We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Choose the right Amazon RDS deployment option: Single-AZ instance, Multi-AZ instance, or Multi-AZ database cluster
In addition to offering you a choice of seven well-known engines,
In the following sections, we dive deeper into different Amazon RDS deployment options of Single-AZ deployment,
Single-AZ Instance
A Single-AZ instance runs on a single
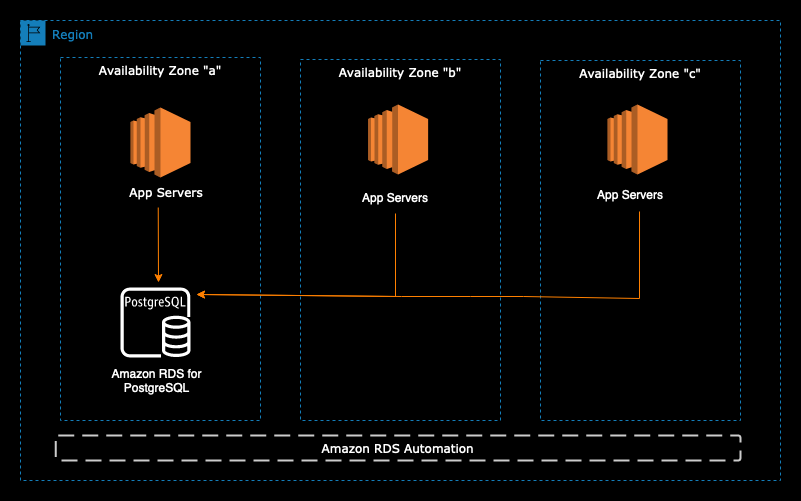
Due to the lack of standby instances, a Single-AZ instance cannot failover during an AZ outage. The RPO with an Amazon RDS Single-AZ instance is typically 5 minutes, which is based on the timeout interval for copying transaction logs to Amazon S3. This time may vary due to open transactions, engine specific settings, loss of network connectivity to Amazon S3, and instance class (network/disk/heavy workload) limits. You can find it by calling
The Single-AZ instance is not the best fit for production workloads where high availability is required. However, it can be a good fit for development or testing purposes where applications do not require high availability, automatic failover, or low RTO/RPO.
For more information, visit
Multi-AZ instance
A Multi-AZ instance consists of two Amazon RDS managed instances in two different AZs. The two instances in Multi-AZ instance deployment are referred to as the primary instance and the standby instance. The primary instance is responsible for serving read and write traffic. In this deployment option, the standby instance doesn’t serve any read or write traffic. The storage replication happens synchronously from primary instance to secondary instance.
The following diagram illustrates the high-level architecture of Multi-AZ Deployment for Amazon RDS For PostgreSQL and it also applies
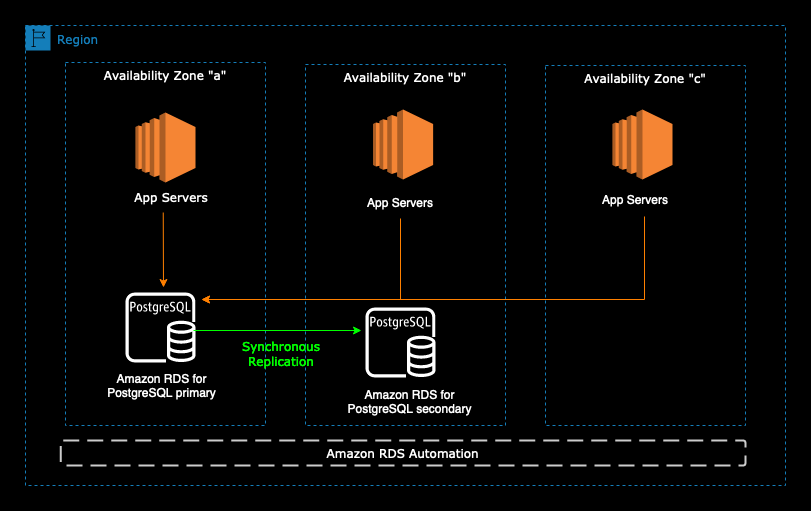
In the event of failure, Amazon RDS initiates an automated failover to the standby instance. During this time, the role of instances in Multi-AZ instance deployment is reversed and DNS propagation takes place. The automated failover process promotes the standby instance to the new role of primary without any manual intervention. Amazon RDS automatically performs a failover in the event of any of the following:
- Loss of availability in primary Availability Zone
- Loss of network connectivity to primary
- Compute unit failure on primary
- Storage failure on primary
The RPO with an Amazon RDS Multi-AZ instance failover is zero because of the synchronous replication to the standby db instance. The amount of time it takes for failover is usually 1–2 minutes. Long recovery times due to rollback of uncommitted transactions or roll-forward of in-memory committed transactions, limits on instance class’s IO throughput,
During automated failover, transactions or inflight queries are terminated. Therefore, it’s best practice to have your own mechanisms in place for detecting query cancellation. For information on how you can respond to failovers, reduce recovery time, and other best practices for Amazon RDS, see
When using the Amazon RDS Multi-AZ instance the snapshots and backups are taken from the standby instance. This prevents I/O suspension on the primary instance during the backup process avoiding read/write traffic disruption on primary and lower latencies. However, as discussed above, the standby instance is passive and does not serve read traffic. To serve read-only traffic, we can add read replica’s to the Multi-AZ instance and use read endpoint to serve read-only traffic. You can also use read replica promotion as a data recovery scheme if the primary DB instance fails. For more information about read replicas, see
The Multi-AZ instance is suitable for business/mission critical applications that require high availability with low RTO/RPO and resilience to availability zone outage. However, this high availability option isn’t a scaling solution for read-only scenarios. You can’t use a standby replica to serve read traffic. To serve read-only traffic, use a Multi-AZ DB cluster or a read replica instead.
For more information, visit
Multi-AZ DB cluster
The Multi-AZ DB cluster is the latest deployment offering in Amazon RDS, and is available for MySQL and PostgreSQL engines. The Multi-AZ DB cluster combines automatic failover with two readable standby instances and provides up to 2x faster commit latencies and automated failovers, typically under 35 seconds. The Amazon RDS managed instances are created in three separate Availability Zones and are equipped with fast
The Multi-AZ DB cluster helps maximize application performance and scalability by splitting traffic, to the cluster endpoint for write traffic and reader endpoint for read traffic respectively. The following diagram illustrates the high-level architecture.
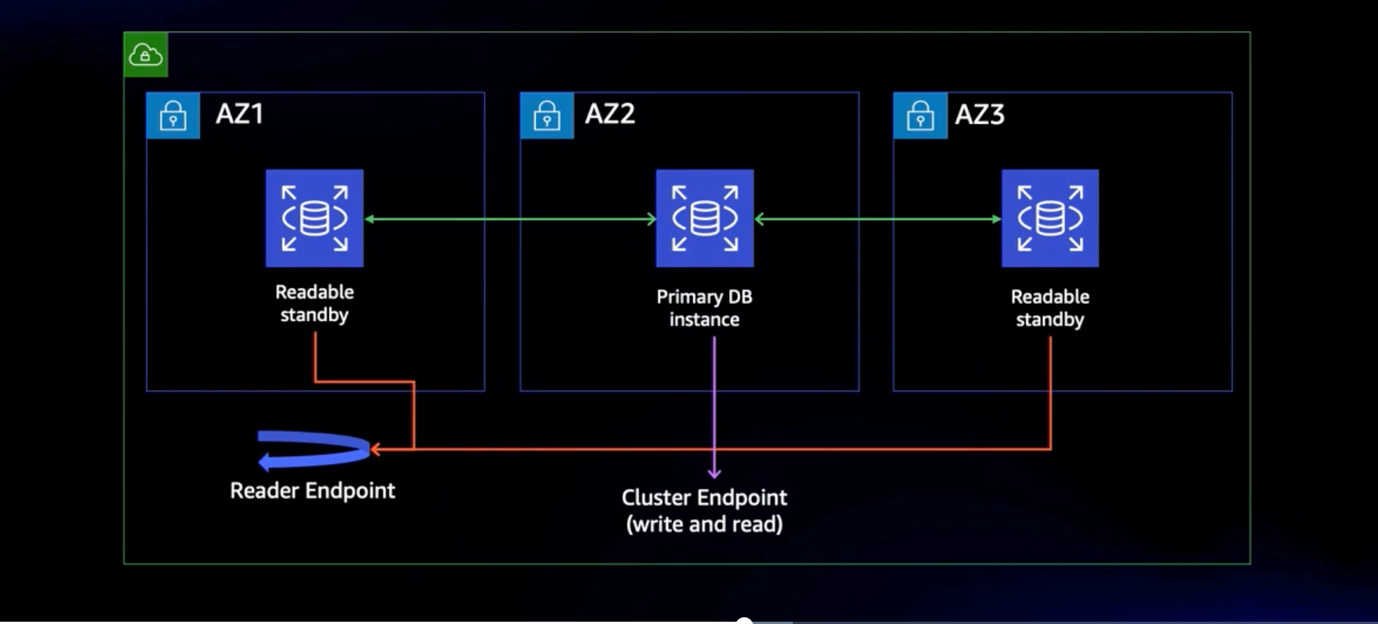
This deployment option also offers improved failover time, typically under 35 seconds, compared to Multi-AZ instance deployment with the elimination of the crash recovery step. However, the total recovery time depends on
In the following sections, we dive deeper into the differences on how the the Multi-AZ DB cluster handles read write traffic as compared to Single-AZ instance or Multi-AZ instance offerings.
Basic Architecture
There are three instances in Multi-AZ DB cluster: one primary writer instance and two readable standby instances in different AZs. Each of these instances consists of an
Replication Intricacies
Although the Multi-AZ instance deployment option uses synchronous replication, Multi-AZ DB cluster deployment replication is semi-synchronous. Semi-synchronous replication guarantees that if the primary crashes, all committed transactions have been transmitted to at least one readable standby instance. This is called a “quorum” when compared with asynchronous replication, semi-synchronous replication provides improved data integrity and durability, because when a commit returns successfully, we know that the data exists in at least two places. This makes sure that in the event of failure on the primary instance, one of the standby reader instances can be promoted to primary through an automated failover orchestrated by Amazon RDS. The time taken for failover is typically around 25–75 seconds, but may increase because of replica lag due to additional time required for applying transactions (for example, relay logs in MySQL) from local SSD to Amazon EBS volumes before the reader can be promoted as the new writer.
Faster Write Operations
When compared to Multi-AZ instance deployment, Multi-AZ DB cluster deployment provides lower latency for write commits. The primary database instance replicates to two standby reader instances in their own independent Availability Zone, and provides better durability because the data is available in another Availability Zone. To understand this better, let’s see how writes are made in a Multi-AZ DB cluster:
-
Transactions are committed and applied on primary only after one of the standby instances acknowledges that the transaction is written to standby’s local SSD. The Multi-AZ DB cluster uses a
quorum mechanism to confirm at least one standby acknowledged the change. -
Data is copied
asynchronously from local SSD to attached EBS volumes.
The following figure illustrates this process.
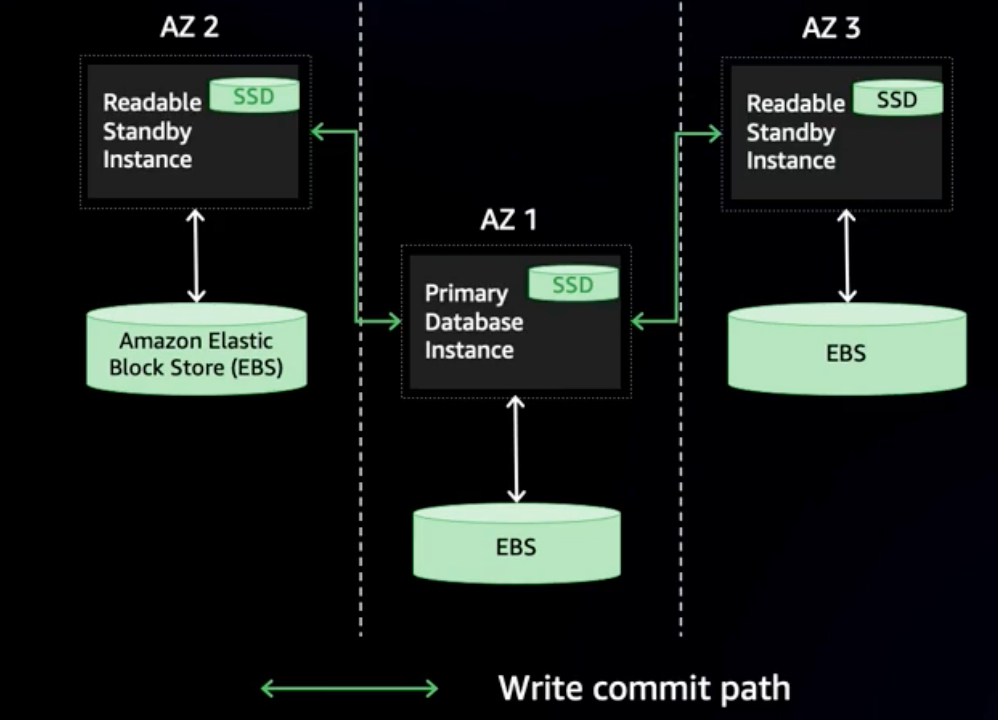
While Multi-AZ DB clusters provide resiliency using the semi-synchronous replication model, they can still have replication lag if one instance in the quorum set has not applied all of the transactions. If your application needs to read all up-to-date data, which is known as “strong read consistency”, then you must use the writer endpoint for reads. You can use the reader endpoint for applications that are build to handle replication lag.
The behavior of readable standby instances observed in a Multi-AZ DB cluster with respect to replica lag is similar to what we observe in a Single-AZ or Multi-AZ instance with one or more read replicas, where each read replica may lag by different values. However, unlike standalone read replicas of Single-AZ instances and Multi-AZ instances, where replication is asynchronous, the replication in a Multi-AZ DB cluster from the primary to readable standby instances is semi-synchronous.
As a result of these improvements in the write process, the RDS Multi-AZ DB cluster provides the following benefits:
- Lower latency and higher throughput as writes are made to local storage, which is faster storage when compared to Amazon EBS. Amazon RDS Multi-AZ DB cluster supports up to 2x faster transaction commit latencies than a Multi-AZ or Single-AZ deployment.
- Higher resiliency to Availability Zone outage with two standby instances that can serve read traffic.
- The Multi-AZ DB cluster uses a two out of three quorum, meaning that writes need to be acknowledged by one of the standbys. This makes the cluster more resilient if a write path is impaired, leading to better overall performance in the event of a failure scenario.
The Multi-AZ DB cluster is suitable for business/mission critical applications that require high availability, low RTO/RPO, improved commit latency, faster failover, readable standby instances, and optimized replications with both high availability with automatic failover and read scalability.
Summary
In this post, we walked you through the different Amazon RDS offerings, the new Multi AZ database cluster and key factors to consider while choosing the right offering for your workloads. The following table summarizes the key considerations while selecting the deployment options.
| Considerations | Single-AZ | Multi-AZ (with one standby) | Multi-AZ (with two readable standby instances) |
| Standby instance can accept reads | No | No | Yes |
| Commit latency | Low | Higher than Single-AZ | Up to two-times faster commits for writes compared to Multi-AZ instance |
| Automatic failover | No, because there is no standby | Yes | Yes |
| Failover time | Not possible | Can take up to 120 seconds, based on crash recovery | Typically 25–75 seconds, but depends replica lag |
| AZ outage resiliency | In the event of Availability Zone failure, you risk data loss; RPO can be up to 5 minutes | In the event of Availability Zone failure, your workload automatically fails over to standby instances | Two standby instances serve as failover targets |
| Storage jitter | No optimization for jitter | Sensitive to impairments on the write path | Uses two of three quorum: insensitive to up to one impaired write path |
| Replication mode | None | Synchronous replication | Semi-synchronous engine-native replication |
| Performance impact of snapshots | Brief I/O suspension | Taken from secondary instance, no I/O suspension | Amazon EBS crash consistent snapshot feature to take backup from primary, which doesn’t result in I/O suspension |
The Multi AZ database cluster option is ideal when your workloads require lower write latency, automated failovers, and additional read capacity. You can
Have follow-up questions or feedback? Let us know by creating a
About the Authors
 Ankush Agarwal
is a Solutions Architect at Amazon Web Services. He’s a Amazon Web Services certified architect and helps customer design resilient workloads on Amazon Web Services. He also has experience in designing, deploying, and optimizing data analytics workloads on the Amazon Web Services Cloud. Outside of work, you will find him wandering in urban forests or on sports field.
Ankush Agarwal
is a Solutions Architect at Amazon Web Services. He’s a Amazon Web Services certified architect and helps customer design resilient workloads on Amazon Web Services. He also has experience in designing, deploying, and optimizing data analytics workloads on the Amazon Web Services Cloud. Outside of work, you will find him wandering in urban forests or on sports field.
 Pranshu Mishra
is a Solutions Architect at Amazon Web Services. He’s an Amazon Web Services certified professional in eight areas and specializes in databases and serverless technologies. He has experience in designing, deploying, and optimizing workloads on the Amazon Web Services Cloud. Beyond work, he enjoys spending his time exploring the outdoors and immersing himself in nature
Pranshu Mishra
is a Solutions Architect at Amazon Web Services. He’s an Amazon Web Services certified professional in eight areas and specializes in databases and serverless technologies. He has experience in designing, deploying, and optimizing workloads on the Amazon Web Services Cloud. Beyond work, he enjoys spending his time exploring the outdoors and immersing himself in nature
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.