我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 亚马逊云科技 Storage Gateway 对下一代测序工作流程进行现代化改造
E@@
随着我们对流程进行现代化改造,新的解决方案需要提供可扩展性和近乎实时的支持,以支持快速扩展或包括大量数据传输在内的弹出式实验室。
我们需要管理来减少花费太长时间的本地基础设施/处理。速度至关重要,因为我们需要加快向云端的数据迁移以缩短周转时间。最后,重要的是,我们的解决方案能够消除用于传输和通知的自定义解决方案,从而通过集成提高运营效率。
在这篇博客文章中,我们将分享我们的实验室数据实时数据传输解决方案,该解决方案使用原生 亚马逊云科技 技术构建,旨在扩展和适应我们不断增长的实验室需求。我们的解决方案使用
解决方案概述
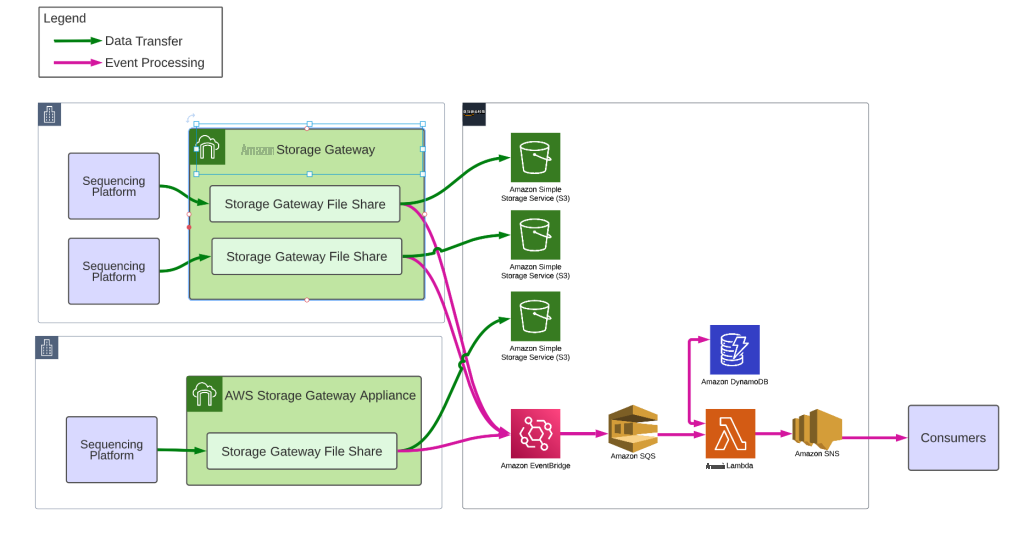
NGS 数据湖由作为数据提取和通知平台的 亚马逊云科技 Storage Gateway 提供支持,利用亚马逊 Dynamo
亚马逊云科技 Storage Gateway
事件处理
Storage Gateway 文件共享 向亚马逊 EventBridge 发送
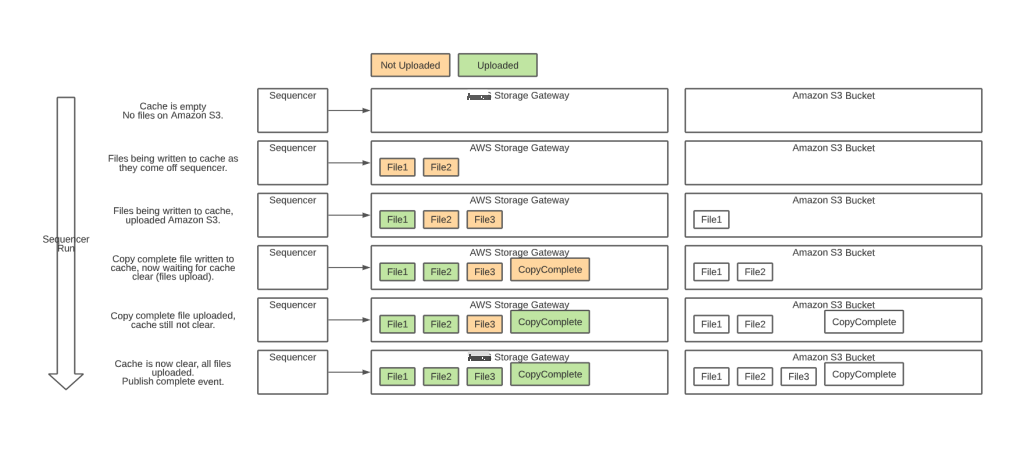
当 copyComplete 文件出现时,我们通过验证 v 整个文件夹是否为空来确认运行中的所有文件都已成功上传到 S3。这个简单的步骤由 亚马逊云科技 Storage Gateway NotifyWhenUploaded API 提供支持,当缓存为空时,它会发送异步确认。当我们收到此通知时,我们会触发一个 run complete 事件,该事件通过 SNS 流向消费者。在测序运行期间,数据传输是实时的,因此我们的数据上传通常在测序运行结束后的几分钟内完成。
数据湖
在我们的数据湖中,每个测序设备都有自己的 Amazon S3 存储桶,专用于存储 亚马逊云科技 Storage Gateway 文件共享。整个数据湖都是通过自动化配置的,因此我们可以轻松控制存储桶策略、生命周期管理、加密等。我们将每个存储桶的库存配置为集中存储桶,并提供相应的复制和访问日志记录策略。我们的数据湖是 WORM(一次写入多次读取),因此我们的测序数据永远不会被修改或删除。数据湖的使用者根据其要求被授予只读访问权限。
将新的文件共享和 Amazon S3 存储桶部署到数据湖只需要更新配置文档,即可在现有 S3 文件网关上放置新的序列器 ID。自动化将在文件网关上预置文件共享,并使用共享数据湖存储桶配置设置将其链接到新的 Amazon S3 存储桶。在自动化过程中,所有文件共享和存储桶都列在单独的 Amazon DynamoDB 表中,包括有关如何挂载文件共享的相关详细信息,例如文件共享 IP 地址和文件共享名称。由于这些资源是虚拟的,因此我们可以轻松地转移文件共享的部署位置,以便根据需要移动容量。现场技术人员将排序器配置为在配置文件共享并结束安装过程后将其写入。
部署
部署分为两个步骤。如果我们的站点现有容量不足,我们会采购和安装 亚马逊云科技 Storage Gateway 设备。我们有仪表板显示每个站点的可用容量,以便我们知道是否需要其他硬件。如果我们需要更多硬件,我们可以从我们的首选经销商处订购,或者如果在美国,则通过
结论
Exact Sciences 已将 亚马逊云科技 Storage Gateway 作为 亚马逊云科技 上的 NGS 数据湖的基础,它依靠灵活性、可扩展性、易管理性以及原生 亚马逊云科技 与解耦服务的集成,在全国范围内快速扩展 NGS 数据传输解决方案。自首次部署以来,我们已经在 3 个不同时区的 4 个实验室地点上传了数百次测序结果(很多 TB 数据),占地面积为 9 台 Storage Gateway 物理设备,为 25 台测序设备提供服务。我们的基础设施和配置流程已经标准化,新的测序平台比以往任何时候都更快地上线。该解决方案需要少量资本投资,但可以无限扩展,为短期时间敏感型工作负载和长期数据湖功能提供强大的处理能力,同时减少本地占用空间,转而依赖云原生服务。
这篇文章中的内容和观点是第三方作者的内容和观点,亚马逊云科技 对这篇文章的内容或准确性不承担任何责任。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。