We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Deploy multi-Region Amazon RDS for SQL Server using cross-Region read replicas with a disaster recovery blueprint – Part 1
Disaster recovery and high availability planning play a critical role in ensuring the resilience and continuity of business operations. When considering disaster recovery strategies on Amazon Web Services, there are two primary options: in-Region disaster recovery and cross-Region disaster recovery. The choice between in-Region and cross-Region disaster recovery depends on various factors, including the criticality of the applications and data, regulatory requirements, geographic distribution of users, cost and complexity.
To implement a multi-Region disaster recovery solution on Amazon Web Services, you must first identify the critical components of your infrastructure and determine the required Recovery Point Objective (RPO) and Recovery Time Objective (RTO) for each component. The RPO is the maximum amount of data loss that is acceptable, and the RTO is the maximum amount of time that can elapse before the system must be restored.
As of July 2023,
In this series, we are focusing on the needs of critical applications that require the best possible availability and disaster recovery across different Amazon Web Services Regions. In this first post, we guide you through the process of establishing a failover strategy for applications utilizing
Solution overview
This solution is deployed in two Amazon Web Services Regions with active-passive strategy where primary (active) Region host the workload and serve the traffic. The secondary (passive) Region is used for the disaster recovery. Amazon Route53 public hosted zone with failover policy is created to route internet traffic between primary and secondary Regions. Amazon Route 53 private hosted zone CNAME records to store RDS for SQL Server endpoints. The application connects to the database using these records.
The following diagram illustrates the key components of this architecture.
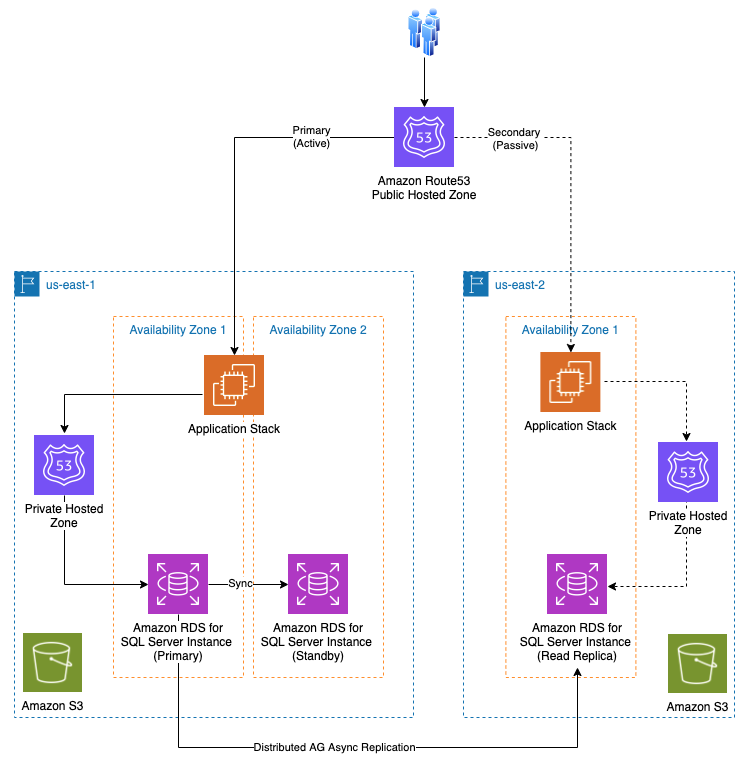
In our example, the primary Amazon Web Services Region is referred as us-east-1 and secondary Amazon Web Services Region as us-east-2. In addition, note the following:
- The Amazon RDS for SQL Server Multi-AZ DB instance is deployed in the primary Amazon Web Services Region and the cross-Region read replica is in the secondary Region.
-
Amazon RDS for SQL Server configures cross-Region read replicas (asynchronous replication) using
Distributed Availability Groups . - Application stack deployed in both Regions and maintain the same release version.
-
Amazon Route53 public hosted zone that serve internet traffic is configured with ‘failover’routing policies . -
Amazon Route53 private hosted zone configured with ‘simple’ routing policies for application to RDS for SQL Server instance connectivity.
Standby takes over primary
examplebucket123
in Amazon Web Services Region
us-east-2
and file name is
initiate_failover.dr
, the corresponding endpoint to access this S3 file would be:
https://examplebucket123.s3.us-east-2.amazonaws.com/initiate_failover.dr
This health check is deemed healthy when the HTTP response received from the designated endpoint returns a status code of 4xx or 5xx (That means, the Route 53 health check agents NOT able to resolve that Amazon S3 file endpoint). Conversely, if the response returns a status code of 2xx or 3xx, the health check fails (That means, the Route 53 health check agents were able resolve the Amazon S3 file endpoint). This method is called Route53
It is important to note that automatic failover of internet traffic to the secondary Region is not recommended. In situations like a brief network glitch in primary Region, automatic failover can result into longer downtime.
Prerequisites
To implement this solution, you need the following:
- An application stack and Amazon RDS for SQL Server multi-AZ instance in the primary Region.
-
An application stack and Amazon RDS for SQL Server read replica instance in secondary Region(cross-replication). For instructions, refer
Use cross-Region read replicas with Amazon Relational Database Service for SQL Server . -
Any server level objects (for example logins, SQL agent jobs and more) that are created in the primary DB instance after the creation of the read replica are not automatically replicated, and you must create them manually in the read replica. Hence make sure these objects are in sync between primary and secondary Regions. Refer to the
Amazon RDS documentation for more details.
Walkthrough
To deploy this solution, complete the following steps:
-
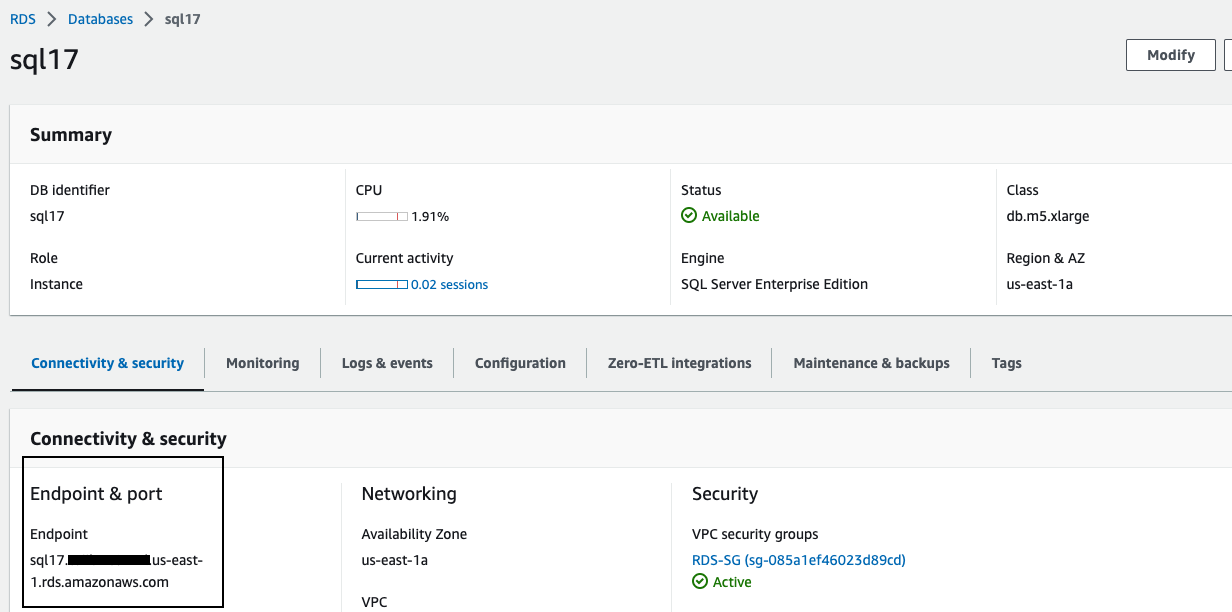
Navigate to
Amazon Relational Database service (RDS) console in primary Region. -
Capture endpoint of the primary RDS for SQL Server instance.
-
Similarly, navigate to
Amazon RDS Console in secondary Region . - Capture endpoint of RDS for SQL Server cross-Region read replica.
-
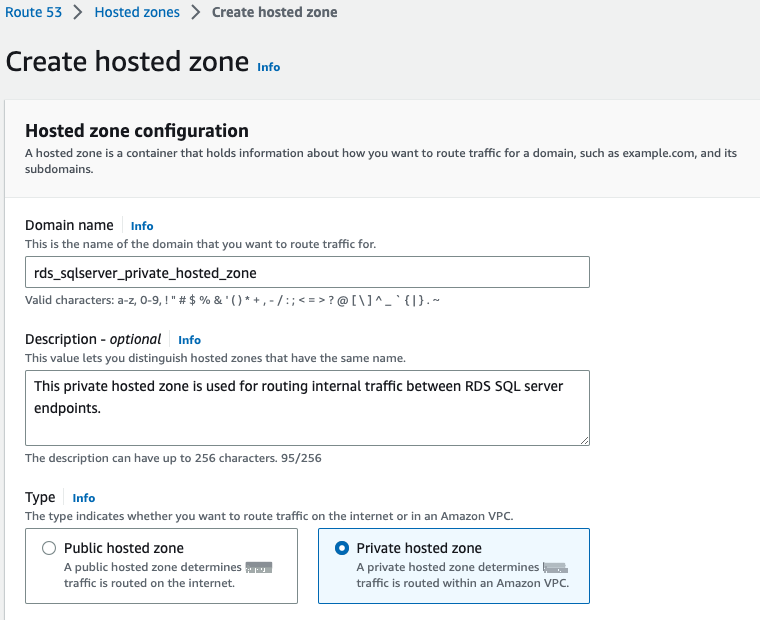
Navigate to
Amazon Route53 console . -
Create a newprivate hosted zone .
-
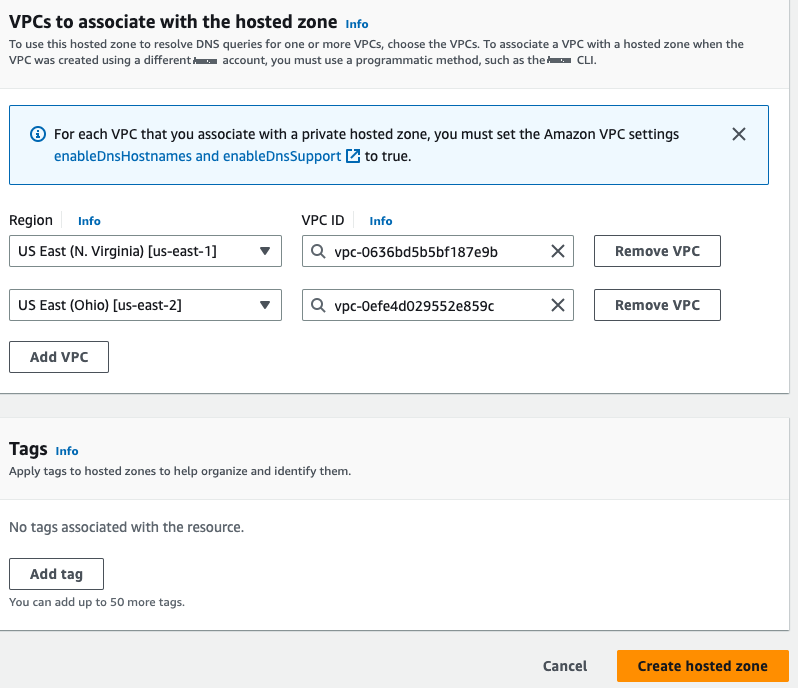
Associate the VPCs for both Regions to the private hosted zone. This is necessary because private hosted zone routes traffic within an Amazon VPC.
-
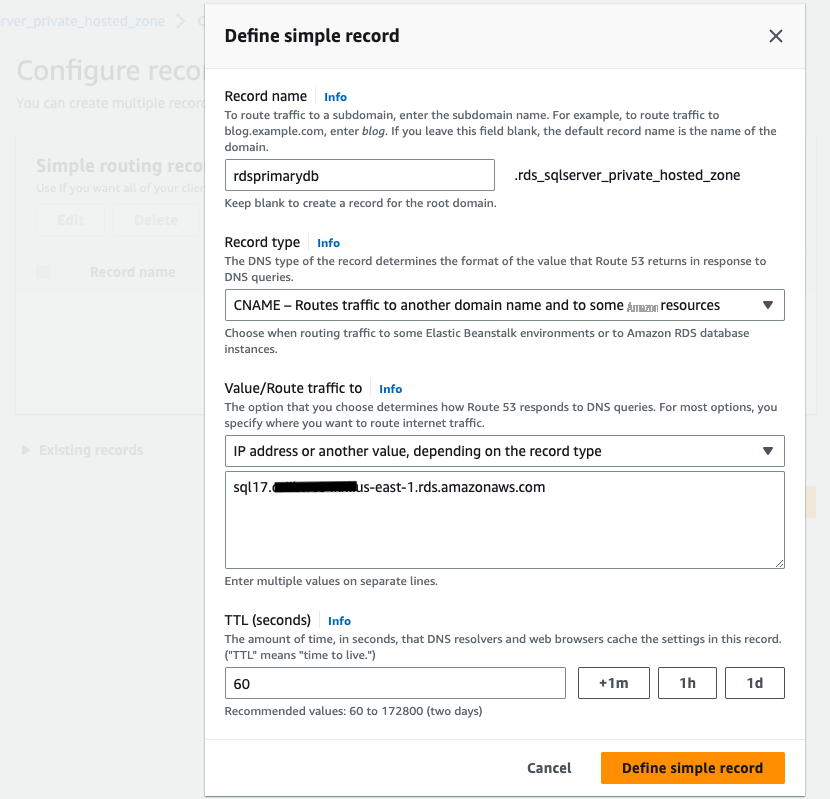
Once private hosted zone is created, add two CNAME records with
simple routing policy . In our example, we created below CNAME records:-
rdsprimarydb.rds_sqlserver_private_hosted_zone– Connects to RDS for SQL Server in primary Region. -
rdssecondarydb.rds_sqlserver_private_hosted_zone– Connects to RDS for SQL Server cross-Region read replica.
-
-
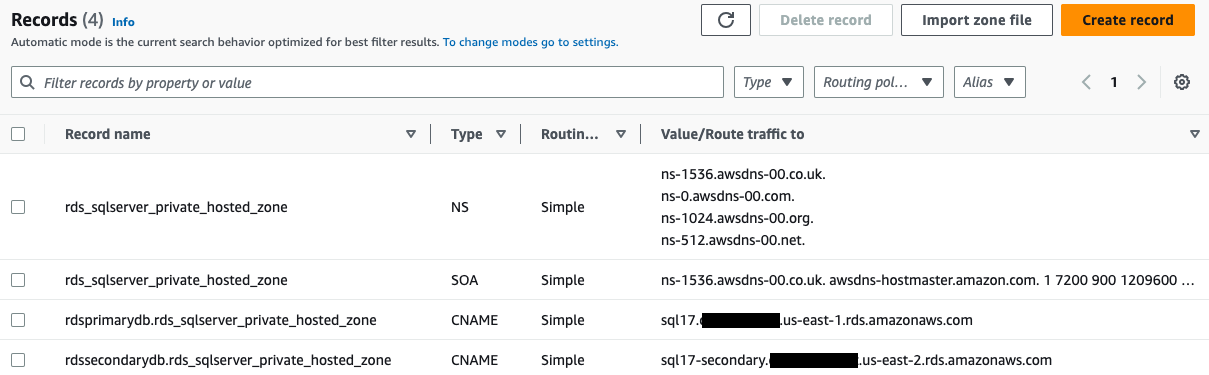
After adding both CNAME records, private hosted zone should look like following screenshot.
-
Update your application configuration in primary Region and use CNAME record
rdsprimarydb.rds_sqlserver_private_hosted_zoneas the database host name in database connection string. -
Similarly update application in secondary Region using CNAME record
rdssecondarydb.rds_sqlserver_private_hosted_zone. This step ensure that applications are not directly using RDS endpoints. Hence during failover application changes would not require.
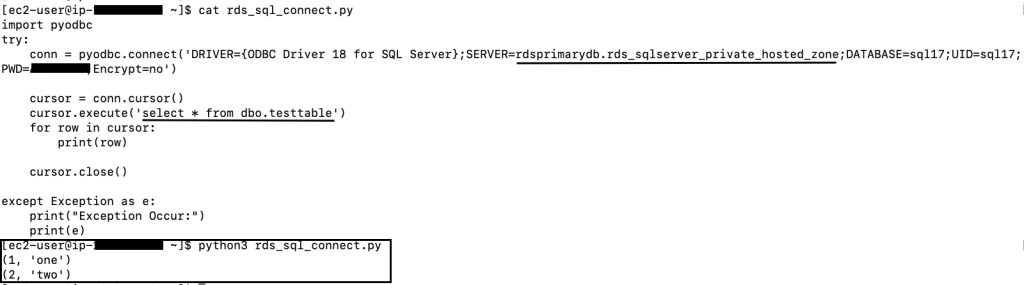
The following python code is an example code connecting to RDS for SQL Server instance using private hosted zone CNAME record:

- Create new Amazon S3 buckets in both primary and secondary Regions. These S3 buckets are dedicated to host disaster recovery file. To ensure the security and integrity of the health check process, it is crucial to restrict access to this bucket exclusively for authorized personnel. You may leave these buckets empty at this point when both primary and secondary Regions are healthy.
-
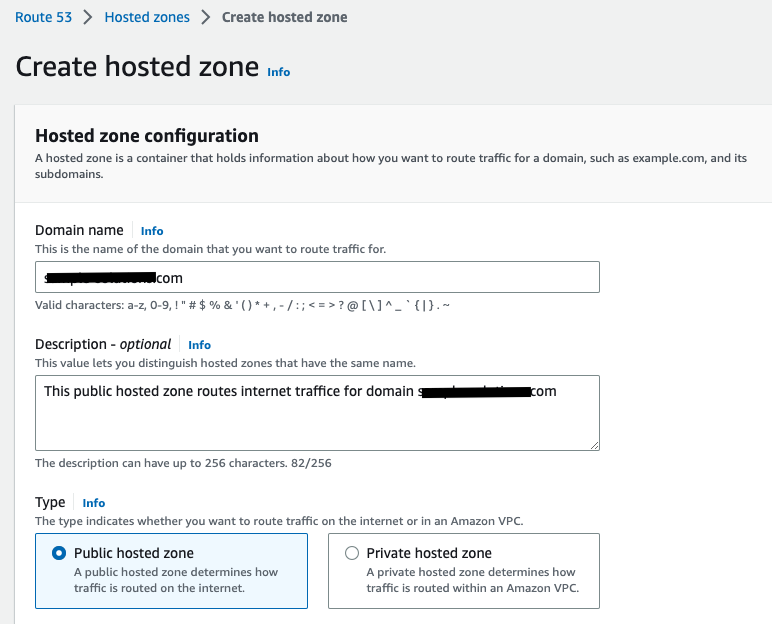
Navigate to
Amazon Route53 console and createRoute53 public hosted zone to manage internet traffic for your public domain.
-
After creating public hosted zone, navigate to
Amazon Route53 health checks console . -
Create two new Route53 health checks one for primary Region failover and another is for secondary Region failover. These health checks will be attached to primary and secondary Region failover records.
-
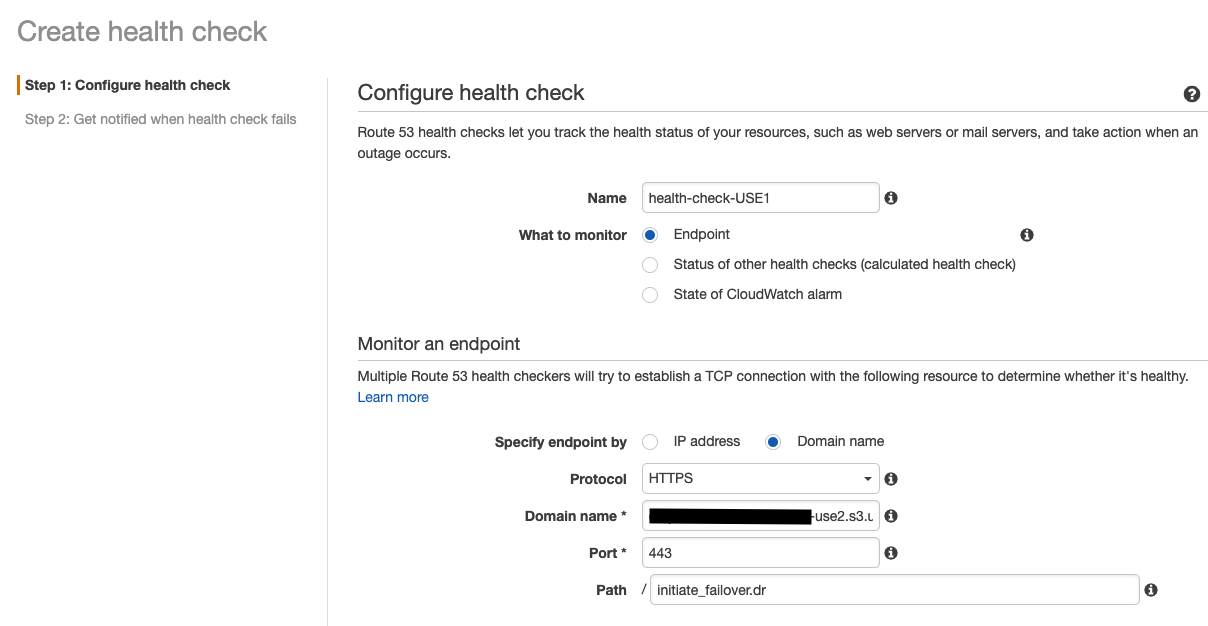
On Create health check page,
- Enter health check name for primary Region.
- Then select Endpoint option for what to monitor.
- In monitor and endpoint section, select Domain name and protocol HTTPS .
-
Under domain name, specify Amazon S3 bucket endpoint of secondary Region. For example:
examplebucket123.s3.us-east-2.amazonaws.com -
Under Path, specify the disaster recovery file name. For example:
initiate_failover.dr -
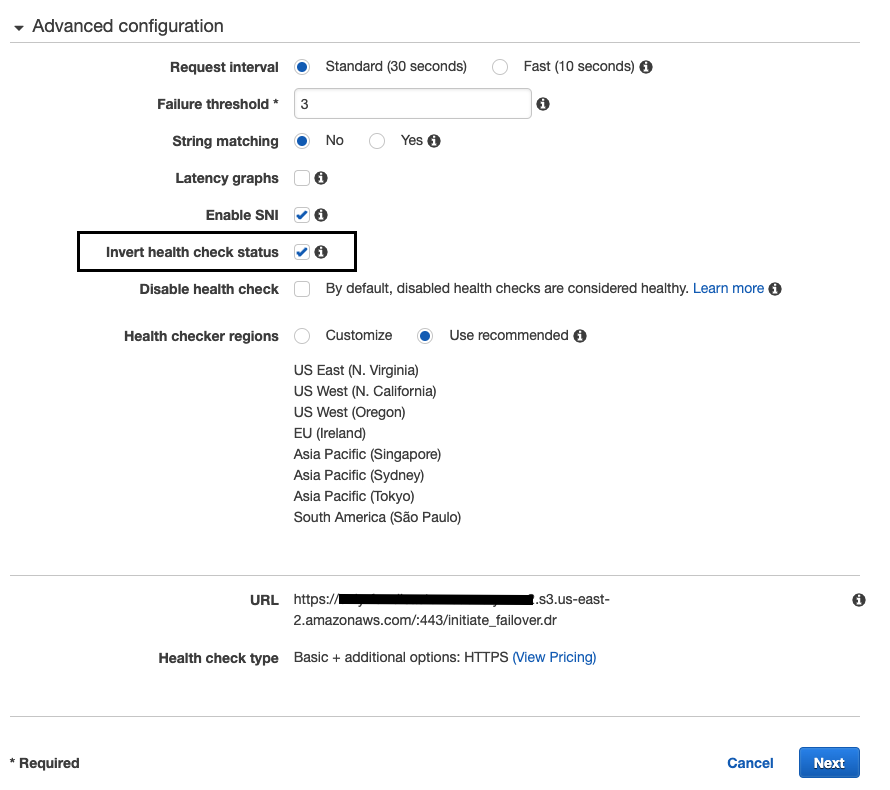
Specify
failover threshold andrequest interval in advanced configuration section. -
Check option for ‘
Invert health check status ’ and hit next. - Submit create health check .
Repeat the same steps to create health check record for secondary Region.
For the primary Region health check, specify the S3 file endpoint from the secondary Region and vice versa. In the event that the primary Region becomes inaccessible, you will be able to modify the S3 file in the secondary Region and initiate the failover. -
After health checks are created for primary and secondary Regions, Amazon Route53 will initiate the health check and report the status.

-
Navigate to the
Route53 public hosted zone created at step 13 and complete the following steps:-
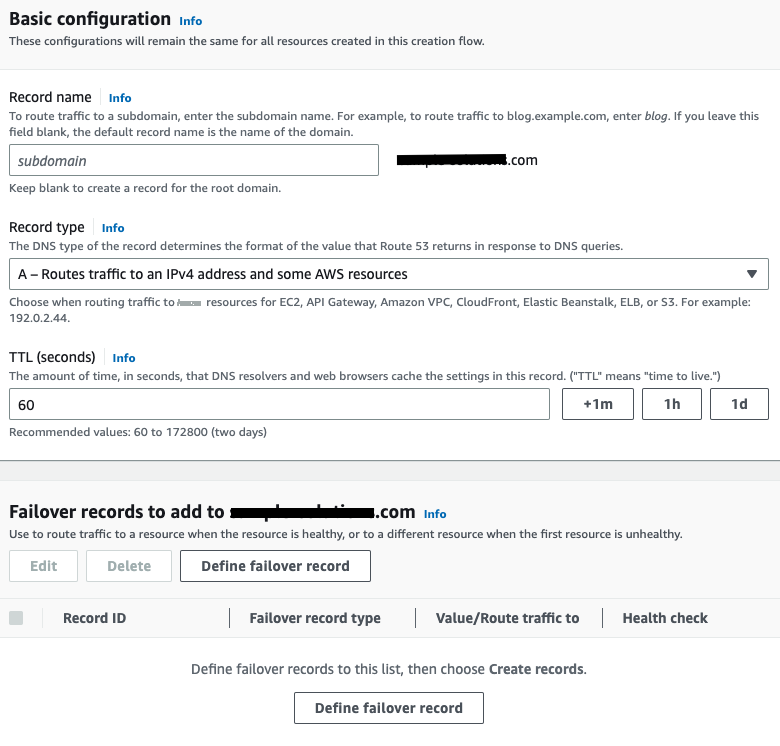
Create record
with
failover routing policy . - Click on Define failover record .
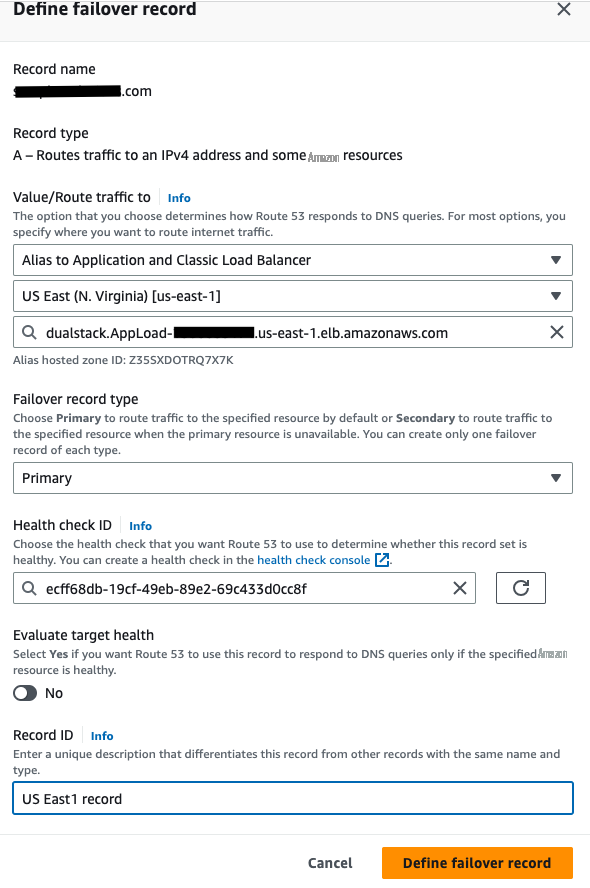
- Associate this record with application target. For example, Route53 support Application load balancer, API gateway, VPC endpoint or S3 endpoints and more. In this example, application load balance target is selected.
- Choose primary Region.
- Choose the target load balancer.
- Specify failover record type as Primary .
- Choose health check record created for primary region.
- Disable evaluate target health option.
- Submit
-
Create record
with
- Repeat the similar steps to create another record for secondary record type.
Once public hosted zone configuration complete, it should look like below screenshot:
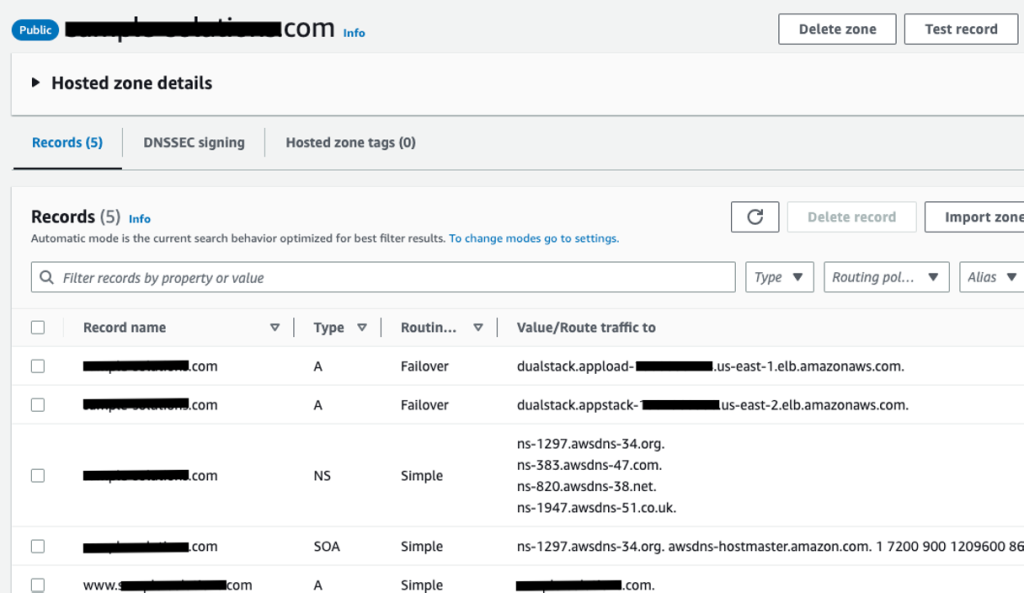
This completes deployment of disaster recovery blueprint with Amazon Route53, Amazon S3 and Amazon RDS for SQL Server. At this point, you should be able to access your application through internet traffic.

Clean up
In the next post of this series, we are going to use this blueprint and show you how to perform cross-Region failover. Hence if you are planning to continue, preserve all resources created under this deployment.
To delete the resources created to implement this solution, complete the following steps:
- Delete public and private hosted zone you created.
- Change the application configuration to its original state.
- Delete the Amazon S3 bucket you created.
Summary
In this post, we provided guidance on how to implement a cross-Region disaster recovery blueprint. The ‘standby takes over primary’ approach in Amazon Route53 public hosted zone policies empowers organizations to maintain control over the failover process and manually initiate failover when the primary Region becomes inaccessible.
In the
If you have any comments or feedback, leave them in the comments section.
About the author
 Ravi Mathur
is a Sr. Solutions Architect at Amazon Web Services. He works with customers providing technical assistance and architectural guidance on various Amazon Web Services services. He brings several years of experience in software engineering and architecture roles for various large-scale enterprises.
Ravi Mathur
is a Sr. Solutions Architect at Amazon Web Services. He works with customers providing technical assistance and architectural guidance on various Amazon Web Services services. He brings several years of experience in software engineering and architecture roles for various large-scale enterprises.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.