我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用反向标记过滤器在 OpenSearch 中启用后缀匹配查询
在这篇文章中,我们将介绍如何实现基于后缀的搜索。例如,要查找电影名称为 “saving private ryan” 的文档,可以在基于前缀的查询中使用前缀 “保存”。有时,你还想匹配后缀,例如将 “哈利波特火焰杯” 与后缀 “Fire” 进行匹配。为此,首先使用反向
解决方案概述
文本分析涉及将非结构化文本(例如电子邮件的内容或产品描述)转换为经过微调以进行有效搜索的结构化格式。分析器允许使用分词化实现全文搜索,这需要将文本分解成称为标语的较小片段,这些标记通常代表单个单词。为了实现反向字段搜索,分析器会执行以下操作。
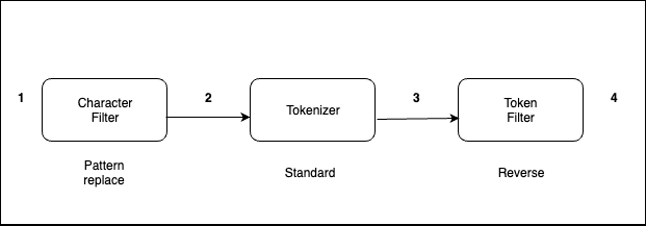
分析器按以下顺序处理文本:
-
使用字符过滤器将
-替换为_。例如,从 “我的驾驶执照号码是 123-456-789” 到 “我的驾驶执照号码是 123_456_789”。 - 标准分词器将文本拆分为标记。例如,从 “我的驾驶执照号码是 123_456_789” 到 “[我的,驾照,号码,是,123、456、789]”。
- 反向代币过滤器会反向流中的每个代币。例如,从 [我的,驾照,号码,是,123,456,789] 到 [我的,gnivird,esnecil,rebmun,si,321,654,987]。
标准分析器(默认分析器)根据单词边界将输入字符串分解为标记,并删除大多数标点符号。有关分析仪的更多信息,请参阅
索引和搜索
每个文档都是字段的集合,每个字段都有自己的特定数据类型。为数据创建映射时,将创建一个映射定义,其中包含与文档相关的字段列表。要了解有关索引映射的更多信息,请参阅
让我们举一个分析器的示例,该分析器在文本字段上应用了反向标记过滤器。
-
首先,创建带有映射的索引,如以下代码所示。新字段 “
reverse_title” 源自用于后缀搜索 的 “标题” 字段,而原始字段 “标题” 将用于常规搜索。
- 在索引中插入一些文档:
-
运行以下查询,对派生字段 “
reverse_title” 执行 “Fire” 的后缀/反向搜索:
以下代码显示了我们的结果:
-
对于非反向搜索,您可以使用原始字段 “
标题”。
以下代码显示了我们的结果。
该查询返回电影名为 “哈利波特火焰杯” 的文档。
如果你想知道高级搜索是如何运作的,请参阅
结论
在这篇文章中,你介绍了文本分析在 OpenSearch 中的工作原理以及如何有效地使用反向标记过滤器实现基于后缀的搜索。
如果您对这篇文章有反馈,请在评论部分提交您的评论。
作者简介
 巴拉夫·帕特尔
是亚马逊网络服务的专业解决方案架构师,负责分析。他主要在亚马逊 OpenSearch Service 上工作,帮助客户掌握在云端运行 OpenSearch 工作负载的关键概念和设计原则。Bharav喜欢探索新地方并尝试不同的美食。
巴拉夫·帕特尔
是亚马逊网络服务的专业解决方案架构师,负责分析。他主要在亚马逊 OpenSearch Service 上工作,帮助客户掌握在云端运行 OpenSearch 工作负载的关键概念和设计原则。Bharav喜欢探索新地方并尝试不同的美食。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。