亚马逊 OpenSear
ch S ervice 是一项托管服务,可以轻松地在 亚马逊云科技 云中大规模保护、部署和操作 OpenSearch 和传统弹性搜索集群。Amazon OpenSearch Service 为您的集群预置所有资源,启动集群,并自动检测和替换故障节点,从而减少自我管理基础设施的开销。该服务提供最新版本的 OpenSearch、对 19 个版本的 Elasticsearch(1.5 至 7.10 版本)的支持以及由 OpenSearch 控制面板和 Kibana(1.5 至 7.10 版本)提供支持的可视化功能,使您可以轻松地进行交互式日志分析、实时应用程序监控、网站搜索等。亚马逊 OpenSearch Service 现在提供无服务器部署选项(公共预览版),可以更轻松地在 亚马逊云科技 云中使用 OpenSearch。
OpenSearch 的典型工作流程是将
文档
(作为 JSON 数据)存储在索引中,然后执行
搜索
(也是 JSON)来查找这些文档。
渗透法 逆转了这种情况。
您使用
文档
存储
搜索
和查询 。假设我在芝加哥寻找一套价格低于50万的房子。我可以每天访问该网站进行查询。一个聪明的网站将能够存储我的需求(查询),并在出现符合我要求的新内容(文档)时通知我。渗透是 OpenSearch 的一项功能,它使网站能够存储这些查询并针对它们运行文档以查找新的匹配项。
在这篇文章中,我们将探讨如何使用渗滤器从新房源中找到匹配的房屋。
在详细介绍渗滤器之前,让我们先探讨一下搜索的工作原理。当你插入文档时,OpenSearch 会维护一个名为 “
倒排索引
” 的内部数据结构,它可以加快搜索速度。
索引和搜索:
让我们以上面的房地产应用程序为例,该应用程序具有房屋类型、城市和价格的简单架构。
-
首先,让我们创建一个带有映射的索引,如下所示
PUT realestate
{
"mappings": {
"properties": {
"house_type": { "type": "keyword"},
"city": { "type": "keyword" },
"price": { "type": "long" }
}
}
}
-
让我们在索引中插入一些文档。
|
ID
|
House_type
|
City
|
Price
|
|
1
|
townhouse
|
Chicago
|
650000
|
|
2
|
house
|
Washington
|
420000
|
|
3
|
condo
|
Chicago
|
580000
|
POST realestate/_bulk
{ "index" : { "_id": "1" } }
{ "house_type" : "townhouse", "city" : "Chicago", "price": 650000 }
{ "index" : { "_id": "2" } }
{ "house_type" : "house", "city" : "Washington", "price": 420000 }
{ "index" : { "_id": "3"} }
{ "house_type" : "condo", "city" : "Chicago", "price": 580000 }
-
由于我们在芝加哥没有价格低于50万的联排别墅,因此以下查询未返回任何结果。
GET realestate/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "city": "Chicago" } },
{ "term": { "house_type": "townhouse" } },
{ "range": { "price": { "lte": 500000 } } }
]
}
}
}
如果你想知道高级搜索是如何运作的,你可以参考这
篇文章
。
渗透:
如果您的一位客户希望在芝加哥有联排别墅可用且上市价格低于500,000美元时收到通知,则可以将他们的要求作为查询存储在渗滤器索引中。当有新的列表可用时,您可以使用 _percolate 查询根据渗滤器索引运行该列表。该查询将返回该新列表的所有匹配项(每个匹配项是来自一个用户的一组要求)。然后,您可以通知每位用户有符合他们要求的新列表可用。在 OpenSearch 中,此过程称为渗透。
OpenSearch 有一种名为 “
渗透器
” 的专用数据类型,允许您存储查询。
让我们创建一个具有相同映射的 percolator 索引,其中包含用于查询的附加字段和可选元数据。确保包括存储查询中的所有必需字段。在本例中,除了实际字段和查询外,我们还捕获了customer_id和发送通知的优先级。
PUT realestate-percolator-queries
{
"mappings": {
"properties": {
"user": {
"properties": {
"query": { "type": "percolator" },
"id": { "type": "keyword" },
"priority":{ "type": "keyword" }
}
},
"house_type": {"type": "keyword"},
"city": {"type": "keyword"},
"price": {"type": "long"}
}
}
}
创建索引后,插入如下查询
POST realestate-percolator-queries/_doc/chicago-house-alert-500k
{
"user" : {
"id": "CUST101",
"priority": "high",
"query": {
"bool": {
"filter": [
{ "term": { "city": "Chicago" } },
{ "term": { "house_type": "townhouse" } },
{ "range": { "price": { "lte": 500000 } } }
]
}
}
}
}
当针对存储的查询运行新文档时,渗透就开始了。
{"city": "Chicago", "house_type": "townhouse", "price": 350000}
{"city": "Dallas", "house_type": "house", "price": 500000}
使用文档运行渗透查询,它与存储的查询相匹配
GET realestate-percolator-queries/_search
{
"query": {
"percolate": {
"field": "user.query",
"documents": [
{"city": "Chicago", "house_type": "townhouse", "price": 350000 },
{"city": "Dallas", "house_type": "house", "price": 500000}
]
}
}
}
上面的查询返回查询以及我们存储的与文档相匹配的元数据(在本例中为customer_id)
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "realestate-percolator-queries",
"_id" : "chicago-house-alert-500k",
"_score" : 0.0,
"_source" : {
"user" : {
"id" : "CUST101",
"priority" : "high",
"query" : {
"bool" : {
"filter" : [
{ "term" : { "city" : "Chicago" } },
{ "term" : { "house_type" : "townhouse" } },
{ "range" : { "price" : { "lte" : 500000 } } }
]
}
}
}
},
"fields" : {
"_percolator_document_slot" : [0]
}
}
]
}
}
大规模渗透
当渗透器索引中存储了大量查询时,在索引中搜索查询可能会效率低下。您可以考虑对查询进行细分,并将其用作过滤器,以有效地处理大量查询。由于我们已经捕获了优先级,因此您现在可以使用优先级过滤器运行渗透,从而缩小匹配查询的范围。
GET realestate-percolator-queries/_search
{
"query": {
"bool": {
"must": [
{
"percolate": {
"field": "user.query",
"documents": [
{ "city": "Chicago", "house_type": "townhouse", "price": 35000 },
{ "city": "Dallas", "house_type": "house", "price": 500000 }
]
}
}
],
"filter": [
{ "term": { "user.priority": "high" } }
]
}
}
}
最佳实践
-
最好将渗透索引与文档索引分开。不同的索引配置,例如渗透索引上的分片数量,可以独立调整以提高性能。
-
最好使用查询过滤器来减少从渗透索引中渗出的匹配查询。
-
考虑在采集管道中使用缓冲区,原因如下:
-
您可以根据工作负载和 SLA 单独批量提取和渗透。 您可以通过在非工作时间运行渗透来
-
确定采集和搜索流量的优先级。确保缓冲层中有足够的存储空间。
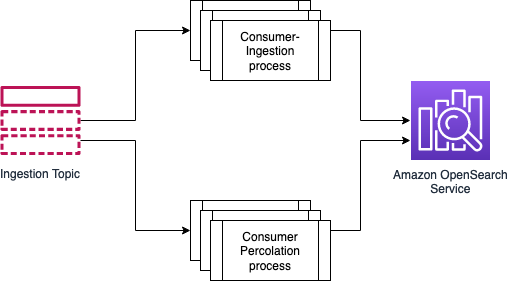
-
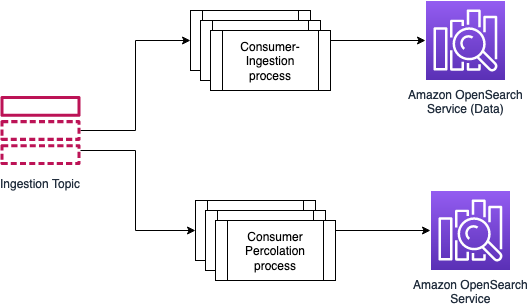
出于以下原因,考虑使用独立集群进行渗透,
-
-
渗透过程依赖于内存和计算,您的主要搜索不会受到影响。
-
您可以灵活地独立扩展集群。
结论
在这篇文章中,我们介绍了 OpenSearch 中渗透是如何工作的,以及如何大规模有效地使用。渗透在 OpenSearch 的托管版本和无服务器版本中均可使用。您可以按照
最佳做法
分析和排列索引中的数据,因为这对于快速的搜索性能很重要。
如果您对这篇文章有反馈,请在评论部分提交您的评论。
作者简介
 阿伦·拉克什曼南
是位于伊利诺伊州芝加哥的亚马逊 OpenSearch Service 的搜索专家。他在与企业客户和初创公司合作方面拥有 20 多年的经验。他喜欢旅行,喜欢与家人共度美好时光。
阿伦·拉克什曼南
是位于伊利诺伊州芝加哥的亚马逊 OpenSearch Service 的搜索专家。他在与企业客户和初创公司合作方面拥有 20 多年的经验。他喜欢旅行,喜欢与家人共度美好时光。