We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Best practices for creating highly available workloads

Many public sector organizations that are moving to the cloud often misunderstand that the architecture of Amazon Web Services (Amazon Web Services) Regions and Availability Zones fundamentally changes how they should think about disaster recovery and resiliency. Prior to joining Amazon Web Services, I spent many years helping organizations understand and build out disaster recovery plans. Now at Amazon Web Services, I work with customers of all sizes across the public sector to build cost-effective and resilient workloads. In this blog post, I share some best practices to answer common questions about building highly available workloads, and share some ways to consider high availability, disaster recovery, and application resiliency within Amazon Web Services.
Do I need to deploy my workload in multiple Regions?
When organizations ask “Do I need to go multi-Region to support my disaster recovery needs?” my first question is to ask about the workload’s recovery time objective (RTO), which is how much downtime you can tolerate, and recovery point objective (RPO), which is how much data you can afford to lose.
The primary mistake I see many organizations make is not having well-defined RTO and RPO targets before beginning to talk about disaster recovery. Every organization wants zero downtime and zero data loss, but the reality is that systems break. Even Werner Vogels, chief technology officer (CTO) of Amazon, stated “
In the on-premises world, running workloads across several data centers—what most organizations think of as “disaster recovery”—is necessary for many RTO/RPO targets, as the data center is a single point of failure. However, when moving workloads to Amazon Web Services, a best practice is to deploy a workload across multiple
Every organization and workload are different. Some public sector organizations might have workloads that can tolerate a higher RTO target (e.g., longer time to recovery). For example, a nonprofit organization’s fundraising application might only need an RTO/RPO target of hours. Conversely, a nonprofit healthcare organization might have a critical workload that lives depend on, leading to an RTO/RPO target of minutes or even real-time. While no organization wants downtime, keep in mind that as RTO/RPO targets decrease (e.g., quicker recovery and less data loss), cost and complexity can increase dramatically (Figure 1).
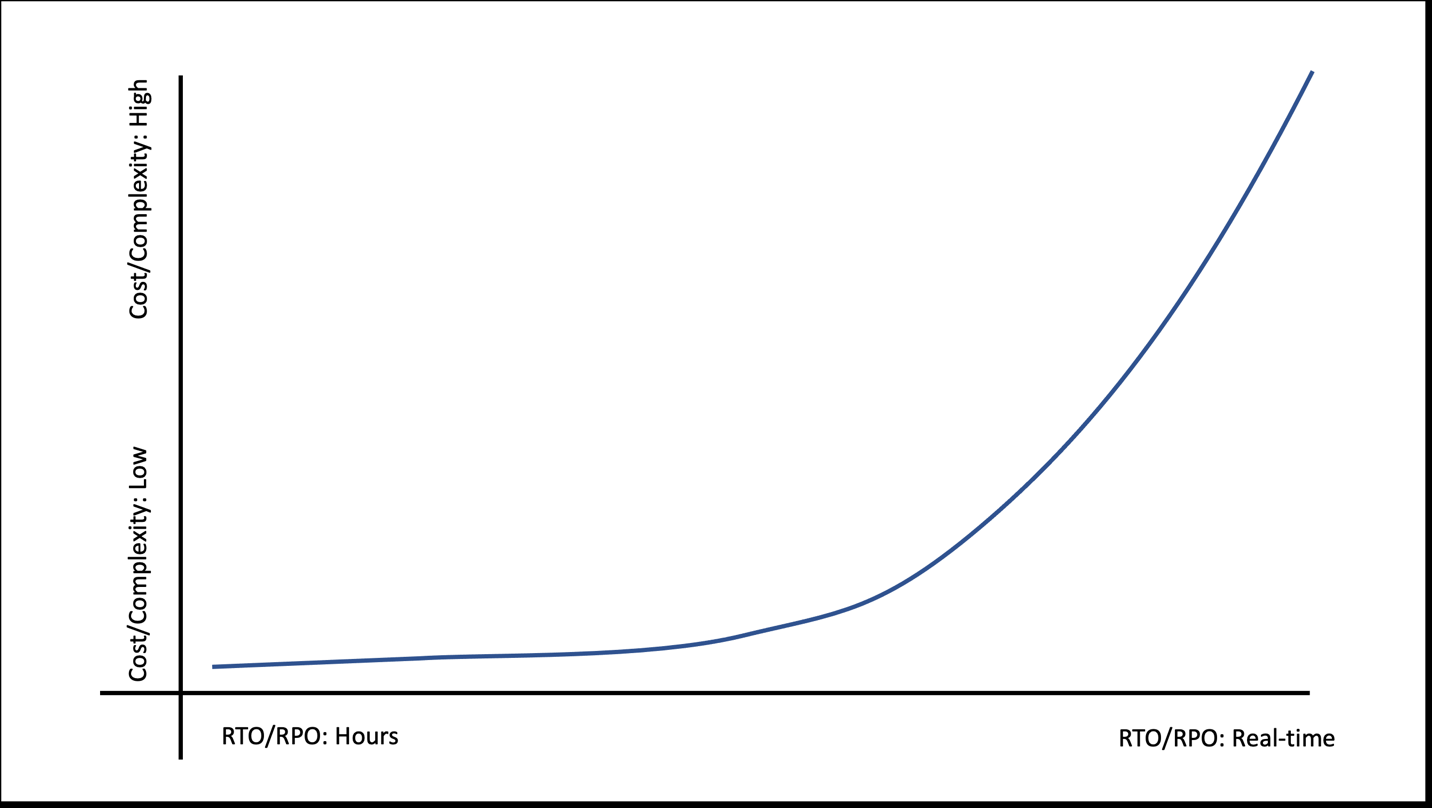
Figure 1. As RTO/RPO decreases, like when you reduce the time you can be down and the amount of potential data loss, costs can increase substantially.
That said, Amazon Web Services provides design patterns for a number of
How do I make my workload as resilient as possible?
While an organization may not need to deploy their workload simultaneously in multiple Regions (say as part of a multi-Region active/active disaster recovery strategy), they still want to make sure that disruptions are minimized and the workload is as resilient as possible.
Amazon Web Services has published many patterns in the
Consider control planes and data planes
At Amazon Web Services, we often talk about
Implement static stability to support availability
Another common pattern is
For example, with a workload running on Amazon EC2 across three Availability Zones within an
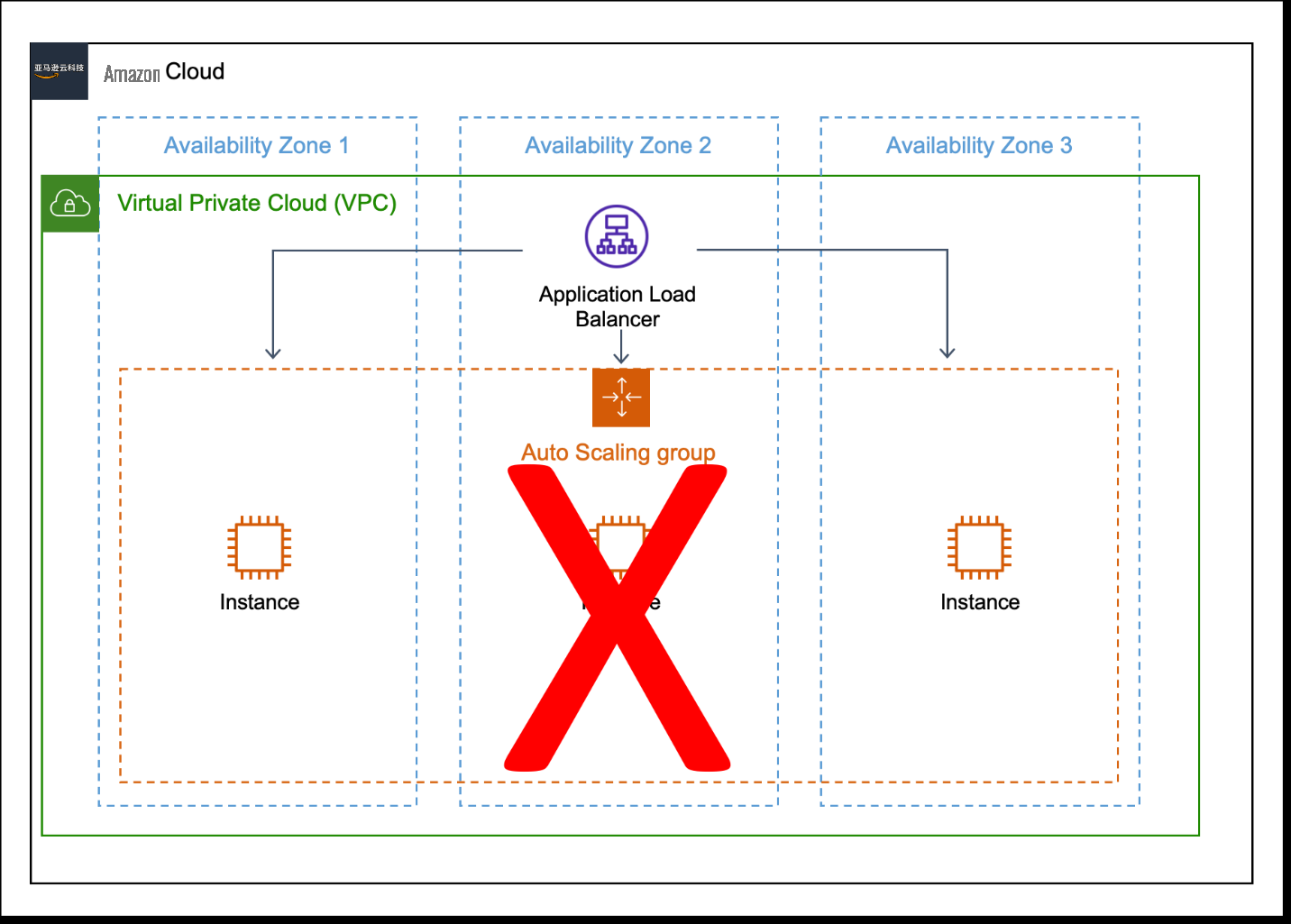
Figure 2. A workload that does not demonstrate static stability. The workload requires three Amazon EC2 instances, but only has two after Availability Zone 2 experiences downtime.
Even during an interruption of service, static stability means that a workload can still meet performance criteria. To achieve static stability in this example, the workload should run two Amazon EC2 instances in each Availability Zone. Even with the loss of an Availability Zone and an impact to the auto scaling service, the workload can continue to meet performance objectives (Figure 3).
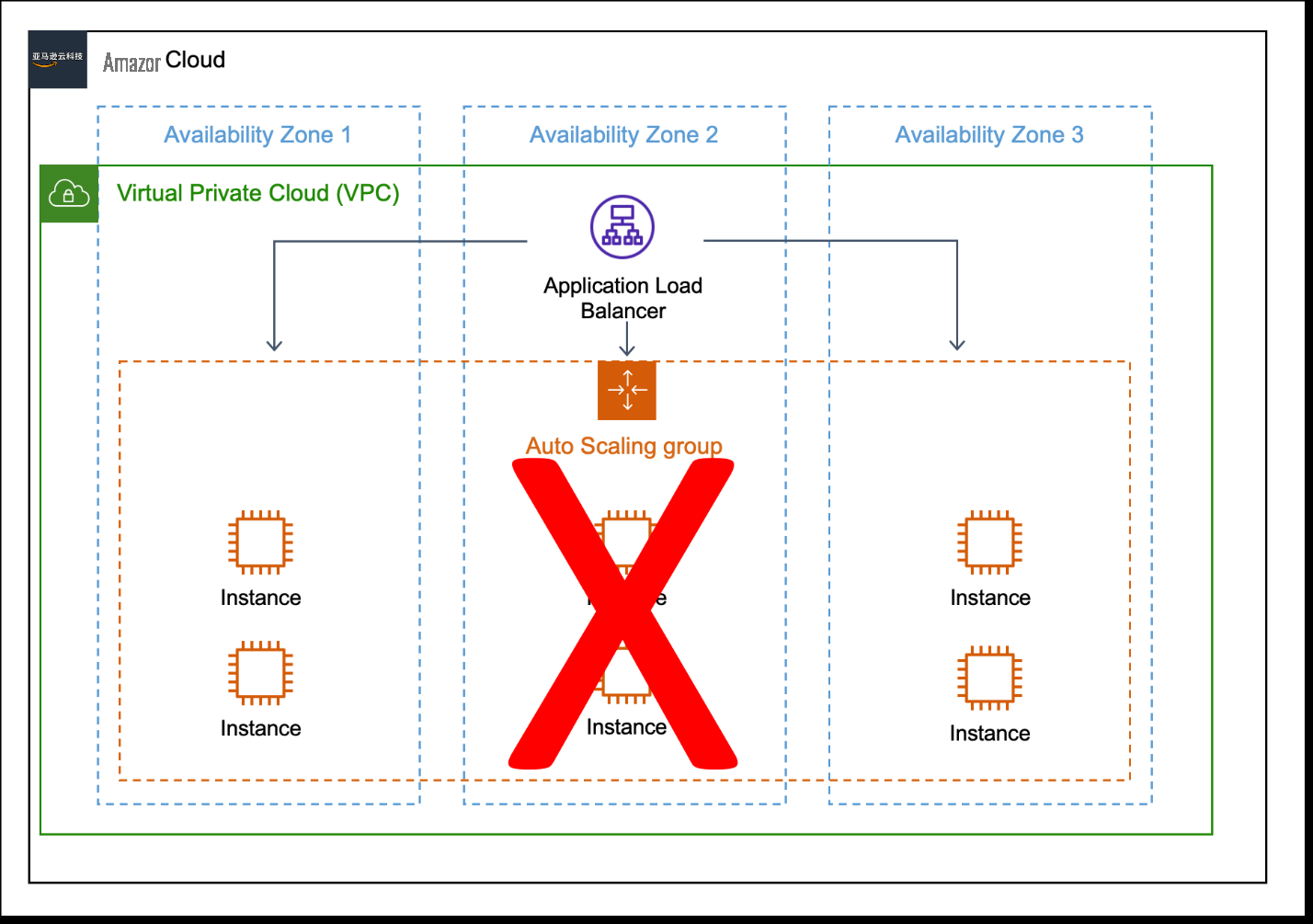
Figure 3. A workload that demonstrates static stability. This workload requires three Amazon EC2 instances and has four, even when Availability Zone 2 experiences downtime.
Static stability is a workload property that Amazon Web Services works hard to achieve. Maintaining this property may mean that your workload is slightly over-provisioned, but it is more resilient to unexpected failures.
Build with automation to save time and support scalability
The final pattern is automation. Many of the organizations I work with don’t have enough people or funding to move their mission forward in the way they would like. Automation is a way for technology to support the mission, not hinder it or act as a distraction.
Organizations usually use source control tools to protect and version source code. Why should cloud infrastructure be any different? There are many different infrastructure as code (IaC) tools available, like
Building automation does require more upfront time, which is why some organizations decide to skip it—sacrificing long-term gains for the short-term. However, successful organizations put in the time to automate their deployments and treat their infrastructure as code. This practice can pay off in the future, and as your organization decides to scale, you can re-deploy your architecture and workloads to multiple Amazon Web Services accounts with ease. Automation also supports disaster recovery objectives by helping deploy workloads simply across multiple Amazon Web Services Regions. Due to automation, one of the public sector customers I work with is able to deploy changes to their workloads over 6,000 times a week.
Conclusion and next steps in creating highly available workloads
In this blog post, I discussed considerations for building a disaster recovery plan. An organization’s disaster recovery plan should be based around recovery time and recovery point objectives for each of the workloads in question. These objectives will help the organization determine what type of disaster recovery solution is most appropriate, given cost and other resource considerations.
Key workload patterns can help organizations implement more resilient workloads. These patterns include reducing the blast radius of your workloads, so if something fails, the impact is limited and does not negatively impact your entire workload; static stability, which allows workload to continue to serve customer-facing requests even in the face of a negative impact; and automation, which can help teams of any size scale beyond what they could ever do otherwise.
As a next step, examine your workloads and determine what the RTO/RPO objectives are. Look at your existing architecture and determine if you can remove bottlenecks or other single points of failure. Do you have control plane functionality intermingled with data plane functionality? Can you refactor this code to provide better resiliency? Are team members spending time on
Learn more about the engineering patterns Amazon Web Services uses to build systems in the
Read more about Amazon Web Services for resiliency in the public sector:
-
The Goldilocks zone for disaster recovery, business continuity planning, and disaster preparedness -
Protect critical services with new Continuity of Government IT on Amazon Web Services solution guide -
Building digital capabilities to withstand future challenges, from cyberattacks to severe weather events -
How Livingston Parish prepares for natural disasters by improving resiliency in the cloud -
How Rockdale County improved operations and security with the cloud
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.