We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
How Chime Financial uses Amazon Web Services to build a serverless stream analytics platform and defeat fraudsters
This is a guest post by Khandu Shinde, Staff Software Engineer and Edward Paget, Senior Software Engineering at Chime Financial.
Chime has a responsibility to protect our members against unauthorized transactions on their accounts. Chime’s Risk Analysis team constantly monitors trends in our data to find patterns that indicate fraudulent transactions.
This post discusses how Chime utilizes
Problem statement
In order to keep up with the rapid movement of fraudsters, our decision platform must continuously monitor user events and respond in real-time. However, our legacy data warehouse-based solution was not equipped for this challenge. It was designed to manage complex queries and business intelligence (BI) use cases on a large scale. However, with a minimum data freshness of 10 minutes, this architecture inherently didn’t align with the near real-time fraud detection use case.
To make high-quality decisions, we need to collect user event data from various sources and update risk profiles in real time. We also need to be able to add new fields and metrics to the risk profiles as our team identifies new attacks, without needing engineering intervention or complex deployments.
We decided to explore streaming analytics solutions where we can capture, transform, and store event streams at scale, and serve rule-based fraud detection models and machine learning (ML) models with milliseconds latency.
Solution overview
The following diagram illustrates the design of the Chime Streaming 2.0 system.
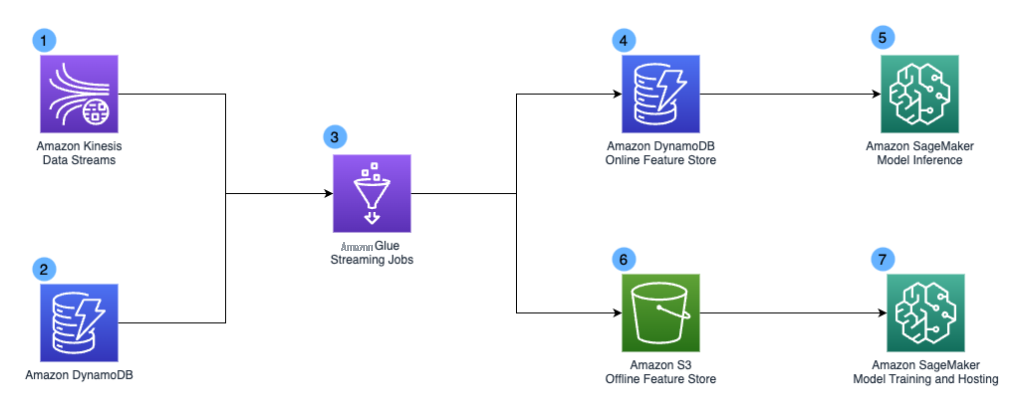
The design included the following key components:
-
We have
Amazon Kinesis Data Streams as our streaming data service to capture and store event streams at scale. Our stream pipelines capture various event types, including user enrollment events, user login events, card swipe events, peer-to-peer payments, and application screen actions. - Amazon DynamoDB is another data source for our Streaming 2.0 system. It acts as the application backend and stores data such as blocked devices list and device-user mapping. We mainly use it as lookup tables in our pipeline.
-
Amazon Web Services Glue jobs form the backbone of our Streaming 2.0 system. The simple Amazon Web Services Glue icon in the diagram represents thousands of Amazon Web Services Glue jobs performing different transformations. To achieve the 5-15 seconds end-to-end data freshness service level agreement (SLA) for the Steaming 2.0 pipeline, we use
streaming ETL jobs in Amazon Web Services Glue to consume data from Kinesis Data Streams and apply near-real-time transformation. We choose Amazon Web Services Glue mainly due to its serverless nature, which simplifies infrastructure management with automatic provisioning and worker management, and the ability to perform complex data transformations at scale. - The Amazon Web Services Glue streaming jobs generate derived fields and risk profiles that get stored in Amazon DynamoDB. We use Amazon DynamoDB as our online feature store due to its millisecond performance and scalability.
- Our applications call Amazon SageMaker Inference endpoints for fraud detections. The Amazon DynamoDB online feature store supports real-time inference with single digit millisecond query latency.
-
We use
Amazon Simple Storage Service (Amazon S3) as our offline feature store. It contains historical user activities and other derived ML features. - Our data scientist team can access the dataset and perform ML model training and batch inferencing using Amazon SageMaker.
Amazon Web Services Glue pipeline implementation deep dive
There are several key design principles for our Amazon Web Services Glue Pipeline and the Streaming 2.0 project.
- We want to democratize our data platform and make the data pipeline accessible to all Chime developers.
- We want to implement cloud financial backend services and achieve cost efficiency.
To achieve data democratization, we needed to enable different personas in the organization to use the platform and define transformation jobs quickly, without worrying about the actual implementation details of the pipelines. The data infrastructure team built an abstraction layer on top of Spark and integrated services. This layer contained API wrappers over integrated services, job tags, scheduling configurations and debug tooling, hiding Spark and other lower-level complexities from end users. As a result, end users were able to define jobs with declarative YAML configurations and define transformation logic with SQL. This simplified the onboarding process and accelerated the implementation phase.
To achieve cost efficiency, our team built a cost attribution dashboard based on
Conclusion
In this post, we showed you how Chime’s Streaming 2.0 system allows us to ingest events and make them available to the decision platform just seconds after they are emitted from other services. This enables us to write better risk policies, provide fresher data for our machine learning models, and protect our members from unauthorized transactions on their accounts.
Over 500 developers in Chime are using this streaming pipeline and we ingest more than 1 million events per second. We follow the sizing and scaling process from the
We hope this post will inspire your organization to build a real-time analytics platform using serverless technologies to accelerate your business goals.
About the Authors
 Khandu Shinde
is a Staff Engineer focused on Big Data Platforms and Solutions for Chime. He helps to make the platform scalable for Chime’s business needs with architectural direction and vision. He’s based in San Francisco where he plays cricket and watches movies.
Khandu Shinde
is a Staff Engineer focused on Big Data Platforms and Solutions for Chime. He helps to make the platform scalable for Chime’s business needs with architectural direction and vision. He’s based in San Francisco where he plays cricket and watches movies.
 Edward Paget
is a Software Engineer working on building Chime’s capabilities to mitigate risk to ensure our members’ financial peace of mind. He enjoys being at the intersection of big data and programming language theory. He’s based in Chicago where he spends his time running along the lake shore.
Edward Paget
is a Software Engineer working on building Chime’s capabilities to mitigate risk to ensure our members’ financial peace of mind. He enjoys being at the intersection of big data and programming language theory. He’s based in Chicago where he spends his time running along the lake shore.
 Dylan Qu
is a Specialist Solutions Architect focused on Big Data & Analytics with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on Amazon Web Services.
Dylan Qu
is a Specialist Solutions Architect focused on Big Data & Analytics with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on Amazon Web Services.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.