我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 Redshift 数据 API 与亚马逊 Redshift 无服务器进行交互
作为数据工程师或应用程序开发人员,对于某些用例,您希望与 Redshift Serverless 数据仓库进行交互,以便使用简单的 API 端点加载或查询数据,而无需管理持续连接。使用
这篇文章解释了如何通过
介绍数据 API
Data API 使您能够使用所有类型的传统、云原生和容器化基于无服务器 Web 服务的应用程序和事件驱动的应用程序无缝访问来自 Redshift Serverless 的数据。
下图说明了这种架构。
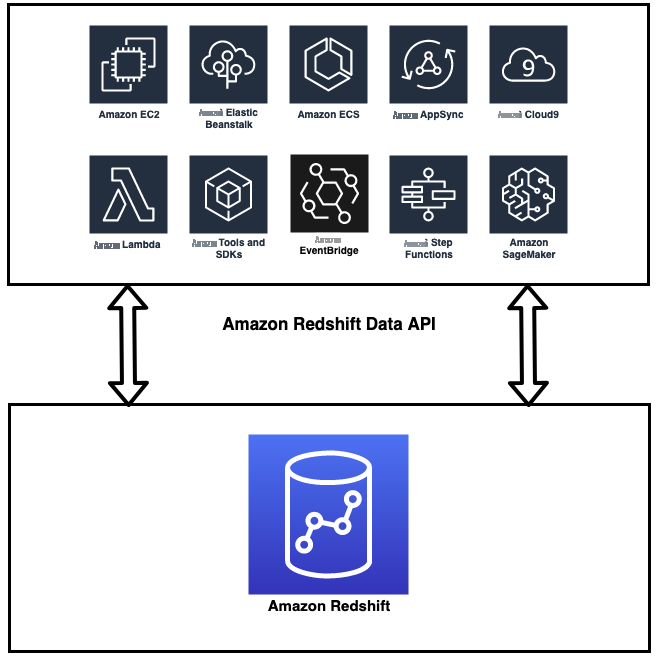
数据 API 简化了
数据 API 无需配置驱动程序和管理数据库连接,从而简化了对 Amazon Redshift 的访问。取而代之的是,你只需调用数据 API 提供的安全 API 端点即可向 Redshift Serverless 运行 SQL 命令。Data API 负责管理数据库连接和缓冲数据。数据 API 是异步的,因此您可以稍后检索结果。您的查询结果将存储 24 小时。数据 API 联合了
对于使用
相关用例
Data API 不能取代 JDBC 和 ODBC 驱动程序,适用于不需要持续连接到无服务器数据仓库的用例。它适用于以下用例:
- 使用 亚马逊云科技 开发工具包支持的任何编程语言从自定义应用程序访问 Amazon Redshift。这使您能够集成基于网络服务的应用程序,使用运行 SQL 语句的 API 访问来自 Amazon Redshift 的数据。例如,你可以通过 JavaScript 运行 SQL。
- 构建无服务器数据处理工作流程。
- 设计异步 Web 仪表板是因为 Data API 允许您运行长时间运行的查询,而不必等待查询完成。
- 运行一次查询并多次检索结果,而不必在 24 小时内再次运行查询。
-
使用 亚马逊云科技 Step Fun ctions 、Lambda 和存储过程构建 ETL 管道。 -
简化了从亚马逊 S
ageMaker 和 Jupyter 笔记本电脑访问亚马逊 Red shift 的过程。 -
使用
亚马逊 EventB ridge 和 L ambda 构建事件驱动型应用程序。 - 调度 SQL 脚本以简化实例化视图的数据加载、卸载和刷新。
数据 API
创建 Redshift 无服务器工作组
如果你尚未创建 Redshift 无服务器数据仓库,或者想要创建一个新的数据仓库,请参阅
mazon
s3ReadonlyAccess 权限。您可以使用
使用数据 API 的先决条件
您必须获得访问数据 API 的授权。亚马逊 Redshift 提供 reds
您还可以创建自己的 IAM 策略,该策略允许访问特定资源,方法是使用
redshiftDataFullA
ccess 作为模板开始。
数据 API 允许您使用您的 IAM 证书或存储在 Secrets Manager 中的密钥访问您的数据库。在这篇文章中,我们使用 IAM 证书。
当您联合您的 IAM 证书以连接到 Amazon Redshift 时,它会自动为正在使用的 IAM 用户创建一个数据库用户。它使用
getCredit
ials API 来获取临时数据库证书。如果您想通过此 API 向用户提供特定的数据库权限,则可以使用标签名为
RedshiftdBrole
s 的 IAM 角色,并使用以冒号分 隔的角色列表。
例如,如果要分配销售和分析师 等
ales: an
alyst。
使用 亚马逊云科技 CLI 中的数据 API
您可以使用 亚马逊云科技 CLI 中的数据 API 与 Redshift 无服务器工作组和命名空间进行交互。有关配置 亚马逊云科技 CLI 的说明,请参阅
s redshift-serverless )是 AWS
CLI
ft-data )提供了命令行接口,允许您与 Redshift S
erverless 中的数据库进行交互。
您可以使用以下命令调 用
帮助
:
下表显示了 Data API CLI 中可用的不同命令。
| Command | Description |
list-databases
|
Lists the databases in a workgroup. |
list-schemas
|
Lists the schemas in a database. You can filter this by a matching schema pattern. |
list-tables
|
Lists the tables in a database. You can filter the tables list by a schema name pattern, a matching table name pattern, or a combination of both. |
describe-table
|
Describes the detailed information about a table including column metadata. |
execute-statement
|
Runs a SQL statement, which can be SELECT, DML, DDL, COPY, or UNLOAD. |
batch-execute-statement
|
Runs multiple SQL statements in a batch as a part of single transaction. The statements can be SELECT, DML, DDL, COPY, or UNLOAD. |
cancel-statement
|
Cancels a running query. To be canceled, a query must not be in the FINISHED or FAILED state. |
describe-statement
|
Describes the details of a specific SQL statement run. The information includes when the query started, when it finished, the number of rows processed, and the SQL statement. |
list-statements
|
Lists the SQL statements in the last 24 hours. By default, only finished statements are shown. |
get-statement-result
|
Fetches the temporarily cached result of the query. The result set contains the complete result set and the column metadata. You can paginate through a set of records to retrieve the entire result as needed. |
如果你想获得有关特定命令的帮助,请运行以下命令:
现在我们来看看如何使用这些命令。
列出数据库
大多数组织在其亚马逊 Redshift 工作组中使用单一数据库。您可以使用以下命令列出无服务器端点中的数据库。此操作需要您连接到数据库,因此需要数据库凭据。
列出架构
与列出数据库类似,您可以使用
list-
schemas 命令列出架构:
如果您有多个与
演示
相匹配的架构 (
dem
o
、d emo2
、demo3
等),则可以选择提供一种模式来筛选与该模式匹配的结果:
列出表格
数据 API 提供了一个简单的命令,
即列表表
,用于列出数据库中的表。一个架构中可能有数千个表;Data API 允许您对结果集进行分页或通过提供筛选条件来筛选表列表。
您可以使用
表模式
在架构中进行搜索 ;例如,您可以按表名前缀筛选数据库中所有架构的表列表,或者使用架构模式以特定的架构模式筛选表列表。
以下是同时使用两者的代码示例:
运行 SQL 命令
您可以使用数据 API 运行 Amazon Redshift 的 SELECT、DML、DDL、COPY 或卸载命令。如果您想在查询运行后向 EventBridge 发送
事件,则可以选择指定 —with-
event 选项,然后 Data API 将发送带有
quer
yID 和最终运行状态的事件。
创建架构
让我们使用 Data API 来看看如何创建架构。以下命令允许您在数据库中创建架构。如果您已经预先创建了架构,则不必运行此 SQL。必须指定
—-sql 才能指定 SQ
L 命令。
以下显示了
执行语句的示例输出:
我们将在本文后面讨论如何检查使用
执行语句运行的 SQL 的状态。
创建表
您可以使用以下命令通过 CLI 创建表:
加载样本数据
使用 COPY 命令可以将批量数据加载到 Amazon Redshift 中的表中。您可以使用以下命令将数据加载到我们之前创建的表中:
检索数据
以下查询使用了我们之前创建的表:
以下显示了示例输出:
您可以使用作为
执行语句输出收到的语句 ID 来获取结果。
检查语句的状态
你可以使用
描述语句来检查你的陈述的状态。
d
escribe-stat
ement 的输出 提供了其他详细信息,例如 PID、查询时长、结果集的行数和大小,以及 Amazon Redshift 给出的查询 ID。你必须指定运行
执行语句命令时得到的语句 ID
。参见以下命令:
以下是示例输出:
语句的状态可以是 “开始”、“完成”、“中止” 或 “失败”。
运行带参数的 SQL 语句
您可以运行带参数的 SQL 语句。以下示例在 SQL 中使用两个使用名称-值对指定的命名参数:
描述语句
返回
queryParameters 以及 queryString。
您可以将参数列表中的名称-值对映射到 SQL 文本中的一个或多个参数,并且名称-值参数可以按随机顺序排列。您不能将 NULL 值或零长度值指定为参数。
取消正在运行的语句
如果您的查询仍在运行,则可以使用
取消语句 取消 S
QL 查询。参见以下命令:
从您的查询中获取结果
你可以使用 get-statement
-result 来获取
查询结果。查询结果将存储 24 小时。参见以下命令:
结果的输出包含元数据,例如提取的记录数、列元数据和分页标记。
运行多条 SQL 语句
您可以使用数据 API 在一次事务中为 Amazon Redshift 运行多个 SELECT、DML、DDL、COPY 或 UNLOAD 命令。
批处理执行语句使
您 能够创建表并运行多个 COPY 命令,或者创建临时表作为报告系统的一部分,并对该临时表运行查询。参见以下代码:
多
语句查询的 des
cribe-statement 显示所有子语句的状态:
{
在前面的示例中,我们有两条 SQL 语句,因此输出包括 SQL 语句的 ID,分别为 23d99d7f-fd13-4686-92c8-e2c279715c 21:1 和
批处理 SQL 语句的每个子语句都有一个状态,并且批处理语句的状态使用最后一个子语句的状态进行更新。例如,如果最后一条语句的状态为 FAILED,则批处理语句的状态显示为 FAILED。
23d99d7f-fd13-4686-92c8-e2c279715c 21
:2。
您可以单独获取每条语句的查询结果。在我们的示例中,第一条语句是用于创建临时表的 SQL 语句,因此第一条语句没有结果可供检索。您可以通过提供子语句的语句 ID 来检索第二条语句的结果集:
将数据 API 与密钥管理器一起使用
数据 API 允许您使用存储在密钥管理器中的数据库凭据。您可以将密钥类型创建为其他类型的密钥,然后指定用户名和密码。请注意,你无法选择 Amazon Redshift 集群,因为 Redshift 无服务器与集群不同。
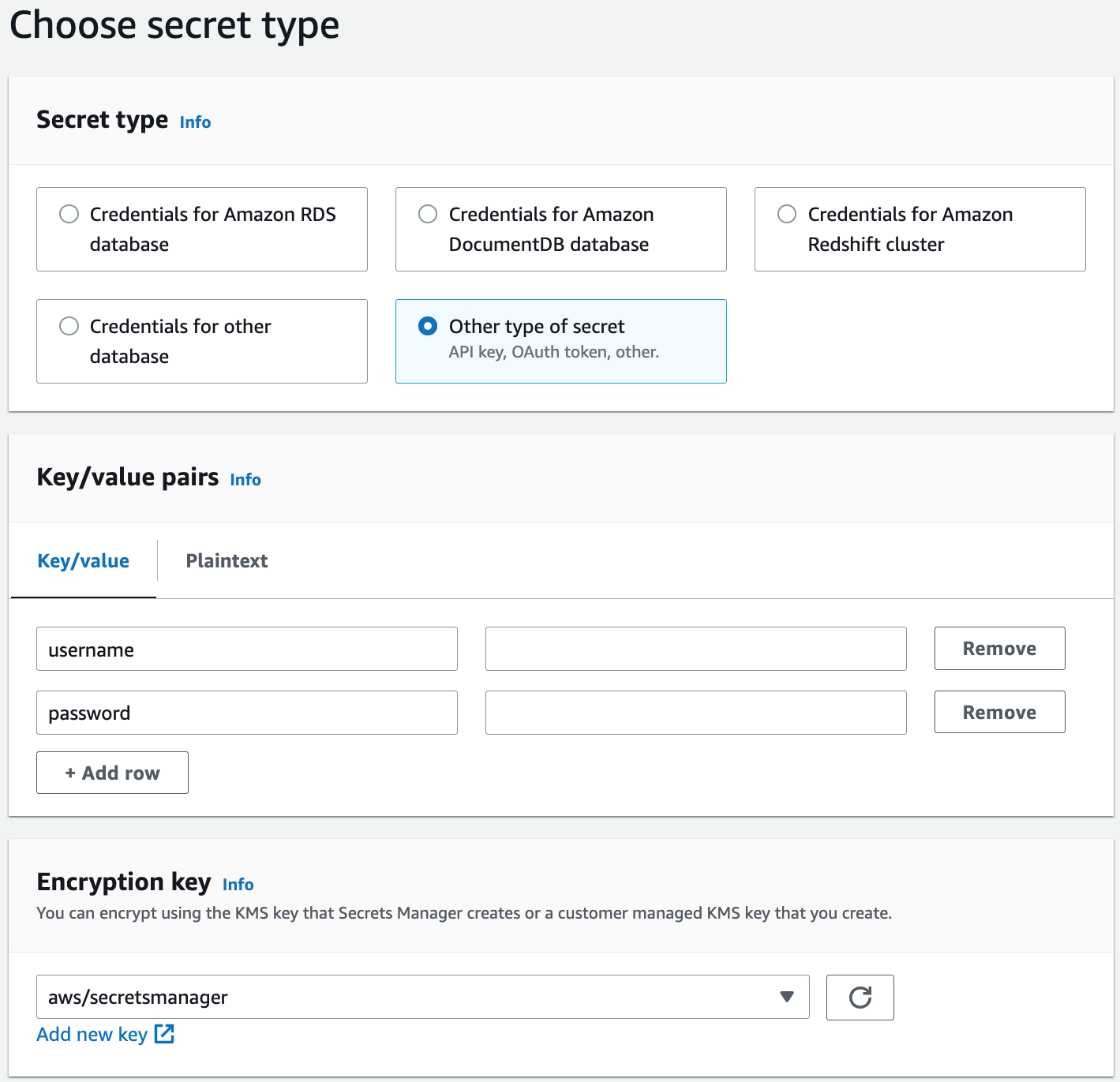
假设你以 Defa
ul
Twg 的名义为证书创建了一个密钥。你可以使用
secret-arn
参数来传递你的密钥,如下所示:
导出数据
Amazon Redshift 允许您使用带有 SELECT 语句的
如果要在 UN
LOAD 中使用多个语句或将 UNLOAD 与其他 SQL 语句结合使用,则可以使用批处理执行
语句。
使用 亚马逊云科技 开发工具包中的数据 API
您可以在 亚马逊云科技 开发工具包支持的任何编程语言中使用数据 API。在这篇文章中,我们使用适用于 Python 的 亚马逊云科技 开发工具包 (Boto3) 作为示例来说明数据 API 的功能。
我们首先导入 Boto3 包并建立一个会话:
获取客户端对象
你可以从
boto3.Session 对象中使用 Redshift
Data 创建客户端 对象:
如果你不想创建会话,你的客户端就像下面的代码一样简单:
运行语句
以下示例代码使用密钥管理器密钥运行语句。在这篇文章中,我们使用之前创建的表。您可以在 SQL 参数中使用 DDL、DML、COPY 和 UNLOAD:
正如我们前面所讨论的,运行查询是异步的;运行语句会返回
executeStatementOut
put ,其中包括语句 ID。
如果要在语句完成后
将事件发布到 EventBridge,则可以使用附加参数,将 Event
设置为 true:
描述陈述
你可以使用 desc
ribe_stat
ement 来查找查询的状态和检索到的记录数:
从您的查询中获取结果
如果您的查询已完成,则可以使用
get_statement_resul
t 来检索查询结果:
get_statement_resul
t 命令返回一个 JSON 对象,其中包含结果和实际结果集的元数据。如果要以用户友好的格式显示结果,则可能需要处理数据以格式化结果。
获取和格式化结果
在这篇文章中,我们演示了如何使用 Pandas 框架格式化结果。
post_process 函数处理
元数据和结果以填充 DataFrame。查询函数从 Amazon Redshift 集群中的数据库中检索结果。参见以下代码:
在这篇文章中,我们演示了在 Python 中使用数据 API 和 Redshift 无服务器。但是,您可以将数据 API 与 亚马逊云科技 开发工具包支持的其他编程语言一起使用。你可以阅读罗氏如何
最佳实践
在使用 Data API 时,我们建议采用以下最佳做法:
-
将您的 IAM 证书联合到数据库以连接亚马逊 Redshift。
Redshift 无服务器允许用户使用 getCreditials 获取临时数据库证书。Redshift 无服务器将访问范围限定为特定 IAM 用户,数据库用户是自动创建的。 - 如果您不希望用户使用临时证书,请使用自定义策略在生产环境中提供对数据 API 的精细访问。在此类用例中,你必须使用密钥管理器来管理你的证书。
- 不要从您的客户端检索大量数据,并使用 UNLOAD 命令将查询结果导出到 Amazon S3。使用数据 API,您只能检索 100 MB 的数据。
- 不要忘记在 24 小时内检索结果;结果仅存储 24 小时。
结论
在这篇文章中,我们介绍了如何在 Redshift 无服务器中使用数据 API。我们还演示了如何使用 Amazon Redshift CLI 中的数据 API,以及如何使用 亚马逊云科技 开发工具包使用 Python。此外,我们还讨论了使用数据 API 的最佳实践。
要了解更多信息,请参阅
作者简介

 彭飞是一名软件开发工程师
,在亚马逊 Redshift 团队 工作。
彭飞是一名软件开发工程师
,在亚马逊 Redshift 团队 工作。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。