We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Amazon Aurora PostgreSQL: cross-account synchronization using logical replication
In this post, we show you how to set up cross-account logical replication using
You can customize the solution to meet specific requirements, including selective replication at the database, schema, or table level. This approach offers flexibility, scalability, and enhanced security, empowering organizations to meet specific use cases, such as
- Development and Testing: You can use the cross-account replica for development and testing purposes without impacting the production environment. Developers and testers can work on the replica, perform experiments, run simulations, and validate changes without affecting the live production database.
- Data Analysis and Reporting: You can use the replica for data analysis, reporting, and generating insights without impacting the primary database’s performance. This allows for offloading resource-intensive analytical queries, facilitating business intelligence initiatives, and generating timely reports.
- Auditing and Compliance Reporting: You can use the cross-account replica for auditing and compliance reporting purposes if you have an Amazon Web Services account dedicated for auditing. It provides a separate and immutable copy of the production data, ensuring data integrity and facilitating audit trails.
Solution overview
PostgreSQL logical replication provides fine-grained control over replicating and synchronizing parts of a database. For example, you can use logical replication to replicate an individual table or collection of tables of a database. For more information about the PostgreSQL implementation of logical replication, refer to
The following diagram illustrates our solution architecture.
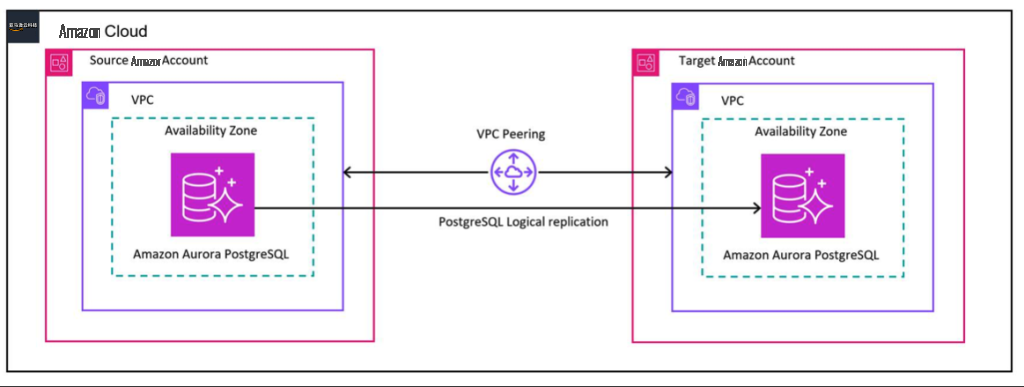
Amazon Aurora PostgreSQL has a function called
aurora_volume_logical_start_lsn()
, which identifies the beginning of the record in the logical Write Ahead Log (WAL) stream for a given Aurora cluster volume. You can use this function during logical replication setup to determine the Log Sequence Number (LSN) at which the target database clone is taken. You can then use logical replication to continuously stream the newer data recorded after the LSN and synchronize the changes from publisher to subscriber.
This function is available on the following versions of Aurora PostgreSQL:
- 15.2 and higher 15 versions
- 14.3 and higher 14 versions
- 13.6 and higher 13 versions
- 12.10 and higher 12 versions
- 11.15 and higher 11 versions
Prerequisites
To set up cross-account logical replication using
-
- Two Amazon Web Services accounts (source and target).
-
An Aurora PostgreSQL database cluster.
Your Aurora PostgreSQL version must meet the specified level mentioned above in order to utilize theaurora_volume_logical_start_lsn()function.
Set therds.logical_replicationparameter in the RDS DB cluster parameter group on both the source and destination clusters.- VPC peering between primary and secondary Amazon Web Services accounts.
- Set up clone of your Aurora PostgreSQL on a different Amazon Web Services account on the same region.
- All tables to be logically replicated from source to target database across Amazon Web Services accounts must have a primary key.
Limitations
When working on a logical replication setup, it is important to consider the restrictions that exist in PostgreSQL. Please refer
Aurora PostgreSQL doesn’t support cross-account cloning across Regions, so the source and target (clone) databases should be in the same Region.
Solution walk-through
Using these Amazon Web Services services will result in costs, so remember to clean up the services if you utilize this post for testing purpose
In this section we implement the solution using the following steps:
- Clone the source Aurora cluster in the target account
- Configure the source database
- Publication for PostgreSQL Logical Replication
- Create the replication slot for the source database
- Get the LSN of the target database
- Drop replication on target
- Create a subscription on the target database
- Start logical replication
- Monitor replication
- Clean up
Clone the source Aurora cluster in the target account
-
On your source Amazon Web Services account, open the
Amazon Web Services Resource Access Manager Console and create a resource share for your Amazon Aurora PostgreSQL

-
Specify the resource share details (Source: Aurora PostgreSQL DB cluster)

-
Provide permission details
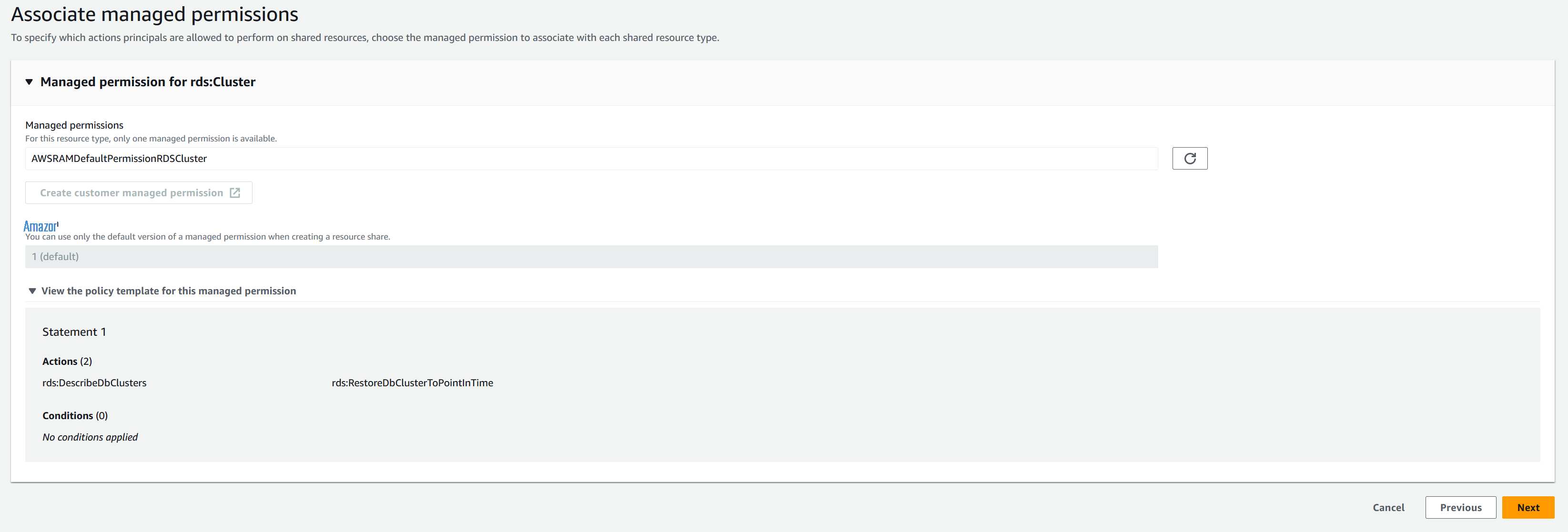
-
Provide the target Amazon Web Services account details to share the source Aurora PostgreSQL DB resource.
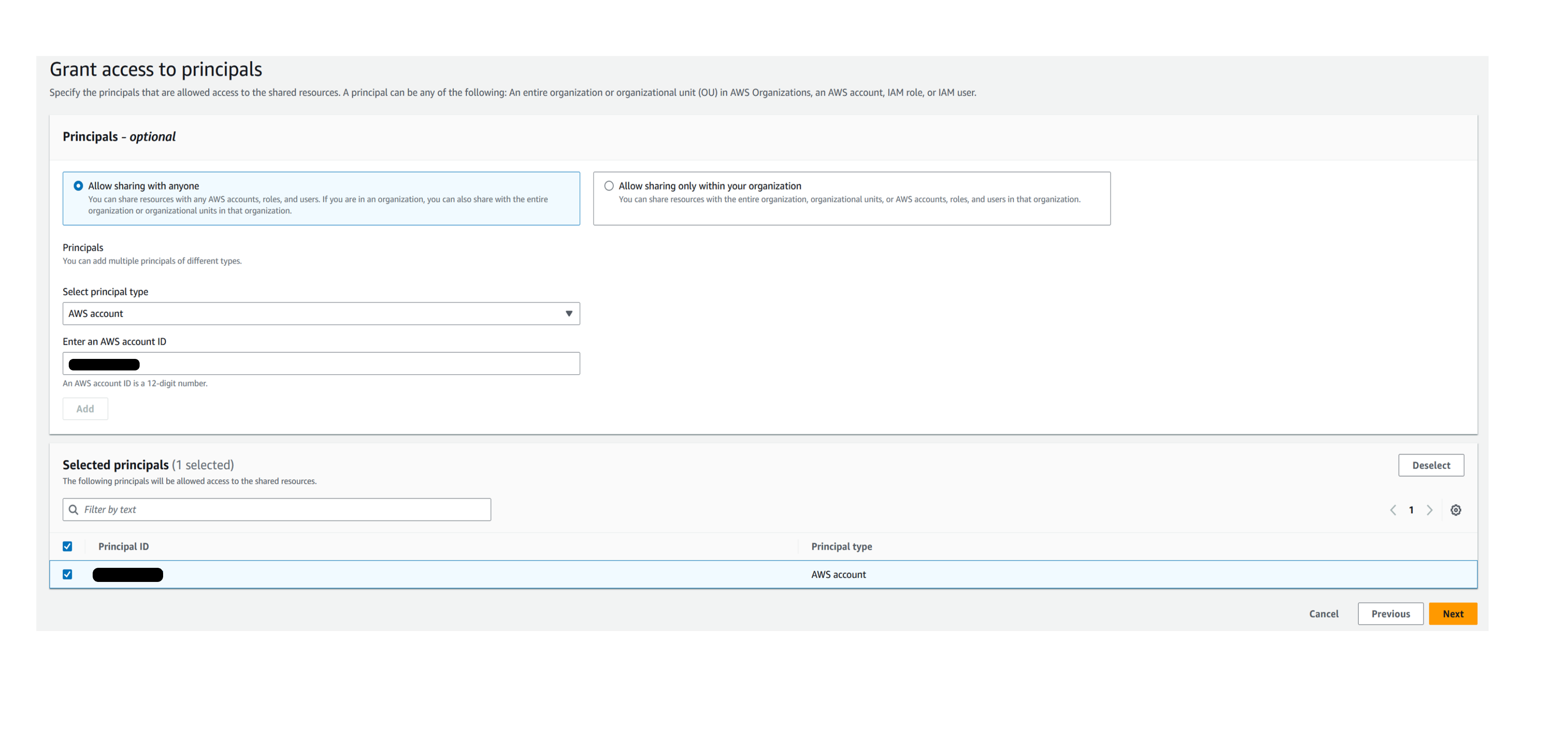
-
Validate the status of the resource sharing on the Amazon Web Services Resource Access Manager console (The status would show “Associating”)
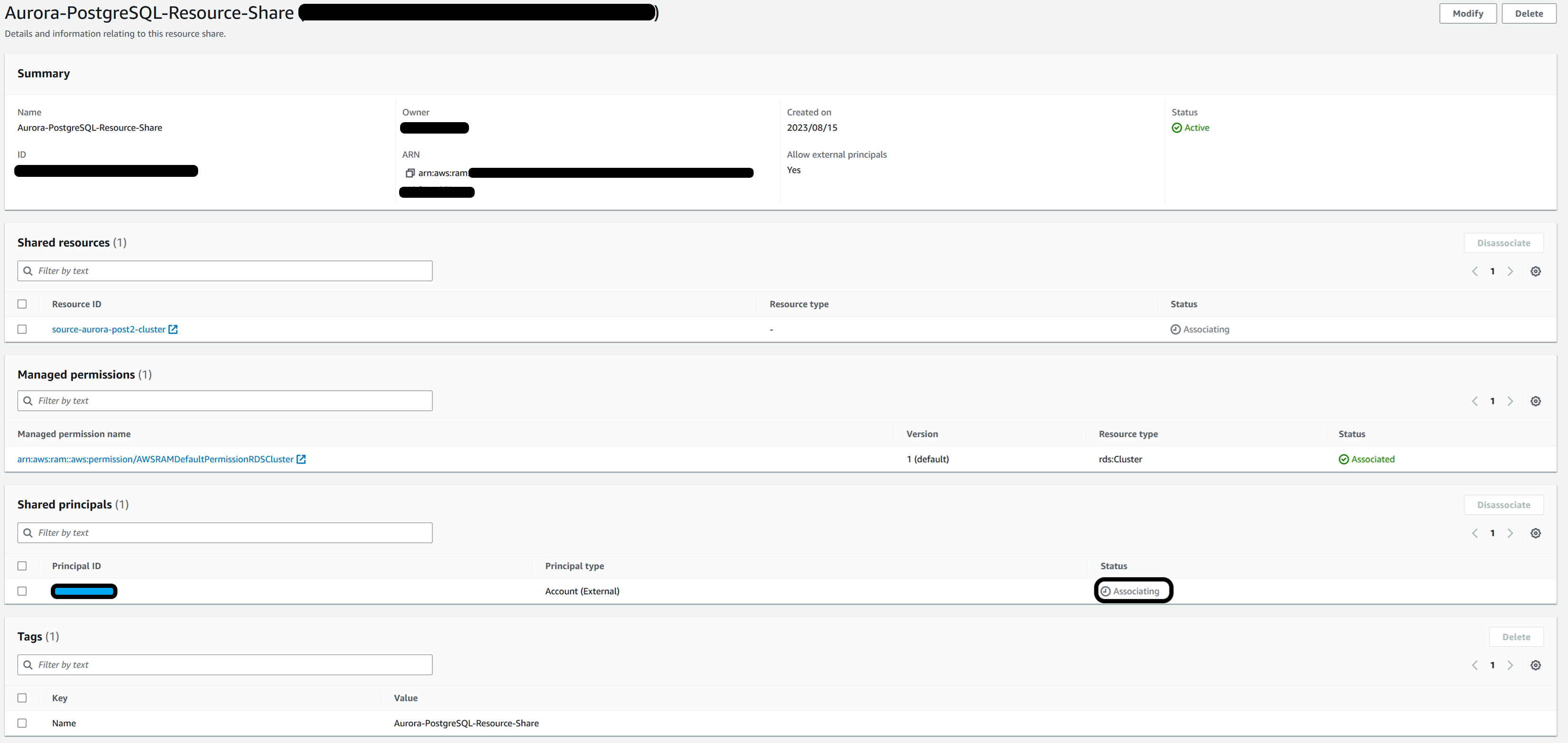
-
On your target Amazon Web Services account, open the Amazon Web Services Resource Access Manager console and accept the invitation for resource sharing. Select the Aurora DB resource and “Accept Sharing”

-
Once the invitation is accepted on target Amazon Web Services account, go back to Amazon RDS console of the source Amazon Web Services account, under
Connectivity & security
– scroll down and validate if you can find the target account in the a section
Share DB cluster with other Amazon Web Services accounts
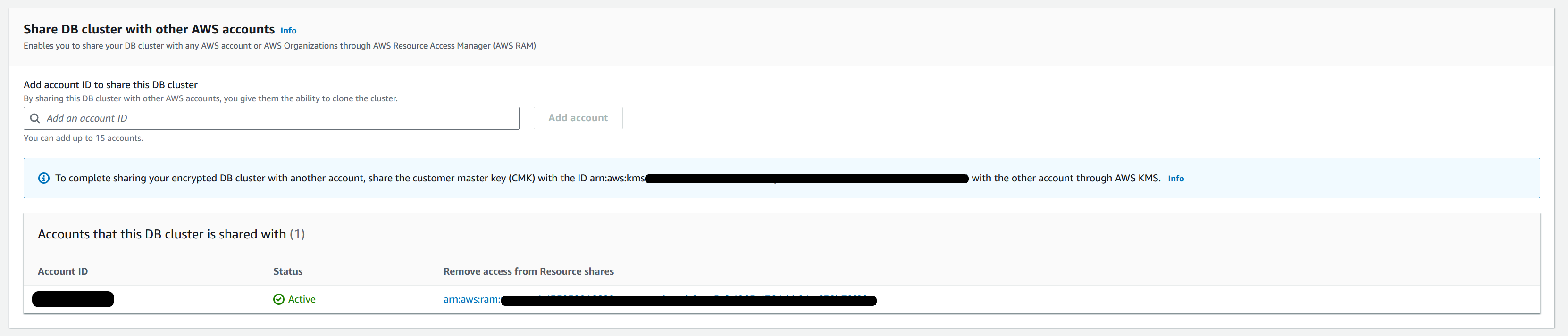
-
Once you share the source DB with target account, create the clone DB on the target account.

For more details, follow steps in
Configure the source database
Configure the WAL parameters
In PostgreSQL, logical replication is based on
On the current source database, make sure the following settings are configured. If not already enabled, you can configure these parameters in a new parameter group and assign this parameter group to your database, which requires a database reboot.
- On the Amazon RDS console, choose Parameter groups in the navigation pane.
- Choose Create a new parameter group .
-
Modify the following parameters
-
wal_level
– The wal_level parameter determines how much information is written to the WAL. The default value is minimal, which writes only the information needed to recover from a crash or immediate shutdown. The replica adds logging required for WAL archiving as well as information required to run read-only queries on a standby server. Setting this parameter to logical enables the replica database to be in read-only mode. For this post, we set
rds.logical_replication=1to achievewal_level=logical. This way, the same information is logged as with replica, plus information needed to allow extracting logical change sets from the WAL. The logical setting also adds information necessary to support logical decoding. - max_replication_slots – Setting this parameter ensures the primary database cluster retains enough WAL segments for replicas to receive them and the primary only recycles the transaction logs after it has been consumed by all the replicas. The advantage is that a replica can never fall behind so much that a re-sync is needed. This parameter must be set to at least the number of subscriptions expected to connect, plus some reserve for table synchronization.
- max_worker_processes – This parameter sets the maximum number of background processes that the database can support. It creates enough worker processes to serve each replica that corresponds to the WAL sender and handles other background processes the database system is running. The best practice is to set this to the number of CPUs you want to share for PostgreSQL exclusively. Generally, one per database is needed on the provider node and one per database is needed on the subscriber node in addition to the background processes.
- max_wal_senders – This parameter sets the maximum number of concurrent connections from replication databases (the maximum number of simultaneously running WAL sender processes). The default is zero, meaning replication is disabled. If starting with one replica, you must set this to 3. For every replica, you can add two WAL senders.
-
wal_level
– The wal_level parameter determines how much information is written to the WAL. The default value is minimal, which writes only the information needed to recover from a crash or immediate shutdown. The replica adds logging required for WAL archiving as well as information required to run read-only queries on a standby server. Setting this parameter to logical enables the replica database to be in read-only mode. For this post, we set
To use the Amazon Web Services CLI to complete these steps, enter the following commands to set the parameters at the parameter group:
You can verify the parameter changes on the Amazon RDS console. In the following screenshot,
rds.logical_replication=1
is set.

- After the parameter settings in the parameter group are modified, you need to reboot the cluster for the changes to take effect, which causes an outage.
- Apply the parameter group to the database instance.
Publication for PostgreSQL Logical Replication
- Connect to source database and specify the below command to create a new publication on the source database for all tables (or a set of tables) to be replicated.
- Validate the publication is created on the source database.
Create the replication slot for the source database
- Create a Replication slot for the source database publication that was created in previous step.
- Validate the replication slot is created using the following query.
Get the LSN of the target database
- Identify the Logical Sequence number from target database for Logical replication
- Query the LSN, which identifies the beginning of a record in the WAL stream from where the logical replication should begin, you need this number later in the process, so make a note of it.
If the query to retrieve the LSN from the cloned database
aurora_volume_logical_start_lsn()
isn’t supported on your Aurora PostgreSQL version, perform a minor database upgrade of the clone to bring it to the nearest supported version as mentioned in the previous section.
Drop the replication slot on the target database
- Replication slot on the target database is brought over as part of the cloning process and not needed on the target database.
- Drop the replication slot on the target database
- Validate the replication slot is dropped on the target database
Create a subscription on the target database
- Create a subscription on the target Aurora database clone (with source database credentials):
- Validate the Subscription created on the target database
Start logical replication between source and target database
- Determine the origin value of replication from the system catalog table in the cloned (target) database
-
Kick off replication in the cloned target database using the values determined in the preceding step:
<ro_name> ---> pg_33462, refers to the replication origin for target database.<lsn> ---> 0/6799E20, log_sequence_numberis the value returned by the earlier query of theaurora_volume_logical_start_lsnfunction.The previous command uses the
pg_replication_origin_advance function to specify the starting point in the log sequence for replication. - Enable the subscription on the target database with the following code:
Monitor Replication
To monitor replication, run the following query on the source Aurora database in the primary Amazon Web Services account
The “active” column should show the value t (true) and the values for
diff_size
and
diff_bytes
should be decreased based on the sync between the source and target databases. See the following example:
You can view the PostgreSQL logs on the Events tab of the RDS console. See the following example code:
Note that sequence data isn’t replicated. The data in serial or identity columns backed by sequences are replicated as part of the table, but the sequence itself still shows the start value on the subscriber. If the subscriber is used as a read-only database, then this should typically not be a problem. If, however, some kind of switchover or failover to the subscriber database is intended, then the sequences need to be updated to the latest values, either by copying the current data from the publisher (perhaps using
pg_dump
) or by determining a sufficiently high value from the tables themselves.
Clean up
To clean up when finished, complete the following steps:
- Stop the logical replication and drop replication slots by connecting to the publisher (source database) and running the following SQL command
-
The replication slots can’t be active when you run this command. To de-activate the slot perform the following steps:
-
Modify the DB cluster parameter group associated with the publisher, as described in
modify-db-cluster-parameter-group . Set therds.logical_replicationstatic parameter to 0. -
Restart the publisher DB cluster for the change to the
rds.logical_replicationstatic parameter to take effect.
-
Modify the DB cluster parameter group associated with the publisher, as described in
- To drop a subscription that no longer has a replication slot upstream, run the following commands in the target database
-
Delete the Aurora DB clusters and DB instances that you no longer need to avoid any cost associated with the database instances. For instructions, refer to
Deleting Aurora DB clusters and DB instances .
WAL storage
In Amazon Aurora for PostgreSQL, the write-ahead log (WAL) storage is managed automatically by the service, and you don’t have direct control over its size.
Troubleshooting
By following
potential issues in your logical replication setup. It’s worth noting that data may experience delays in reaching the target system due to network glitches or unexpected high volumes on the source system; however, the system will eventually catch up and synchronize the data accordingly.
One of the common issues is duplicate key on target subscriber database, to avoid this kind of error, ensure to use
aurora_volume_logical_start_lsn()
function to capture correct LSN number to enable subscription on target.
Future Object Replication: In this scenario, we have enabled logical replication for all tables. Tables created after enabling replication we have to run below command to push changes for new tables.
Conclusion
In this post, we reviewed the steps to perform an Aurora PostgreSQL database cross-account clone (standalone cluster) with continuous replication with your primary database. Furthermore, we discussed the utilization of
aurora_volume_logical_start_lsn()
function in conjunction with native PostgreSQL logical replication. This combination enables the replication of your database across Amazon Web Services accounts,
while also leveraging the capabilities of Aurora clone. This feature is useful for running your lower database environment clones (synced with your primary database) on a different Amazon Web Services account.
We welcome the feedback. If you have questions or comments, leave them in the comments section.
About the Authors
 Senthil Ramasamy
is a Senior Database Consultant at Amazon Web Services. He works with Amazon Web Services customers to provide guidance and technical assistance on database services, helping them with database migrations to the Amazon Web Services Cloud and improving the value of their solutions when using Amazon Web Services.
Senthil Ramasamy
is a Senior Database Consultant at Amazon Web Services. He works with Amazon Web Services customers to provide guidance and technical assistance on database services, helping them with database migrations to the Amazon Web Services Cloud and improving the value of their solutions when using Amazon Web Services.
 John Lonappan
is a Senior Database Specialist Consultant / Solutions Architect at Amazon Web Services with a focus on relational databases. Prior to Amazon Web Services, John worked as a Database Architect for large data center providers across the globe. Outside of work, he is passionate about long drives, EV conversion, playing chess, and traveling.
John Lonappan
is a Senior Database Specialist Consultant / Solutions Architect at Amazon Web Services with a focus on relational databases. Prior to Amazon Web Services, John worked as a Database Architect for large data center providers across the globe. Outside of work, he is passionate about long drives, EV conversion, playing chess, and traveling.
 Harshad Gohil
is a Cloud/Database Consultant with Professional Services team at Amazon Web Services. He helps customers to build scalable, highly available and secure solutions in Amazon Web Services cloud. His focus area is homogeneous and heterogeneous migrations of on-premise infrastructure to Amazon Web Services cloud.
Harshad Gohil
is a Cloud/Database Consultant with Professional Services team at Amazon Web Services. He helps customers to build scalable, highly available and secure solutions in Amazon Web Services cloud. His focus area is homogeneous and heterogeneous migrations of on-premise infrastructure to Amazon Web Services cloud.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.