我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
用于自动语音识别的耳语模型现已在亚马逊 SageMaker JumpStart 中推出
今天,我们很高兴地宣布,OpenAI Whisper基础模型可供使用亚马逊S
您也可以使用
在这篇文章中,我们将向您展示如何部署
OpenAI Whisper 模型使用 h
SageMaker 中的基础模型
SageMaker JumpStart 允许访问来自热门模型中心的一系列模型,包括 Hugging Face、PyTorch Hub 和 TensorFlow Hub,你可以在 SageMaker 的机器学习开发工作流程中使用这些模型。机器学习的最新进展催生了一类新的模型,即 基础模型 ,这些模型通常根据数十亿个参数进行训练,可以适应各种用例,例如文本摘要、生成数字艺术和语言翻译。由于这些模型的训练成本很高,因此客户希望使用现有的预训练基础模型并根据需要对其进行微调,而不是自己训练这些模型。SageMaker 提供了精选的模型列表,您可以在 SageMaker 控制台上从中进行选择。
现在,您可以在 SageMaker JumpStart 中找到来自不同模型提供商的基础模型,从而使您能够快速开始使用基础模型。SageMaker JumpStart 提供基于不同任务或模型提供者的基础模型,您可以轻松查看模型特征和使用条款。你也可以使用测试界面控件来尝试这些模型。当你想大规模使用基础模型时,你可以在不离开 SageMaker 的情况下使用模型提供商提供的预建笔记本电脑。由于模型在 亚马逊云科技 上托管和部署,因此您相信您的数据,无论是用于评估还是大规模使用模型,都不会与第三方共享。
OpenAI Whisper 基础模型
Whisper 是用于 ASR 和语音翻译的预训练模型。Whisper 是亚历克·拉德福德等人在 OpenAI 的
Whisper 是基于变压器的编码器-解码器模型,也称为序列到序列模型。 它接受了使用大规模薄弱监督进行注释的680,000小时的带标签语音数据的培训。Whisper 模型显示出无需微调即可推广到许多数据集和域的强大能力。
这些模型是根据纯英语数据或多语言数据进行训练的。仅限英语的模型接受了语音识别任务方面的训练。多语言模型接受了语音识别和语音翻译方面的训练。对于语音识别,该模型预测使用与音频 相同的 语言进行的转录。对于语音翻译,该模型预测转录为 与音频不同的 语言。
Whisper 检查点有五种不同模型大小的配置。最小的四个人使用纯英语或多语言数据进行训练。最大的检查站仅使用多种语言。所有十个预先训练的检查点都在
| Model name | Number of parameters | Multilingual |
| whisper-tiny | 39 M |
|
| whisper-base | 74 M |
|
| whisper-small | 244 M |
|
| whisper-medium | 769 M |
|
| whisper-large | 1550 M |
|
| whisper-large-v2 | 1550 M |
|
让我们来探讨如何在 SageMaker JumpStart 中使用 Whisper 模型。
OpenAI Whisper 基础模型 WER 和延迟对比
下表显示了基于 Li
| Model | WER (percent) |
| whisper-tiny | 7.54 |
| whisper-base | 5.08 |
| whisper-small | 3.43 |
| whisper-medium | 2.9 |
| whisper-large | 3 |
| whisper-large-v2 | 3 |
在这篇博客中,我们提取了下面的音频文件,比较了不同耳语模型的语音识别延迟。延迟是指从用户发送请求到您的应用程序表明请求已完成的时间。下表中的数字表示使用与 ml.g5.2xlarge 实例上托管的模型相同的音频文件的总计 100 个请求的平均延迟。
| Model | Average latency(s) | Model output |
| whisper-tiny | 0.43 | We are living in very exciting times with machine lighting. The speed of ML model development will really actually increase. But you won’t get to that end state that we won in the next coming years. Unless we actually make these models more accessible to everybody. |
| whisper-base | 0.49 | We are living in very exciting times with machine learning. The speed of ML model development will really actually increase. But you won’t get to that end state that we won in the next coming years. Unless we actually make these models more accessible to everybody. |
| whisper-small | 0.84 | We are living in very exciting times with machine learning. The speed of ML model development will really actually increase. But you won’t get to that end state that we want in the next coming years unless we actually make these models more accessible to everybody. |
| whisper-medium | 1.5 | We are living in very exciting times with machine learning. The speed of ML model development will really actually increase. But you won’t get to that end state that we want in the next coming years unless we actually make these models more accessible to everybody. |
| whisper-large | 1.96 | We are living in very exciting times with machine learning. The speed of ML model development will really actually increase. But you won’t get to that end state that we want in the next coming years unless we actually make these models more accessible to everybody. |
| whisper-large-v2 | 1.98 | We are living in very exciting times with machine learning. The speed of ML model development will really actually increase. But you won’t get to that end state that we want in the next coming years unless we actually make these models more accessible to everybody. |
解决方案演练
你可以使用亚马逊 SageMaker 主机或亚马逊 SageMaker 笔记本来部署 Whisper 模型。在这篇文章中,我们将演示如何使用 SageMaker Studio 控制台或 SageMaker 笔记本部署 Whisper API,然后使用部署的模型进行语音识别和语言翻译。这篇文章中使用的代码可以在
让我们详细扩展每个步骤。
从控制台部署 Whisper
- 要开始使用 SageMaker JumpStart,请打开亚马逊 SageMaker Studio 主机,前往 SageMaker JumpStart 的启动页面,然后选择 JumpStart 入门。
-
要选择 Whisper 模型,你可以使用顶部的选项卡,也可以使用右上角的搜索框,如以下屏幕截图所示。在此示例中,使用右上角的搜索框输入
Whisper,然后从下拉菜单中选择相应的 Whisper 模型。
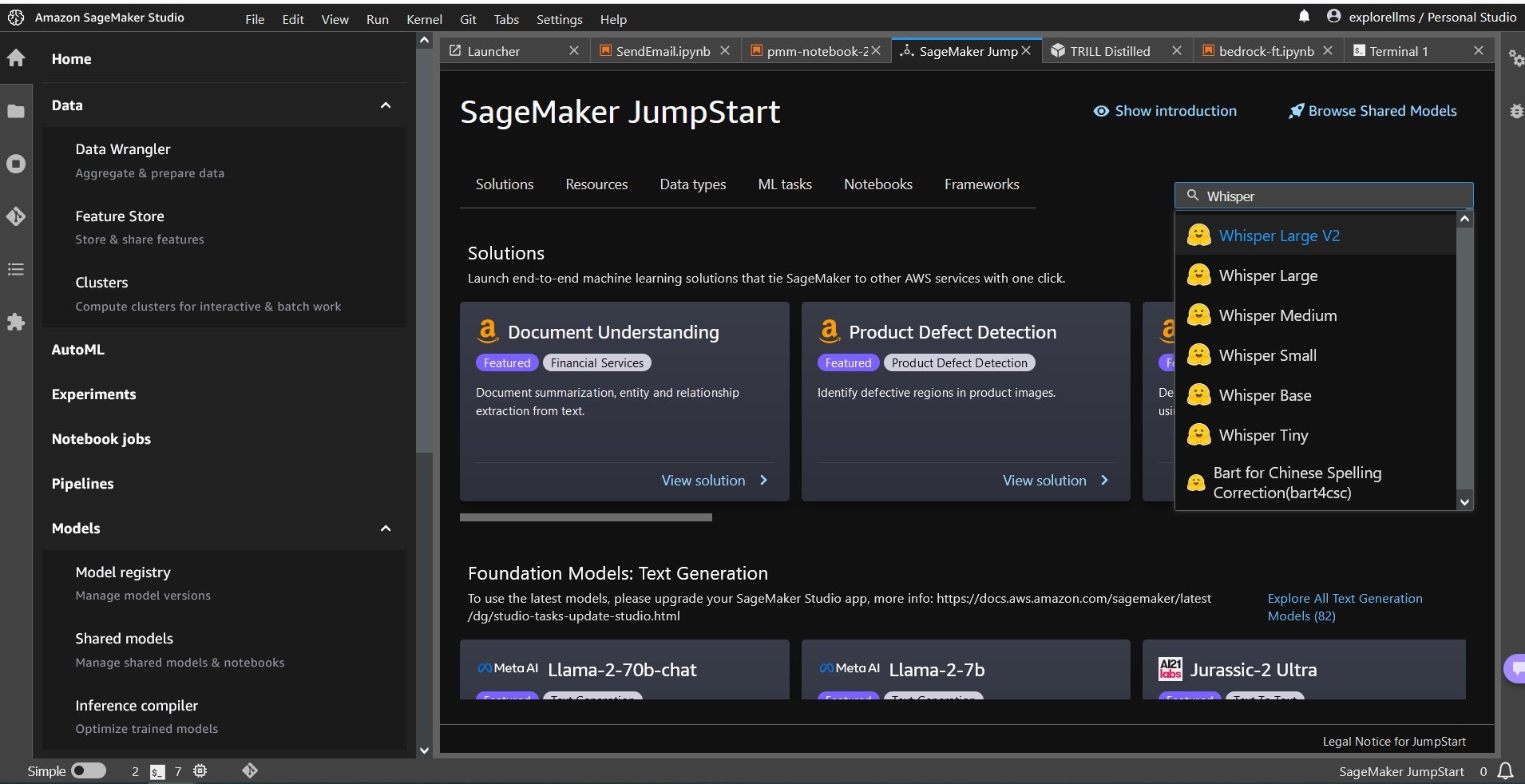
-
选择 Whisper 模型后,您可以使用控制台部署该模型。您可以选择要部署的实例,也可以使用默认实例。
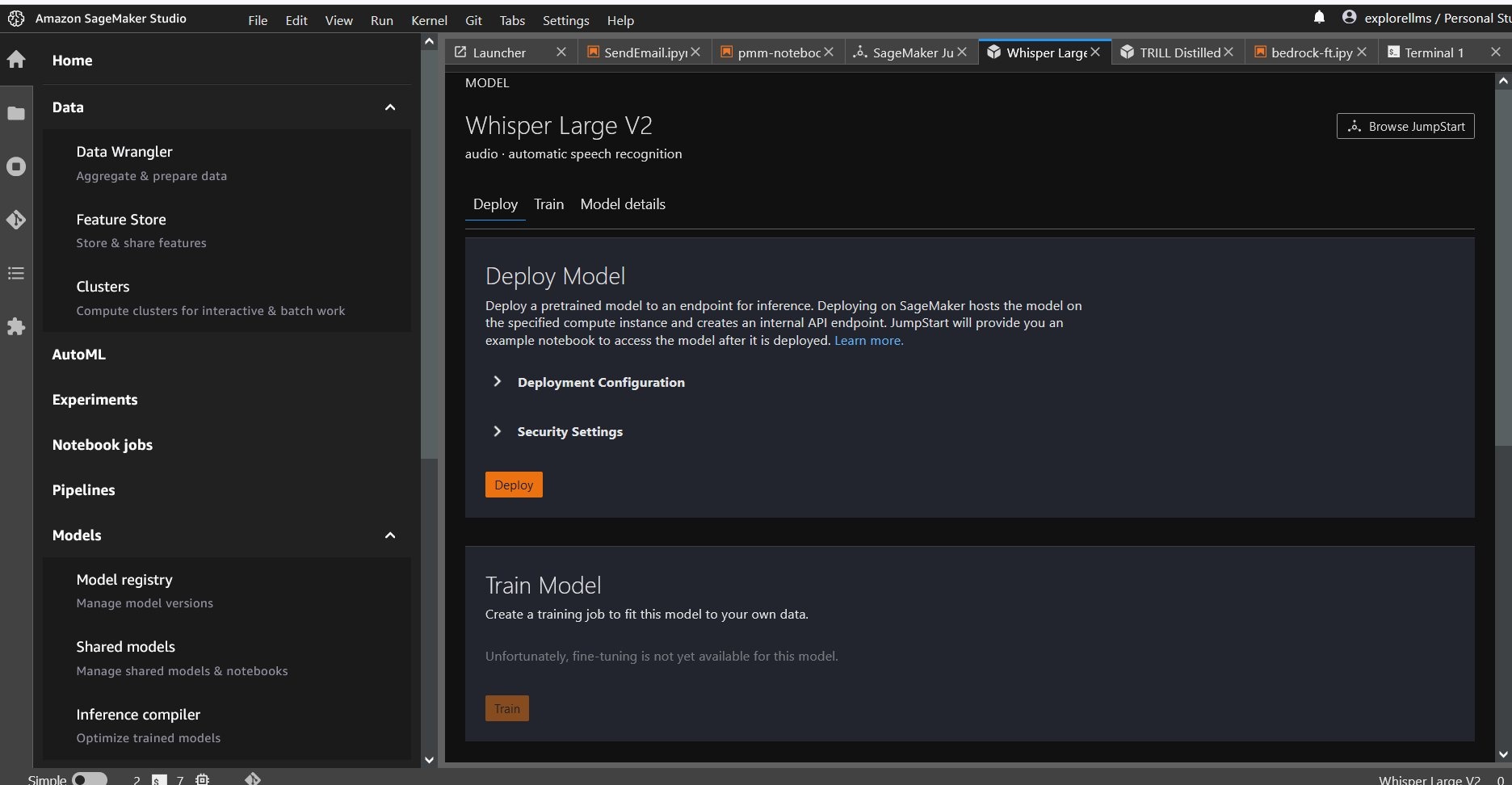
从 Sagemaker 笔记本中部署基础模型
首先部署然后使用已部署的模型来解决不同任务的步骤是:
- 设置
- 选择一个型号
- 检索工件并部署端点
- 使用已部署的模型进行 ASR
- 使用已部署的模型进行语言翻译
- 清理端点
设置
这款笔记本电脑在 SageMaker Studio 中使用 Python 3(数据科学)内核的 ml.t3.medium 实例和带有 conda_python3 内核的亚马逊 SageMaker Notebook 实例上进行了测试。
选择预训练的模型
使用 Boto3 设置 SageMaker 会话,然后选择要部署的模型 ID。
检索工件并部署端点
使用 SageMaker,您可以对预训练的模型进行推断,即使无需先在新数据集上对其进行微调。要托管预训练模型,请创建
ml.g5.2xlarge 作为超大 v2 模型
的推理端点。
您可以通过在 JumpStartModel 类中传递
部署可能需要几分钟。
instance_type 来将模型部署到 其他实例类型
上。
自动语音识别
接下来,你从 SageMaker Jumpstart 的
该模型在执行推理时支持许多参数。它们包括:
-
max_len gth:模型生成文本直到输出长度。如果指定,则它必须是正整数。 - 语言和任务:在此处指定输出语言和任务。该模型支持转录或翻译任务。
-
max_new_tokens :要生成的最大代币数。 -
n@@
um_return_sequences :返回的输出序列的数量。如果指定,则它必须是正整数。 -
num_beams :贪婪搜索中使用的光束数量。如果指定,则它必须是大于或等于 num_return_sequences 的整数。 -
no_repeat_ngram_size :该模型确保输出序列中不重复no_repeat_ngram_size 的单词序列。如果指定,则它必须是大于 1 的正整数。 - 温度:这控制输出中的随机性。较高的温度会生成包含低概率字的输出序列,而较低的温度会生成包含高概率字的输出序列。如果温度接近 0,则会导致解码失败。如果指定,则它必须是正浮点数。
-
e@@
arly_stoping:如果为 True,则当所有光束假设到达句子标记的末尾时,文本生成即告完成。如果指定,则它必须是布尔值。 -
do_sample:如果为 True,则对下一个单词进行抽样以得出可能性。如果指定,则必须为布尔值。 -
top_k:在文本生成的每个步骤中,仅从top_k最有可能的单词中抽样。如果指定,则它必须是正整数。 -
top_p:在文本生成的每个步骤中,从尽可能小的单词集中抽样,累积概率 为 top_p。如果指定,则它必须是介于 0 和 1 之间的浮点数。
调用端点时,您可以指定前面参数的任意子集。接下来,我们向您展示如何使用这些参数调用端点的示例。
语言翻译
要使用 Whisper 模型展示语言翻译,请使用以下法语音频文件并将其翻译成英语。必须以 16 kHz 的频率对文件进行采样(按照 ASR 模型的要求),因此请务必根据需要对文件进行重新采样,并确保样本不超过 30 秒。
-
从 SageMaker JumpStart 的 S3 公共位置下载
sample_french1.wav,这样 Whisper 模型就可以将其传入有效负载进行翻译。
-
将任务参数设置为
翻译 并将语言设置为法语, 以强制 Whisper 模型执行语音翻译。 - 使用 预测器 来预测语言的翻译。如果您收到客户端错误(错误 413),请检查端点的有效负载大小。SageMaker 调用端点请求的有效负载限制为大约 5 MB。
- 从法语音频文件翻译成英语的文本输出如下:
清理
测试完端点后,删除 SageMaker 推理端点并删除模型以避免产生费用。
结论
在这篇文章中,我们向您展示了如何使用亚马逊 SageMaker 测试和使用 OpenAI Whisper 模型来构建有趣的应用程序。立即在 SageMaker 中试用基础模型,并告诉我们您的反馈!
本指南仅供参考。您仍应自行进行独立评估并采取措施确保遵守自己的特定质量控制措施和标准,以及适用于您、您的内容和本指南中提及的第三方模式的当地法规、法律、法规、许可和使用条款。亚马逊云科技 对本指南中提及的第三方模型没有控制权或权限,也不对第三方模型安全、无病毒、可操作或与您的生产环境和标准兼容做出任何陈述或保证。亚马逊云科技 不对本指南中的任何信息将产生特定的结果或结果作出任何陈述、担保或保证。
作者简介
 Hemant Singh
是一位应用科学家,拥有亚马逊 SageMaker JumpStart 方面的经验。他从库兰特数学科学研究所获得硕士学位,在印度理工学院德里分校获得理学学士学位。他在处理自然语言处理、计算机视觉和时间序列分析领域的各种机器学习问题方面拥有经验。
Hemant Singh
是一位应用科学家,拥有亚马逊 SageMaker JumpStart 方面的经验。他从库兰特数学科学研究所获得硕士学位,在印度理工学院德里分校获得理学学士学位。他在处理自然语言处理、计算机视觉和时间序列分析领域的各种机器学习问题方面拥有经验。
 Rachna Chadha
是 亚马逊云科技 战略账户领域首席解决方案架构师 AI/ML。拉赫纳是一位乐观主义者,他相信以合乎道德和负责任的方式使用人工智能可以改善未来的社会,带来经济和社会繁荣。在业余时间,Rachna 喜欢与家人共度时光、远足和听音乐。
Rachna Chadha
是 亚马逊云科技 战略账户领域首席解决方案架构师 AI/ML。拉赫纳是一位乐观主义者,他相信以合乎道德和负责任的方式使用人工智能可以改善未来的社会,带来经济和社会繁荣。在业余时间,Rachna 喜欢与家人共度时光、远足和听音乐。
 Ashish Khetan 博士
是一位高级应用科学家,拥有亚马逊 SageMaker 内置算法,并帮助开发机器学习算法。他在伊利诺伊大学厄巴纳-香槟分校获得博士学位。他是机器学习和统计推理领域的活跃研究人员,曾在Neurips、ICML、ICLR、JMLR、ACL和EMNLP会议上发表过许多论文。
Ashish Khetan 博士
是一位高级应用科学家,拥有亚马逊 SageMaker 内置算法,并帮助开发机器学习算法。他在伊利诺伊大学厄巴纳-香槟分校获得博士学位。他是机器学习和统计推理领域的活跃研究人员,曾在Neurips、ICML、ICLR、JMLR、ACL和EMNLP会议上发表过许多论文。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。