Amazon Redshift
是一项完全托管的 PB 级云端数据仓库服务。成千上万的客户每天使用 Amazon Redshift 处理艾字节的数据,以支持他们的分析工作负载。
Amazon Redshift 添加了许多功能来增强分析处理,例如
汇总、多维数据集和分组集
,在 A
mazon Redshift 的《 简化在线分析处理 (OLAP) 查询》一文中使用汇总、多维数据集和分组集等新 SQL 结构
对此进行了演示。 亚马逊 Redshift 最近添加了许多 SQL 命令和表达式。
在这篇文章中,我们将讨论两个新的 SQL 功能,即
M
ERGE 命令和 QUAL ITY 子句,它们简化了数据提取和数据过滤。
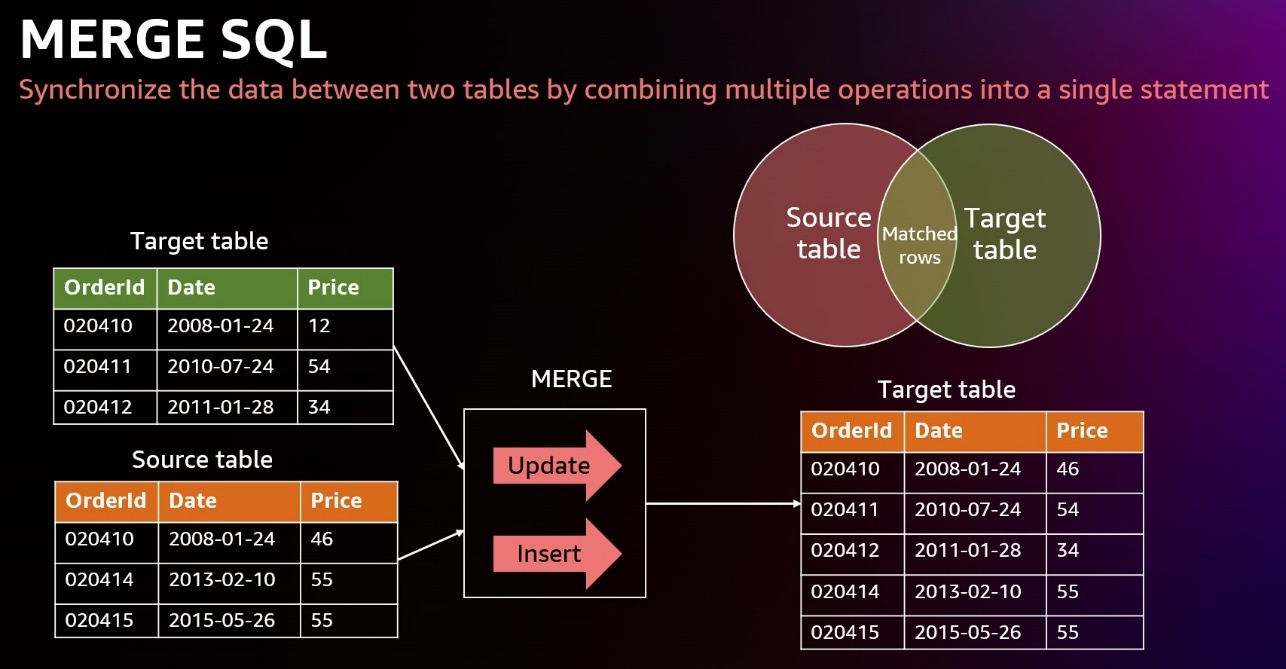
大多数下游应用程序中一项熟悉的任务是变更数据捕获 (CDC) 并将其应用于目标表。此任务需要检查源数据,以确定它是对现有目标数据的更新还是插入。如果没有 MERGE 命令,则需要使用业务密钥对照现有数据集测试新数据集。如果不匹配,则在现有数据集中插入新行;否则,使用新的数据集值更新了现有数据集行。
MERG
E 命令有条件地将源表中的行合并
到目标表中。传统上,这只能通过分别使用多个插入、更新或删除语句来实现。使用多个语句更新或插入数据时,不同操作之间存在不一致的风险。合并操作通过确保所有操作在单个事务中一起执行来降低这种风险。
Q U
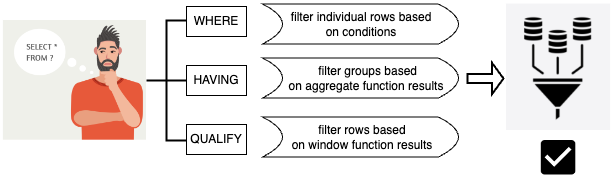
AL
ITY 子句根据用户指定的搜索条件筛选先前计算的窗口函数的结果。您可以使用子句将筛选条件应用于窗口函数的结果,而无需使用子查询。
这与 HAV ING 子句类似,后者应用条件从 WHERE 子句中进一步筛选行。
QUALITY 和 HAVING 之间的区别在于,QUALITY 子句的筛选结果可能基于对数据运行窗口函数的结果。你可以在一个查询中同时使用QUALITY和HAVING子句。
在这篇文章中,我们将演示如何使用 MERGE 命令来实现 CDC,以及如何使用 QUALITY 来简化对这些更改的验证。
解决方案概述
在这个用例中,我们有一个数据仓库,其中有一个客户维度表,需要始终从源系统获取最新数据。这些数据还必须反映初始创建时间和上次更新时间,以便进行审计和跟踪。
解决这个问题的一种简单方法是每天完全忽略客户维度;但是,这无法实现更新跟踪,而更新跟踪是一项审计任务,对于更大的表格也可能不可行。
您可以按照
此
处的说明从 Amazon S3 加载示例数据 。使用 s
ample_data_dev.tpcds
下的现有客户表 ,我们创建了一个客户维度表和一个包含现有客户更新和新客户插页的源表。我们使用 MERGE 命令将源表数据与目标表(客户维度)合并。我们还将介绍如何使用 QUALITY 子句来简化对目标表中更改的验证。
要按照本文中的步骤进行操作,我们建议您下载随附的
笔记本
,其中包含为这篇文章运行的所有脚本。要了解如何创作和运行笔记本,请参阅
创作和运行
笔记本。
先决条件
您应该具备以下先决条件:
-
一个
亚马逊云科技 账户
-
Redshift 预置的集群或
Amazon Red shift
无服务器终端节点
-
s ample_d
ata_dev 数据库(包含客户表)中的 tpcds 数据
创建并填充维度表
我们使用
sample_data_dev.t
pcds 下的现有客户表来创建客户维度表。
完成以下步骤:
-
使用包括业务密钥在内的几个选定字段创建表,并添加几个维护字段用于插入和更新时间戳:
— 创建客户维度表 DROP TABLE 如果存在 customer_dim CASCADE;创建表 customer_dim (customer_dim_id bigint 默认生成为身份 (1, 1),c_customer_sk 整数不为空编码 az64 distkey,c_first_name 字符 (20) ENCODE 哈哈,c_last_name 字符 (30) ENCODE lzo,c_current_addr_sk 整数 ENCODE az64,c_birth_country 字符变化 (20) ENCODE lzo,c_email_address 字符 (50) ENCODE lzo,record_insert_ts 时间戳不带时区默认当前时间戳,record_upd_ts 时间戳不带时区默认值为空)排序键(c_customer_sk
);
-
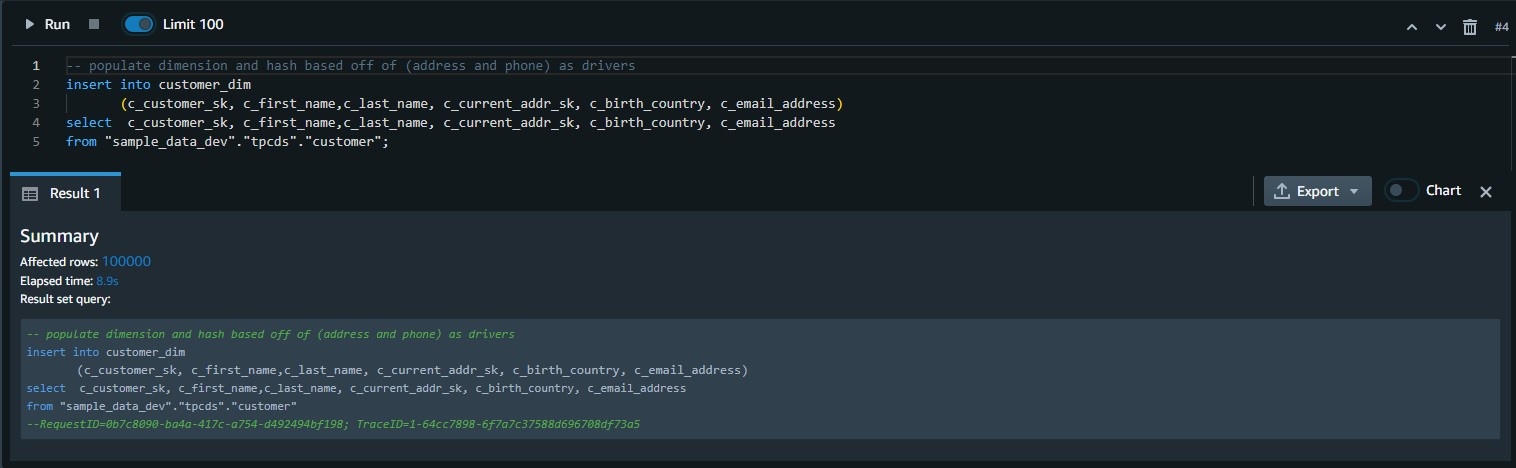
填充维度表:
--将维度插入客户_dim(c_customer_sk、c_first_name、c_last_name、c_current_addr_sk、c_birth_countr_country_country_country_country_country_country_country_country_country_country_country_country_country_country_country、c_email_addr_sk 来自 “sample_data_dev” 的_地址。” tpcds”。” 客户”;
-
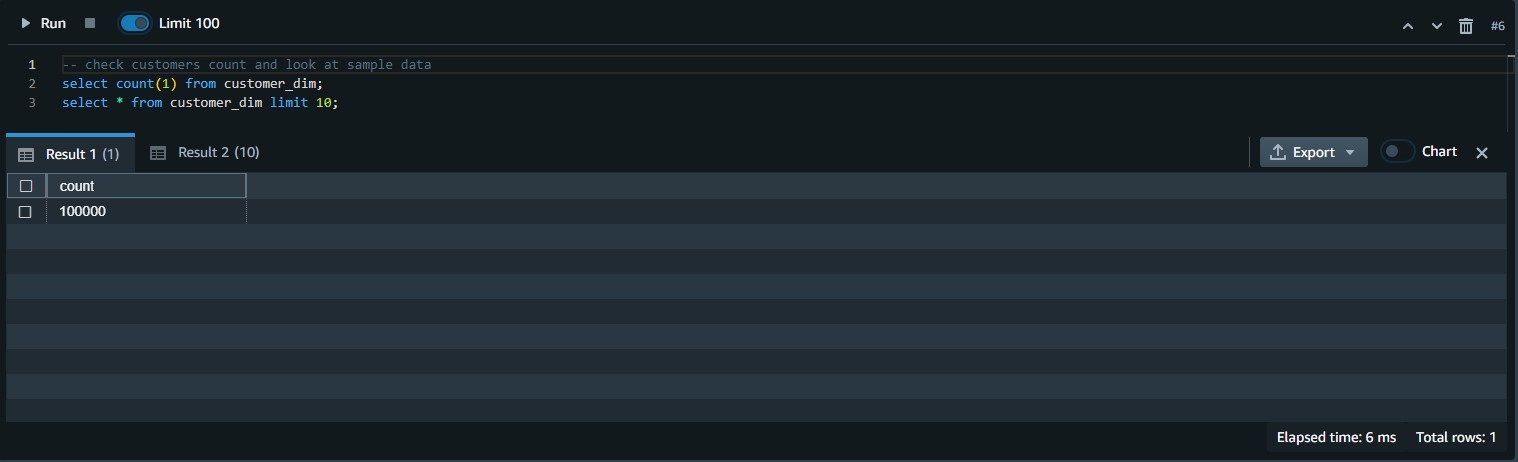
验证行数和表格内容:
--检查客户数量并查看样本数据,从 customer_dim 中选择数量 (1);从 customer_dim limit 10 中选择*;
模拟客户表的变化
使用以下代码来模拟对表格所做的更改:
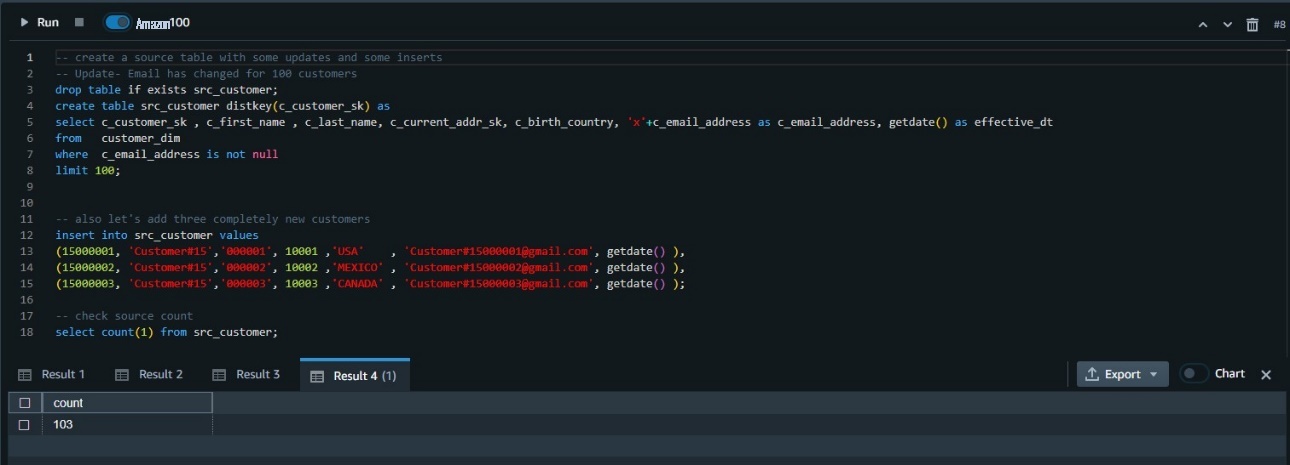
-- create a source table with some updates and some inserts
-- Update- Email has changed for 100 customers
drop table if exists src_customer;
create table src_customer distkey(c_customer_sk) as
select c_customer_sk , c_first_name , c_last_name, c_current_addr_sk, c_birth_country, ‘x’+c_email_address as c_email_address, getdate() as effective_dt
from customer_dim
where c_email_address is not null
limit 100;
-- also let’s add three completely new customers
insert into src_customer values
(15000001, ‘Customer#15’,’000001’, 10001 ,’USA’ , ‘Customer#15000001@gmail.com’, getdate() ),
(15000002, ‘Customer#15’,’000002’, 10002 ,’MEXICO’ , ‘Customer#15000002@gmail.com’, getdate() ),
(15000003, ‘Customer#15’,’000003’, 10003 ,’CANADA’ , ‘Customer#15000003@gmail.com’, getdate() );
-- check source count
select count(1) from src_customer;
将源表合并到目标表中
现在,您有了包含一些更改的源表,您需要将其与客户维度表合并。
在执行 MERGE 命令之前,此类任务需要两个单独的 UPDATE 和 INSERT 命令才能实现:
-- merge changes to dim customer
BEGIN TRANSACTION;
-- update current records
UPDATE customer_dim
SET c_first_name = src.c_first_name ,
c_last_name = src.c_last_name ,
c_current_addr_sk = src.c_current_addr_sk ,
c_birth_country = src.c_birth_country ,
c_email_address = src.c_email_address ,
record_upd_ts = current_timestamp
from src_customer AS src
where customer_dim.c_customer_sk = src.c_customer_sk ;
-- Insert new records
INSERT INTO customer_dim (c_customer_sk, c_first_name,c_last_name, c_current_addr_sk, c_birth_country, c_email_address)
select src.c_customer_sk, src.c_first_name,src.c_last_name, src.c_current_addr_sk, src.c_birth_country, src.c_email_address
from src_customer AS src
where src.c_customer_sk NOT IN (select c_customer_sk from customer_dim);
-- end merge operation
COMMIT TRANSACTION;
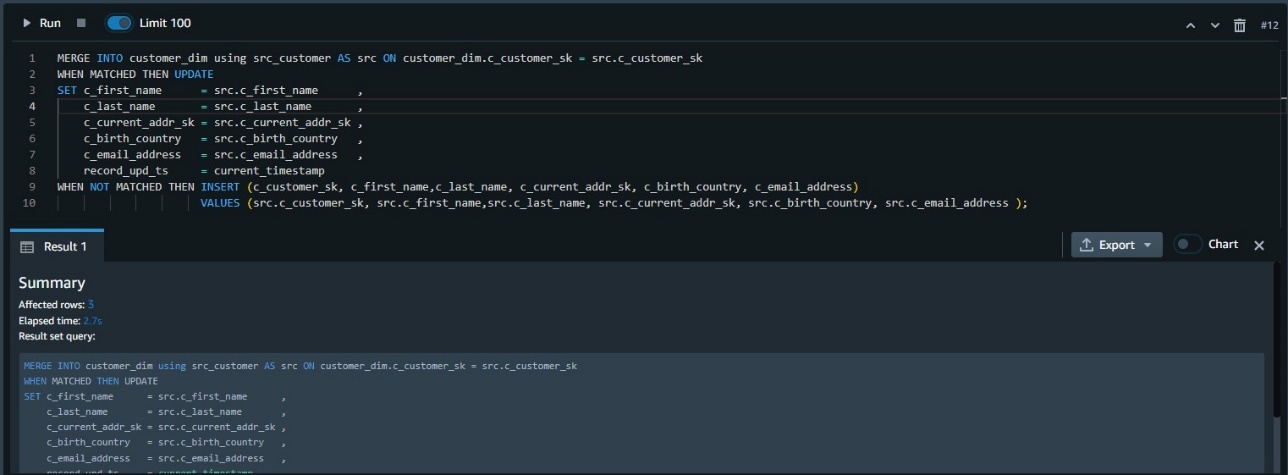
MERGE 命令使用更简单的语法,在该语法中,我们使用键比较结果来决定是执行更新 DML 操作(匹配时)还是插入 DML 操作(不匹配时):
MERGE INTO customer_dim using src_customer AS src ON customer_dim.c_customer_sk = src.c_customer_sk
WHEN MATCHED THEN UPDATE
SET c_first_name = src.c_first_name ,
c_last_name = src.c_last_name ,
c_current_addr_sk = src.c_current_addr_sk ,
c_birth_country = src.c_birth_country ,
c_email_address = src.c_email_address ,
record_upd_ts = current_timestamp
WHEN NOT MATCHED THEN INSERT (c_customer_sk, c_first_name,c_last_name, c_current_addr_sk, c_birth_country, c_email_address)
VALUES (src.c_customer_sk, src.c_first_name,src.c_last_name, src.c_current_addr_sk, src.c_birth_country, src.c_email_address );
验证目标表中的数据更改
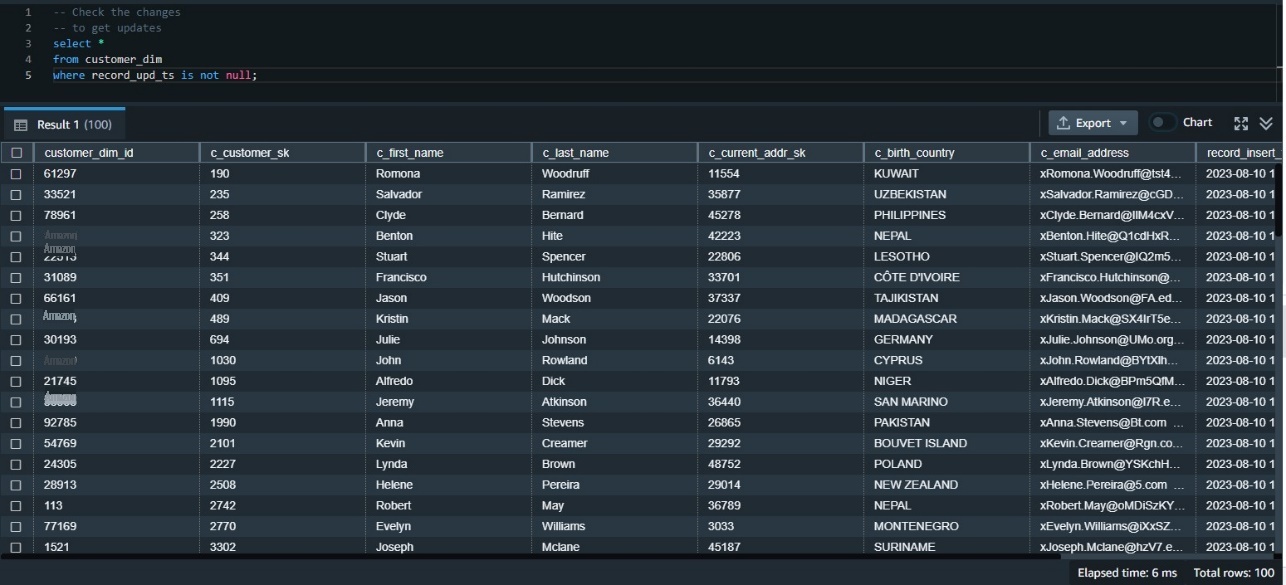
现在我们需要验证数据是否已正确进入目标表。我们可以先使用更新时间戳检查更新的数据。因为这是我们的第一次更新,所以我们可以检查更新时间戳不为空的所有行:
-- Check the changes
-- to get updates
select *
from customer_dim
where record_upd_ts is not null
使用 QUALITY 来简化对数据更改的验证
我们需要检查最近插入到该表中的数据。做到这一点的一种方法是按插入时间戳对数据进行排名,然后获得排名第一的那些数据。这需要使用窗口函数
rank ()
,还需要子查询才能获得结果。
在 QUALITY 问世之前,我们需要使用如下所示的子查询来构建它:
select customer_dim_id,c_customer_sk ,c_first_name ,c_last_name ,c_current_addr_sk,c_birth_country ,c_email_address ,record_insert_ts ,record_upd_ts
from
( select rank() OVER (ORDER BY DATE_TRUNC(‘second’,record_insert_ts) desc) AS rnk,
customer_dim_id,c_customer_sk ,c_first_name ,c_last_name ,c_current_addr_sk,c_birth_country ,c_email_address ,record_insert_ts ,record_upd_ts
from customer_dim
where record_upd_ts is null)
where rnk = 1;
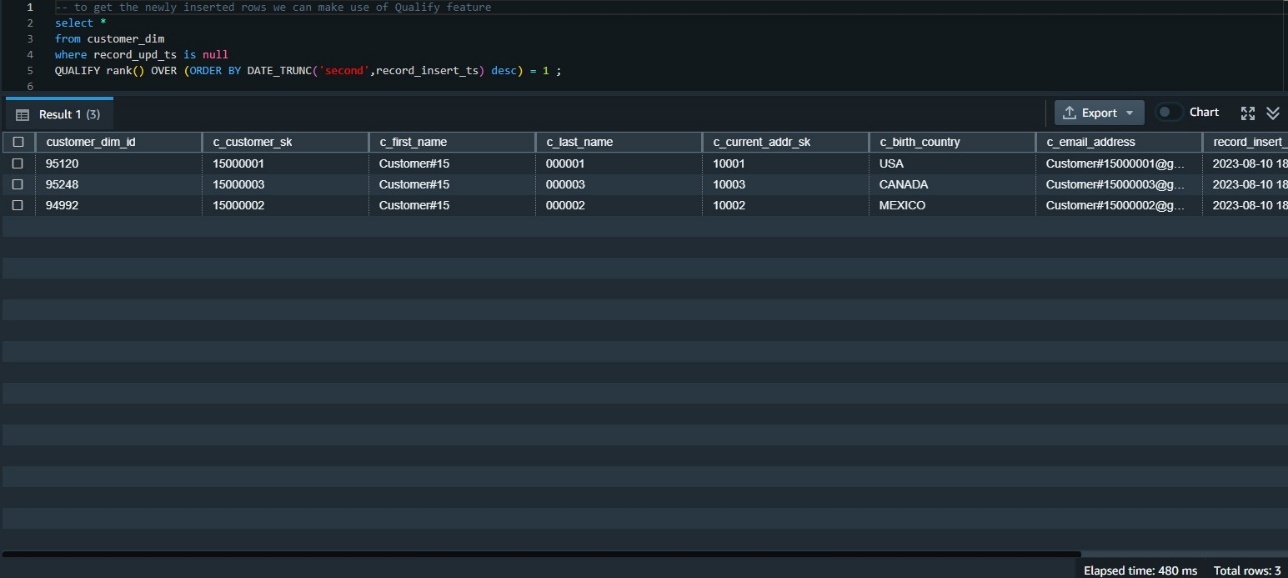
QUALITY 函数消除了对子查询的需求,如以下代码片段所示:
-- to get the newly inserted rows we can make use of Qualify feature
select *
from customer_dim
where record_upd_ts is null
qualify rank() OVER (ORDER BY DATE_TRUNC(‘second’,record_insert_ts) desc) = 1
验证所有数据更改
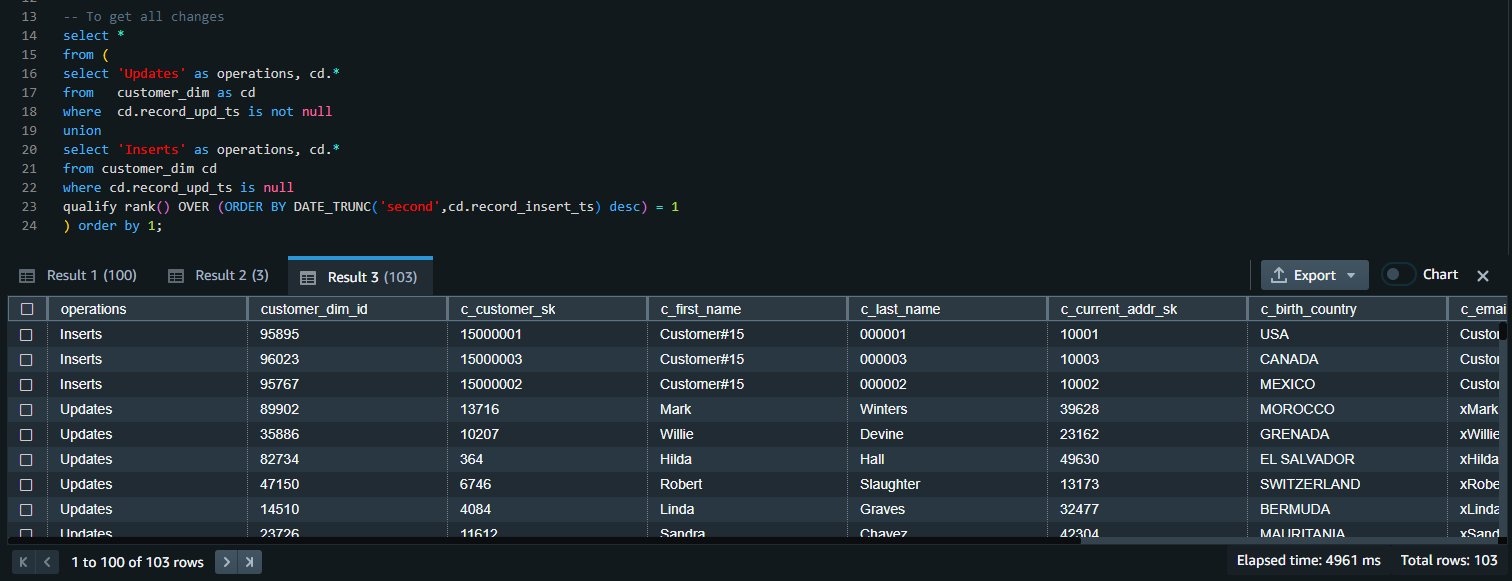
我们可以合并这两个查询的结果来获得所有的插入和更新更改:
-- To get all changes
select *
from (
select 'Updates' as operations, cd.*
from customer_dim as cd
where cd.record_upd_ts is not null
union
select 'Inserts' as operations, cd.*
from customer_dim cd
where cd.record_upd_ts is null
qualify rank() OVER (ORDER BY DATE_TRUNC('second',cd.record_insert_ts) desc) = 1
) order by 1
清理
要清理帖子中使用的资源,请删除您为这篇文章创建的 Redshift 预配置集群或 Redshift Serverless 工作组和命名空间(这也会删除所有创建的对象)。
如果您使用现有的 Redshift 预置集群或 Redshift 无服务器工作组和命名空间,请使用以下代码删除这些对象:
DROP TABLE IF EXISTS customer_dim CASCADE;
DROP TABLE IF EXISTS src_customer CASCADE;
结论
使用多个语句更新或插入数据时,不同操作之间存在不一致的风险。MERGE 操作通过确保所有操作在单个事务中一起执行来降低这种风险。对于从其他数据仓库系统迁移或经常需要将快速变化的数据提取到其 Redshift 仓库中的 Amazon Redshift 客户,MERGE 命令是一种基于现有和新的源数据有条件地从目标表中插入、更新和删除数据的简单方法。
在大多数使用窗口函数的分析查询中,您可能还需要在 WHERE 子句中使用这些窗口函数。但是,这是不允许的,为此,您必须构建一个包含所需窗口函数的子查询,然后在 WHERE 子句中使用父查询中的结果。使用 QUALIT 子句可以消除对子查询的需求,因此简化了 SQL 语句,降低了写入和读取的难度。
我们鼓励您开始使用这些新功能并向我们提供反馈。有关更多详细信息,请参阅
合并
和
资格条款
。
作者简介
 季燕珠
是亚马逊 Redshift 团队的产品经理。她在行业领先的数据产品和平台的产品愿景和策略方面拥有丰富的经验。她在使用网络开发、系统设计、数据库和分布式编程技术构建大量软件产品方面具有出色的技能。在她的个人生活中,燕珠喜欢绘画、摄影和打网球。
季燕珠
是亚马逊 Redshift 团队的产品经理。她在行业领先的数据产品和平台的产品愿景和策略方面拥有丰富的经验。她在使用网络开发、系统设计、数据库和分布式编程技术构建大量软件产品方面具有出色的技能。在她的个人生活中,燕珠喜欢绘画、摄影和打网球。
 艾哈迈德·谢哈塔 是位于多
伦多的亚马逊云科技的高级分析专家解决方案架构师。他在帮助客户实现数据平台现代化方面拥有二十多年的经验。Ahmed 热衷于帮助客户构建高效、高性能和可扩展的分析解决方案。
艾哈迈德·谢哈塔 是位于多
伦多的亚马逊云科技的高级分析专家解决方案架构师。他在帮助客户实现数据平台现代化方面拥有二十多年的经验。Ahmed 热衷于帮助客户构建高效、高性能和可扩展的分析解决方案。
 Ranjan Burman
是 亚马逊云科技 的分析专家解决方案架构师。他专门研究亚马逊 Redshift,帮助客户构建可扩展的分析解决方案。他在不同的数据库和数据仓库技术方面拥有超过 16 年的经验。他热衷于使用云解决方案自动化和解决客户问题。
Ranjan Burman
是 亚马逊云科技 的分析专家解决方案架构师。他专门研究亚马逊 Redshift,帮助客户构建可扩展的分析解决方案。他在不同的数据库和数据仓库技术方面拥有超过 16 年的经验。他热衷于使用云解决方案自动化和解决客户问题。