We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Generate a distinct set of partition keys for an Amazon DynamoDB table efficiently
There are a few situations where you might want a distinct list of partition keys:
- The partition key is a customer ID and you want a list of all customers held in the table. It doesn’t have to be a customer, of course. It might be the ID of the device, shopping cart, game, or whatever entity type is being held in the table.
- You are rolling out a new feature and want to insert a new item into each item collection (an item collection is the set of items having the same partition key but different sort key values). You need to know the partition keys in order to insert the new items.
Scan the whole table
If your table schema has only a partition key (no sort key), then generating a distinct list of partition keys can be done fairly efficiently using a table scan. Each item returned by the scan will have a unique partition key value. No items are needlessly read.
The following code shows how to do a full table scan using the
pk
. If your partition key attribute name is different, you’ll just need to adjust the sample code to match your table schema.
This command scans the
SampleTable
table and selects only the
pk
attribute for each item. It then outputs the partition keys as a space-separated list, which is piped through the
tr
command to convert the tabs to newlines. The list is then sorted and deduplicated using the
sort
command.
An eventually consistent scan costs
The same scan approach works if your table schema includes a sort key, but it grows less efficient as the average item collection size grows larger. If the average item collection has a thousand items, then you need to scan through 999 extra items before seeing the next distinct partition key. Imagine you have 2 million distinct partition keys as above, but each partition key has 1,000 items in its item collection. Now the table would be 1 TB and to extract the 2 million distinct values using a scan will require 125,000,000 read request units. This is 1,000 times more costly, and proportionally slower as well. It’s also more likely to create a rolling hot partition as the scan reads a large amount of data from one partition at a time before jumping to the next.
Use a Global Secondary Index
One way to improve on this efficiency is to create a global secondary index (GSI). Within each item collection you can insert a special item that has a GSI partition key equal to the partition key on the base table. This will propagate those items (and only those items) into the GSI. Scanning this GSI is very efficient as the GSI holds just one item per base table partition key value. As an extra advantage, the average item size in the GSI will be lower than in the base table because the GSI can project
KEYS_ONLY
and avoid holding any non-key attributes. If the average GSI item size is 150 bytes, the GSI holding the 2 million distinct partition key values will be just 300 MB and a full scan will require only 37,500 read request units. The downside is you need to manage the lifecycle of that special item put into each item collection to get it projected into the GSI.
Figure 1 shows a table tracking data about two devices, having IDs and partition keys
1
and
2
. They each have a
#static
element holding static metadata about that device, and into there goes its partition key value as a
GSI-pk
.
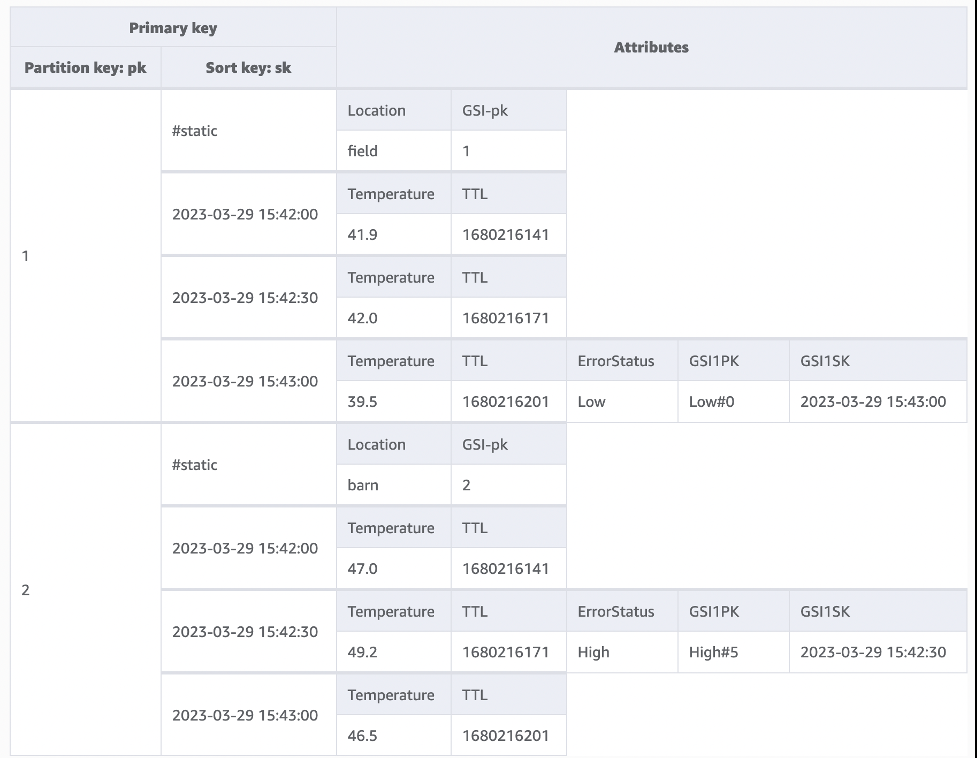
Figure 1: A base table holding two item collections and many items
Figure 2 shows the
GSI-pk
index built against this base table. It can be scanned to extract the partition key values with high efficiency. The GSI partition key has high cardinality to ensure an even write spread and no hot partitions.
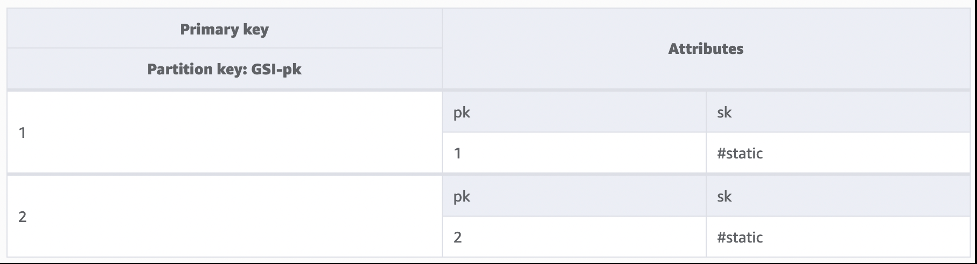
Figure 2: A GSI holding just two items, one for each partition key value
Scan with a modified exclusive start key
If generating a distinct set of partition keys is an access pattern you don’t run frequently, or one you need to run without having first anticipated that requirement, there’s a creative approach that minimizes how much data is actually read using some special manipulation of the
The
LastEvaluatedKey
value is typically treated as an opaque value but it’s actually a map structure holding a partition key and sort key. For example, a
LastEvaluatedKey
value could be:
The sort key can be manipulated during the scan to jump past the maximum possible sort key value to ensure the next read starts at the next item collection.
The steps are as follows:
-
Use the
scanoperation to retrieve a single item from the table, with a Limit of 1. -
If the response contains a
LastEvaluatedKey, modify the key to have the maximum possible sort key value for that partition key and use it as theExclusiveStartKeyin the nextscanoperation. This will continue thescanfrom right after the previous item collection, such that the nextscanoperation should return a new unique partition key value. -
Repeat Steps 1 and 2 until the response doesn’t contain a
LastEvaluatedKey. That indicates the end of the table. - Extract the partition keys from the responses.
The cost for this solution is the total read request units required to read all the first items of each item collection. If the items are 4 KB or less, then it would be 0.5 times the number of distinct partition keys. For our example with 2 million items, this would cost 1,000,000 read request units. That’s less efficient than the optimized GSI (because the GSI can return many items with each request) but much more efficient than a full table scan (because there are no large item collections being pulled with wasted items). When the average item collection size exceeds 4 KB, this approach will be lower cost. This approach has the particular advantage it requires no special advance setup or ongoing maintenance.
The following sections show how to implement this approach in Python, Node.js, and Java. The full source code of these examples as well as some test scripts that load sample data for testing is available in the
Note these examples perform serial scans. If you enjoy a challenge and want maximum performance against a large table, you can convert them to use parallel scans.
Python
For Python, use the following code:
import argparse
import boto3
import decimal
import time
import boto3.dynamodb.types
from botocore.exceptions import ClientError
MAX_SORT_KEY_VALUE_S = str(256 * chr(0x10FFFF))
MAX_SORT_KEY_VALUE_N = decimal.Decimal('9.9999999999999999999999999999999999999E+125')
MAX_SORT_KEY_VALUE_B = boto3.dynamodb.types.Binary(b'\xFF' * 1024)
def print_distinct_pks(region, table_name):
dynamodb = boto3.resource('dynamodb', region_name=region)
table = dynamodb.Table(table_name)
partition_key_name = table.key_schema[0]['AttributeName']
sort_key_name = table.key_schema[1]['AttributeName']
sort_key_type = table.attribute_definitions[1]['AttributeType']
# Determine the maximum value of the sort key based on its type
max_sort_key_value = ''
if sort_key_type == 'S':
max_sort_key_value = MAX_SORT_KEY_VALUE_S
elif sort_key_type == 'N':
max_sort_key_value = MAX_SORT_KEY_VALUE_N
elif sort_key_type == 'B':
max_sort_key_value = MAX_SORT_KEY_VALUE_B
else:
raise ValueError(f"Unsupported sort key type: {sort_key_type}")
last_evaluated_key = None
while True:
try:
scan_params = {
'TableName': table_name,
'Limit': 1,
'ProjectionExpression': 'pk',
}
if last_evaluated_key:
scan_params['ExclusiveStartKey'] = last_evaluated_key
response = table.scan(**scan_params)
items = response['Items']
if len(items) > 0:
print(items[0]['pk'])
if 'LastEvaluatedKey' not in response:
break
last_key = response['LastEvaluatedKey']
partition_key_value = last_key[partition_key_name]
sort_key_value = last_key[sort_key_name]
# Create a new key with the maximum value of the sort key
new_key = {
partition_key_name: partition_key_value,
sort_key_name: max_sort_key_value
}
last_evaluated_key = new_key
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code == 'InternalServerError' or error_code == 'ThrottlingException':
print(f"Received an error: {error_code}, retrying...")
time.sleep(1)
else:
raise
if __name__ == '__main__':
# Define CLI arguments
parser = argparse.ArgumentParser()
parser.add_argument('--region', required=True, help='AWS Region')
parser.add_argument('--table-name', required=True, help='Name of the DynamoDB table')
args = parser.parse_args()
# Call the function with the specified table name
print_distinct_pks(args.region, args.table_name)
Node.js
For Node.js, use the following code:
const { DynamoDBClient, ScanCommand, DescribeTableCommand } = require('@aws-sdk/client-dynamodb');
const { program } = require('commander');
async function printDistinctPKs(region, tableName) {
const dynamoDb = new DynamoDBClient({ region : region });
const describeTableCommand = new DescribeTableCommand({ TableName: tableName });
const table = await dynamoDb.send(describeTableCommand);
const partitionKeyName = table.Table.KeySchema[0].AttributeName;
const sortKeyName = table.Table.KeySchema[1].AttributeName;
const sortKeyType = table.Table.AttributeDefinitions.find(attr => attr.AttributeName === sortKeyName).AttributeType;
const MAX_SORT_KEY_VALUE_S = String.fromCharCode(0x10FFFF).repeat(256);
const MAX_SORT_KEY_VALUE_N = '9.9999999999999999999999999999999999999E+125';
const MAX_SORT_KEY_VALUE_B = Buffer.alloc(1024, 0xFF);
let maxSortKeyValue = '';
// Determine the maximum value of the sort key based on its type
if (sortKeyType === 'S') {
maxSortKeyValue = MAX_SORT_KEY_VALUE_S;
} else if (sortKeyType === 'N') {
maxSortKeyValue = MAX_SORT_KEY_VALUE_N;
} else if (sortKeyType === 'B') {
maxSortKeyValue = MAX_SORT_KEY_VALUE_B;
} else {
throw new Error(`Unsupported sort key type: ${sortKeyType}`);
}
let lastEvaluatedKey = null;
while (true) {
try {
const scanParams = {
TableName: tableName,
Limit: 1,
ExclusiveStartKey: lastEvaluatedKey,
ProjectionExpression: 'pk',
};
const scanCommand = new ScanCommand(scanParams);
const response = await dynamoDb.send(scanCommand);
const items = response.Items;
if (items && items.length > 0) {
console.log(items[0].pk.S);
}
lastEvaluatedKey = response.LastEvaluatedKey;
if (!lastEvaluatedKey) {
break;
}
// Create a new key with the maximum value of the sort key
lastEvaluatedKey = {
[partitionKeyName]: lastEvaluatedKey[partitionKeyName],
[sortKeyName]: { [sortKeyType]: maxSortKeyValue },
};
} catch (error) {
if (error.code === 'InternalServerError' || error.code === 'ThrottlingException') {
console.error(`Received an error: ${error.code}, retrying...`);
await new Promise(resolve => setTimeout(resolve, 1000));
} else {
throw error;
}
}
}
}
// Define CLI arguments
program
.option('--table-name <tableName>', 'Name of the DynamoDB table')
.option('--region <region>', 'AWS region for the DynamoDB table')
.parse(process.argv);
const options = program.opts();
if (!options.region) {
console.error('Error: --region option is required.');
process.exit(1);
}
if (!options.tableName) {
console.error('Error: --table-name option is required.');
process.exit(1);
}
// Call the function with the specified table name and region
printDistinctPKs(options.region, options.tableName);
Java
For Java, use the following code:
package org.example;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import software.amazon.awssdk.core.SdkBytes;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.dynamodb.DynamoDbClient;
import software.amazon.awssdk.services.dynamodb.model.AttributeValue;
import software.amazon.awssdk.services.dynamodb.model.DescribeTableRequest;
import software.amazon.awssdk.services.dynamodb.model.DescribeTableResponse;
import software.amazon.awssdk.services.dynamodb.model.DynamoDbException;
import software.amazon.awssdk.services.dynamodb.model.ScanRequest;
import software.amazon.awssdk.services.dynamodb.model.ScanResponse;
import software.amazon.awssdk.services.dynamodb.model.*;
import software.amazon.awssdk.core.SdkBytes;
import software.amazon.awssdk.core.exception.SdkException;
import software.amazon.awssdk.services.sts.StsClient;
import software.amazon.awssdk.services.sts.model.GetCallerIdentityRequest;
import software.amazon.awssdk.services.sts.model.GetCallerIdentityResponse;
public class PrintDistinctPKs {
static DynamoDbClient dynamoDb;
public static void main(String[] args) {
String tableName;
String region;
if (args.length != 4 || !args[0].equals("--table-name") || !args[2].equals("--region")) {
System.out.println("Error: --table-name and --region params not passed, checking AWS_DEFAULT_REGION and DYNAMODB_TABLE_NAME environment variables.");
// If they didn't pass the table name and region on the command line, see if they
// passed it in environment variables
region = System.getenv("AWS_DEFAULT_REGION");
if (region == null || region.isEmpty()) {
System.out.println("Error: AWS_DEFAULT_REGION environment variable is not set.");
System.exit(1);
} else {
software.amazon.awssdk.regions.Region awsRegion = null;
try {
awsRegion = software.amazon.awssdk.regions.Region.of(region);
} catch (IllegalArgumentException e) {
System.out.println("Error: Invalid AWS region specified in AWS_DEFAULT_REGION.");
System.exit(1);
}
dynamoDb = DynamoDbClient.builder().region(awsRegion).build();
// Validate region by making an API call to AWS STS service
try {
StsClient stsClient = StsClient.builder().region(awsRegion).build();
GetCallerIdentityRequest request = GetCallerIdentityRequest.builder().build();
GetCallerIdentityResponse response = stsClient.getCallerIdentity(request);
System.out.println("Region is valid. Account ID: " + response.account());
} catch (SdkException e) {
System.out.println("Error: Unable to validate region. Check your AWS credentials and region.");
System.exit(1);
}
}
tableName = System.getenv("DYNAMODB_TABLE_NAME");
if (tableName == null || tableName.isEmpty()) {
System.out.println("Error: DYNAMODB_TABLE_NAME environment variable is not set.");
System.exit(1);
}
} else {
tableName = args[1];
region = args[3];
}
printDistinctPKs(Region.of(region), tableName);
}
public static void printDistinctPKs(Region awsRegion, String tableName) {
DynamoDbClient dynamoDb = DynamoDbClient.builder().region(awsRegion).build();
DescribeTableResponse table = dynamoDb.describeTable(DescribeTableRequest.builder().tableName(tableName).build());
String partitionKeyName = table.table().keySchema().get(0).attributeName();
if (table.table().keySchema().size() == 1) {
throw new RuntimeException("Table needs to be a hash/range table");
}
String sortKeyName = table.table().keySchema().get(1).attributeName();
String sortKeyType = table.table().attributeDefinitions().stream()
.filter(attr -> attr.attributeName().equals(sortKeyName))
.findFirst()
.orElseThrow(() -> new RuntimeException("Could not find schema for attribute name: " + sortKeyName))
.attributeType().toString();
// We need to create a string that is encoded in UTF-8 to 1024 bytes of the highest
// code point. This is 256 code points. Each code point is a 4 byte value in UTF-8.
// In Java, the code point needs to be specified as a surrogate pair of characters, thus
// 512 characters.
StringBuilder sb = new StringBuilder(512);
for (int i = 0; i < 256; i++) {
sb.append("\uDBFF\uDFFF");
}
String maxSortKeyValueS = sb.toString();
String maxSortKeyValueN = "9.9999999999999999999999999999999999999E+125";
byte[] maxBytes = new byte[1024];
Arrays.fill(maxBytes, (byte)0xFF);
SdkBytes maxSortKeyValueB = SdkBytes.fromByteArray(maxBytes);
Map<String, AttributeValue> lastEvaluatedKey = null;
while (true) {
try {
ScanRequest scanRequest = ScanRequest.builder()
.tableName(tableName)
.limit(1)
.exclusiveStartKey(lastEvaluatedKey)
.projectionExpression("pk").build();
ScanResponse response = dynamoDb.scan(scanRequest);
if (!response.items().isEmpty()) {
System.out.println(response.items().get(0).get(partitionKeyName).s());
}
if (!response.hasLastEvaluatedKey()) {
break;
}
lastEvaluatedKey = response.lastEvaluatedKey();
AttributeValue maxSortKeyValue;
switch (sortKeyType) {
case "S":
maxSortKeyValue = AttributeValue.builder().s(maxSortKeyValueS).build();
break;
case "N":
maxSortKeyValue = AttributeValue.builder().n(maxSortKeyValueN).build();
break;
case "B":
maxSortKeyValue = AttributeValue.builder().b(maxSortKeyValueB).build();
break;
default:
throw new RuntimeException("Unsupported sort key type: " + sortKeyType);
}
lastEvaluatedKey = new HashMap<>(lastEvaluatedKey);
lastEvaluatedKey.put(sortKeyName, maxSortKeyValue);
} catch (DynamoDbException e) {
if (e.awsErrorDetails().errorCode().equals("InternalServerError")
|| e.awsErrorDetails().errorCode().equals("ThrottlingException")) {
System.err.println("Received an error: " + e.awsErrorDetails().errorCode() + ", retrying...");
try {
Thread.sleep(1000);
} catch (InterruptedException interruptedException) {
break;
}
} else {
throw e;
}
}
}
}
}
Conclusion
In this post, we explored the challenge of generating a distinct set of partition keys in a DynamoDB table. We discussed the traditional approach of scanning the entire table, which can work well for a table without sort keys or with small item collections, but it can be expensive and slow for tables with large item collections. Then we presented a more efficient solution using the pagination feature in DynamoDB, which allows you to retrieve partition keys one at a time, thereby minimizing the amount of data scanned and reducing the cost.
This optimized solution not only speeds up the process of generating a distinct set of partition keys, but also helps you save on read capacity and avoid throttling. Remember that it’s important to adapt your approach to your specific use case and table size. The efficiency of this method will depend on the distribution of your partition keys and the overall structure of your table. If you need to generate a distinct set of partition keys for a large table or perform other operations that require scanning the table, consider using the efficient pagination method outlined in this post to save on time and costs. Sample code in multiple programming languages is provided in the
About the Author
 Chad Tindel
is a Principal DynamoDB Specialist Solutions Architect based out of New York City. He works with large enterprises to evaluate, design, and deploy DynamoDB-based solutions. Prior to joining Amazon he held similar roles at Red Hat, Cloudera, MongoDB, and Elastic.
Chad Tindel
is a Principal DynamoDB Specialist Solutions Architect based out of New York City. He works with large enterprises to evaluate, design, and deploy DynamoDB-based solutions. Prior to joining Amazon he held similar roles at Red Hat, Cloudera, MongoDB, and Elastic.

 Jason Hunter
is a Principal DynamoDB Specialist Solution Architect based in California. He’s been working with NoSQL Databases since 2003. He’s known for his contributions to Java, open source, and XML.
Jason Hunter
is a Principal DynamoDB Specialist Solution Architect based in California. He’s been working with NoSQL Databases since 2003. He’s known for his contributions to Java, open source, and XML.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.