We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
How Amazon Finance Technologies simplified global payments by creating a payments repository using Amazon DocumentDB
Amazon Finance Technologies (FinTech) Payments systems disburse Accounts Payable (AP) payments to Amazon’s suppliers and service providers. In 2021, FinTech AP systems disbursed millions of payments in over 150 countries and in more than 50 currencies through various payment options.
In this post, we show you how we built an extensible payments metadata repository solution that provides standardized payment options and toolkit for all Amazon businesses, and thereby improving payment accuracy with timely payment instructions by taking advantage of Amazon Web Services (Amazon Web Services) purpose built database
Challenges and requirements
In any financial transaction, there are two parties: the payer (debtor) and the payee (creditor). The payers for FinTech AP payments are Amazon businesses who are making the payment, and the payees are diverse, including but not limited to digital authors, app developers, retail vendors, utility companies, and tax authorities, who are the receivers of the payment.
Each business gathers payee information, including payment preferences and bank account information, during the onboarding process. The payee’s payment details determine the payment method. This can be a domestic payment in local currency (ACH: Automated Clearing House), domestic wires for large payments, and cross-border wires for cross-country or cross-currency payments. For instance, a digital author from the US may collect royalties in USD in ACH from a US business and a cross-border wire from an EU business.
Where they are, who is paying them, and how they want to be paid influence the payment method, which determines the type of information we need from the payee to complete a successful payment. For example, an app developer in Latin America receiving a local payment as opposed to an international payment requires a different set of payment details.
The following diagram illustrates an example of the payment workflow.
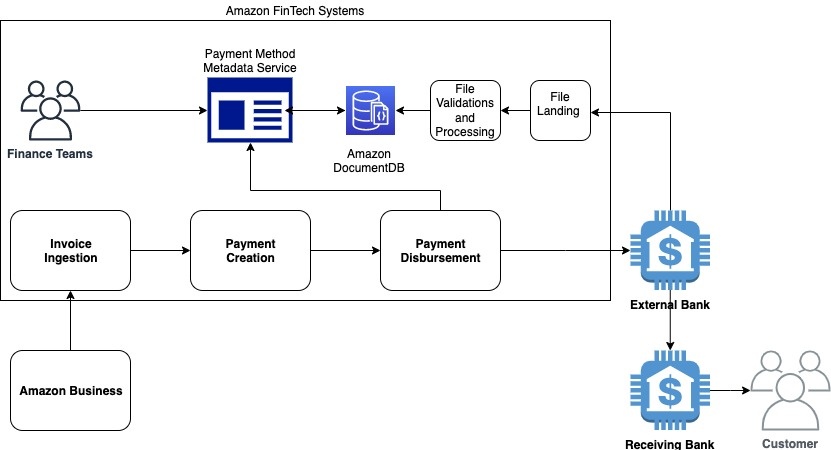
During invoice ingestion, processing, and payment generation, we verify that we have all the required information to make a successful payment, and we optimize the bank disbursement by taking their availability, cut-off hours, and processing times into account.
This payments landscape is growing and changing, and many systems are involved in orchestrating the payment from payee onboarding to disbursement. We need a payment method metadata service capable of storing the rules and payment options from global banking partners, which are subsequently accessed by microservices in the AP systems. This metadata service is important because we have a wide set of global requirements from banking partners and centralized validation rules for payment options, and it allows us to expand to other Regions quickly by reducing code duplication.
After examining the payment metadata from an external bank, we were able to identify the following data characteristics for our metadata service:
- It requires flexible query capabilities
- The attributes vary by bank
- It has a read-heavy access pattern
Why Amazon DocumentDB?
To ensure we could make payments around the globe with our Account Payables system, it was important to have a fast, highly available, scalable, and purpose-built data storage that could support our payment metadata service needs.
The FinTech team started using
Our first decision criteria was whether to use a SQL (relational) or NoSQL (non-relational) database. For our use case, we needed both schema flexibility and a simplified data model because data from banks is hierarchal with multiple levels of nesting.
Going with a relational database would mean losing schema flexibility. For relational storage, tables need a defined structure, and any new field will impact every record in that table. This would have been difficult to maintain and would have resulted in table-level changes for every new bank entity or new attribute we onboarded to our repository. It would have been even more complex if we had to maintain different tables for each country based on the common features and avoid wide tables with many null values that encompass the complete universe of attributes.
Payment data is hierarchal in nature with deep nesting. With a relational database, it would require a complex data model in third normal form to model the various one-to-one and one-to-many relationships in the data. This would not only make the storage pattern complex, but would impact consumption and throughput latency. For most of our business needs, we needed to join data cross multiple entities, which adds an overhead to query and database performance. Scaling to address the storage and performance overhead would lead to higher cost with an anticipated delay in performance.
For NoSQL (non-relational) databases, we looked at both key-value pairs and document structure. With key-value databases, we could get the needed schema flexibility, but it still had complexity in table design. Due to hierarchal data elements, we would need advanced row design to optimize our solution and would most likely have to break down to multiple rows.
Similar to the relational database approach, the second challenge would have been query flexibility. Key-value options work best when we know the access pattern, and we didn’t want to slice the data in different rows and programmatically bring it together. There are limitations on indexes we can define for flexible query patterns, and we didn’t want to maintain two separate data stores for that because it was cost prohibitive and didn’t meet the consistency requirements for our applications.
When we looked at Amazon DocumentDB, we identified that our data can be easily represented in natural JSON format as documents. Each document can have variable fields and doesn’t need to adhere to a common static schema. This provided the flexibility we were looking for because we could onboard data from multiple countries that had varying attributes in a common collection for our applications. We didn’t need to maintain separate instances for each country, which was a win for us. The document structure also simplified our applications because we were interacting with Amazon DocumentDB with JSON data structures that we could easily format, shape, and share with other APIs needed in the application.
For schema design, we created a denormalized model embedding the hierarchies to reduce overhead during data consumption. We could get specific attributes without needing to join or look up either in a database or application. This gave us added advantages to simplify the entire system without any consistency challenges because data could be inserted and updated in a single transaction. As we mentioned earlier, for various use cases, we needed different combination of attributes.
The following is a sample document structure with limited attributes :
Amazon DocumentDB also provided the query flexibility we needed because we could create indexes including on the nested fields. We adhered with the
The following are a few indexes we identified and defined for the application:
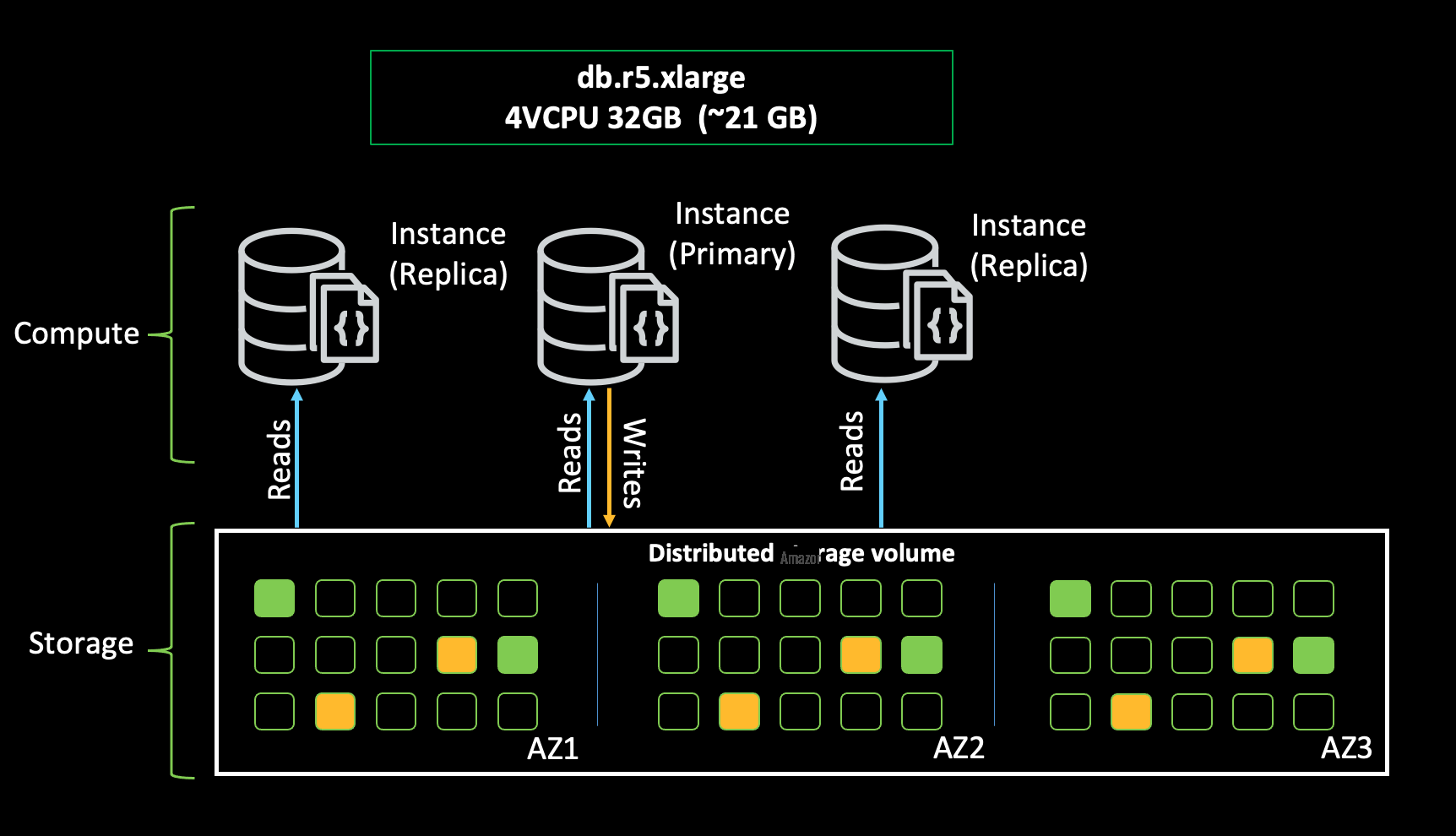
It’s important for us make timely payments, so we wanted our repository to be highly available. For cluster sizing, we launched a minimum of three instances to get 99.99% of our availability target and to have the instances in three separate Availability Zones. If primary instance fails, failover completes within 30 secs.
Another best practice we followed was to choose the right instances to ensure indexes and the working set fit in the cache. Because only approximately 2/3 of the available memory in an instance would be used for cache, we worked to identify the right instance size and selected db.r5.xlarge instances for our purposes.
Our application would be used by teams across various countries. Amazon DocumentDB global clusters allow us to perform global reads with low latency and improves resiliency for our application against region-wide outages. Our application is read intensive and update volumes are low. Replication for global databases are less than a second and works for our needs. In case there are any region-wide outages, we can promote one of the secondary clusters to primary cluster to ensure uptime and availability of our application. We performance tested with 100 TPS and have an option to scale even further if needed.
The following diagram shows the instances to get high availability for our performance needs.
Finally, we could achieve all this with high security standards. Amazon DocumentDB comes with many security features enabled by default. Because it’s a VPC-only service, we could protect the perimeter for access and utilize security groups to allow traffic. Encryption is enabled for data and in transit by default. With role-based access controls, we implemented least privilege enforcement along with cluster audit and monitoring. It also integrates with
Based on these evaluations, we identified Amazon DocumentDB to be the best fit for our solution. We could create a simple yet flexible data model, get the needed query flexibility, support high-volume read requests, get the availability and resiliency target required for our application with security controls, and have pay-per-use pricing. Furthermore, because it’s fully managed, we didn’t have any operational overhead to manage databases, because this is done by Amazon DocumentDB.
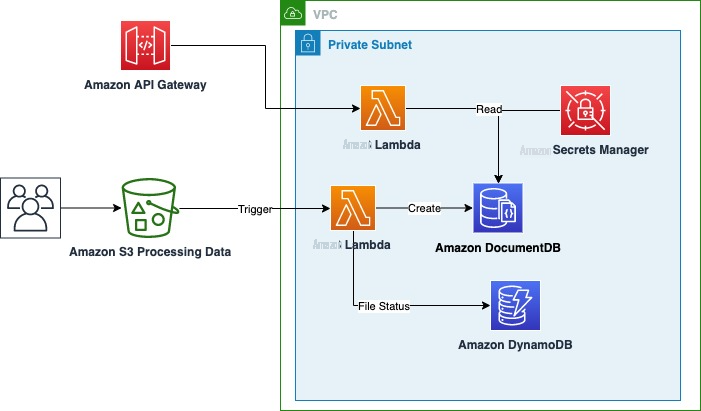
The following diagram shows the overall application architecture.
Summary
With Amazon DocumentDB database, the Amazon FinTech team was able to innovate their payment system with the launch of the global payment repository. The team was able simplify the solution with the document structure, which improved the overall time to launch the product for the global AP team. We’re also able to monitor all these managed services via
For more information on Amazon DocumentDB, visit the
About the Authors


The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.