We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
A Continuous Improvement Model for Interconnects within Amazon Web Services Data Centers
This blog post provides a look into some of the technical management and hardware decisions we make when building Amazon Web Services network infrastructure. Working with network engineers, we wrote this blog to reveal some of the work that goes on behind the scenes to provide Amazon Web Services services to our customers. In particular, this blog explores the complexity we faced when
Overview
The Amazon Web Services network operates on a massive global scale. As the largest cloud service provider, we often have to solve networking challenges at a size and complexity that few, if any, have ever even considered. Over the last 17 years, Amazon Web Services has rapidly expanded from one location in Virginia to
In 2018, during capacity planning, we realized the sheer size of our network, and the amount of data our customers send along it, necessitated we move from 100 GbE to 400 GbE optics to stay ahead of demand. Past experience, from our move to 100GbE, had also taught us that higher data rate products have a corresponding higher failure rate. Amazon Web Services has a core tenet to ensure redundancy across all layers of our network, and we have been able to minimize and largely eliminate any direct customer impact from hardware failures. But, as we prepared for the transition to 400 GbE, we realized that this deployment would be significantly more complex than previous generations. This increased complexity, along with higher data rates, meant that there was the potential for a compounding situation that could increase failure rates and strain our network. In light of this, we changed our approach towards interconnects to make sure their quality met our standards and provided the availability our customers depend on. In this blog post, we will explain how Amazon Web Services established a continuous improvement model for the tens of millions of interconnects in our data centers and successfully reversed the trend of increased failure rates with increased data rates.
The evolution of interconnects at Amazon Web Services
Optical interconnects are critical components of data centers and telecommunication networks that allow data to be moved to where it is required. They connect fiber-optic cables between transceivers with integrated lasers and detectors that offer the ability to both transmit and receive optical signals. Historically, Amazon treated optical interconnects as commodities, relying on vendors who manufacturing transceiver optics and cables to validate their products against industry-wide standards. This largely mirrors the conventional approach of other hyper-scalers and cloud providers, as standardizing these products and making them as interchangeable as possible helps simplify the operations and tools we used to run data centers, and reduces overall cost. Although this approach worked well for many years, during the deployment of the 100 Gigabit Ethernet (GbE) generation, we had to make reliability-based design decisions that incrementally reduced the margins of the link budget that had allowed a commodity-based approach to be successful. Although the reduction seemed small on paper, because we have tens of millions of interconnects, we saw a real and sustained impact. This would bring a new set of challenges that required significant investment to mitigate and solve.
Before the 400 GbE generation, optical interconnects delivered the required bandwidth through NRZ (non-return to zero) encoding, where there are two distinct levels (encoded as 0 or 1) driven at a specific signaling rate. For example, to achieve 100 GbE, we combined a 25 GbE signal over four fibers, or four wavelengths, for a total bandwidth of 100 GbE. To achieve 400 GbE, we had to not only increase the signaling rate from 25 GbE to 100 GbE, but also change the encoding to PAM4 (4-level pulse-amplitude modulation) which increases the levels to 4 (encoded as 00, 01, 10, or 11). This change in encoding enables each pulse of data to carry more bits and thus more information. You can see the change in the data rate and encoding, and the additional complexity that this results in, in the signal eye diagrams in Figure 1. Signal eye diagrams represent the time on the x-axis and the power levels on the y-axis. Transitions between the signal levels result in a pattern that resembles a series of eyes between a pair of rails. To handle this additional complexity, we needed additional components to help clean up and maintain the signal so that customer data can be transmitted with as few errors and dropped packets as possible.
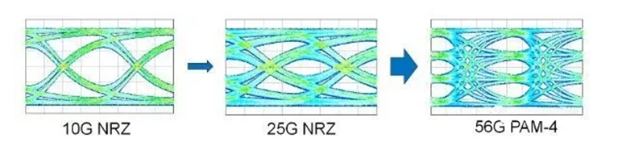
Figure 1. Difference between two distinct power levels for 10G/25G NRZ and the four distinct power levels for 56G PAM-4 is visible
One of the critical components that has enabled 400 GbE interconnects is DSPs (digital signal processors), DSPs sit in between switch application-specific integrated circuits (ASICs) and both transmit and receive OEs (optical engines) of the pluggable optics. When we move to higher baud-rates (a modulate rate or number of signal changes per unit of time), the conventional analog re-timers used in the 100GbE module generation do not provide the flexibility and performance to compensate for the additional complexity in electrical and optical channels. The DSP improves on this by taking an analog high-speed signal and converting it to the digital domain, where we can apply signal processing to clean up and improve the flow of data using several key tools. This provides better equalization, reflection cancellation, and power budget. It introduces more advanced receiver architectures, such as maximum likelihood sequence detectors (MLSD), a mathematical algorithm to extract useful data out of a noisy data stream. It also makes adding Forward Error Correction (FEC) possible, which adds a redundant signal that allows for the automatic correction of errors. Achieving the desired link performance depends on a detailed and complicated calibration process that involves numerous parameters. The DSP and module firmware (FW) are in charge of finding those optimal settings, and use complex calibration algorithms, which was the first time the industry has deployed these.
Not only does the technology itself add to the complexity of our interconnects, but so does our desire to diversify our supply chain. Due to the large scale of our fleet and supply constraints, we found it necessary to use multiple vendors. We needed this diversity, not just at the module and system level, but for critical subcomponents such as DSPs and switch ASICs. Planning ahead with vendor redundancy meant that we were able to ensure we could deploy enough capacity to meet our customers’ needs, even when the COVID-19 pandemic exacerbated supply chain issues. But enabling a healthy supply chain makes interoperability in the network much more complex, as shown in Figure 2 where multiple vendors on switches, modules, and their critical sub-components such as DSPs and ASICs create a vast matrix of possible link configurations. The combination of both technological and interoperability complexity was a significant risk that we had to take actions to address.

Figure 2. 400 GbE link showing the complexity of maintaining the interoperability of components from multiple vendors
Defining a continuous improvement model for interconnects
Due to the increasing complexity of both the modules and their firmware, we knew that we had to approach the deployment of 400 GbE interconnects at Amazon Web Services differently than we had previously. Rather than treat these interconnects as commodities that we would simply replace upon failure, we had to improve the speed at which we could respond to the data center’s needs. This led us to establish a model that would enable a continuous improvement cycle for interconnects, as shown in Figure 3.
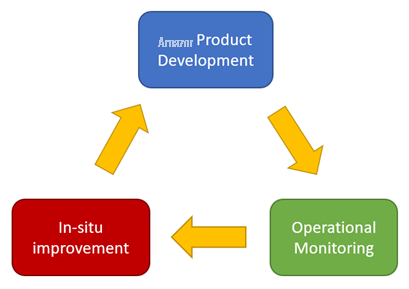
Figure 3. Interconnect lifecycle continuous improvement model
This model tracks the lifecycle of our interconnects from Amazon Web Services’s product development process with its vendors throughout those products’ operation in our network. It required us to complete several initiatives that not only enabled us to continuously reduce the failure rates of our 400 GbE interconnects by enabling in-place upgrades of the transceivers while they were still installed in our fleet, but also apply learnings from the fleet and improve our product development process.
Our first step was to take a deeper role in the product development of optical pluggables. Normally, we relied on industry standards from Institute of Electrical and Electronics Engineers (
To make sure that requirements on paper actually resulted in improved performance and quality, we could not simply stop at defining standards and had to take a leading role in the product development with our vendors. This meant not only working on component and system designs, but taking ownership in making sure the products work as we had designed it. This includes evaluating their initial prototypes in our own labs and providing direct guidance to vendors on how to improve their products. It also meant testing the long tails of the distribution of the production line against corner cases and under accelerated conditions to make sure that all products deployed to the fleet meet the requirements of our data center deployments. In order to ensure that this was scalable and long-term, we established several mechanisms to make every part that they shipped would continue to meet our standards. We added several gates to both the pre-production process and on the production line itself that allowed us to track and monitor module performance. To make sure that our testing remains as comprehensive as possible in light of changing requirements, new information from the fleet, or feedback from our vendors, we have continuously improved upon it. For example, we have added several environmental tests and more stringent test conditions that, at the time, were not covered by typical industry test methodologies. These mechanisms ensure that we catch emerging issues in the fleet early on, and enable us to adjust our product development process to respond quickly to changing requirements.
Architecting a monitoring system built on Amazon Web Services services
In order to understand whether we were improving the quality of our products by defining new specifications, we had to close the feedback loop. We needed to measure how tens of millions of modules were actually performing in the fleet. To do this, we built an operational monitoring service to track the performance of our products when deployed in our network.
We built this infrastructure with the same Amazon Web Services services that you are familiar with and communicate with through the very network of interconnects that we were monitoring. We show a simplified service diagram in Figure 4.
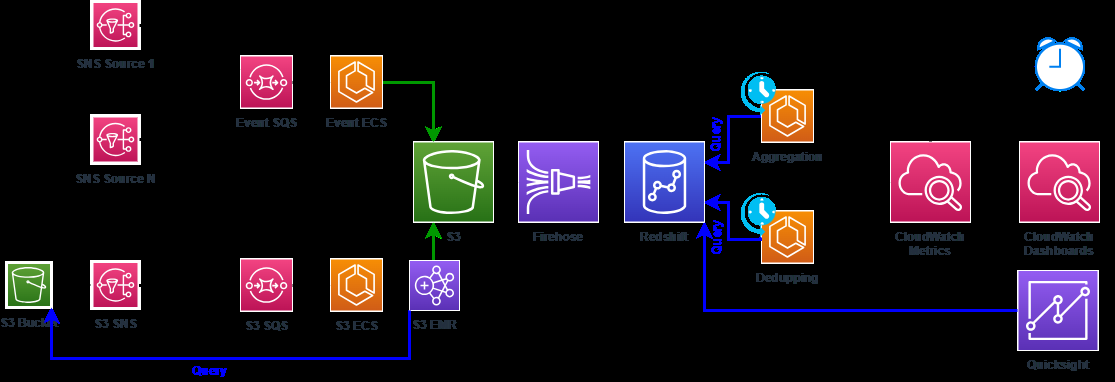
Figure 4. Interconnect monitoring service infrastructure diagram
First, we ingest Amazon
It is worth noting our internal teams use the same services as any Amazon Web Services customer. Like any other customer, we are always looking to become more efficient and operate in ways that scale. For example, we initially used
Our monitoring system made it possible for Amazon Web Services to track millions of 400 GbE interconnects during their entire lifecycle. This includes collecting, ingesting and alarming on data from: our vendors’ factories and manufacturing lines, deployment tool logs as the devices enter into our network, monitoring and remediation mechanisms that track operational performance in the fleet, and lab test results from analysis run on decommissioned devices.
Working with vendors, we raised the industry standards for measurement and data collection. This included collecting additional key performance indicators (KPIs), such as Pre-FEC BER (bit-error rate), which lets us detect signal degradation before FEC thresholds are exceeded. By acting on this metric, we prevent packet drops and errors in received data that have the potential to cause customer impact. We collaborated with our vendors to implement
Delivering improved reliability to our internal and external customers
Armed with the ability to monitor and track performance in our fleet and create a feedback loop, we now had to act on the vast amount of information we were collecting. As a result, we set a goal for in situ, or in production, improvement of our interconnects. We had to create mechanisms to improve the quality of our modules while they were operational and carrying customer traffic, as well as the ones that were still undergoing qualification or on the production line. These mechanisms include ones that are triggered when we detect specific failure modes using our newly established monitoring systems, in addition to campaigns that are pushed to production on a regular cadence throughout the fleet. When combined, these processes have helped us continuously raise the bar on interconnect quality. This was most important for the complex 400 GbE generation of interconnects that we had begun to deploy.
The efficacy of this new approach to interconnects and the tools that we created is reflected in the quality improvement that we have observed in the network. As you can see in Figure 5, there has been a 4–5x improvement in link fault rates between the 400 GbE modules that are running the latest vintage firmware compared to those that are using older versions. This large disparity shows that we were correct: the increased complexity of the 400 GbE generation of interconnects required a change in the way we do things. While link faults rarely result in actual customer impact because of the amount of redundancy that is built into the Amazon Web Services network, reducing faults is vital for maintaining the network capacity our customers require and reducing the operational burden on our network engineers.
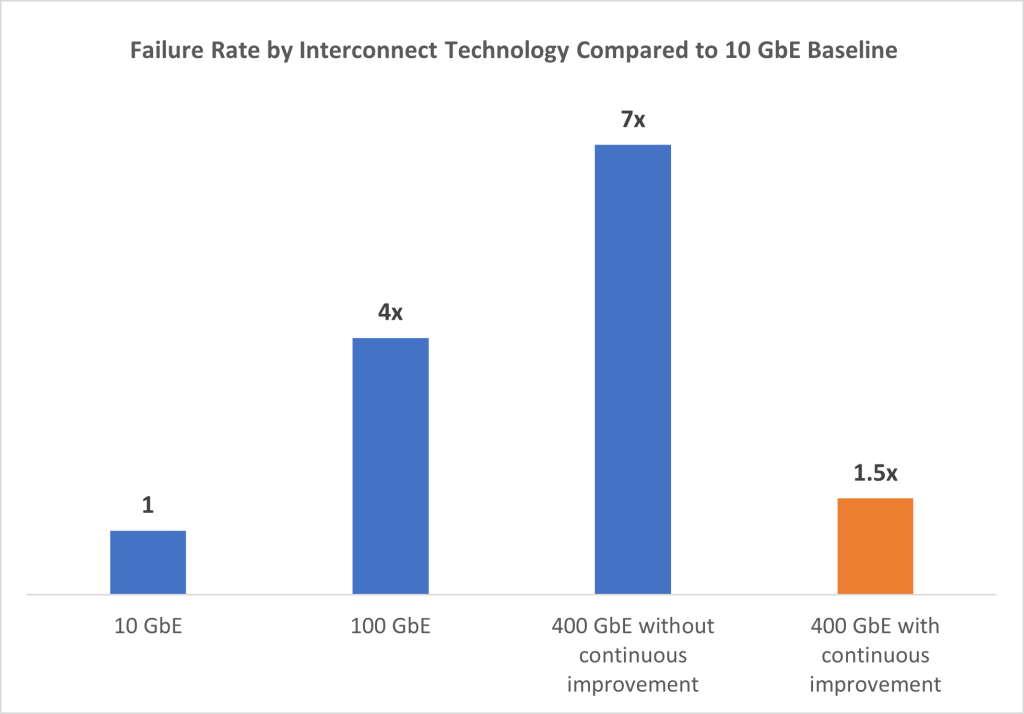
Figure 5. Comparison of interconnect link fault rate performance by technology in the Amazon Web Services fleet
At Amazon Web Services, we are proud to say that we have successfully reversed the industry-wide trend of declining performance with each generation of interconnect technology. In fact, the 400 GbE generation’s link fault rate is already lower than that of 100 GbE and is actually approaching that of 10 GbE. This is a significant achievement that was only made possible by the mechanisms and processes that we implemented that allowed us to more closely monitor and improve the reliability of our 400 GbE interconnect products. We continue to utilize and enhance these processes as we work on the next generation of 800 GbE interconnects and beyond, so that we can further increase our up-time and deliver data to our customers as quickly and error-free as possible.

Paul Yu
Paul is a Network Development Manager at Amazon Web Services. He works in the Networking Product Development organization on optical interconnects with a focus on building and maintaining the technology, tools, and systems that keeps Amazon Web Services data centers functioning.

Al Hayder
Al is a Principal Networking Development Engineer at Amazon Web Services. He works in the Networking Product Development organization and focuses on enabling cutting edge scalable networking technologies.

Poorya Saghari
Poorya is a Senior Network Development Manager at Amazon Web Services. He works in the Networking Product Development organization and focuses on driving cutting edge technologies to scale the Interconnect solutions enabling Amazon Web Services network.

Ipolitas Dunaravich
Ipolitas is a technical marketing leader for networking and security services at Amazon Web Services. With over 15 years of marketing experience and 4+ years at Amazon Web Services, Ipolitas has been responsible for launching many of the managed networking services and features that run on Amazon Web Services’ network infrastructure.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.