We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Define per-team resource limits for big data workloads using Amazon EMR Serverless
Customers face a challenge when distributing cloud resources between different teams running workloads such as development, testing, or production. The resource distribution challenge also occurs when you have different line-of-business users. The objective is not only to ensure sufficient resources be consistently available to production workloads and critical teams, but also to prevent adhoc jobs from using all the resources and delaying other critical workloads due to mis-configured or non-optimized code. Cost controls and usage tracking across these teams is also a critical factor.
In the legacy big data and Hadoop clusters as well as
In this post, we show how to define per-team resource limits for big data workloads using EMR serverless.
Solution overview
The following diagram illustrates our solution architecture. We see that two different teams namely Prod team and Dev team are submitting their jobs independently to two different EMR Applications (namely ProdApp and DevApp respectively ) having dedicated resources.
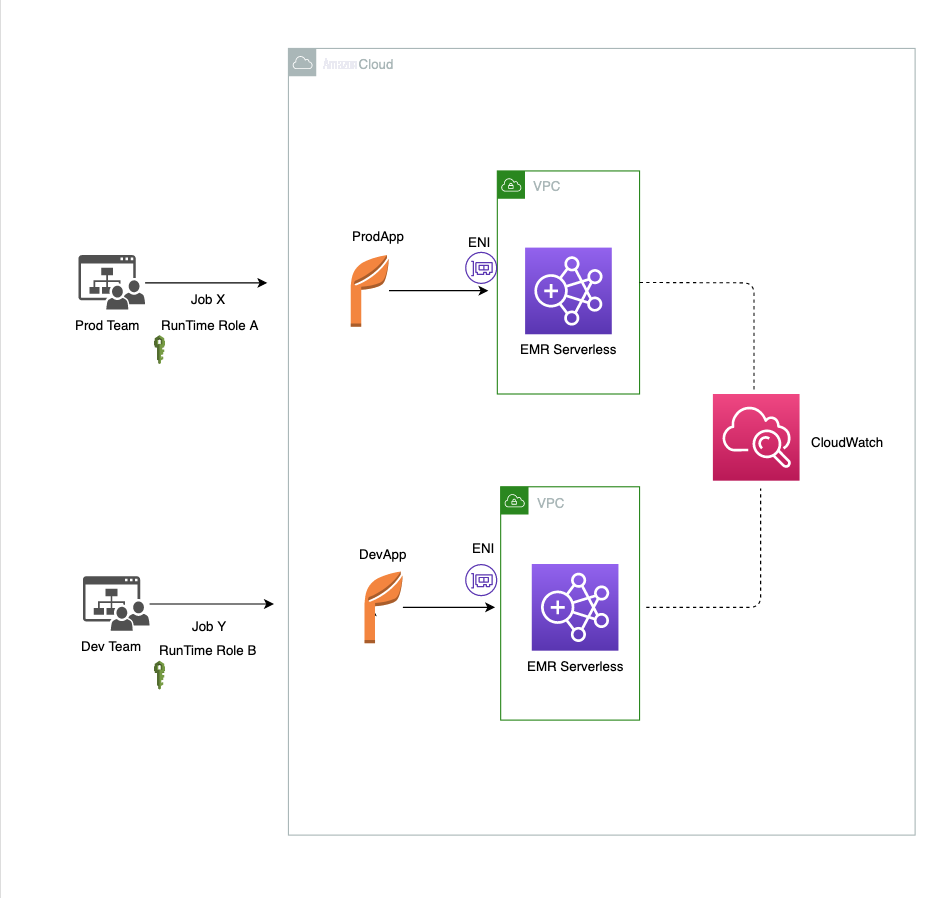
EMR Serverless provides controls at the account, application and job level to limit the use of resources such as CPU, memory or disk. In the following sections, we discuss some of these controls.
Service quotas at account level
Amazon EMR Serverless has a default quota of 16 for maximum concurrent vCPUs per account. In other words, a new account can have a maximum of 16 vCPUs running at a given point in time in a particular Region across all EMR Serverless applications. However, this quota is auto-adjustable based on the usage patterns, which are monitored at the account and Region levels.
Resource limits and runtime configurations at the application level
In addition to quotas at the account levels, administrators can limit the use of resources at the application level using a feature known as “
You also have an option to specify common runtime and monitoring configurations at the application level which you would otherwise put in the specific job configurations. This helps create a standardized runtime environment for all the jobs running under an application. This can include settings like defining common connection setting your jobs need access to, log configurations that all your jobs will inherit by default, or Spark resource settings to help balance ad-hoc workloads. You can override these configurations at the job level, but defining them at the application can help reduce the configuration necessary for individual jobs.
For further details, refer to
Runtime configurations at Job level
After you have set service, application quotas and runtime configurations at application level, you also have an option to override or add new configurations at the job level as well. For example, you can use different Spark job parameters to define how many maximum executors can be run by that specific job. One such parameter is
spark.dynamicAllocation.maxExecutors
which defines an upper bound for the number of executors in a job and therefore controls the number of workers in an EMR Serverless application because each executor runs within a single worker. This parameter is part of the
With these configurations, you can control the resources used across accounts, applications, and jobs. For example, you can create applications with a predefined maximum capacity to constrain costs or configure jobs with resource limits in order to allow multiple ad hoc jobs to run simultaneously without consuming too many resources.
Best practices and considerations
Extending these usage scenarios further, EMR Serverless provides features and capabilities to implement the following design considerations and best practices based on your workload requirements:
-
To make sure that the users or teams submit their jobs only to their approved applications, you could use tag based
Amazon Web Services Identity and Access Management (IAM) policy conditions. For more details, refer toUsing tags for access control . -
You can use
custom images as applications belonging to different teams that have distinct use-cases and software requirements. Using custom images is possible EMR 6.9.0 and onwards. Custom images allows you to package various application dependencies into a single container. Some of the important benefits of using custom images include the ability to use your own JDK and Python versions, apply your organization-specific security policies and integrate EMR Serverless into your build, test and deploy pipelines. For more information, refer toCustomizing an EMR Serverless image . -
If you need to estimate how much a Spark job would cost when run on EMR Serverless, you can use the open-source tool
EMR Serverless Estimator. This tool analyzes Spark event logs to provide you with the cost estimate. For more details, refer toAmazon EMR Serverless cost estimator - We recommend that you determine your maximum capacity relative to the supported worker sizes by multiplying the number of workers by their size. For example, if you want to limit your application with 50 workers to 2 vCPUs, 16 GB of memory and 20 GB of disk, set the maximum capacity to 100 vCPU, 800 GB of memory, and 1000 GB of disk.
-
You can use tags when you create the EMR Serverless application to help search and filter your resources, or track the Amazon Web Services costs using
Amazon Web Services Cost Explorer . You can also use tags for controlling who can submit jobs to a particular application or modify its configurations. Refer toTagging your resources for more details. -
You can configure the
pre-initialized capacity at the time of application creation, which keeps the resources ready to be consumed by the time-sensitive jobs you submit. - The number of concurrent jobs you can run depends on important factors like maximum capacity limits, workers required for each job, and available IP address if using a VPC.
-
EMR Serverless will setup
elastic network interfaces (ENIs) to securely communicate with resources in your VPC. Make sure you have enough IP addresses in your subnet for the job. - It’s a best practice to select multiple subnets from multiple Availability Zones. This is because the subnets you select determine the Availability Zones that are available to run the EMR Serverless application. Each worker uses an IP address in the subnet where it is launched. Make sure the configured subnets have enough IP addresses for the number of workers you plan to run.
Resource usage tracking
EMR Serverless not only allows cloud administrators to limit the resources for each application, it also enables them to monitor the applications and track the usage of resources across these applications. For more details, refer to
You can also deploy an Amazon Web Services CloudFormation template to build a sample
Conclusion
In this post, we discussed how EMR Serverless empowers cloud and data platform administrators to efficiently distribute as well as restrict the cloud resources at different levels, for different organizational units, users and teams, as well as between critical and non-critical workloads. EMR Serverless resource limiting features make sure cloud cost is under control and resource usage is tracked effectively.
For more information on EMR Serverless applications and resource quotas, please refer to
About the Authors
 Gaurav Sharma
is a Specialist Solutions Architect(Analytics) at Amazon Web Services (Amazon Web Services), supporting US public sector customers on their cloud journey. Outside of work, Gaurav enjoys spending time with his family and reading books.
Gaurav Sharma
is a Specialist Solutions Architect(Analytics) at Amazon Web Services (Amazon Web Services), supporting US public sector customers on their cloud journey. Outside of work, Gaurav enjoys spending time with his family and reading books.
 Damon Cortesi
is a Principal Developer Advocate with Amazon Web Services. He builds tools and content to help make the lives of data engineers easier. When not hard at work, he still builds data pipelines and splits logs in his spare time.
Damon Cortesi
is a Principal Developer Advocate with Amazon Web Services. He builds tools and content to help make the lives of data engineers easier. When not hard at work, he still builds data pipelines and splits logs in his spare time.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.