We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Alcion supports their multi-tenant platform with Amazon OpenSearch Serverless
This is a guest blog post co-written with Zack Rossman from Alcion.
Alcion, a security-first, AI-driven backup-as-a-service (BaaS) platform, helps Microsoft 365 administrators quickly and intuitively protect data from cyber threats and accidental data loss. In the event of data loss, Alcion customers need to search metadata for the backed-up items (files, emails, contacts, events, and so on) to select specific item versions for restore. Alcion uses
OpenSearch Service is a fully managed service that makes it easy to deploy, scale, and operate OpenSearch in the Amazon Web Services Cloud. OpenSearch is an Apache-2.0-licensed, open-source search and analytics suite, comprising OpenSearch (a search, analytics engine, and vector database), OpenSearch Dashboards (a visualization and utility user interface), and plugins that provide advanced capabilities like enterprise-grade security, anomaly detection, observability, alerting, and much more.
In this post, we share how adopting OpenSearch Serverless enabled Alcion to meet their scale requirements, reduce their operational overhead, and secure their tenants’ data by enforcing
OpenSearch Service managed domains
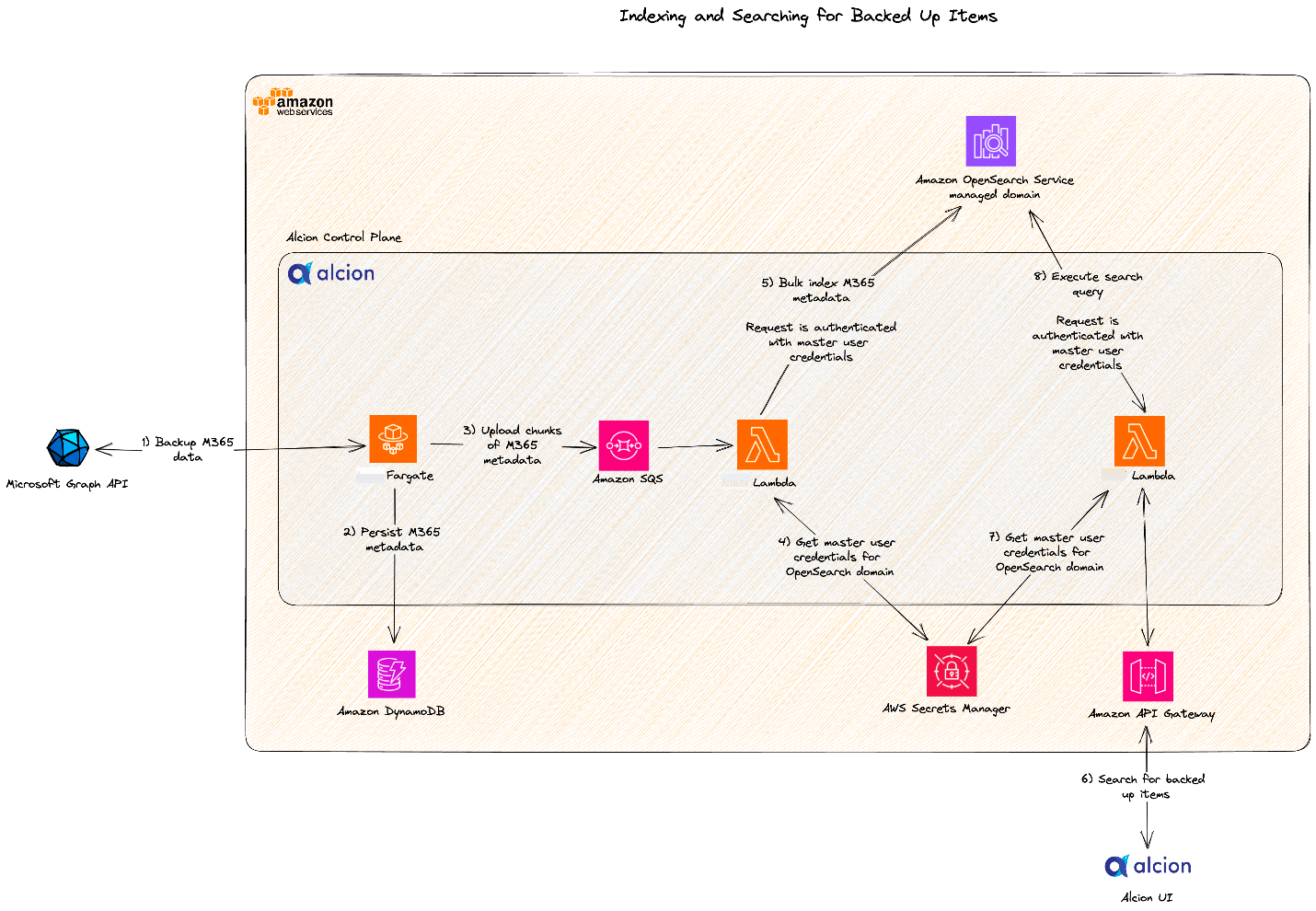
For the first iteration of their search architecture, Alcion chose the managed domains deployment option in OpenSearch Service and was able to launch their search functionality in production in less than a month. To meet their security, scale, and tenancy requirements, they stored data for each tenant in a dedicated index and used
The team at Alcion used several features of OpenSearch Service managed domains to improve their operational stance. They introduced index aliases, which provide a single alias name to access (read and write) multiple underlying indexes. They also configured
The following architecture diagram shows how Alcion configured their OpenSearch managed domains.
The following diagram shows how Microsoft 365 data was indexed to and queried from tenant-specific indexes. Alcion implemented request authentication by providing the OpenSearch primary user credentials with each API request.
OpenSearch Serverless overview and tenancy model options
OpenSearch Service managed domains provided a stable foundation for Alcion’s search functionality, but the team needed to manually provision resources to the domains for their peak workload. This left room for cost optimizations because Alcion’s workload is bursty—there are large variations in the number of search and indexing transactions per second, both for a single customer and taken as a whole. To reduce costs and operational burden, the team turned to OpenSearch Serverless, which offers auto-scaling capability.
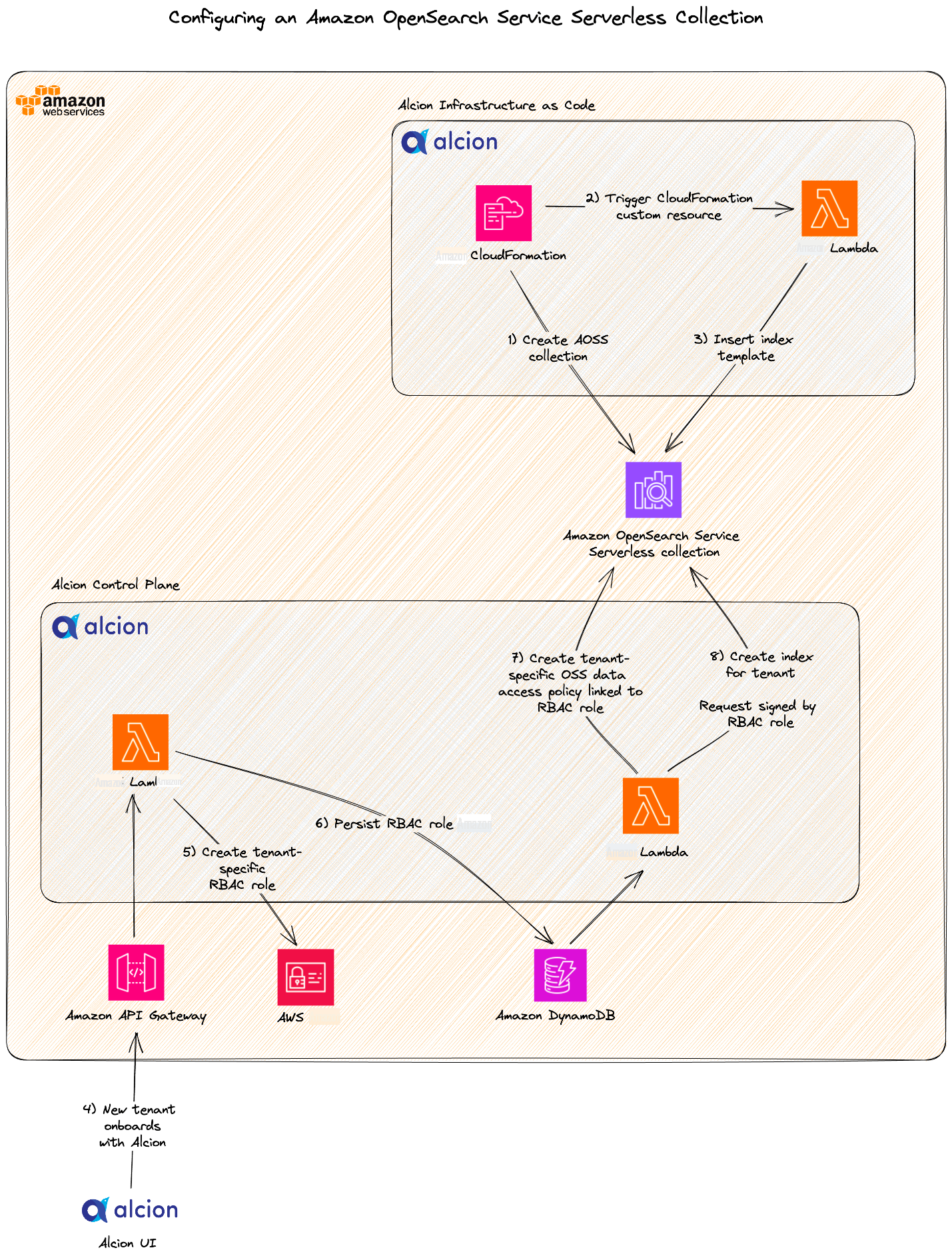
To use OpenSearch Serverless, the first step is to create a collection. A collection is a group of OpenSearch indexes that work together to support a specific workload or use case. The compute resources for a collection, called OpenSearch Compute Units (OCUs), are shared across all collections in an account that share an encryption key. The pool of OCUs is automatically scaled up and down to meet the demands of indexing and search traffic.
The level of effort required to migrate from an OpenSearch Service managed domain to OpenSearch Serverless was manageable thanks to the fact that OpenSearch Serverless collections support the same OpenSearch APIs and libraries as OpenSearch Service managed domains. This allowed Alcion to focus on optimizing the tenancy model for the new search architecture. Specifically, the team needed to decide how to partition tenant data within collections and indexes while balancing security and total cost of ownership. Alcion engineers, in collaboration with the OpenSearch Serverless team,
- Silo model: Create a collection for each tenant
- Pool model: Create a single collection and use a single index for multiple tenants
- Bridge model: Create a single collection and use a single index per tenant
All three design choices had benefits and trade-offs that had to be considered for designing the final solution.
Silo model: Create a collection for each tenant
In this model, Alcion would create a new collection whenever a new customer onboarded to their platform. Although tenant data would be cleanly separated between collections, this option was disqualified because the collection creation time meant that customers wouldn’t be able to back up and search data immediately after registration.
Pool model: Create a single collection and use a single index for multiple tenants
In this model, Alcion would create a single collection per Amazon Web Services account and index tenant-specific data in one of many shared indexes belonging to that collection. Initially, pooling tenant data into shared indexes was attractive from a scale perspective because this led to the most efficient use of index resources. But after further analysis, Alcion found that they would be well within the per-collection index quota even if they allocated one index for each tenant. With that scalability concern resolved, Alcion pursued the third option because siloing tenant data into dedicated indexes results in stronger tenant isolation than the shared index model.
Bridge model: Create a single collection and use a single index per tenant
In this model, Alcion would create a single collection per Amazon Web Services account and create an index for each of the hundreds of tenants managed by that account. By assigning each tenant to a dedicated index and pooling these indexes in a single collection, Alcion reduced onboarding time for new tenants and siloed tenant data into cleanly separated buckets.
Implementing role-based access control for supporting multi-tenancy
OpenSearch Serverless offers a multi-point, inheritable set of security controls, covering data access, network access, and encryption. Alcion took full advantage of OpenSearch Serverless
-
Allocate an index with a common prefix and the tenant ID (for example,
index-v1-<tenantID>) -
Create a dedicated
Amazon Web Services Identity and Access Management (IAM) role that is used to sign requests to the OpenSearch Serverless collection - Create an OpenSearch Serverless data access policy that grants document read/write permissions within a dedicated tenant index to the IAM role for that tenant
- OpenSearch API requests to a tenant index are signed with temporary credentials belonging to the tenant-specific IAM role
The following is an example OpenSearch Serverless data access policy for a mock tenant with ID
t-eca0acc1-12345678910
. This policy grants the IAM role document read/write access to the dedicated tenant access.
The following architecture diagram depicts how Alcion implemented indexing and searching for Microsoft 365 resources using the OpenSearch Serverless shared collection approach.
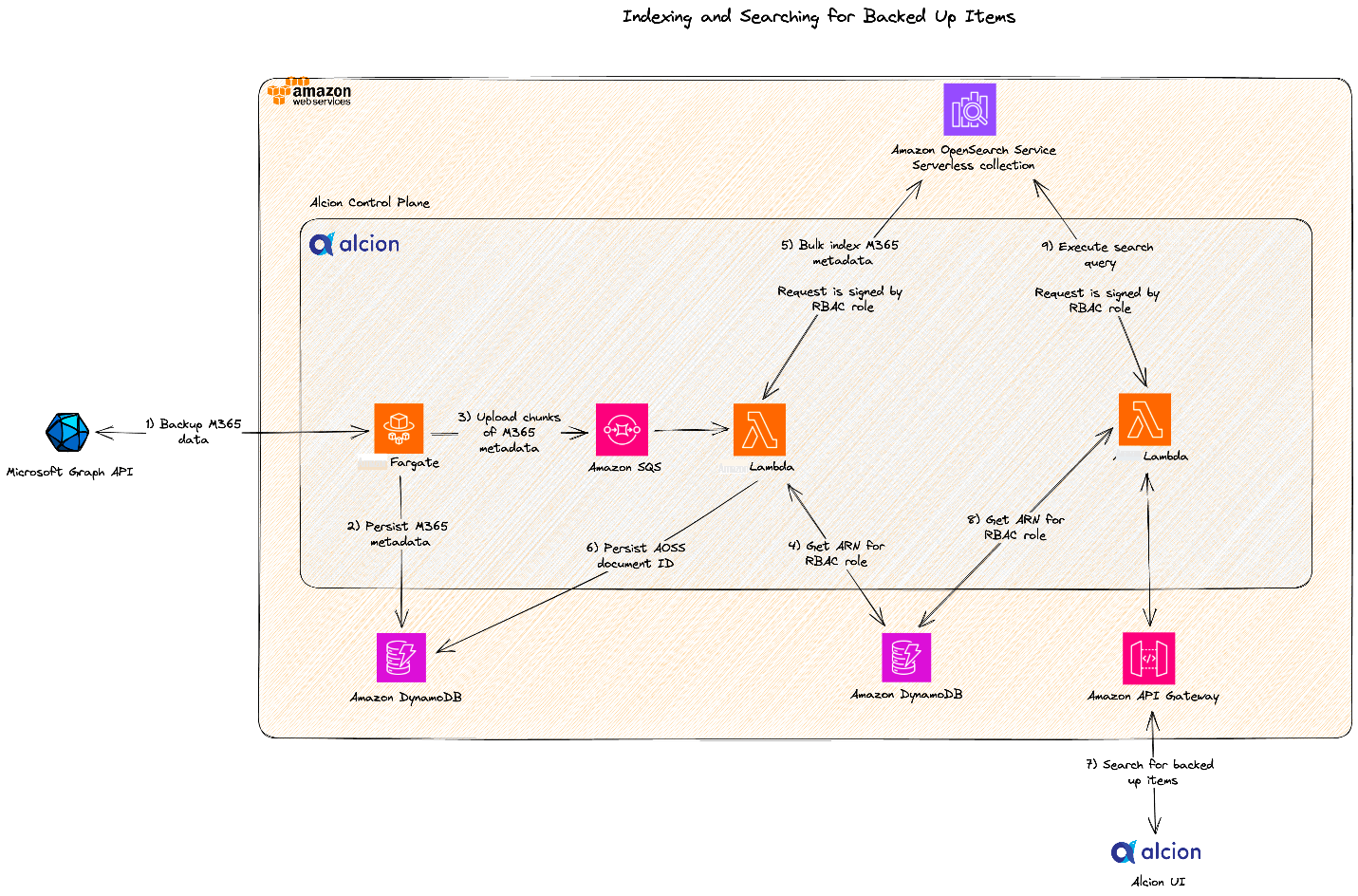
The following is the sample code snippet for sending an API request to an OpenSearch Serverless collection. Notice how the API client is initialized with a signer object that signs requests with the same IAM principal that is linked to the OpenSearch Serverless data access policy from the previous code snippet.
Conclusion
In May of 2023, Alcion rolled out its search architecture based on the shared collection and dedicated index-per-tenant model in all production and pre-production environments. The team was able to tear out complex code and operational processes that had been dedicated to scaling OpenSearch Service managed domains. Furthermore, thanks to the auto scaling capabilities of OpenSearch Serverless, Alcion has reduced their OpenSearch costs by 30% and expects the cost profile to scale favorably.
In their journey from managed to serverless OpenSearch Service, Alcion benefited in their initial choice of OpenSearch Service managed domains. In migrating forward, they were able to reuse the same OpenSearch APIs and libraries for their OpenSearch Serverless collections that they used for their OpenSearch Service managed domain. Additionally, they updated their tenancy model to take advantage of OpenSearch Serverless data access policies. With OpenSearch Serverless, they were able to effortlessly adapt to their customers’ scale needs while ensuring tenant isolation.
For more information about Alcion, visit their
About the Authors
 Zack Rossman is a Member of Technical Staff at Alcion.
He is the tech lead for the search and AI platforms. Prior to Alcion, Zack was a Senior Software Engineer at Okta, developing core workforce identity and access management products for the Directories team.
Zack Rossman is a Member of Technical Staff at Alcion.
He is the tech lead for the search and AI platforms. Prior to Alcion, Zack was a Senior Software Engineer at Okta, developing core workforce identity and access management products for the Directories team.
 Niraj Jetly is a Software Development Manager for Amazon OpenSearch Serverless.
Niraj leads several data plane teams responsible for launching Amazon OpenSearch Serverless. Prior to Amazon Web Services, Niraj led several product and engineering teams as CTO, VP of Engineering, and Head of Product Management for over 15 years. Niraj is a recipient of over 15 innovation awards, including being named CIO of the year in 2014 and top 100 CIO in 2013 and 2016. A frequent speaker at several conferences, he has been quoted in NPR, WSJ, and The Boston Globe.
Niraj Jetly is a Software Development Manager for Amazon OpenSearch Serverless.
Niraj leads several data plane teams responsible for launching Amazon OpenSearch Serverless. Prior to Amazon Web Services, Niraj led several product and engineering teams as CTO, VP of Engineering, and Head of Product Management for over 15 years. Niraj is a recipient of over 15 innovation awards, including being named CIO of the year in 2014 and top 100 CIO in 2013 and 2016. A frequent speaker at several conferences, he has been quoted in NPR, WSJ, and The Boston Globe.
 Jon Handler
is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the Amazon Web Services Cloud. Prior to joining Amazon Web Services, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler
is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the Amazon Web Services Cloud. Prior to joining Amazon Web Services, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.