We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Build a multi-Region and highly resilient modern data architecture using Amazon Web Services Glue and Amazon Web Services Lake Formation
This post explains how to create a design that automatically backs up
This solution only replicates metadata in the Data Catalog, not the actual underlying data. To have a redundant data lake using Lake Formation and Amazon Web Services Glue in an additional Region, we recommend replicating the Amazon S3-based storage using
Solution overview
This post shows how to create a backup of the Lake Formation permissions and Amazon Web Services Glue Data Catalog from one Region to another in the same account. The solution doesn’t create or modify
- Migrate Lake Formation data permissions.
- Migrate Amazon Web Services Glue databases and tables.
- Migrate Amazon S3 data.
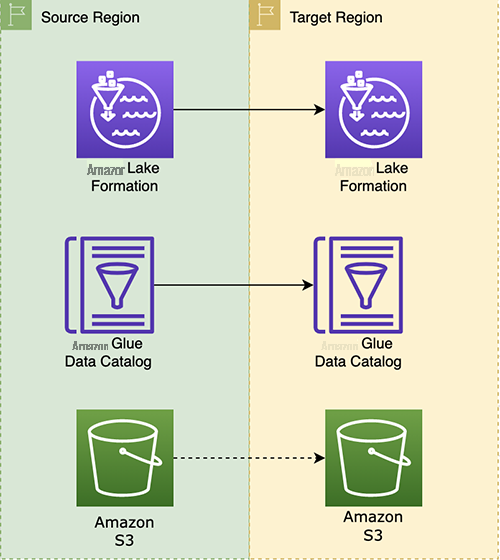
In the following sections, we look at each migration step in more detail.
Lake Formation permissions
In Lake Formation, there are two types of permissions: metadata access and data access.
Metadata access permissions allow users to create, read, update, and delete metadata databases and tables in the Data Catalog.
Data access permissions allow users to read and write data to specific locations in Amazon S3. Data access permissions are managed using data location permissions, which allow users to create and alter metadata databases and tables that point to specific Amazon S3 locations.
When data is migrated from one Region to another, only the metadata access permissions are replicated. This means that if data is moved from a bucket in the source Region to another bucket in the target Region, the data access permissions need to be reapplied in the target Region.
Amazon Web Services Glue Data Catalog
The Amazon Web Services Glue Data Catalog is a central repository of metadata about data stored in your data lake. It contains references to data that is used as sources and targets in Amazon Web Services Glue ETL (extract, transform, and load) jobs, and stores information about the location, schema, and runtime metrics of your data. The Data Catalog organizes this information in the form of metadata tables and databases. A table in the Data Catalog is a metadata definition that represents the data in a data lake, and databases are used to organize these metadata tables.
Lake Formation permissions can only be applied to objects that already exist in the Data Catalog in the target Region. Therefore, in order to apply these permissions, the underlying Data Catalog databases and tables must already exist in the target Region. To meet this requirement, this utility migrates both the Amazon Web Services Glue databases and tables from the source Region to the target Region.
Amazon S3 data
The data that underlies an Amazon Web Services Glue table can be stored in an S3 bucket in any Region, so replication of the data itself isn’t necessary. However, if the data has already been replicated to the target Region, this utility has the option to update the table’s location to point to the replicated data in the target Region. If the location of the data is changed, the utility updates the S3 bucket name and keeps the rest of the prefix hierarchy unchanged.
This utility doesn’t include the migration of data from the source Region to the target Region. Data migration must be performed separately using methods such as S3
This utility has two modes for replicating Lake Formation and Data Catalog metadata: on-demand and real-time. The on-demand mode is a batch replication that takes a snapshot of the metadata at a specific point in time and uses it to synchronize the metadata. The real-time mode replicates changes made to the Lake Formation permissions or Data Catalog in near-real time.
The on-demand mode of this utility is recommended for creating existing Lake Formation permissions and Data Catalogs because it replicates a snapshot of the metadata. After the Lake Formation and Data Catalogs are synchronized, you can use real-time mode to replicate any ongoing changes. This creates a mirror image of the source Region in the target Region and keeps it up to date as changes are made in the source Region. These two modes can be used independently of each other, and the operations are idempotent.
The code for the on-demand and real-time modes is available in the
On-demand mode
On-demand mode is used to copy the Lake Formation permissions and Data Catalog at a specific point in time. The code is deployed using the
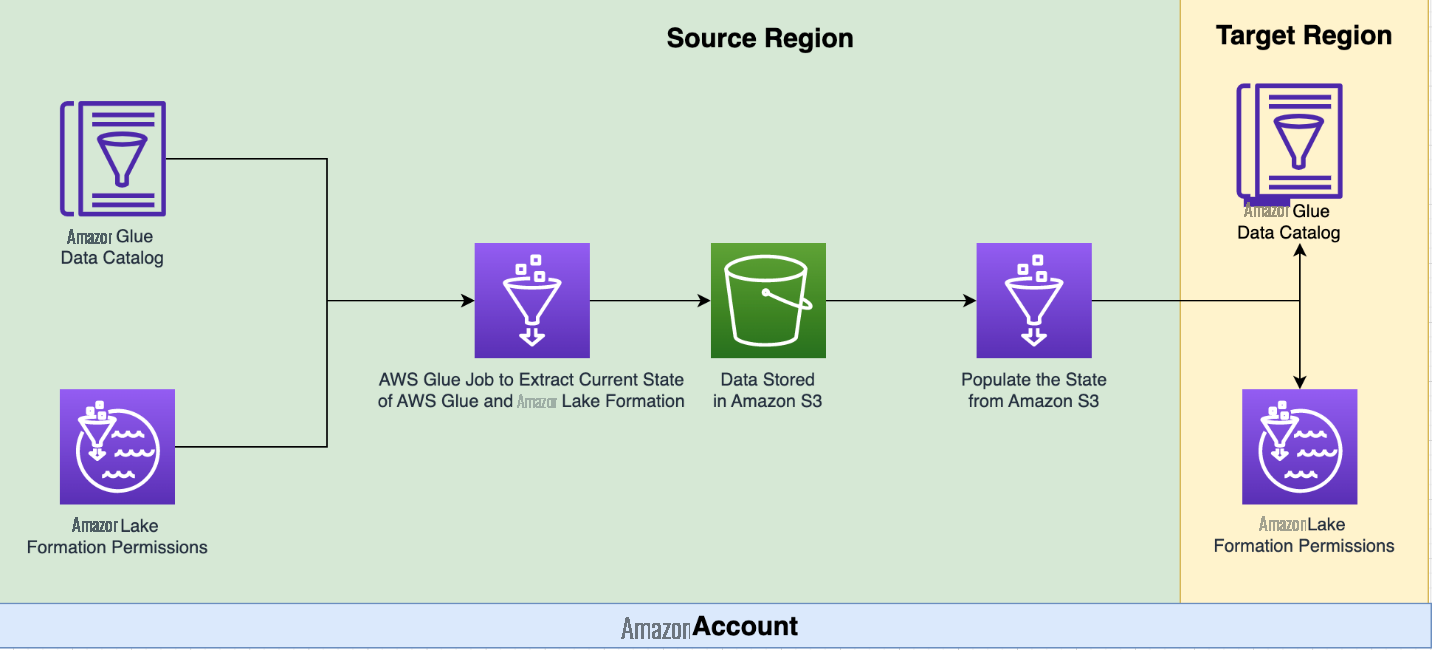
The Amazon Web Services CDK deploys an Amazon Web Services Glue job to perform the replication. The job retrieves configuration information from a file stored in an S3 bucket. This file includes details such as the source and target Regions, an optional list of databases to replicate, and options for moving data to a different S3 bucket. More information about these options and deployment instructions is available in the
The Amazon Web Services Glue job retrieves the Lake Formation permissions and Data Catalog object metadata from the source Region and stores it in a JSON file in an S3 bucket. The same job then uses this file to create the Lake Formation permissions and Data Catalog databases and tables in the target Region.
This tool can be run on demand by running the Amazon Web Services Glue job. It copies the Lake Formation permissions and Data Catalog object metadata from the source Region to the target Region. If you run the tool again after making changes to the target Region, the changes are replaced with the latest Lake Formation permissions and Data Catalog from the source Region.
This utility can detect any changes made to the Data Catalog metadata, databases, tables, and columns while replicating the Data Catalog from the source to the target Region. If a change is detected in the source Region, the latest version of the Amazon Web Services Glue object is applied to the target Region. The utility reports the number of objects modified during its run.
The Lake Formation permissions are copied from the source to the target Region, so any new permissions are replicated in the target Region. If a permission is removed from the source Region, it is not removed from the target Region.
Real-time mode
Real-time mode replicates the Lake Formation permissions and Data Catalog at a regular interval. The default interval is 1 minute, but it can be modified during deployment. The code is deployed using the Amazon Web Services CDK. The following diagram shows the solution architecture for this mode.
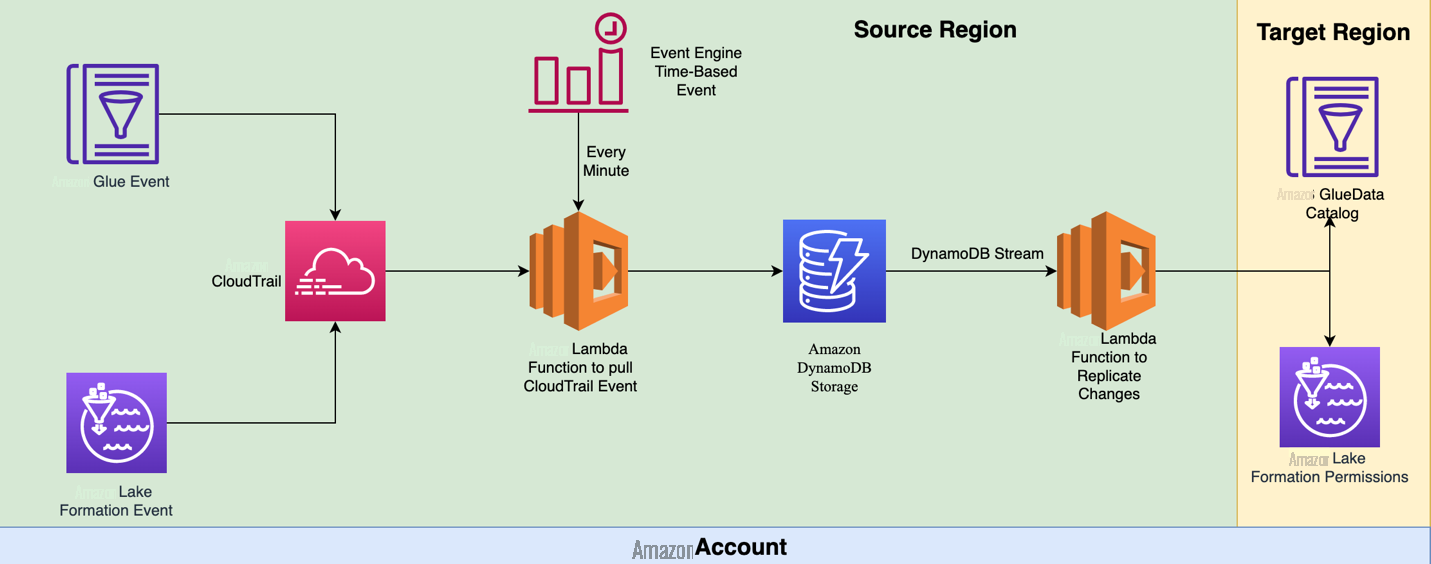
The Amazon Web Services CDK deploys two
The EventBridge rule triggers a Lambda job at a fixed interval. This job retrieves the configuration information and queries CloudTrail events related to the Data Catalog and Lake Formation that occurred in the past hour (the duration is configurable). All relevant events are then stored in a DynamoDB table.
After the event information is inserted into the DynamoDB table, another Lambda job is triggered. This job retrieves the configuration information and queries the DynamoDB table. It then applies all the changes to the target Region. If the tool is run again after making changes to the target Region, the changes are replaced with the latest Lake Formation permissions and Data Catalog from the source Region. Unlike on-demand mode, this utility also removes any Lake Formation permissions that were removed from the source Region from the target Region.
Limitations
This utility is designed to replicate permissions within a single account only. The on-demand mode replicates a snapshot and doesn’t remove existing permissions, so it doesn’t perform delete operations. The API currently doesn’t support replicating changes to row and column permissions.
Conclusion
In this post, we showed how you can use this utility to migrate the Amazon Web Services Glue Data Catalog and Lake Formation permissions from one Region to another. It can also keep the source and target Regions synchronized if any changes are made to the Data Catalog or the Lake Formation permissions. Implementing it across Regions (multi-Region) is a good option if you are looking for the most separation and complete independence of your globally diverse data workloads. Also consider the trade-offs. Implementing and operating this strategy, particularly using multi-Region, can be more complicated and more expensive, than other DR strategies.
To get started, checkout the
-
Amazon Web Services Glue -
Amazon Web Services Lake Formation
About the authors
 Vivek Shrivastava
is a Principal Data Architect, Data Lake in Amazon Web Services Professional Services. He is a Bigdata enthusiast and holds 13 Amazon Web Services Certifications. He is passionate about helping customers build scalable and high-performance data analytics solutions in the cloud. In his spare time, he loves reading and finds areas for home automation
Vivek Shrivastava
is a Principal Data Architect, Data Lake in Amazon Web Services Professional Services. He is a Bigdata enthusiast and holds 13 Amazon Web Services Certifications. He is passionate about helping customers build scalable and high-performance data analytics solutions in the cloud. In his spare time, he loves reading and finds areas for home automation


The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.