 and design highly scalable network architectures. Outside work, she loves sailing, especially catamarans, traveling, discovering new cultures, and reading.

Tony Hawke
Tony is a Specialist Technical Account Manager – Networking based out of Canberra, Australia. Tony has been supporting Amazon Web Services customers in Australia, New Zealand, and ASEAN across all industries since 2016. Prior to Amazon Web Services, Tony architected and operated large LAN/WANs in enterprise and higher education.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.