We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Implement a multi-object tracking solution on a custom dataset with Amazon SageMaker
The demand for multi-object tracking (MOT) in video analysis has increased significantly in many industries, such as live sports, manufacturing, and traffic monitoring. For example, in live sports, MOT can track soccer players in real time to analyze physical performance such as real-time speed and moving distance.
Since its introduction in 2021,
In the post
Following on the previous post, we have added the following contributions and modifications:
- Generate labels for a custom video dataset using Ground Truth
- Preprocess the Ground Truth generated label to be compatible with ByteTrack and other MOT solutions
-
Train the ByteTrack algorithm with a
SageMaker training job (with the option toextend a pre-built container ) - Deploy the trained model with various deployment options, including asynchronous inference
We also provide the
SageMaker is a fully managed service that provides every developer and data scientist with the ability to prepare, build, train, and deploy machine learning (ML) models quickly. SageMaker provides several built-in algorithms and container images that you can use to accelerate training and deployment of ML models. Additionally, custom algorithms such as ByteTrack can also be supported via custom-built Docker container images. For more information about deciding on the right level of engagement with containers, refer to
SageMaker provides plenty of options for model deployment, such as real-time inference, serverless inference, and asynchronous inference. In this post, we show how to deploy a tracking model with different deployment options, so that you can choose the suitable deployment method in your own use case.
Overview of solution
Our solution consists of the following high-level steps:
- Label the dataset for tracking, with a bounding box on each object (for example, pedestrian, car, and so on). Set up the resources for ML code development and execution.
- Train a ByteTrack model and tune hyperparameters on a custom dataset.
- Deploy the trained ByteTrack model with different deployment options depending on your use case: real-time processing, asynchronous, or batch prediction.
The following diagram illustrates the architecture in each step.

Prerequisites
Before getting started, complete the following prerequisites:
- Create an Amazon Web Services account or use an existing Amazon Web Services account.
-
We recommend running the source code in the
us-east-1Region. -
Make sure that you have a minimum of one GPU instance (for example,
ml.p3.2xlargefor single GPU training, orml.p3.16xlarge) for the distributed training job. Other types of GPU instances are also supported, with various performance differences. -
Make sure that you have a minimum of one GPU instance (for example,
ml.p3.2xlarge) for inference endpoint. -
Make sure that you have a minimum of one GPU instance (for example,
ml.p3.2xlarge) for running batch prediction with processing jobs.
If this is your first time running SageMaker services on the aforementioned instance types, you may have to
Set up your resources
After you complete all the prerequisites, you’re ready to deploy the solution.
-
Create a SageMaker notebook instance . For this task, we recommend using theml.t3.mediuminstance type. While running the code, we usedocker buildto extend the SageMaker training image with the ByteTrack code (thedocker buildcommand will be run locally within the notebook instance environment). Therefore, we recommend increasing the volume size to 100 GB (default volume size to 5 GB) from the advanced configuration options. For yourAmazon Web Services Identity and Access Management (IAM) role, choose an existing role or create a new role, and attach theAmazonS3FullAccess,AmazonSNSFullAccess,AmazonSageMakerFullAccess, andAmazonElasticContainerRegistryPublicFullAccesspolicies to the role. -
Clone the
GitHub repo to the/home/ec2-user/SageMakerfolder on the notebook instance you created. -
Create a newAmazon Simple Storage Service (Amazon S3) bucket or use an existing bucket.
Label the dataset
In the
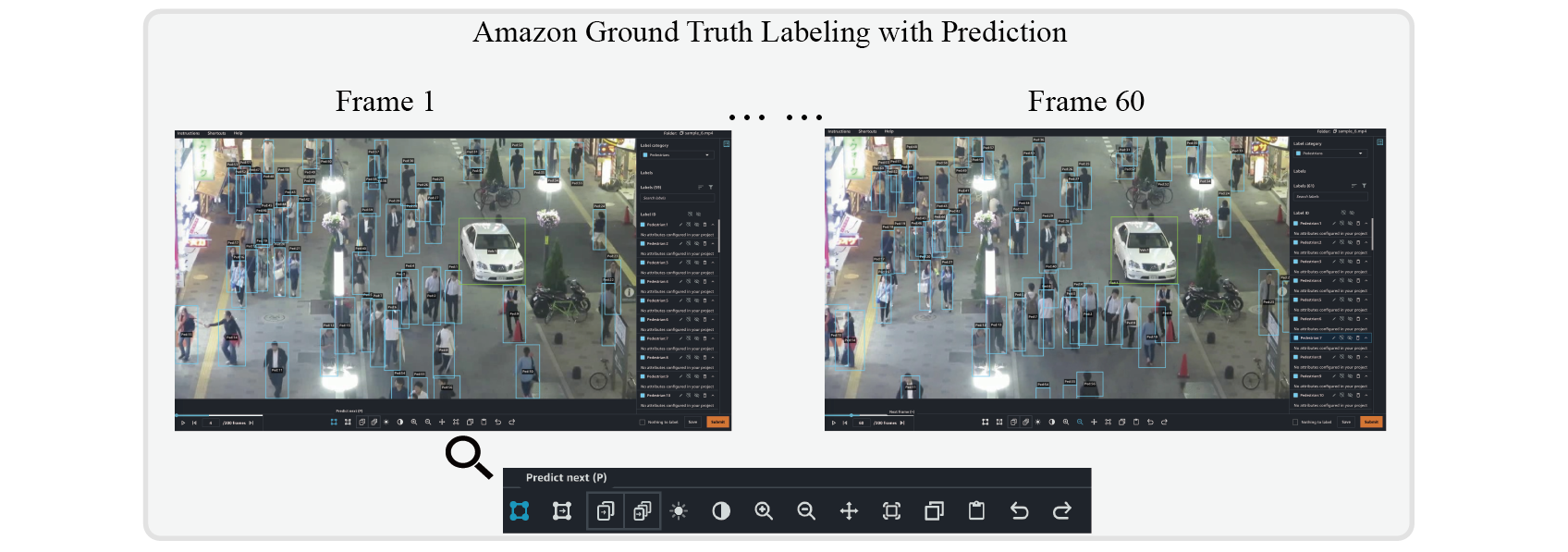
To label the dataset for the MOT task, refer to

The
manifests
directory should contain an
output
folder if we finished labeling all the files. We can see the file
output.manifest
in the
output
folder. This manifest file contains information about the video and video tracking labels that you can use later to train and test a model.
Train a ByteTrack model and tune hyperparameters on the custom dataset
To train your ByteTrack model, we use the
- Initialize the SageMaker setting.
- Perform data preprocessing.
- Build and push the container image.
- Define a training job.
- Launch the training job.
- Tune hyperparameters.
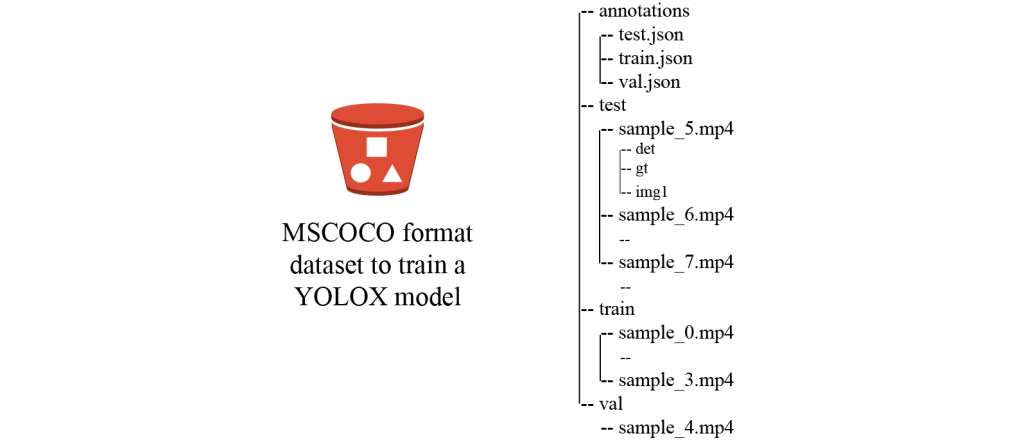
Especially in data preprocessing, we need to convert the labeled dataset with the Ground Truth output format to the MOT17 format dataset, and convert the MOT17 format dataset to a MSCOCO format dataset (as shown in the following figure) so that we can train a YOLOX model on the custom dataset. Because we keep both the MOT format dataset and MSCOCO format dataset, you can train other MOT algorithms without separating detection and tracking on the MOT format dataset. You can easily change the detector to other algorithms such as YOLO7 to use your existing object detection algorithm.
Deploy the trained ByteTrack model
After we train the YOLOX model, we deploy the trained model for inference.
Because SageMaker batch transform requires the data to be partitioned and stored on Amazon S3 as input and the invocations are sent to the inference endpoints concurrently, it doesn’t meet the requirements in object tracking tasks where the targets need to be sent in a sequential manner. Therefore, we don’t use the SageMaker batch transform jobs to run the batch inference. In this example, we use SageMaker processing jobs to do batch inference.
The following table summarizes the configuration for our inference jobs.
| Inference Type | Payload | Processing Time | Auto Scaling |
| Real-time | Up to 6 MB | Up to 1 minute | Minimum instance count is 1 or higher |
| Asynchronous | Up to 1 GB | Up to 15 minutes | Minimum instance count can be zero |
| Batch (with processing job) | No limit | No limit | Not supported |
Deploy a real-time inference endpoint
To deploy a real-time inference endpoint, we can run the
We use SageMaker PyTorchModel SDK to create and deploy a ByteTrack model as follows:
After we deploy the model to an endpoint successfully, we can invoke the inference endpoint with the following code snippet:
We run the tracking task on the client side after accepting the detection result from the endpoint (see the following code). By drawing the tracking results in each frame and saving as a tracking video, you can confirm the tracking result on the tracking video.
Deploy an asynchronous inference endpoint
SageMaker asynchronous inference is the ideal option for requests with large payload sizes (up to 1 GB), long processing times (up to 1 hour), and near-real-time latency requirements. For MOT tasks, it’s common that a video file is beyond 6 MB, which is the payload limit of a real-time endpoint. Therefore, we deploy an asynchronous inference endpoint. Refer to
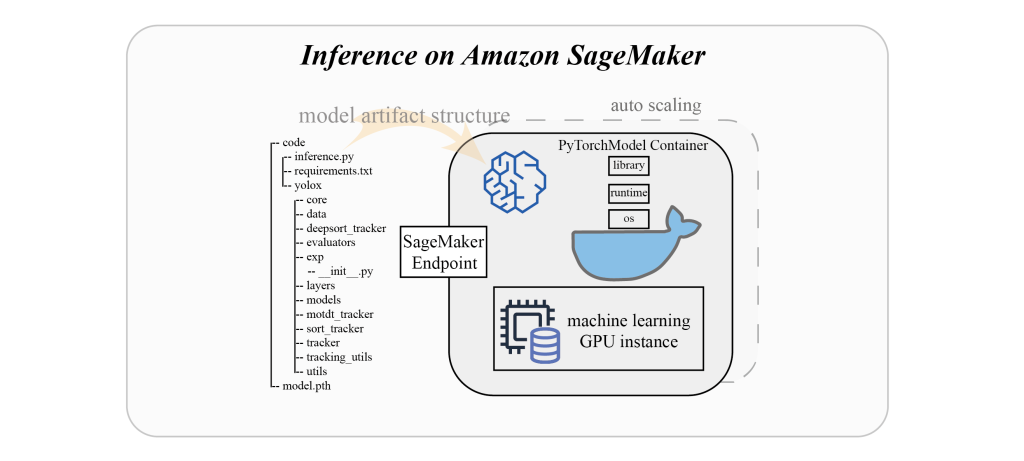
To use scripts related to ByteTrack on the endpoint, we need to put the tracking script and model into the same folder and compress the folder as the
model.tar.gz
file, and then upload it to the S3 bucket for model creation. The following diagram shows the structure of
model.tar.gz
.
We need to explicitly set the request size, response size, and response timeout as the environment variables, as shown in the following code. The name of the environment variable varies depending on the framework. For more details, refer to
When invoking the asynchronous endpoint, instead of sending the payload in the request, we send the Amazon S3 URL of the input video. When the model inference finishes processing the video, the results will be saved on the S3 output path. We can configure
Run batch inference with SageMaker processing
For video files bigger than 1 GB, we use a SageMaker processing job to do batch inference. We define a custom Docker container to run a SageMaker processing job (see the following code). We draw the tracking result on the input video. You can find the result video in the S3 bucket defined by
s3_output
.
Clean up
To avoid unnecessary costs, delete the resources you created as part of this solution, including the inference endpoint.
Conclusion
This post demonstrated how to implement a multi-object tracking solution on a custom dataset using one of the state-of-the-art algorithms on SageMaker. We also demonstrated three deployment options on SageMaker so that you can choose the optimal option for your own business scenario. If the use case requires low latency and needs a model to be deployed on an edge device, you can deploy the MOT solution at the edge with
For more information, refer to
About the Authors
 Gordon Wang
, is a Senior AI/ML Specialist TAM at Amazon Web Services. He supports strategic customers with AI/ML best practices cross many industries. He is passionate about computer vision, NLP, Generative AI and MLOps. In his spare time, he loves running and hiking.
Gordon Wang
, is a Senior AI/ML Specialist TAM at Amazon Web Services. He supports strategic customers with AI/ML best practices cross many industries. He is passionate about computer vision, NLP, Generative AI and MLOps. In his spare time, he loves running and hiking.
 Yanwei Cui, PhD
, is a Senior Machine Learning Specialist Solutions Architect at Amazon Web Services. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building artificial intelligence powered industrial applications in computer vision, natural language processing and online user behavior prediction. At Amazon Web Services, he shares the domain expertise and helps customers to unlock business potentials, and to drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
Yanwei Cui, PhD
, is a Senior Machine Learning Specialist Solutions Architect at Amazon Web Services. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building artificial intelligence powered industrial applications in computer vision, natural language processing and online user behavior prediction. At Amazon Web Services, he shares the domain expertise and helps customers to unlock business potentials, and to drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
 Melanie Li, PhD
, is a Senior AI/ML Specialist TAM at Amazon Web Services based in Sydney, Australia. She helps enterprise customers to build solutions leveraging the state-of-the-art AI/ML tools on Amazon Web Services and provides guidance on architecting and implementing machine learning solutions with best practices. In her spare time, she loves to explore nature outdoors and spend time with family and friends.
Melanie Li, PhD
, is a Senior AI/ML Specialist TAM at Amazon Web Services based in Sydney, Australia. She helps enterprise customers to build solutions leveraging the state-of-the-art AI/ML tools on Amazon Web Services and provides guidance on architecting and implementing machine learning solutions with best practices. In her spare time, she loves to explore nature outdoors and spend time with family and friends.
 Guang Yang
, is a Senior applied scientist at the Amazon ML Solutions Lab where he works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art ML/AI solutions.
Guang Yang
, is a Senior applied scientist at the Amazon ML Solutions Lab where he works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art ML/AI solutions.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.