客户正在将其任务关键型传统本地
IBM Db2 for z/OS 数据库更新为适用于
PostgreSQL 的
亚马逊关系数据库服务 (Amazon RDS) 或 兼容 Amazon A urora PostgreSQL
的 版本,以实现其可扩展性、性能、敏
捷性和可用性。
你可以使用
亚马逊云科技 架构转换工具 (亚马逊云科技
SCT) 来简化从 db2 for z/OS 到适用于 PostgreSQL 的亚马逊 RDS 或亚马逊 Aurora PostgreSQL 兼容版的架构转换。有关使用适用于 Db2 z/OS 的 亚马逊云科技 SCT 作为源转换架构对象的详细信息,请参阅
亚马逊云科技 SCT 现在支持 IBM DB2 for z/OS
作为源。 使用 亚马逊云科技 SCT 转换架构对象后,您可以使用
亚马逊云科技 数据库迁移服务
(亚马逊云科技 DMS) 迁移数据。由于架构迁移是一个半自动过程,因此有时当对象未完全转换或关键对象功能不匹配时,它可能仍需要手动转换。
在这篇文章中,我们将向您介绍如何验证从 Db2 for z/OS 迁移到适用于 PostgreSQL 的亚马逊 RDS 或亚马逊 Aurora PostgreSQL 兼容版的数据库架构对象。另一篇文章 将介绍适用于 z/OS 的 Db2 与适用于
MySQL 的 亚马逊 RDS
或
亚马逊 A urora MySQL 兼容版
之间的类似验证。
要验证的对象
作为最佳实践,您应该在成功地从 Db2 for z/OS 转换数据库架构对象后执行架构验证,并使用 亚马逊云科技 SCT 在 PostgreSQL 中部署转换后的架构对象。迁移后的架构验证决定了整体迁移的成功因素。
在以下部分中,我们将详细介绍以下每种数据库架构对象类型的验证方案,以确保每种对象类型的对象数量在源数据库和目标数据库之间保持一致。这些验证场景不涵盖或探讨迁移的转换精度,而是直接验证迁移的数据库对象。
-
架构
-
桌子
-
观点
-
主键
-
外键
-
索引
-
物化查询表
-
用户定义的数据类型
-
触发器
-
序列
-
程序
-
函数
架构
架构
代表在应用程序或微服务中提供相关功能的数据库对象的集合。您可以使用以下 SQL 查询验证源数据库和目标数据库中的架构:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT DISTINCT CREATOR AS SCHEMA_NAME
FROM SYSIBM.SYSTABLES
WHERE CREATOR NOT LIKE 'SYS%'
ORDER BY SCHEMA_NAME;
|
SELECT SCHEMA_NAME, SCHEMA_OWNER
FROM INFORMATION_SCHEMA.SCHEMATA
WHERE SCHEMA_NAME NOT IN ('pg_catalog',
'information_schema',
'aws_db2zos_ext','public')
AND SCHEMA_NAME NOT LIKE 'pg_temp%'
AND SCHEMA_NAME NOT LIKE 'pg_toast%'
ORDER BY SCHEMA_NAME;
|
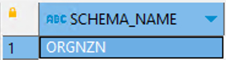
|

|
当您将 Db2 转换为 z/OS 架构时,亚马逊云科技 SCT 会向您的目标数据库添加一个额外的架构 (aws_db2zos_ext)。这些架构实现了 Db2 for z/OS 数据库的 SQL 系统函数,这些函数是将转换后的架构写入 Aurora PostgreSQL 数据库时所必需的。这些额外的架构被称为
亚马逊云科技 SCT 扩展包
。
在 Db2 for z/OS 和 PostgreSQL(pg_catalog、information_schema、public)中,我们排除了与系统表或目录表(SYS%)相关的架构。
验证源数据库和目标数据库中的架构数量是否匹配。如果发现任何差异,请查看
亚马逊云科技 SCT 日志
以确定失败原因或手动创建。
桌子
亚马逊云科技 SCT 将 z/OS 表的源 Db2 转换为等效的目标表 (PostgreSQL)。如果需要,我们可以使用自定义
映射规则
在迁移中包含或排除特定的表。以下脚本返回所有表的计数和详细级别信息:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT TAB.CREATOR AS SCHEMA_NAME,
COUNT(TAB.NAME) AS TABLE_COUNT
FROM SYSIBM.SYSTABLES TAB
WHERE TAB.TYPE = 'T'
AND TAB.CREATOR NOT LIKE 'SYS%'
GROUP BY TAB.CREATOR
ORDER BY TAB.CREATOR;
|
SELECT NSPNAME as schema_name,
count(RELNAME) as table_count
FROM PG_CLASS C
LEFT JOIN PG_NAMESPACE N
ON N.OID = C.RELNAMESPACE
WHERE C.RELKIND in (‘r’)
AND N.NSPNAME
not in
('pg_catalog',
'information_schema',
'aws_db2zos_ext','public')
group by NSPNAME
ORDER BY NSPNAME;
|

|

|
有关详细级别的信息,请使用以下查询:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT TAB.CREATOR AS SCHEMA_NAME,
TAB.NAME AS TABLE_NAME
FROM SYSIBM.SYSTABLES TAB
WHERE TAB.TYPE = 'T'
AND TAB.CREATOR NOT LIKE 'SYS%'
ORDER BY TAB.CREATOR,TAB.NAME;
|
SELECT NSPNAME as schema_name,
RELNAME as table_name
FROM PG_CLASS C
LEFT JOIN PG_NAMESPACE N
ON N.OID = C.RELNAMESPACE
WHERE C.RELKIND in (‘r’)
AND N.NSPNAME
not in ('pg_catalog',
'information_schema',
'aws_db2zos_ext',
'public')
order by NSPNAME,RELNAME;
|
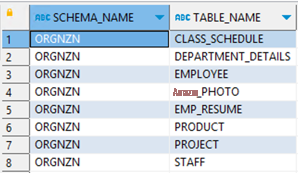
|
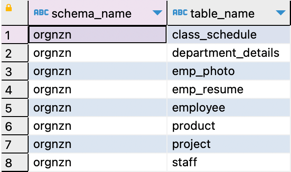
|
验证源数据库和目标数据库的结果。如果您发现任何差异,请从 亚马逊云科技 SCT 或手动日志中找出原因,然后在修复问题后重新运行失败的语句。
观点
您可以使用对源数据库和目标数据库的以下查询来验证 亚马逊云科技 SCT 转换的视图数:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT TAB.CREATOR AS SCHEMA_NAME,
COUNT(TAB.NAME) AS VIEW_COUNT
FROM SYSIBM.SYSTABLES TAB
WHERE TAB.TYPE = 'V'
AND TAB.CREATOR NOT LIKE 'SYS%'
GROUP BY TAB.CREATOR
ORDER BY TAB.CREATOR;
|
SELECT NSPNAME as schema_name,
COUNT(RELNAME) as view_count
FROM PG_CLASS C
LEFT JOIN PG_NAMESPACE N
ON N.OID = C.RELNAMESPACE
WHERE C.RELKIND in ('v')
AND N.NSPNAME
not in ('pg_catalog',
'information_schema',
'aws_db2zos_ext',
'public')
group by NSPNAME
order by NSPNAME;
|

|

|
有关详细级别的信息,请使用以下查询:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT TAB.CREATOR AS SCHEMA_NAME,
TAB.NAME AS VIEW_NAME
FROM SYSIBM.SYSTABLES TAB
WHERE TAB.TYPE = 'V'
AND TAB.CREATOR NOT LIKE 'SYS%'
ORDER BY TAB.CREATOR, TAB.NAME;
|
SELECT NSPNAME as schema_name,
RELNAME as view_name
FROM PG_CLASS C
LEFT JOIN PG_NAMESPACE N
ON N.OID = C.RELNAMESPACE
WHERE C.RELKIND in ('v')
AND N.NSPNAME
not in ('pg_catalog',
'information_schema',
'aws_db2zos_ext',
'public')
order by NSPNAME,RELNAME;
|
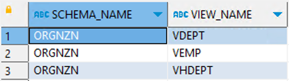
|

|
使用这些查询验证源和目标之间的数量和详细信息。如果发现任何差异,请找出原因并修复差异。
主键
主键
允许您为列设置唯一值,从而防止信息被重复。此键有助于改进基于键值的搜索并避免表扫描。
以下查询可帮助您提取源数据库和目标数据库中主键的数量和详细信息:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT TBCREATOR AS SCHEMA_NAME,
SUM(COLCOUNT) AS PK_COUNT
FROM SYSIBM.SYSTABCONST
WHERE TBCREATOR NOT LIKE 'SYS%'
AND TYPE='P'
GROUP BY TBCREATOR
Order by TBCREATOR;
|
select kcu.table_schema,
count(*) as pk_count
from information_schema.table_constraints tco
join information_schema.key_column_usage kcu
on kcu.constraint_name = tco.constraint_name
and kcu.constraint_schema = tco.constraint_schema
and kcu.constraint_name = tco.constraint_name
where tco.constraint_type = 'PRIMARY KEY'
and kcu.table_schema not in ('pg_catalog',
'information_schema'
,'aws_db2zos_ext', 'public')
group by kcu.table_schema
order by kcu.table_schema;
|

|

|
有关详细级别的信息,请使用以下查询:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT TBCREATOR AS TABLE_SCHEMA,
TBNAME AS TABLE_NAME,
CONSTNAME AS CONSTRTAINT_NAME,
COLNAME AS COLUMN_NAME,
COLSEQ AS POSITION
FROM SYSIBM.SYSKEYCOLUSE
WHERE TBCREATOR NOT LIKE 'SYS%'
ORDER BY TBCREATOR,TBNAME TAB.CREATOR,
TAB.NAME,COL.NAME, COL.KEYSEQ;
|
select kcu.table_schema,
kcu.table_name,
tco.constraint_name,
kcu.column_name,
kcu.ordinal_position as position
from information_schema.table_constraints tco
join
information_schema.key_column_usage kcu
on kcu.constraint_name = tco.constraint_name
and kcu.constraint_schema = tco.constraint_schema
and kcu.constraint_name = tco.constraint_name
where tco.constraint_type = 'PRIMARY KEY'
and kcu.table_schema
not in ('pg_catalog',
'information_schema',
'aws_db2zos_ext','public')
order by kcu.table_schema,kcu.table_name,
tco.constraint_name,kcu.column_name,
kcu.ordinal_position;
|
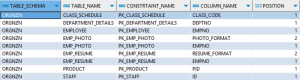
|
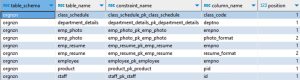
|
使用这些查询验证源和目标之间主键的数量和详细信息。如果发现任何差异,请通过部署日志确定原因并修复差异。
外键
外键
可以帮助您保持表之间的引用完整性。在使用 亚马逊云科技 DMS 满负载迁移执行数据迁移之前,应在目标系统上关闭这些密钥。有关更多信息,请参阅
使用 PostgreSQL 数据库作为 亚马逊云科技 数据库迁移服务的目标
。
通过以下查询,您可以获得有关源数据库和目标数据库中外键的计数和详细信息。使用 亚马逊云科技 DMS 完成满负载数据迁移后,您可以验证外键。
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT FK.CREATOR AS SCHEMA_NAME,
COUNT(*) AS FK_COUNT
FROM SYSIBM.SYSFOREIGNKEYS FK
WHERE FK.CREATOR NOT LIKE 'SYS%'
GROUP BY FK.CREATOR
ORDER BY FK.CREATOR;
|
select tc.table_schema,
count(*) as fk_count
from information_schema.table_constraints tc
join information_schema.key_column_usage kcu
on kcu.constraint_name = tc.constraint_name
and kcu.constraint_schema = tc.constraint_schema
and kcu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and kcu.table_schema
not in ('pg_catalog',
'information_schema',
'aws_db2zos_ext','public')
group by tc.table_schema
order by tc.table_schema;
|

|

|
有关详细级别的信息,请使用以下查询:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT FK.CREATOR AS SCHEMA_NAME,
REL.TBNAME AS TABLE_NAME,
REL.RELNAME AS FK_CONST_NAME,
REL.REFTBNAME AS FOREIGN_TABLE_NAME,
FK.COLNAME AS FK_COLUMN_NAME
FROM SYSIBM.SYSFOREIGNKEYS FK
LEFT OUTER JOIN SYSIBM.SYSRELS REL
ON FK.CREATOR = REL.REFTBCREATOR
AND FK.TBNAME = REL.TBNAME
WHERE FK.CREATOR NOT LIKE 'SYS%'
ORDER BY FK.CREATOR,
REL.TBNAME, REL.RELNAME;
|
SELECT tc.table_schema AS schema_name,
tc.table_name AS table_name,
tc.constraint_name AS fk_const_name,
ccu.table_name AS foreign_table_name,
kcu.column_name AS fk_column_name
FROM information_schema.table_constraints AS tc
JOIN information_schema.key_column_usage AS kcu
ON tc.constraint_name = kcu.constraint_name
AND tc.table_schema = kcu.table_schema
JOIN information_schema.constraint_column_usage AS ccu
ON ccu.constraint_name = tc.constraint_name
AND ccu.table_schema = tc.table_schema
WHERE tc.constraint_type = 'FOREIGN KEY'
AND tc.table_schema
not in ('pg_catalog',
'information_schema',
'aws_db2zos_ext', 'public')
order by tc.table_schema, tc.table_name;
|

|

|
索引
索引
是基于表的一列或多列创建的数据库对象。当定义为唯一索引时,索引用于提高查询性能并确保数据的唯一性。
唯一索引
使用
唯一键
,您可以保持列中数据的唯一性。通过以下查询,您可以获得有关源数据库和目标数据库中唯一密钥的计数和详细信息:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT IND.CREATOR AS SCHEMA_NAME,
COUNT(*) AS UNIQUE_COUNT
FROM SYSIBM.SYSINDEXES IND
INNER JOIN SYSIBM.SYSTABLES T
ON IND.CREATOR=T.CREATOR
AND IND.TBNAME=T.NAME
WHERE IND.CREATOR NOT LIKE 'SYS%'
AND IND.UNIQUERULE in ('U')
AND T.TYPE='T'
GROUP BY IND.CREATOR
ORDER BY IND.CREATOR;
|
SELECT sch.nspname as schema_name,
count(*) as unique_count
FROM pg_index idx JOIN pg_class cls
ON cls.oid=idx.indexrelid JOIN pg_class tab
ON tab.oid=idx.indrelid
and tab.RELISPARTITION = 'f'
JOIN pg_namespace sch
on sch.oid = tab.relnamespace
JOIN pg_am am ON am.oid=cls.relam
JOIN pg_indexes ids
ON sch.nspname = ids.schemaname
and ids.tablename = tab.relname
and cls.relname = ids.indexname
where idx.indisunique='t'
and indisprimary='f'
and sch.nspname
not in ('pg_toast',
'pg_catalog','information_schema',
'aws_db2zos_ext','public')
group by sch.nspname
order by sch.nspname;
|

|

|
有关详细级别的信息,请使用以下查询:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT IND.CREATOR AS SCHEMA_NAME,
IND.TBNAME AS TABLE_NAME,
IND.NAME AS CONTRAINT_NAME,
'Unique Index' AS CONSTRAINT_TYPE,
COL.COLNAME AS COLUMN_NAME
FROM SYSIBM.SYSINDEXES IND
LEFT OUTER JOIN SYSIBM.SYSKEYS COL
ON IND.CREATOR = COL.IXCREATOR
AND IND.NAME = COL.IXNAME
INNER JOIN SYSIBM.SYSTABLES T
ON IND.CREATOR=T.CREATOR
AND IND.TBNAME=T.NAME
WHERE IND.CREATOR NOT LIKE 'SYS%'
AND IND.UNIQUERULE IN ('U')
AND T.TYPE='T'
ORDER BY IND.CREATOR,
IND.TBNAME,IND.NAME, COL.COLNAME;
|
SELECT sch.nspname as schema_name,
tab.relname as table_name,
cls.relname as constraint_name,
ids.indexdef as definition
FROM pg_index idx
JOIN pg_class cls
ON cls.oid=idx.indexrelid
JOIN pg_class tab
ON tab.oid=idx.indrelid
and tab.RELISPARTITION = 'f'
JOIN pg_namespace sch
on sch.oid = tab.relnamespace
JOIN pg_am am ON am.oid=cls.relam
JOIN pg_indexes ids
ON sch.nspname = ids.schemaname
and ids.tablename = tab.relname
and cls.relname = ids.indexname
where idx.indisunique='t'
and indisprimary='f'
and sch.nspname
not in ('pg_toast',
'pg_catalog',
'information_schema',
'aws_db2zos_ext',
'public')
order by sch.nspname;
|

|

|
非唯一索引
索引在提高查询性能方面起着关键作用。由于调整方法因数据库而异,因此根据不同的用例,db2 for z/OS 和 PostgreSQL 数据库的索引数量及其类型会有所不同,因此索引数量也可能有所不同。由于 PostgreSQL 中分区表的限制,索引数也可能有所不同。
使用以下查询:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT IND.CREATOR AS SCHEMA_NAME,
COUNT(*) AS NON_UNIQUE_COUNT
FROM SYSIBM.SYSINDEXES IND
WHERE IND.CREATOR NOT LIKE 'SYS%'
AND IND.UNIQUERULE in ('D')
GROUP BY IND.CREATOR
ORDER BY IND.CREATOR;
|
SELECT sch.nspname,count(*) as index_count
FROM pg_index idx
JOIN pg_class cls
ON cls.oid=idx.indexrelid
JOIN pg_class tab
ON tab.oid=idx.indrelid
and tab.RELISPARTITION = 'f'
JOIN pg_namespace sch
on sch.oid = tab.relnamespace
JOIN pg_am am ON am.oid=cls.relam
JOIN pg_indexes ids
ON sch.nspname = ids.schemaname
and ids.tablename = tab.relname
and cls.relname = ids.indexname
where idx.indisunique='f'
and indisprimary='f'
and sch.nspname
not in ('pg_toast',
'pg_catalog',
'information_schema',
'aws_db2zos_ext',
'public',
'db2inst1')
group by sch.nspname
order by sch.nspname;
|

|

|
有关详细级别的信息,请使用以下查询:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT IND.CREATOR AS SCHEMA_NAME,
IND.TBNAME AS TABLE_NAME,
IND.NAME AS CONTRAINT_NAME,
'Unique Index' AS CONSTRAINT_TYPE,
COL.COLNAME AS COLUMN_NAME
FROM SYSIBM.SYSINDEXES IND
LEFT OUTER JOIN SYSIBM.SYSKEYS COL
ON IND.CREATOR = COL.IXCREATOR
AND IND.NAME = COL.IXNAME
WHERE IND.CREATOR NOT LIKE 'SYS%'
AND IND.UNIQUERULE IN ('D')
ORDER BY IND.CREATOR,
IND.TBNAME,IND.NAME, COL.COLNAME;
|
SELECT sch.nspname as schema_name,
tab.relname as tabl_name,
cls.relname as constraint_name,
ids.indexdef as definition
FROM pg_index idx
JOIN pg_class cls
ON cls.oid=idx.indexrelid
JOIN pg_class tab
ON tab.oid=idx.indrelid
and tab.RELISPARTITION = 'f'
JOIN pg_namespace sch
on sch.oid = tab.relnamespace
JOIN pg_am am ON am.oid=cls.relam
JOIN pg_indexes ids ON
sch.nspname = ids.schemaname
and ids.tablename = tab.relname
and cls.relname = ids.indexname
where idx.indisunique='f'
and indisprimary='f'
and sch.nspname
not in ('pg_toast',
'pg_catalog',
'information_schema',
'aws_db2zos_ext',
'public')
order by sch.nspname;
|

|

|
验证源数据库和目标数据库之间索引的数量和详细信息,任何差异都应归因于已知原因,或者应根据部署日志进行调查和修复。
物化查询表
来自 Db2 for z/OS 的物化查询表在 PostgreSQL 中作为
物
化视图迁移。 它们与常规视图类似,不同之处在于物化查询表以类似表格的形式保存结果。这提高了查询性能,因为数据随时可以返回。您可以使用以下查询来比较源和目标之间的对象:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT TAB.CREATOR AS SCHEMA_NAME,
COUNT(TAB.NAME) AS TABLE_COUNT
FROM SYSIBM.SYSTABLES TAB
WHERE TAB.TYPE = 'M'
AND TAB.CREATOR NOT LIKE 'SYS%'
GROUP BY TAB.CREATOR
ORDER BY TAB.CREATOR;
|
select schemaname,count(*) as mq_count
from pg_matviews
where schemaname NOT IN ('information_schema',
'pg_catalog', 'public','aws_db2zos_ext')
group by schemaname;
|

|

|
有关详细级别的信息,请使用以下查询:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT TAB.CREATOR AS SCHEMA_NAME,
TAB.NAME AS TABLE_NAME
FROM SYSIBM.SYSTABLES TAB
WHERE TAB.TYPE = 'M'
AND TAB.CREATOR NOT LIKE 'SYS%'
ORDER BY TAB.CREATOR,TAB.NAME;
|
select schemaname,matviewname as mq_name
from pg_matviews
where schemaname NOT IN ('information_schema',
'pg_catalog', 'public','aws_db2zos_ext');
|

|

|
验证源数据库和目标数据库之间物化查询表和实例化视图的数量和详细信息,并应根据部署日志调查和修复任何差异。
用户定义的数据类型
亚马逊云科技 SCT 将自定义数据类型从 Db2 for z/OS 迁移到 PostgreSQL,作为
类型
s。您可以使用以下查询来比较源和目标之间的对象:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT SCHEMA AS SCHEMA_NAME,
COUNT(*) AS UDT_COUNT
FROM SYSIBM.SYSDATATYPES
WHERE SCHEMA NOT LIKE 'SYS%'
GROUP BY SCHEMA
ORDER BY SCHEMA;
|
SELECT n.nspname as schema_name,
count(*) as udt_count
FROM pg_catalog.pg_type t
JOIN pg_catalog.pg_namespace n
ON n.oid = t.typnamespace
WHERE ( t.typrelid = 0
OR ( SELECT c.relkind = 'c'
FROM pg_catalog.pg_class c
WHERE c.oid = t.typrelid ) )
AND NOT EXISTS (
SELECT 1
FROM pg_catalog.pg_type el
WHERE el.oid = t.typelem
AND el.typarray = t.oid )
AND n.nspname NOT IN ('information_schema',
'pg_toast',
'pg_catalog', 'public',
'aws_db2zos_ext')
group by n.nspname
order by n.nspname;
|

|

|
有关详细级别的信息,请使用以下查询:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT SCHEMA AS SCHEMA_NAME,
NAME AS UDT_NAME
FROM SYSIBM.SYSDATATYPES
WHERE SCHEMA NOT LIKE 'SYS%'
ORDER BY SCHEMA;
|
SELECT n.nspname as schema_name,
t.typname as udt_name
FROM pg_catalog.pg_type t
JOIN pg_catalog.pg_namespace n
ON n.oid = t.typnamespace
WHERE ( t.typrelid = 0
OR ( SELECT c.relkind = 'c'
FROM pg_catalog.pg_class c
WHERE c.oid = t.typrelid ) )
AND NOT EXISTS (
SELECT 1
FROM pg_catalog.pg_type el
WHERE el.oid = t.typelem
AND el.typarray = t.oid )
AND n.nspname NOT IN ('information_schema',
'pg_toast',
'pg_catalog', 'public','aws_db2zos_ext')
order by n.nspname;
|

|

|
验证源数据库和目标数据库之间用户定义类型的数量和详细信息,并应根据部署日志调查和修复任何差异。
触发器
触发器
可以帮助您审计数据库、实施业务规则或实现参照完整性。它们还会根据相应区域的使用情况影响性能。以下查询为您提供了源数据库和目标数据库触发器的数量和详细信息:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT SCHEMA AS SCHEMA_NAME,
COUNT(*) AS TRIGGER_COUNT
FROM SYSIBM.SYSTRIGGERS
WHERE SCHEMA NOT LIKE 'SYS%'
GROUP BY SCHEMA
ORDER BY SCHEMA;
|
SELECT trigger_schema AS SchemaName,
Count(trigger_name) AS TriggerCount
FROM information_schema.TRIGGERS
WHERE trigger_schema NOT IN ('aws_db2zos_ext',
'pg_catalog')
GROUP BY trigger_schema
ORDER BY trigger_schema;
|

|

|
有关详细级别的信息,请使用以下查询:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT SCHEMA AS SCHEMA_NAME,
NAME AS TRIGGER_NAME,
TBNAME AS TABLE_NAME,
CASE TRIGTIME
WHEN 'B' THEN 'BEFORE'
WHEN 'A' THEN 'AFTER'
WHEN 'I' THEN 'INSTEAD OF'
END AS ACTIVATION,
RTRIM(CASE WHEN TRIGEVENT ='U'
THEN 'UPDATE ' ELSE '' END
||
CASE WHEN TRIGEVENT ='D'
THEN 'DELETE ' ELSE '' END
||
CASE WHEN TRIGEVENT ='I'
THEN 'INSERT ' ELSE '' END) AS EVENT
FROM SYSIBM.SYSTRIGGERS
WHERE SCHEMA NOT LIKE 'SYS%'
ORDER BY SCHEMA, NAME, TBNAME;
|
SELECT trigger_schema AS TriggerSchemaName,
trigger_name,
event_object_schema AS TableSchema,
event_object_table AS TableName,
event_manipulation AS TriggerType
FROM information_schema.TRIGGERS
WHERE trigger_schema NOT IN (
'aws_db2zos_ext',
'pg_catalog')
ORDER BY trigger_schema,
trigger_name;
|

|

|
在 PostgreSQL 中,触发器是通过在创建触发器本身之前定义触发器函数来实现的。必须将触发器函数声明为不带参数且返回类型触发器的函数。
由于它们在 PostgreSQL 中的实现方式,db2 for z/OS 和 PostgreSQL 之间的触发次数可能会有所不同。
验证源数据库和目标数据库之间触发器的数量和详细信息,任何差异都应归因于已知原因,或者应根据部署日志进行调查和修复。
序列
序列
可帮助您根据给定的范围和顺序为列创建和递增整数值。与标识列不同,序列与特定表无关。应用程序引用序列对象来检索其下一个值。序列和表格之间的关系由应用程序控制。用户应用程序可以引用序列对象并协调多行和表中的值。
以下查询可帮助您获取源数据库和目标数据库中可用序列的计数和详细级别信息:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT SCHEMA AS SCHEMA_NAME,
COUNT(*) AS SEQ_COUNT
FROM SYSIBM.SYSSEQUENCES
WHERE SCHEMA NOT LIKE 'SYS%'
AND SEQTYPE = 'S'
GROUP BY SCHEMA
ORDER BY SCHEMA;
|
select n.nspname as schema_namee
,count(*) as seq_count
from pg_sequence seq
join pg_class seqc
on seq.seqrelid = seqc.oid
join pg_namespace n
on seqc.relnamespace = n.oid
where n.nspname
NOT IN ( 'pg_catalog',
'information_schema',
'aws_db2zos_ext', 'public')
group by n.nspname
order by n.nspname ;
|

|

|
有关详细级别的信息,请使用以下查询:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT SCHEMA AS SCHEMA_NAME,
NAME AS SEQ_NAME,
CYCLE,
ORDER,
CACHE
FROM SYSIBM.SYSSEQUENCES
WHERE SCHEMA NOT LIKE 'SYS%'
AND SEQTYPE = 'S'
ORDER BY SCHEMA,NAME;
|
select n.nspname as schema_namee
,seqc.relname as seqname,
seqcycle as cycle,
seqcache as cache
from pg_sequence seq
join pg_class seqc
on seq.seqrelid = seqc.oid
join pg_namespace n
on seqc.relnamespace = n.oid
where n.nspname
NOT IN ( 'pg_catalog',
'information_schema',
'aws_db2zos_ext', 'public')
order by n.nspname,seqc.relname;
|

|

|
验证源和目标之间序列的数量和详细信息,但迁移后将
序列 设置
为正确的值也很重要。设置序列很重要,因为序列从源数据库迁移到目标数据库后,它们以序列的最小值开头,并可能在插入和更新语句期间导致重复的键错误。
程序
Db2 for z/OS 标准存储过程封装了业务逻辑,并在单个工作单元中运行相关的 DDL 或 DML 操作。
在 PostgreSQL 中,由于过程的限制,我们使用
函数
而不是存储过程。
在这些情况下,源 Db2 过程数也会被添加到函数计数中。在源数据库和目标数据库中,以下查询均提供有关过程的计数和详细信息:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT SCHEMA AS SCHEMA_NAME,
COUNT(*) AS PROC_COUNT
FROM SYSIBM.SYSROUTINES
WHERE ROUTINETYPE = 'P'
AND SCHEMA NOT LIKE 'SYS%'
GROUP BY SCHEMA
ORDER BY SCHEMA;
|
SELECT n.nspname AS SchemaName,
Count(p.proname) AS procCount
FROM pg_proc p
join pg_namespace n
ON p.pronamespace = n.oid
WHERE n.nspname NOT IN ( 'pg_catalog',
'information_schema',
'aws_db2zos_ext', 'public')
AND p.prokind = 'p'
GROUP BY n.nspname
ORDER BY n.nspname;
|

|

|
有关详细级别的信息,请使用以下查询:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT SCHEMA AS SCHEMA_NAME,
NAME AS PROCEDURE_NAME
FROM SYSIBM.SYSROUTINES
WHERE ROUTINETYPE = 'P'
AND SCHEMA NOT LIKE 'SYS%'
ORDER BY SCHEMA,NAME;
|
SELECT n.nspname AS SchemaName,
p.proname AS procedure_name
FROM pg_proc p
join pg_namespace n
ON p.pronamespace = n.oid
WHERE n.nspname NOT IN ( 'pg_catalog',
'information_schema',
'aws_db2zos_ext', 'public')
AND p.prokind = 'p'
GROUP BY n.nspname, p.proname
ORDER BY n.nspname, p.proname;
|

|

|
函数
在 Db2 for z/OS 中,SQL 函数对输入参数实现特定的业务或功能逻辑,并返回某些类型的预定义输出。在 PostgreSQL 中,由于函数是实现业务和功能逻辑的首选,因此对于 z/OS,它们的数量通常高于 Db2。在源数据库和目标数据库中,以下查询都提供有关函数的计数和详细信息:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT SCHEMA AS SCHEMA_NAME,
COUNT(*) AS PROC_COUNT
FROM SYSIBM.SYSROUTINES
WHERE ROUTINETYPE = 'F'
AND SCHEMA NOT LIKE 'SYS%'
GROUP BY SCHEMA
ORDER BY SCHEMA;
|
SELECT n.nspname AS SchemaName,
Count(p.proname) AS func_Count
FROM pg_proc p
join pg_namespace n
ON p.pronamespace = n.oid
WHERE n.nspname NOT IN ('pg_catalog',
'information_schema',
'aws_db2zos_ext', 'public')
AND p.prokind = 'f'
GROUP BY n.nspname
ORDER BY n.nspname;
|

|

|
有关详细级别的信息,请使用以下查询:
|
Db2 for z/OS Query
|
PostgreSQL Query
|
SELECT SCHEMA AS SCHEMA_NAME,
NAME AS PROCEDURE_NAME
FROM SYSIBM.SYSROUTINES
WHERE ROUTINETYPE = 'F'
AND SCHEMA NOT LIKE 'SYS%'
ORDER BY SCHEMA,NAME;
|
SELECT n.nspname AS SchemaName,
p.proname AS function_name
FROM pg_proc p
join pg_namespace n
ON p.pronamespace = n.oid
WHERE n.nspname NOT IN ('pg_catalog',
'information_schema',
'aws_db2zos_ext', 'public')
AND p.prokind = 'f'
GROUP BY n.nspname, p.proname
ORDER BY n.nspname, p.proname;
|
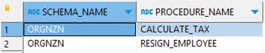
|

|
有用的 PostgreSQL 目录表
下表总结了一些有用的 Db2 for z/OS 及其相应的 PostgreSQL 系统和目录表和视图。这些表和视图包含与数据库中存在的各种对象相关的元数据,用于数据库对象校验。
|
Db2 for z/OS
|
PostgreSQL
|
Use Case
|
|
sysibm.systables/ sysibm.syscolumns
|
pg_tables
/信息_schema.tables
|
Look for various table properties
|
|
sysibm.systables/ sysibm.syscolumns
|
Pg_views/information_schema.views
|
Look for different properties of views
|
|
sysibm.sysindexes/ sysibm.syskeys
|
pg_indexes/pg_index
|
Gather details about indexes
|
|
sysibm.sysroutines
|
pg_proc
|
Gather details about procedures, functions, and trigger functions
|
|
sysibm.systriggers
|
information_schema.triggers
|
Gather details about triggers
|
|
sysibm.syssequences
|
pg_sequence/information_schema.sequences
|
Gather details about sequence, and identity or serial columns
|
|
sysibm.systables
|
pg_matviews
|
Find more details about materialized views
|
|
sysibm.sysdatatypes
|
pg_type
|
Gather more information about custom data types
|
处理 PostgreSQL 中不支持的对象
必须为 PostgreSQL 不支持的 z/OS 对象手动执行 Db2 迁移。要让 z/OS 模拟与源函数相同的函数,需要采用与 DB2 不同的方式实现这些函数。因此,需要对此类对象进行手动验证。
结论
在这篇文章中,我们讨论了使用适用于 z/OS 的 Db2 和 Aurora PostgreSQL 兼容版或适用于 PostgreSQL 数据库的 RDS 的元数据查询来验证数据库对象。数据库对象校验是一个重要步骤,它可以深入了解迁移的准确性,并确认所有数据库对象是否都已正确迁移。数据库验证阶段确认目标数据库的完整性,并确保顺利过渡到依赖应用程序进程的集成。
数据库迁移后应始终对所有对象进行单元测试、功能测试和回归测试,无论是自动迁移还是手动迁移,因为这样可以确保所有迁移的对象都符合标准并按预期运行。当你对应用程序进行集成测试时,这样可以节省大量的返工。
如果您有任何意见或问题,请告诉我们。我们非常重视您的反馈!
作者简介
 Sai Parthasaradhi
是 亚马逊云科技 专业服务的数据库迁移专家。他与客户紧密合作,帮助他们在 亚马逊云科技 上迁移数据库并对其进行现代化改造。
Sai Parthasaradhi
是 亚马逊云科技 专业服务的数据库迁移专家。他与客户紧密合作,帮助他们在 亚马逊云科技 上迁移数据库并对其进行现代化改造。
 Vikas Gupta
是 亚马逊云科技 专业服务的首席数据库迁移顾问。他喜欢自动化手动流程并增强用户体验。他帮助客户在 亚马逊云科技 云中迁移和现代化工作负载,特别关注现代应用程序架构和开发最佳实践。
Vikas Gupta
是 亚马逊云科技 专业服务的首席数据库迁移顾问。他喜欢自动化手动流程并增强用户体验。他帮助客户在 亚马逊云科技 云中迁移和现代化工作负载,特别关注现代应用程序架构和开发最佳实践。
 Pavithra Balasubramanian
是印度亚马逊网络服务的数据库顾问。她热衷于帮助客户完成云采用之旅,重点是将传统数据库迁移到亚马逊云科技 Cloud。
Pavithra Balasubramanian
是印度亚马逊网络服务的数据库顾问。她热衷于帮助客户完成云采用之旅,重点是将传统数据库迁移到亚马逊云科技 Cloud。