We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
How Getir build a comprehensive fraud detection system using Amazon Neptune and Amazon DynamoDB
This is a guest post co-authored by Berkay Berkman, Yağız Yanıkoğlu, Mutlu Polatcan, Mahmut Turan, Umut Cemal Kıraç from Getir.
In this post, we explain how Getir built an end-to-end fraud detection system, from gathering real-time data to detecting fraudulent activities using
Neptune is a fully managed database service built for the cloud that makes it simple to build and run graph applications. Neptune provides built-in security, continuous backups, serverless compute, and integrations with other Amazon Web Services services.
DynamoDB is a fast and flexible non-relational database service for any scale. DynamoDB enables you to offload the administrative burdens of operating and scaling distributed databases to Amazon Web Services so that you don’t have to worry about hardware provisioning, setup and configuration, throughput capacity planning, replication, software patching, or cluster scaling.
Overview of solution
In this project, five people from the data and business teams worked together: Three from the data team and two from the business audit team. The project itself was completed in 3 months, but the data analysis (detection of connected customers, determination of rule sets) took additional 3 months.
The following diagram shows the architecture of the solution.
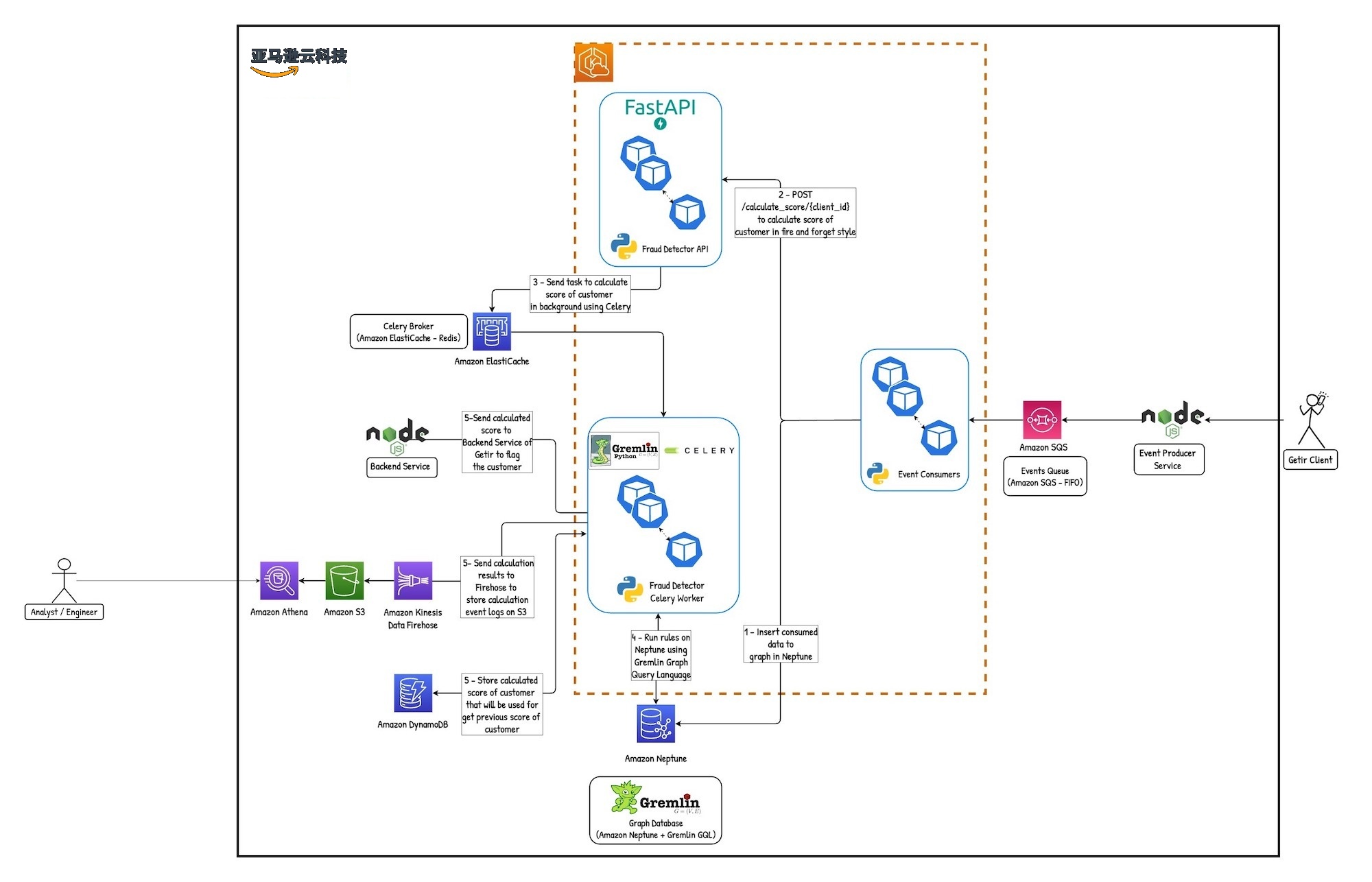
Solution details
We needed to get real-time data from the Getir clients. For this, we needed a service that would provide us with real-time data and ensure that this data reaches us in a fully managed manner. We chose
Our consumers running on
When a user logs in with new information or a new attribute, the consumer writes this new information or attribute details to Neptune in milliseconds and sends it to the data graph tree immediately.
One of the great advantages of using Amazon Neptune is the ability to use the
With the Neptune Notebook, we can use Jupyter notebooks to write code and create visualizations that allow us to interact with our graph data in real-time. This can be particularly useful when trying to identify patterns and relationships between entities, as it allows us to explore the data from multiple angles and gain a deeper understanding of the underlying structures. In addition to its interactive visualization capabilities, the Neptune Notebook also offers a range of other features that make it an ideal tool for data analysis. For example, it provides a range of pre-built templates and sample code snippets that can be used to quickly get up and running with our analysis.
After the real-time data is inserted to the database, we send it to the Calculator API. The actual score calculation is done in the calculator section. The connections between the nodes of the fraud circles can be very large and the calculations can take a long time, the API sends these calculations to the Celery workers, which are the task queues. The Celery workers need a key-value storage to retrieve tasks. We use
These assigned user scores are stored in
We send the log records to
Conclusion
Neptune has allowed us to use graph databases easily and efficiently within the team and has improved our capabilities when working with real-time data. DynamoDB was the first service we tried and it worked very well. In the data modeling part, using DynamoDB as the key-value data store prevented Neptune from slowing down day by day. We were able to optimize Neptune scaling and achieve significant cost savings, reducing our expenses. Specifically, we saved a substantial majority of our previous costs through our optimization efforts. The use of DynamoDB in high traffic has proven its power to us and has become our preferred service in more projects due to its low cost and easy usage.
Our multi-layered approach combines data analysis, user verification, fraud scoring, and machine learning. By using these techniques in combination, we can better protect ourselves and our customers from fraudulent activity by 95%, providing cost savings in marketing as well.
For more information about how to get started building your own fraud detection system using Neptune, you can explore more on
For additional resources on DynamoDB, you can learn more on
About the Authors
 B
erkay Berkman
, who holds a BSc in Computer Engineering, has experience in both data science and engineering. He has been working for Getir on the Data Platform and Engineering team as a Senior Data Engineer. Berkay enjoys working on data problems and creating solutions with cloud-native platforms.
B
erkay Berkman
, who holds a BSc in Computer Engineering, has experience in both data science and engineering. He has been working for Getir on the Data Platform and Engineering team as a Senior Data Engineer. Berkay enjoys working on data problems and creating solutions with cloud-native platforms.
 Yağız Yanıkoğlu
has more than 13 years of experience in Software Development Lifecycle. He started his career working as Backend Developer and met with Amazon Web Services in 2015. Since then, his main goal is to create secure, scalable, fault-tolerant and cost-optimized cloud solutions. He joined Getir, the pioneer of ultrafast grocery delivery, in 2020 and currently works as Senior Data Engineering & Platform Manager. His team is responsible for designing, implementing and maintaining end-to-end data platform solutions for Getir.
Yağız Yanıkoğlu
has more than 13 years of experience in Software Development Lifecycle. He started his career working as Backend Developer and met with Amazon Web Services in 2015. Since then, his main goal is to create secure, scalable, fault-tolerant and cost-optimized cloud solutions. He joined Getir, the pioneer of ultrafast grocery delivery, in 2020 and currently works as Senior Data Engineering & Platform Manager. His team is responsible for designing, implementing and maintaining end-to-end data platform solutions for Getir.
 Mutlu Polatcan
is a Staff Data Engineer at Getir, specialized in design and build cloud-native data platforms. He loves combining open-source projects with cloud services.
Mutlu Polatcan
is a Staff Data Engineer at Getir, specialized in design and build cloud-native data platforms. He loves combining open-source projects with cloud services.
 Mahmut Turan
, BA in Economics and LLB in Law, held various technical and business roles and also have extensive experience in the financial services industry in both regulated and regulatory sides, q-commerce, and technology. For more than 2 years, he has working for Getir holding various roles; internal audit manager (data & analytics), audit analytics and fraud prevention manager, and head of fraud analytics and loss prevention. His expertise is internal audit, audit analytics, data science, credit risk, and fraud risk.
Mahmut Turan
, BA in Economics and LLB in Law, held various technical and business roles and also have extensive experience in the financial services industry in both regulated and regulatory sides, q-commerce, and technology. For more than 2 years, he has working for Getir holding various roles; internal audit manager (data & analytics), audit analytics and fraud prevention manager, and head of fraud analytics and loss prevention. His expertise is internal audit, audit analytics, data science, credit risk, and fraud risk.
 Umut Cemal Kıraç
is a Fraud Analytics & Prevention Manager at Getir. He is responsible for management of company-wide fraud risks as well as audit-analytics function of Getir. He is also designated with CIA (Certified Internal Auditor) and CISA (Certified Information Systems Auditor) certifications. His area of specialty is delivering analytical solutions for business risks.
Umut Cemal Kıraç
is a Fraud Analytics & Prevention Manager at Getir. He is responsible for management of company-wide fraud risks as well as audit-analytics function of Getir. He is also designated with CIA (Certified Internal Auditor) and CISA (Certified Information Systems Auditor) certifications. His area of specialty is delivering analytical solutions for business risks.
 Esra Kayabalı
is a Senior Solutions Architect at Amazon Web Services, specializing in the analytics domain including data warehousing, data lakes, big data analytics, batch and real-time data streaming and data integration. She has 12 years of software development and architecture experience. She is passionate about learning and teaching cloud technologies.
Esra Kayabalı
is a Senior Solutions Architect at Amazon Web Services, specializing in the analytics domain including data warehousing, data lakes, big data analytics, batch and real-time data streaming and data integration. She has 12 years of software development and architecture experience. She is passionate about learning and teaching cloud technologies.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.