使用 Amazon SageMaker 训练
概述
Amazon SageMaker 提供调谐和调试模型、执行训练实验所需的一切工具,让训练机器学习(ML)模型变得轻松简单。
功能
实验管理和跟踪
机器学习是基于连续实验的迭代过程,例如尝试新的学习算法或微调算法的超参数,同时观察此类递增变化对模型性能和精度的影响。数据随着时间的推移呈爆炸式增长,因此,愈发难以跟踪最佳表现模型、观察结果、实验过程中的教训以及起初创建这些模型时的成分和配方。
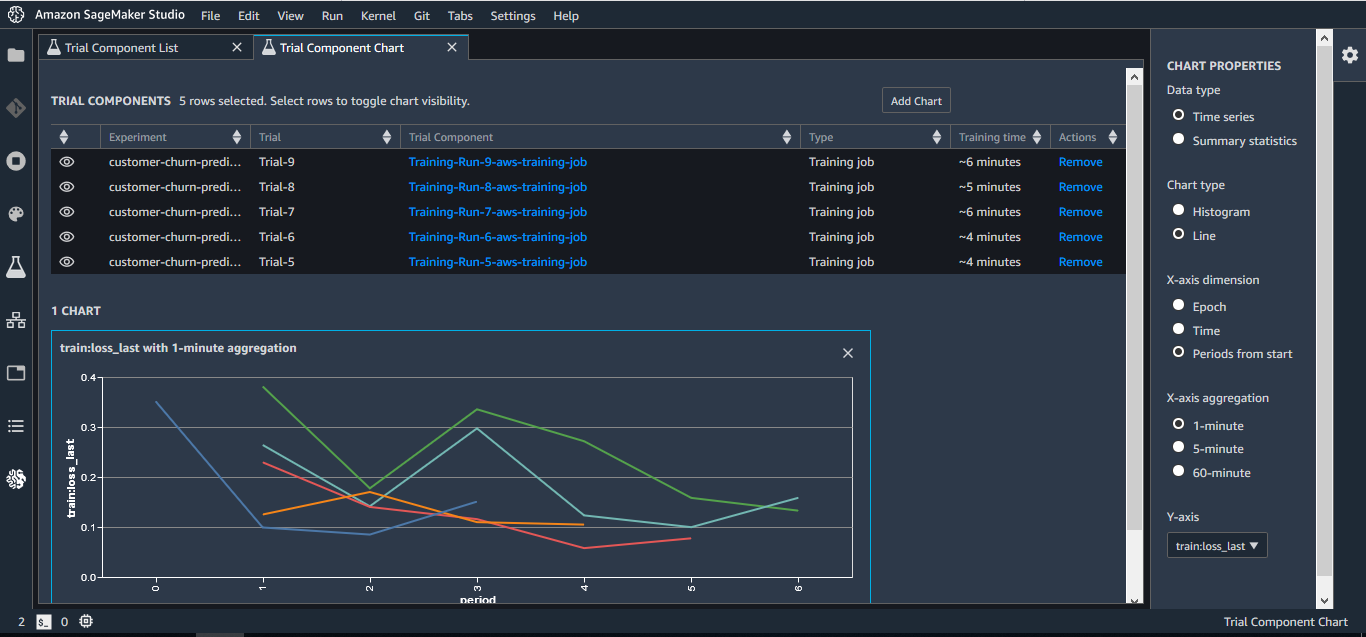
Amazon SageMaker Experiments 可帮助您以简单、可扩展的方式跟踪、评估和组织训练实验。SageMaker Experiments 是 Amazon SageMaker Studio 和 Python SDK 的附件,采用深度 Jupyter 集成。
借助 Amazon SageMaker Experiments,可组织数以千计的训练实验、记录实验构件,例如数据集、超参数和指标,同时复制实验。由于 SageMaker Experiments 与 SageMaker Studio 集成,因此能够可视化模型,快速简单地评估最佳模型。随着实验的进行,还可以记录和维护注释和备注的运行记录,轻松地在团队成员间点击共享实验。SageMaker Experiments 还会保留整个实验沿袭,如果某个模型开始背离预期结果,可返回过去时间点以检查其构件。
使用完整见解进行分析和调试
获取 ML 训练过程的完整见解和可见性很有挑战性。确保模型逐步学习正确的参数值并没有捷径。例如,使用卷积神经网络训练计算机视觉模型时,可能必须运行训练作业数小时。在此期间,无法看见不同的 ML 模型参数对模型训练有何影响,也无法了解训练过程是否会得到所需的结果。
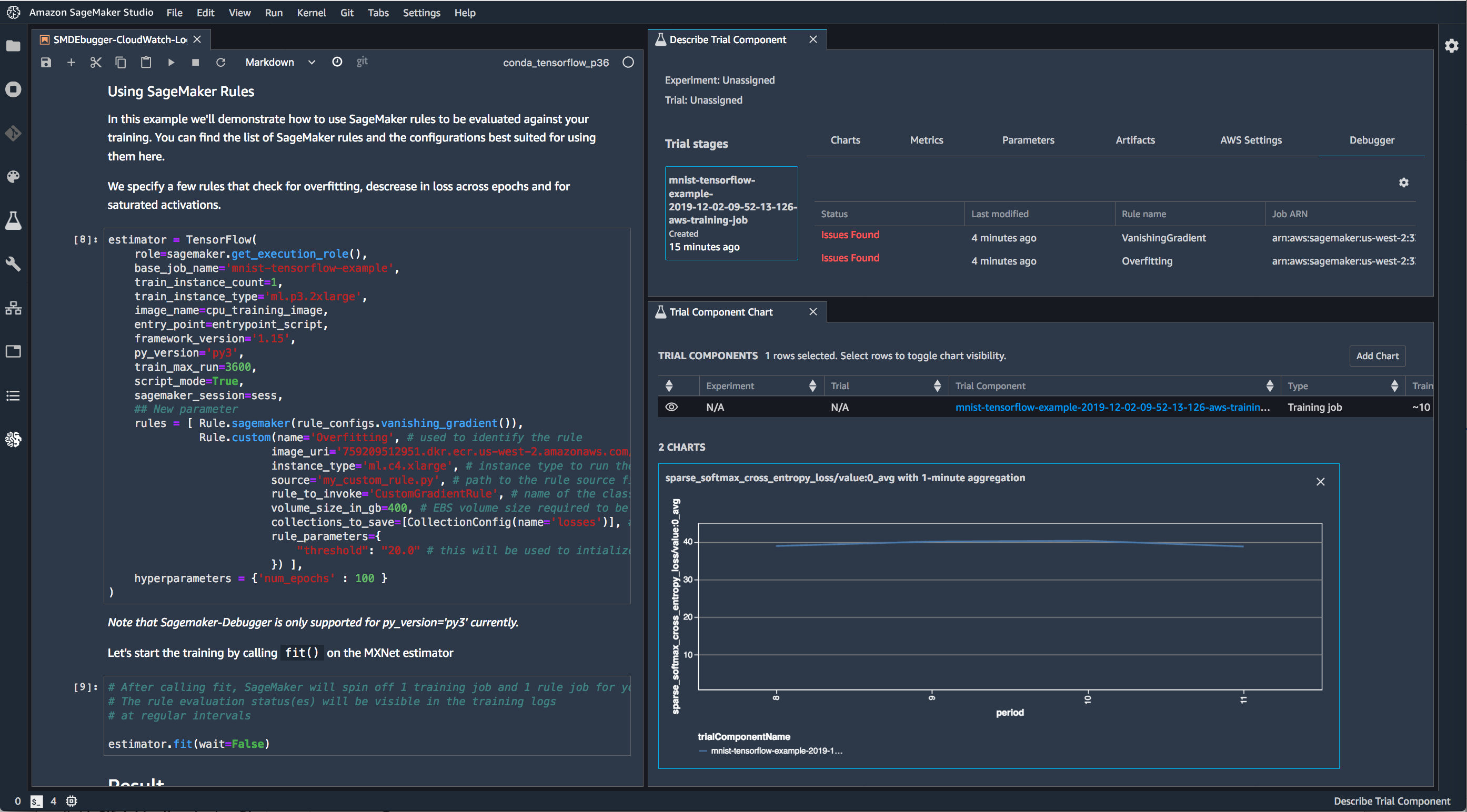
Amazon SageMaker Debugger 提供对训练过程的完整可见性。SageMaker Debugger 为开发人员提供可视界面,以分析调试数据,同时提供关于训练过程潜在异常的可视指示器,以简化检查流程。
SageMaker Debugger 会自动检测和提醒常见问题,例如梯度值过大或过小。您也可以使用 Debugger SDK 自动检测新的特定模型错误类别,或者对 SageMaker Notebook 内的训练运行进行交互式分析。这样,机器学习模型的调试工作可从数天缩短至数分钟。SageMaker Debugger 收集的数据保留在您自己的账户中,可用于对隐私最敏感的应用程序。
SageMaker Debugger 可产生模型的实时性能度量。这些度量包括训练和验证损失(代表模型错误,应尽可能低)、混淆矩阵(用于分类模型,代表假阳性和阴性预测,以及训练过程中的变化)、学习梯度(审查训练过程中的学习曲线,用于诊断学习问题,例如欠拟合或过度拟合模型,以及训练和验证数据集是否具有适当代表性) 这些度量可在 Amazon SageMaker Studio 内的笔记本中进行查看和可视化。
当检测到常见的训练问题时,SageMaker Debugger 还可以生成警告和修正建议。例如,如果您的模型已从数据充分学习而没有改进,但其仍在接受训练(耗时且昂贵),SageMaker Debugger 可以尽早识别此问题,以帮助您终止训练。它还可以识别常见数据验证问题,例如您的网络权重一直设置为零,以及识别模型是否过度拟合数据。
一键式训练
使用 Amazon SageMaker 训练模型很简单。准备在 SageMaker 中训练时,只需在 Amazon S3 中指定数据位置,指示所需 SageMaker ML 实例的类型和数量,便可点击以开始。SageMaker 会设置分布式计算集群,执行训练,将结果输出至 Amazon S3,完成后拆分集群。
在 Amazon S3 中指定数据位置后,SageMaker 会提取算法,并对隔离在自身软件定义网络(根据需要进行配置)中的训练集群运行算法。选择实例类型后,包括云端最强大的基于 GPU 的实例 Amazon EC2 P3dn,SageMaker 会在自动扩展组中创建集群。SageMaker 还会将 EBS 卷附加到每个节点,设置数据管道,开始使用 TensorFlow、MXNet、Pytorch、Chainer 或框架脚本、内置或自定义算法进行训练。结束后,结果会存储在 S3 中,集群自动拆分。
为简化大规模训练,我们已优化 Amazon S3 的训练数据传送方式。通过 API,可以指定是否要将所有数据发送到集群内的每个节点,或者是否要让 SageMaker 根据算法需求管理节点间的数据分布。结合内置算法,Amazon SageMaker 提供的训练可扩展性可大幅减少训练运行的时间和成本。
Automatic Model Tuning
Amazon SageMaker 可通过调整算法参数的数千个不同组合自动调谐模型,最大限度地实现模型精确预测。
调谐模型以提高精确度时,有两种杠杆可用,一是修改为模型提供的数据输入(例如取数值对数),二是调整定义模型行为的参数。这些参数称为超参数,找到适当的值可能很难。通常需要先随机查找,通过调整迭代,同时观察变化的影响。这一周期可能很长,取决于模型有多少超参数。
SageMaker 在训练过程中提供 Automatic Model Tuning,可简化这一流程。自动模型调谐使用机器学习以快速调谐模型,最大限度地提高精确度。该功能避免手动调整超参数的冗长试错过程。自动模型调谐通过发现数据中的有趣特征,以及学习这些特征对精度的互动影响,在多个训练运行中执行超参数优化。这样可以节省数天甚至数周的时间,以最大限度地提高训练模型的质量。
只需通过 API 或控制台指定训练作业数量,SageMaker 即可使用机器学习调谐模型,完成剩余工作。它会学习不同类型数据对模型的影响,将这一知识应用于不同的模型副本,快速找到最佳结果。对于开发人员或数据科学家,这意味着您只需关注如何调整输入模型的数据,显著减少训练过程中的干扰。
Managed Spot Training
使用 Managed Spot Training,机器学习模型的训练成本可减少多达 90%。Managed Spot Training 使用 Amazon EC2 Spot 实例,即闲置的 EC2 容量,与 Amazon EC2 按需实例相比,这大幅降低训练作业成本。Amazon SageMaker 会管理训练作业,使其在计算容量可用时运行。这样可避免您不断轮询容量,而且 Managed Spot Training 也无需构建额外工具用于管理中断。Managed Spot Training 可搭配自动模型调谐、Amazon SageMaker 内置算法和框架以及自定义算法使用。