We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Image classification model selection using Amazon SageMaker JumpStart
Researchers continue to develop new model architectures for common machine learning (ML) tasks. One such task is image classification, where images are accepted as input and the model attempts to classify the image as a whole with object label outputs. With many models available today that perform this image classification task, an ML practitioner may ask questions like: “What model should I fine-tune and then deploy to achieve the best performance on my dataset?” And an ML researcher may ask questions like: “How can I generate my own fair comparison of multiple model architectures against a specified dataset while controlling training hyperparameters and computer specifications, such as GPUs, CPUs, and RAM?” The former question addresses model selection across model architectures, while the latter question concerns benchmarking trained models against a test dataset.
In this post, you will see how the
Solution overview
The following figure illustrates the model selection trade-off for a large number of image classification models fine-tuned on the
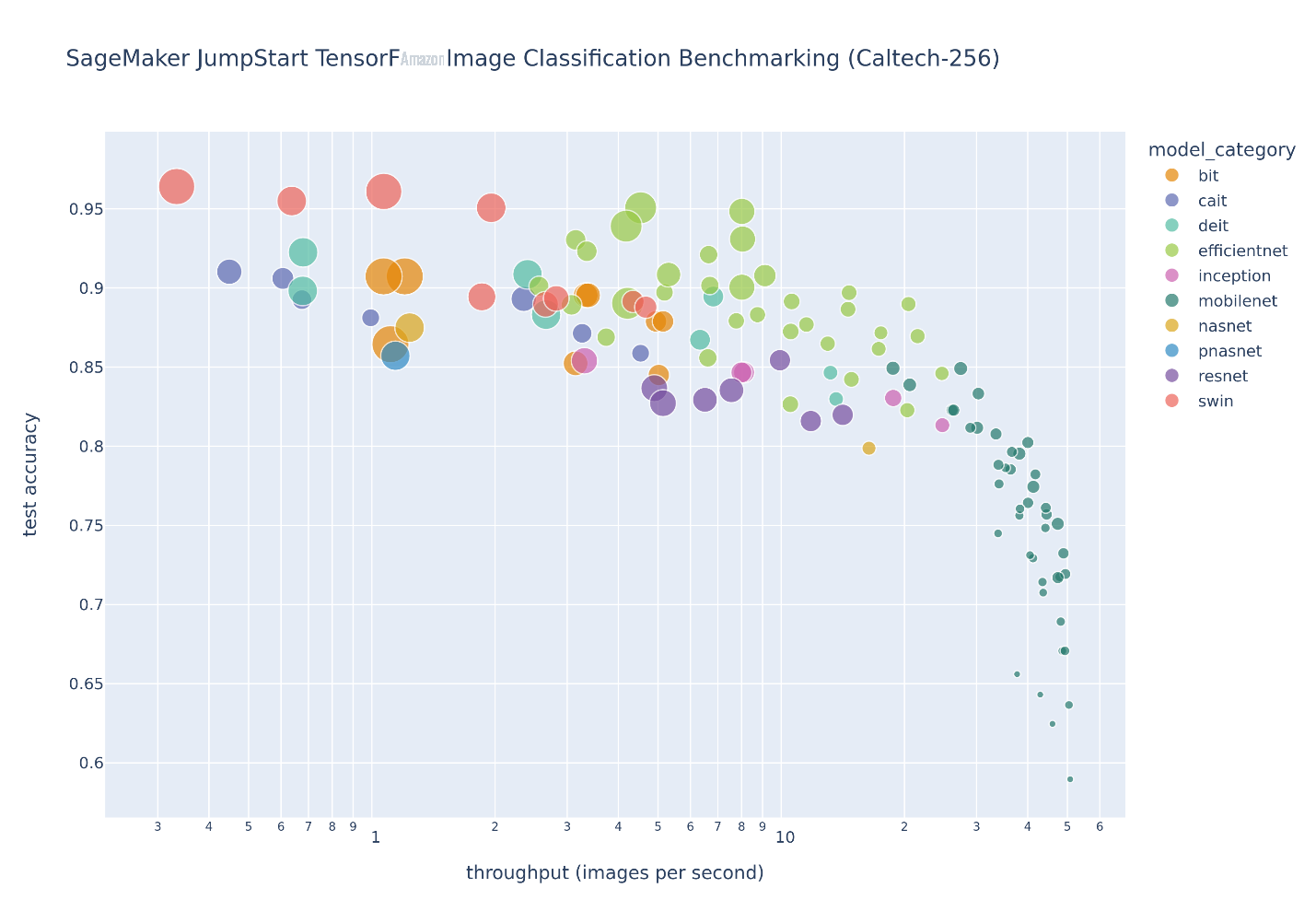
If you observe test accuracy and test throughput frontiers of interest, the set of pareto efficient solutions on the preceding figure are extracted in the following table. Rows are sorted such that test throughput is increasing and test accuracy is decreasing.
| Model Name | Number of Parameters | Test Accuracy | Test Top 5 Accuracy | Throughput (images/s) | Duration per Epoch(s) |
| swin-large-patch4-window12-384 | 195.6M | 96.4% | 99.5% | 0.3 | 2278.6 |
| swin-large-patch4-window7-224 | 195.4M | 96.1% | 99.5% | 1.1 | 698.0 |
| efficientnet-v2-imagenet21k-ft1k-l | 118.1M | 95.1% | 99.2% | 4.5 | 1434.7 |
| efficientnet-v2-imagenet21k-ft1k-m | 53.5M | 94.8% | 99.1% | 8.0 | 769.1 |
| efficientnet-v2-imagenet21k-m | 53.5M | 93.1% | 98.5% | 8.0 | 765.1 |
| efficientnet-b5 | 29.0M | 90.8% | 98.1% | 9.1 | 668.6 |
| efficientnet-v2-imagenet21k-ft1k-b1 | 7.3M | 89.7% | 97.3% | 14.6 | 54.3 |
| efficientnet-v2-imagenet21k-ft1k-b0 | 6.2M | 89.0% | 97.0% | 20.5 | 38.3 |
| efficientnet-v2-imagenet21k-b0 | 6.2M | 87.0% | 95.6% | 21.5 | 38.2 |
| mobilenet-v3-large-100-224 | 4.6M | 84.9% | 95.4% | 27.4 | 28.8 |
| mobilenet-v3-large-075-224 | 3.1M | 83.3% | 95.2% | 30.3 | 26.6 |
| mobilenet-v2-100-192 | 2.6M | 80.8% | 93.5% | 33.5 | 23.9 |
| mobilenet-v2-100-160 | 2.6M | 80.2% | 93.2% | 40.0 | 19.6 |
| mobilenet-v2-075-160 | 1.7M | 78.2% | 92.8% | 41.8 | 19.3 |
| mobilenet-v2-075-128 | 1.7M | 76.1% | 91.1% | 44.3 | 18.3 |
| mobilenet-v1-075-160 | 2.0M | 75.7% | 91.0% | 44.5 | 18.2 |
| mobilenet-v1-100-128 | 3.5M | 75.1% | 90.7% | 47.4 | 17.4 |
| mobilenet-v1-075-128 | 2.0M | 73.2% | 90.0% | 48.9 | 16.8 |
| mobilenet-v2-075-96 | 1.7M | 71.9% | 88.5% | 49.4 | 16.6 |
| mobilenet-v2-035-96 | 0.7M | 63.7% | 83.1% | 50.4 | 16.3 |
| mobilenet-v1-025-128 | 0.3M | 59.0% | 80.7% | 50.8 | 16.2 |
This post provides details on how to implement large-scale
Introduction to JumpStart TensorFlow image classification
JumpStart provides one-click fine-tuning and deployment of a wide variety of pre-trained models across popular ML tasks, as well as a selection of end-to-end solutions that solve common business problems. These features remove the heavy lifting from each step of the ML process, making it easier to develop high-quality models and reducing time to deployment. The
The JumpStart model hub provides access to a large number of
Vastly different internal structures comprise each model architecture. For instance, ResNet models utilize skip connections to allow for substantially deeper networks, whereas transformer-based models use self-attention mechanisms that eliminate the intrinsic locality of convolution operations in favor of more global receptive fields. In addition to the diverse feature sets these different structures provide, each model architecture has several configurations that adjust the model size, shape, and complexity within that architecture. This results in hundreds of unique image classification models available on the JumpStart model hub. Combined with built-in transfer learning and inference scripts that encompass many SageMaker features, the JumpStart API is a great launching point for ML practitioners to get started training and deploying models quickly.
Refer to
Large-scale model selection considerations
Model selection is the process of selecting the best model from a set of candidate models. This process may be applied across models of the same type with different parameter weights and across models of different types. Examples of model selection across models of the same type include fitting the same model with different hyperparameters (for example, learning rate) and early stopping to prevent the overfitting of model weights to the train dataset. Model selection across models of different types includes selecting the best model architecture (for example, Swin vs. MobileNet) and selecting the best model configurations within a single model architecture (for example,
mobilenet-v1-025-128
vs.
mobilenet-v3-large-100-224
).
The considerations outlined in this section enable all of these model selection processes on a validation dataset.
Select hyperparameter configurations
TensorFlow image classification in JumpStart has a large number of available
For this analysis and the associated notebook, all hyperparameters are set to default values except for learning rate, number of epochs, and early stopping specification. Learning rate is adjusted as a
One default hyperparameter setting of particular importance is
train_only_on_top_layer
, where, if set to
True
, the model’s feature extraction layers are not fine-tuned on the provided training dataset. The optimizer will only train parameters in the top fully connected classification layer with output dimensionality equal to the number of class labels in the dataset. By default, this hyperparameter is set to
True
, which is a setting targeted for transfer learning on small datasets. You may have a custom dataset where the feature extraction from the pre-training on the ImageNet dataset is not sufficient. In these cases, you should set
train_only_on_top_layer
to
False
. Although this setting will increase training time, you will extract more meaningful features for your problem of interest, thereby increasing accuracy.
Extract metrics from CloudWatch Logs
The JumpStart TensorFlow image classification algorithm reliably logs a variety of metrics during training that are accessible to SageMaker
Estimator
and HyperparameterTuner objects. The constructor of a SageMaker
Estimator
has a
metric_definitions
keyword argument, which can be used to evaluate the training job by providing a list of dictionaries with two keys: Name for the name of the metric, and
Regex
for the regular expression used to extract the metric from the logs. The accompanying
| Metric Name | Regular Expression |
| number of parameters | “- Number of parameters: ([0-9\\.]+)” |
| number of trainable parameters | “- Number of trainable parameters: ([0-9\\.]+)” |
| number of non-trainable parameters | “- Number of non-trainable parameters: ([0-9\\.]+)” |
| train dataset metric | f”- {metric}: ([0-9\\.]+)” |
| validation dataset metric | f”- val_{metric}: ([0-9\\.]+)” |
| test dataset metric | f”- Test {metric}: ([0-9\\.]+)” |
| train duration | “- Total training duration: ([0-9\\.]+)” |
| train duration per epoch | “- Average training duration per epoch: ([0-9\\.]+)” |
| test evaluation latency | “- Test evaluation latency: ([0-9\\.]+)” |
| test latency per sample | “- Average test latency per sample: ([0-9\\.]+)” |
| test throughput | “- Average test throughput: ([0-9\\.]+)” |
The built-in transfer learning script provides a variety of train, validation, and test dataset metrics within these definitions, as represented by the f-string replacement values. The exact metrics available vary based on the type of classification being performed. All compiled models have a
loss
metric, which is represented by a cross-entropy loss for either a binary or categorical classification problem. The former is used when there is one class label; the latter is used if there are two or more class labels. If there is only a single class label, then the following metrics are computed, logged, and extractable via the f-string regular expressions in the preceding table: number of true positives (
true_pos
), number of false positives (
false_pos
), number of true negatives (
true_neg
), number of false negatives (
false_neg
),
precision
,
recall
, area under the receiver operating characteristic (
ROC
) curve (
auc
), and area under the precision-recall (PR) curve (
prc
). Similarly, if there are six or more class labels, a top-5 accuracy metric (
top_5_accuracy
) is also be computed, logged, and extractable via the preceding regular expressions.
During training, metrics specified to a SageMaker
Estimator
are emitted to CloudWatch Logs. When the training is complete, you can invoke the
FinalMetricDataList
key in the JSON response:
This API requires only the job name to be provided to the query, so, once completed, metrics can be obtained in future analyses so long as the training job name is appropriately logged and recoverable. For this model selection task, hyperparameter tuning job names are stored and subsequent analyses reattach a
HyperparameterTuner
object given the tuning job name, extract the best training job name from the attached hyperparameter tuner, and then invoke the
DescribeTrainingJob
API as described earlier to obtain metrics associated with the best training job.
Launch asynchronous hyperparameter tuning jobs
Refer to the corresponding
-
Each Amazon Web Services account is affiliated with
SageMaker service quotas . You should view your current limits to fully utilize your resources and potentially request resource limit increases as needed. -
Frequent API calls to create many simultaneous hyperparameter tuning jobs may
exceed the Python SDK rate and throw throttling exceptions . A resolution to this is to create a SageMaker Boto3 client with a custom retry configuration. -
What happens if your script encounters an error or the script is stopped before completion? For such a large model selection or benchmarking study, you can log tuning job names and provide convenience functions to
reattach hyperparameter tuning jobs that already exist:
Analysis details and discussion
The analysis in this post performs transfer learning for
The test dataset is evaluated on the training instance at the end of training. Model selection is performed prior to the test dataset evaluation to set model weights to the epoch with the best validation set performance. Test throughput is not optimized: the dataset batch size is set to the default training hyperparameter batch size, which isn’t adjusted to maximize GPU memory usage; reported test throughput includes data loading time because the dataset isn’t pre-cached; and distributed inference across multiple GPUs isn’t utilized. For these reasons, this throughput is a good relative measurement, but actual throughput would depend heavily on your inference endpoint deployment configurations for the trained model.
Although the JumpStart model hub contains many image classification architecture types, this pareto frontier is dominated by select Swin, EfficientNet, and MobileNet models. Swin models are larger and relatively more accurate, whereas MobileNet models are smaller, relatively less accurate, and suitable for resource constraints of mobile devices. It’s important to note that this frontier is conditioned on a variety of factors, including the exact dataset used and the fine-tuning hyperparameters selected. You may find that your custom dataset produces a different set of pareto efficient solutions, and you may desire longer training times with different hyperparameters, such as more data augmentation or fine-tuning more than just the top classification layer of the model.
Conclusion
In this post, we showed how to run large-scale model selection or benchmarking tasks using the JumpStart model hub. This solution can help you choose the best model for your needs. We encourage you to try out and explore this
References
More information is available at the following resources:
-
Image Classification – TensorFlow -
Run image classification with Amazon SageMaker JumpStart -
Build high performing image classification models using Amazon SageMaker JumpStart
About the authors
 Dr. Kyle Ulrich
is an Applied Scientist with the
Dr. Kyle Ulrich
is an Applied Scientist with the
 Dr. Ashish Khetan
is a Senior Applied Scientist with
Dr. Ashish Khetan
is a Senior Applied Scientist with
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.