我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
在你的 亚马逊云科技 Glue Studio 视觉 ETL 作业中使用 亚马逊云科技 Glue DataBrew 食谱
在 DataBrew 中, 配方 是一组数据转换步骤,您可以在其直观的可视界面中以交互方式编写这些步骤。在这篇文章中,您将看到如何在 DataBrew 中使用构建配方,然后将其作为 亚马逊云科技 Glue Studio 可视化 ETL 作业的一部分进行应用。
现有 DataBrew 用户也将从这种集成中受益——除了能够使用高级任务配置和最新 亚马逊云科技 Glue 引擎版本外,您现在还可以在更大的可视化工作流程中使用 亚马逊云科技 Glue Studio 提供的所有其他组件来运行配方。
这种集成为这两种工具的现有用户带来了明显的好处:
- 您可以在 亚马逊云科技 Glue Studio 中集中查看端到端的整个 ETL 图表
- 您可以以交互方式定义配方,在 DataBrew 控制台上查看值、统计数据和分布,然后在 亚马逊云科技 Glue Studio 可视化作业中重复使用经过测试和版本控制的处理逻辑
- 您可以在 亚马逊云科技 Glue ETL 任务中编排多个 DataBrew 配方,甚至可以使用 亚马逊云科技 Glue 工作流程编排多个任务
- DataBrew 配方现在可以使用 亚马逊云科技 Glue 作业功能,例如用于增量数据处理的书签、自动重试、自动扩展或对小文件进行分组以提高效率
解决方案概述
在我们的虚构用例中,要求清理为这篇文章创建的合成医疗索赔数据集,该数据集故意引入了一些数据质量问题,以演示 DataBrew 在数据准备方面的能力。然后,在使用来自单独来源的有关相应医疗提供者的一些相关详细信息来丰富目录后,将索赔数据纳入目录(因此分析师可以看见)。
该解决方案包括一个 亚马逊云科技 Glue Studio 可视化作业,该作业分别读取两个包含索赔和提供者的 CSV 文件。该任务采用第一个方法来解决质量问题,从第二个中选择列,合并两个数据集,最后将结果
创建 DataBrew 配方
首先注册索赔文件的数据存储。这将允许你使用实际数据在其交互式编辑器中构建配方,这样你就可以在定义转换时评估转换结果。
-
使用以下链接下载索赔 CSV 文件:
alabama_claims_data_Jun2023.csv 。 - 在 DataBrew 控制台上,选择导航窗格 中的 数据集 ,然后选择 连接新 数据集。
- 选择 文件上传 选项 。
-
在
数据集名称
中 ,输入
阿拉巴马州的索赔。 -
在 “选择要上传的文件
” 中 ,选择您刚才在计算机上下载的文件。
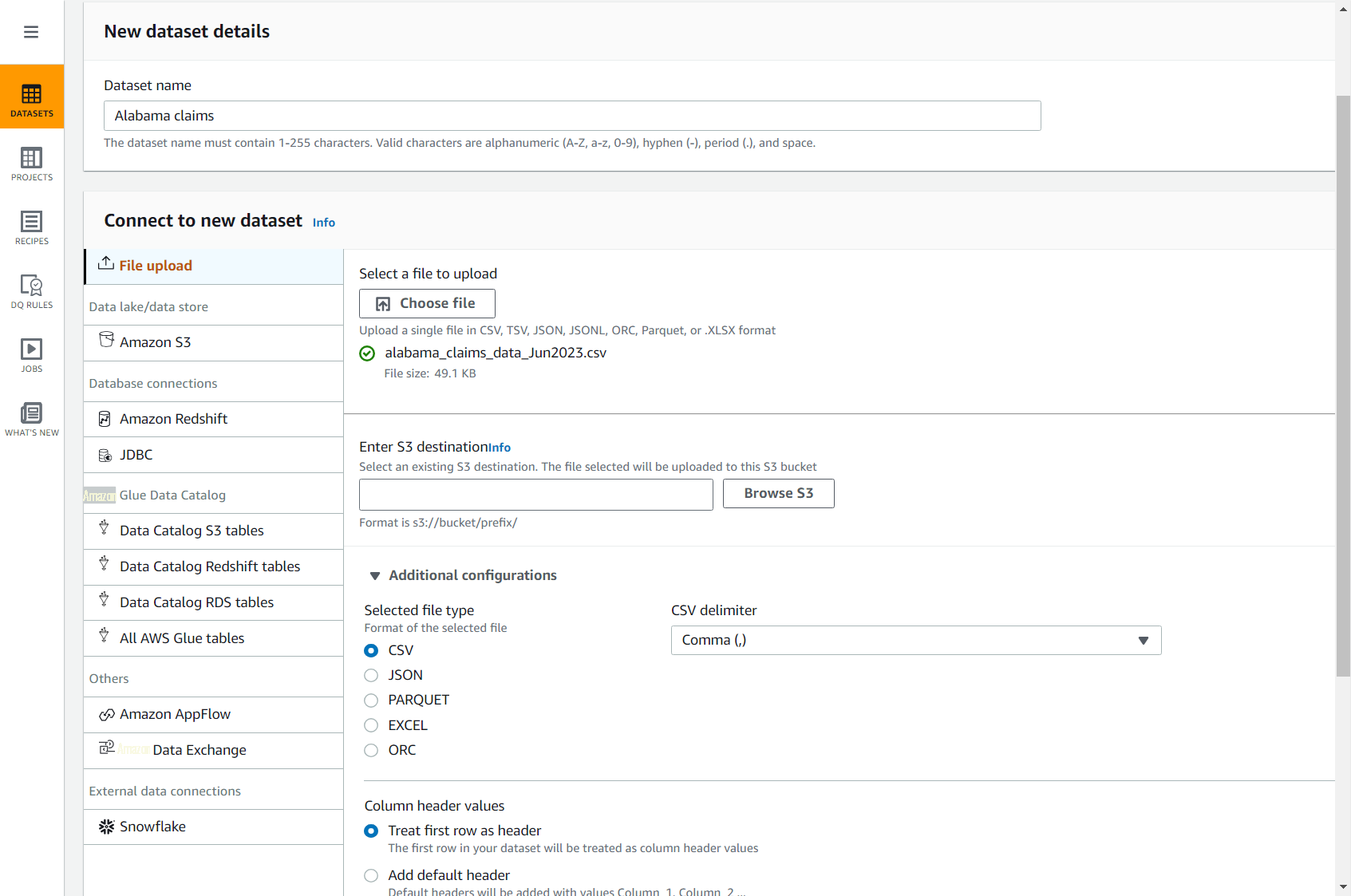
- 对于 输入 S3 目的地 ,输入或浏览到您的账户和区域中的存储桶。
- 默认情况下,保留其余选项(CSV 以逗号和标题分隔),然后完成数据集的创建。
- 在导航窗格 中选择 “ 项目 ”,然后选择 “ 创建项目 ” 。
-
在
项目名称中
,将其命名为 C
laimsCleanup。 -
在
食谱详细信息
下 ,在
附加食谱中 ,选择
创建新
食谱
,将其命名为 C
laimsCleanup-Recipe ,然后选择您刚刚创建的阿拉巴马州索赔数据集。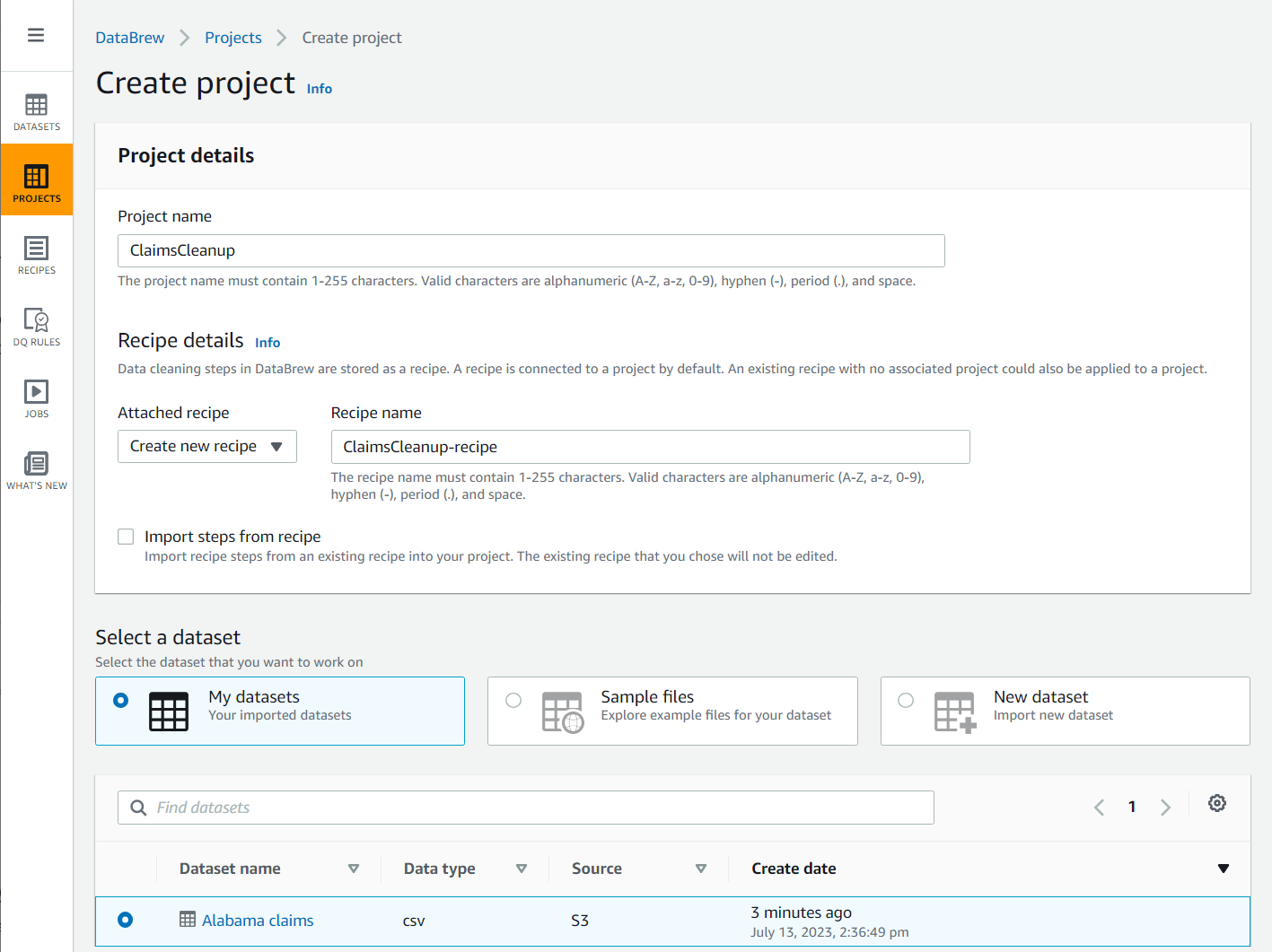
-
选择
适合 DataBrew 的 角色 或创建一个新角色,然后完成项目创建。
这将使用可配置的数据子集创建会话。初始化会话后,您会注意到某些单元格的值无效或缺失。
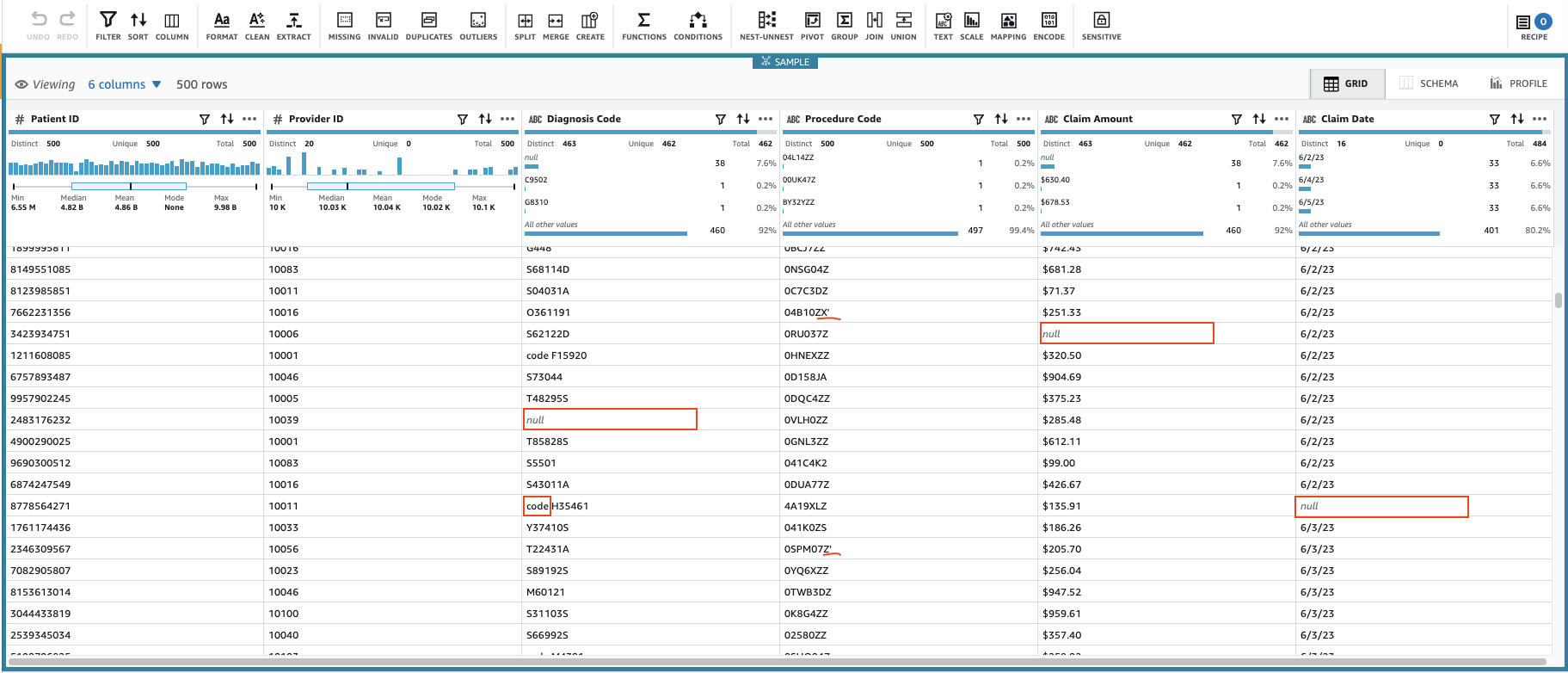
除了 “
诊断码
” 、“
索赔金额 ” 和 “ 索赔
日期
” 列中缺失的值外 ,数据中的某些值还有一些额外的字符:
诊断代码
值有时以 “代码” 为前缀(包括空格),
程序代码
值后面有时带有单引号。
索赔金额
值可能会用于某些计算,因此请转换为数字,
索赔数据
应转换为日期类型。
现在我们已经确定了需要解决的数据质量问题,我们需要决定如何处理每个案例。
您可以通过多种方式添加食谱步骤,包括使用列快捷菜单、顶部的工具栏或食谱摘要。使用最后一种方法,你可以搜索指定的步骤类型来复制本文中创建的食谱。
索赔金额 对于此用例至关重要,决定删除此类行。
- 添加 “ 删除缺失值” 步骤 。
- 在 来源列中 ,选择 索赔金额 。
-
保留默认操作 “
删除缺失值的行
”, 然后选择 “
应用
” 进行保存。
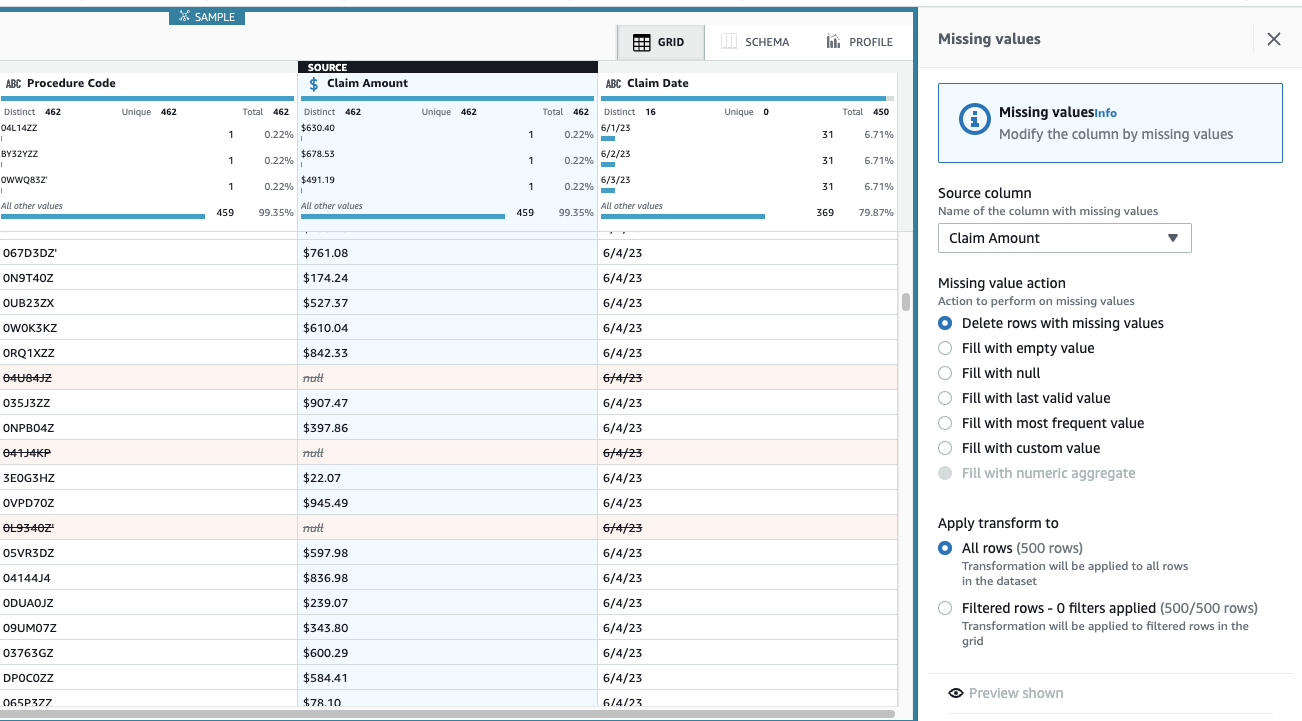
视图现已更新,以反映步骤应用程序,缺失金额的行已不复存在。
诊断代码 可以为空,因此可以接受,但就 索赔日期 而言 ,我们希望有一个合理的估计。数据中的行按时间顺序排序,因此您可以使用前面各行的预览有效值来估算缺失的日期。假设每天都有索赔,如果这是当天第一份缺少日期的索赔,则最大的错误是将其分配给预览日;出于举例说明的目的,让我们认为这种潜在错误是可以接受的。
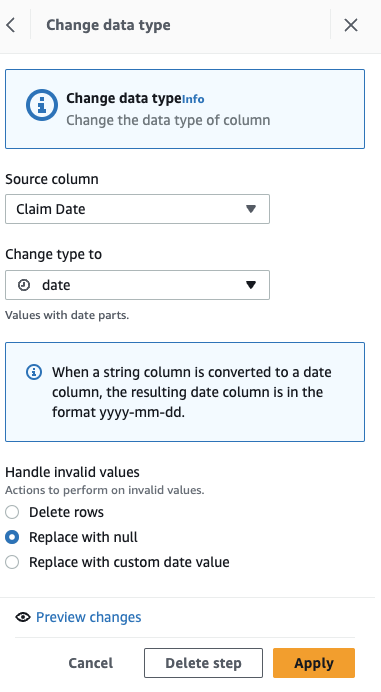
首先,将列从字符串转换为日期类型。
- 添加步骤 更改类型 。
-
选择
索赔日期
作为列,选择
日期
作为类型,然后选择
申请
。
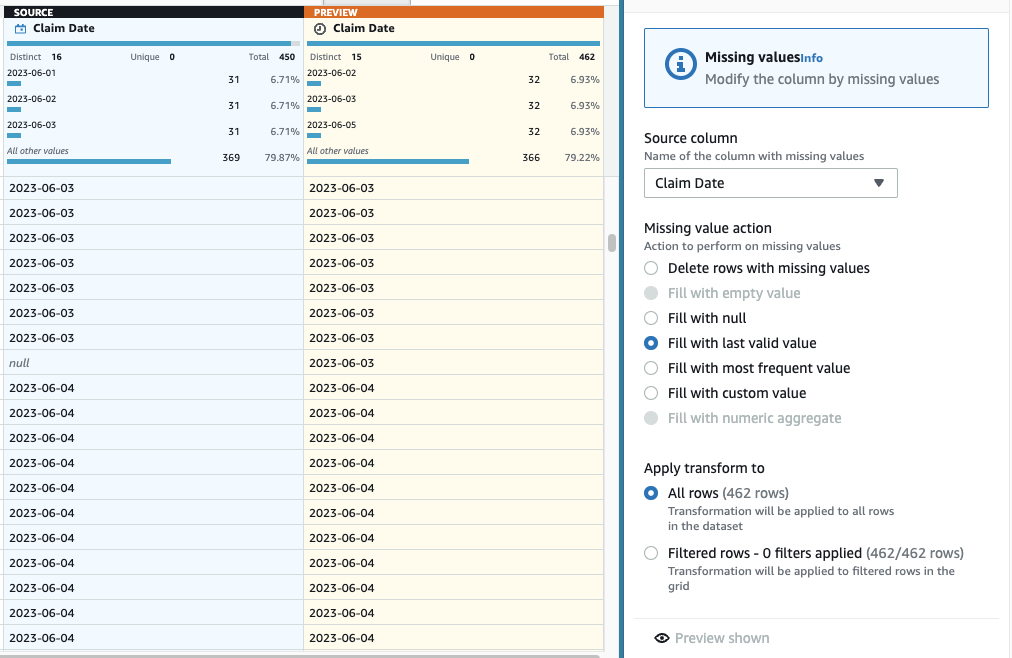
- 现在要对缺失日期进行补充,请添加 填充或估 算缺失值步骤。
- 选择 “填写最后一个有效值” 作为操作,然后选择 “ 索赔日期 ” 作为来源。
-
选择 “
预览更改
” 以对其进行验证,然后选择 “
应用
” 以保存该步骤。
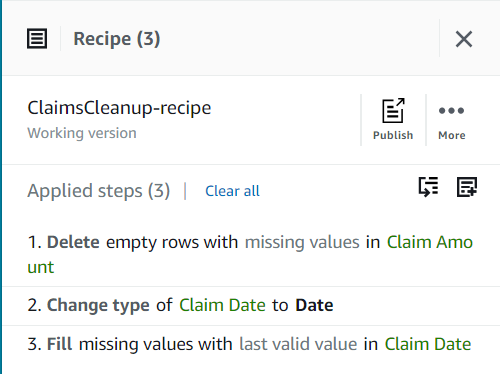
到目前为止,你的食谱应该有三个步骤,如以下屏幕截图所示。
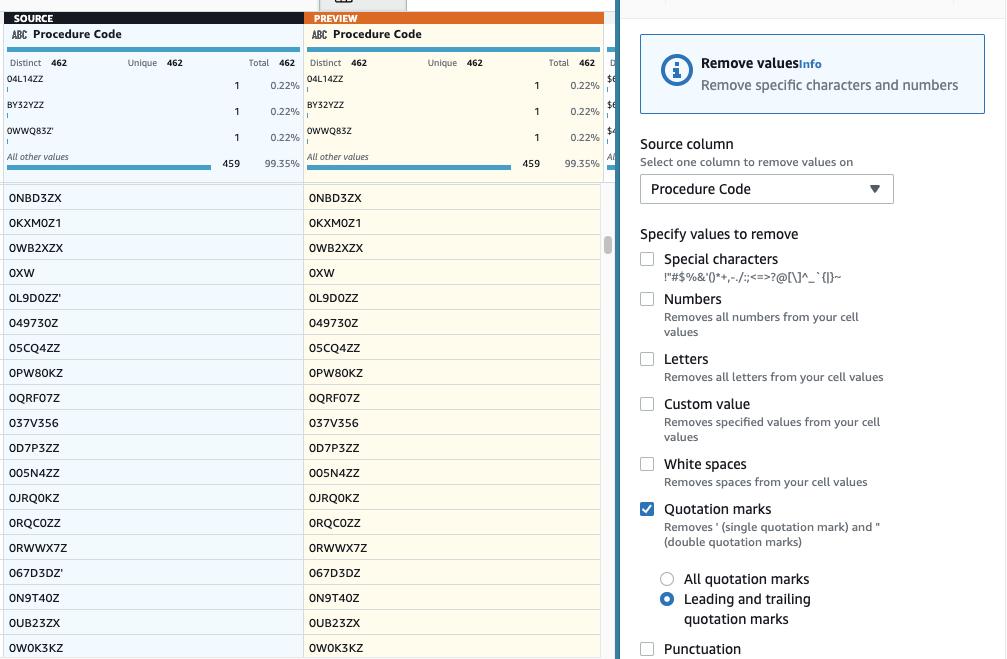
- 接下来,添加 删除引号 步骤 。
- 选择 “ 过程代码 ” 列,然后选择 前导和尾部引号 。
-
预览以验证其是否具有所需的效果并应用新步骤。
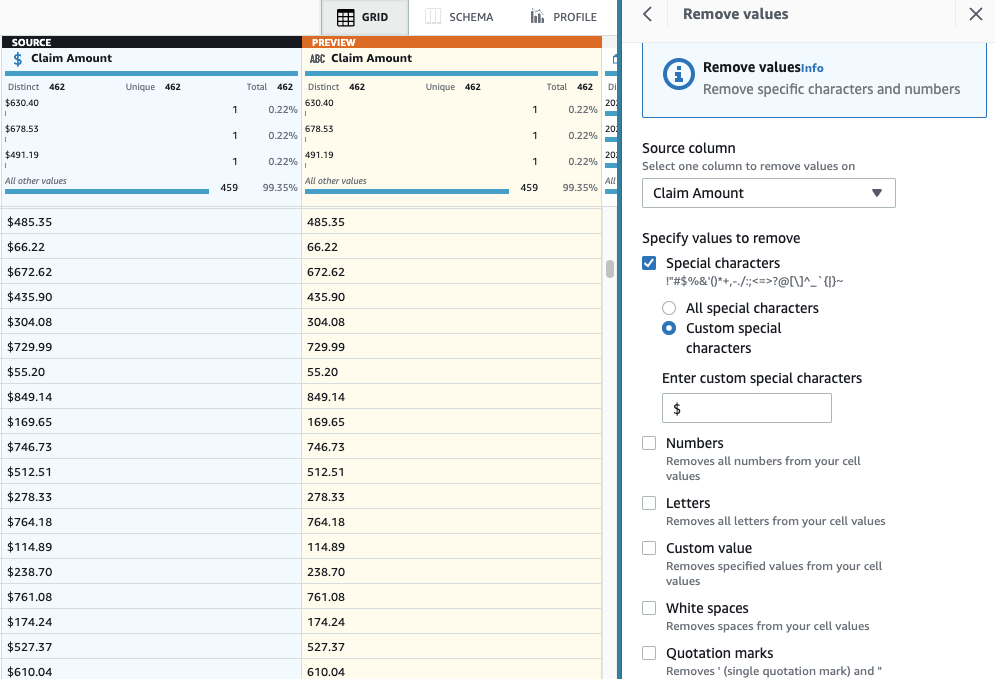
- 添加 “ 删除特殊字符 ” 步骤 。
-
选择 “
索赔金额
” 列,更具体地说,选择 “
自定义特殊字符
”, 然后在 “
输入自定义特殊字符
” 中输入
$。
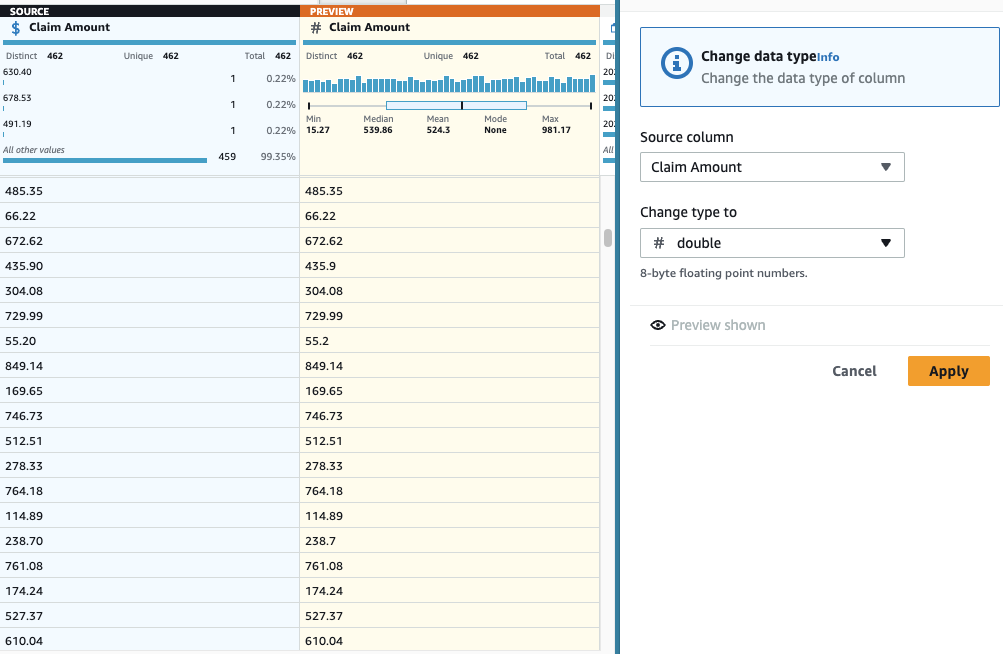
-
在
索赔金额
列中添加
更改类型
步骤, 然后选择
双精
度 作为类型。
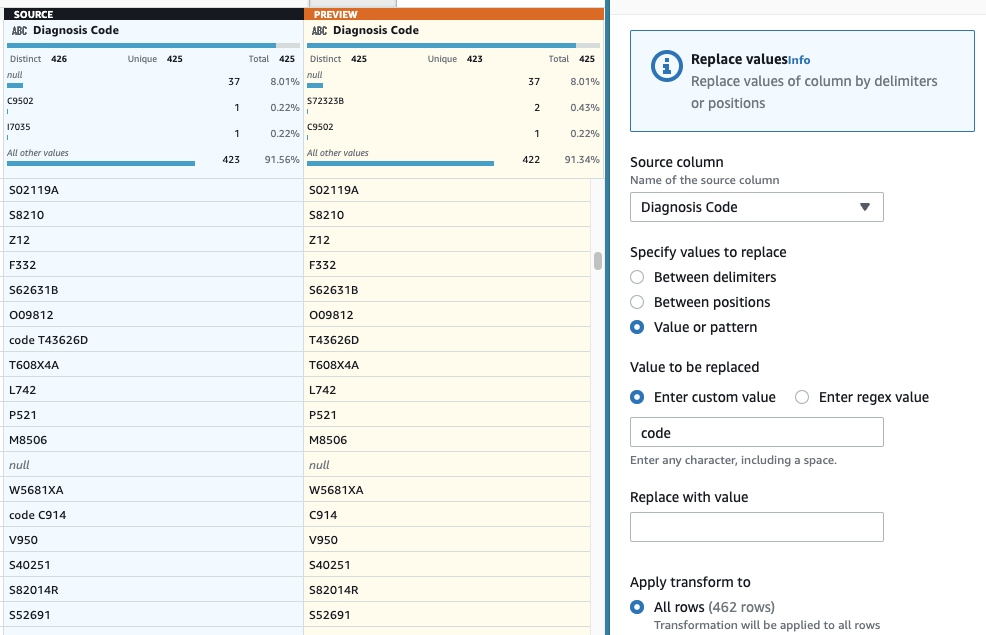
- 最后一步,要删除多余的 “代码” 前缀,请添加 替换值或模式 步骤。
-
选择 “
诊断代码
” 列 ,然后
在 “输入自定义值
” 中输入
代码(末尾带有空格)。
现在,您已经解决了样本中发现的所有数据质量问题,请将该项目作为配方发布。
-
在 “
食谱
” 窗格中选择 “
发布
”,输入可选描述,然后完成发布。
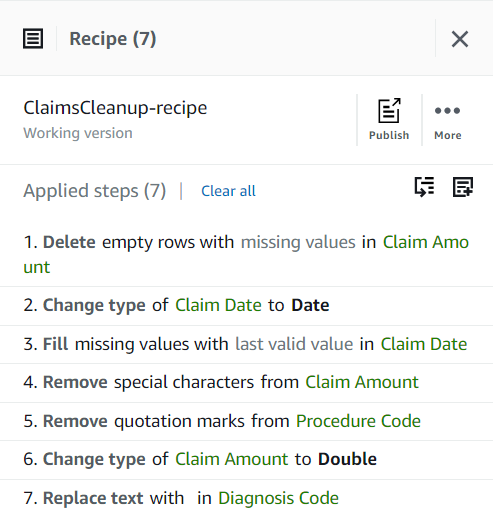
每次发布时,它都会创建食谱的不同版本。稍后,您将能够选择使用哪个版本的食谱。
在 亚马逊云科技 Glue Studio 中创建可视化 ETL 作业
接下来,创建使用该配方的作业。完成以下步骤:
- 在 亚马逊云科技 Glue Studio 控制台上,在导航窗格 中选择 Visual ETL 。
- 选择 带有空白画布的 V isual 并创建可视化作业。
- 在作业的顶部,将 “无标题职位” 替换为你选择的名称。
-
在
作业详细信息
选项卡上,指定作业将使用的角色。
这必须是适用 , 具有访问 Amazon S3 和 亚马逊云科技 Glue 数据目录的权限。请注意,之前用于 DataBrew 的角色不能用于运行作业,因此不会在此处的 IAM 角色 下拉菜单中列出。于 亚马逊云科技 Glue 的 亚马逊云科技 身份和访问管理 (IAM) 角色
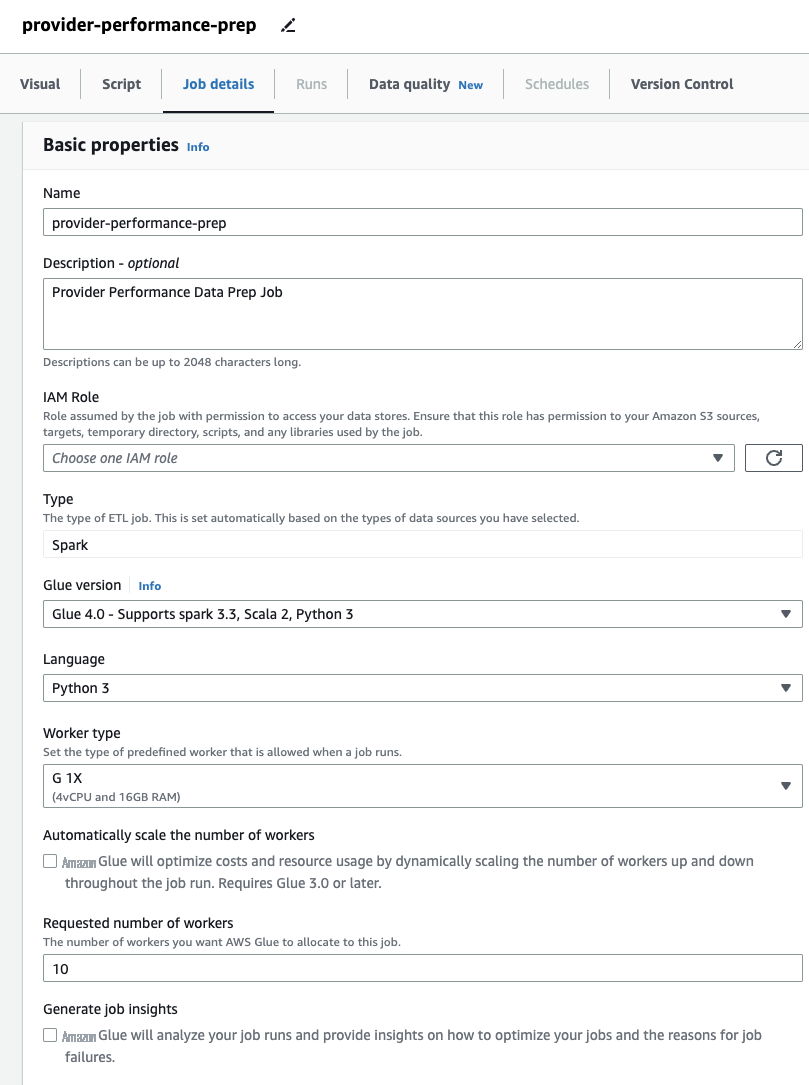
如果您之前只使用过 DataBrew 任务,请注意,在 亚马逊云科技 Glue Studio 中,您可以选择性能和成本设置,包括工作人员规模、自动扩展和 灵活执行 ,也可以使用亚马逊云科技 Glue 4.0 最新运行时并受益于它带来的显著性能改进。对于这项工作,你可以使用默认设置,但为了节俭起见,可以减少要求的工作人员人数。在这个例子中,两个工人就可以了。 -
在 “
可视
” 选项卡上,添加 S3 源并将其命名为 “
提供者” 。 -
对于
S3 网址
,请输入
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv。
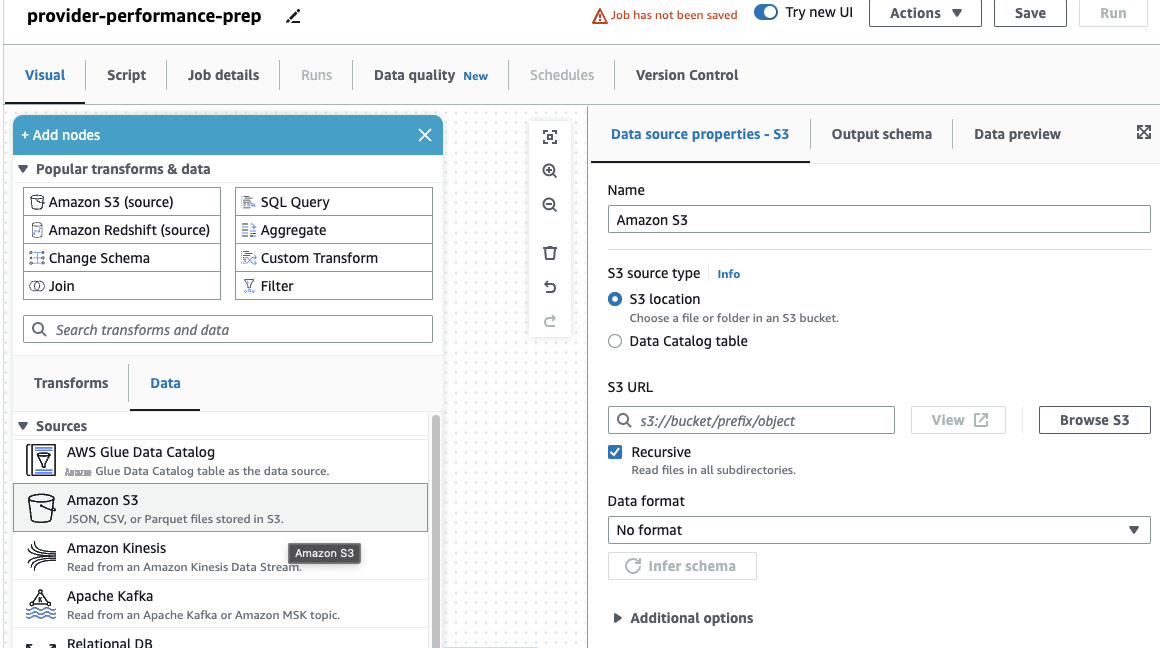
-
选择格式为
CSV
, 然后选择
推断架构
。
现在,该架构使用文件头列在 “ 输出架构 ” 选项卡上。
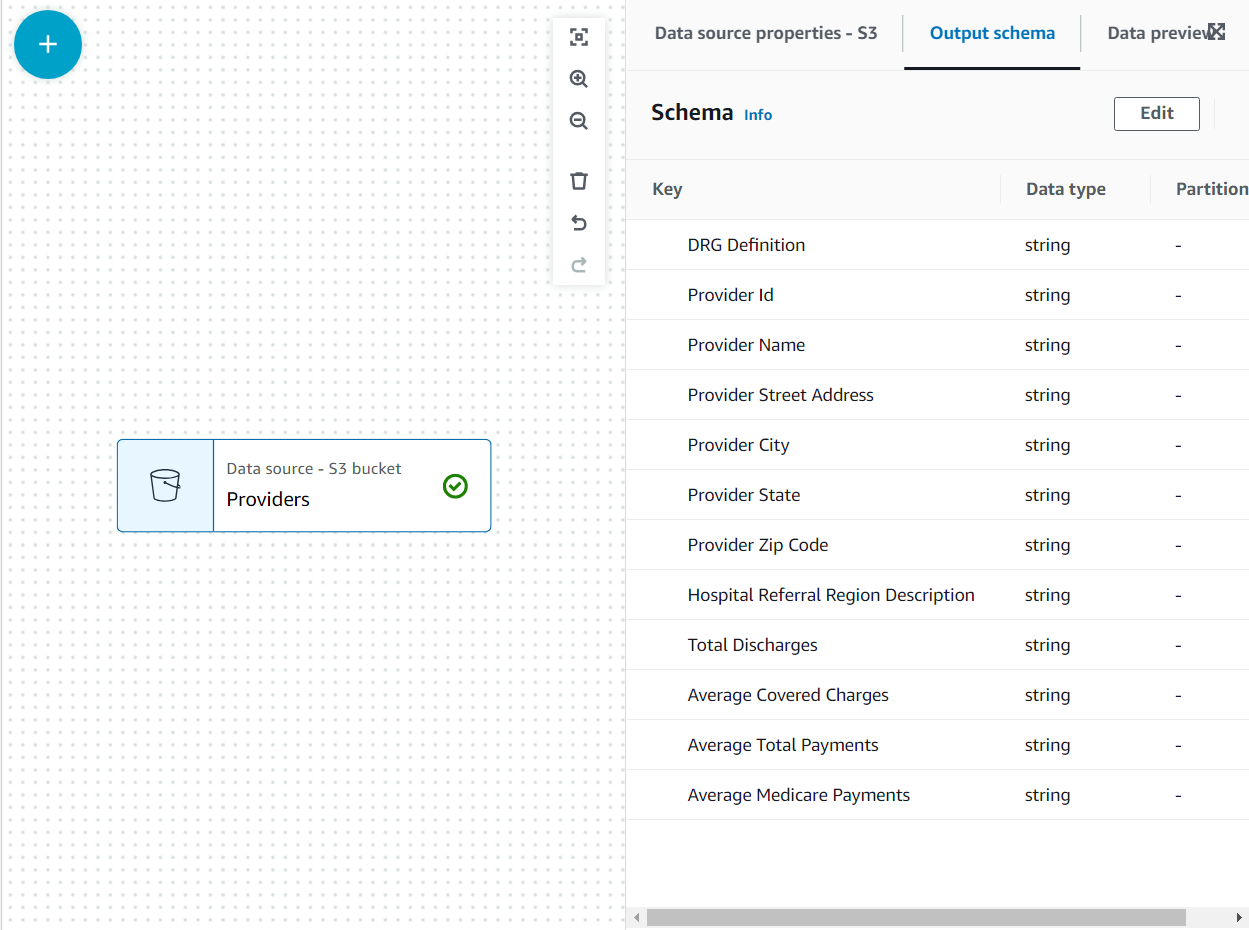
在此用例中,决定并非需要提供者数据集中的所有列,因此我们可以丢弃其余列。
- 选择 Pro v iders 节点后,添加 Drop Field s 转换(如果您没有选择父节点,则不会有父节点;在这种情况下,请手动分配节点父节点)。
-
选择
提供商邮政编码
后面的所有字段 。
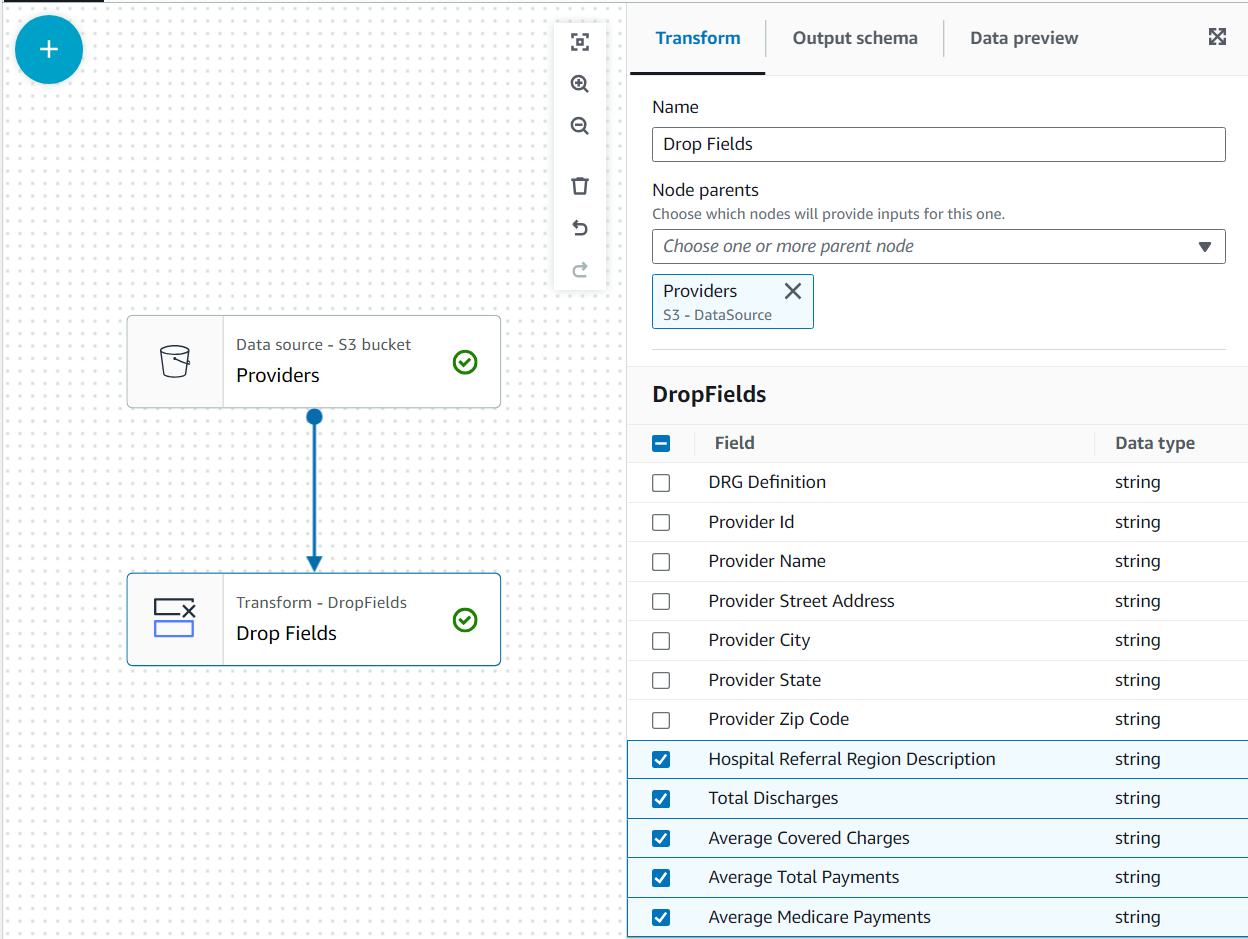
稍后,将使用提供商将这些数据与阿拉巴马州的索赔相结合;但是,第二个数据集没有指定州。我们可以利用数据知识通过筛选我们真正需要的数据来优化联接。
- 将 F ilter 变换添加为 Drop Fields 的子项 。
-
将其命名为
阿拉巴马州的提供商, 并添加一个条件,即该州必须与AL匹配 。
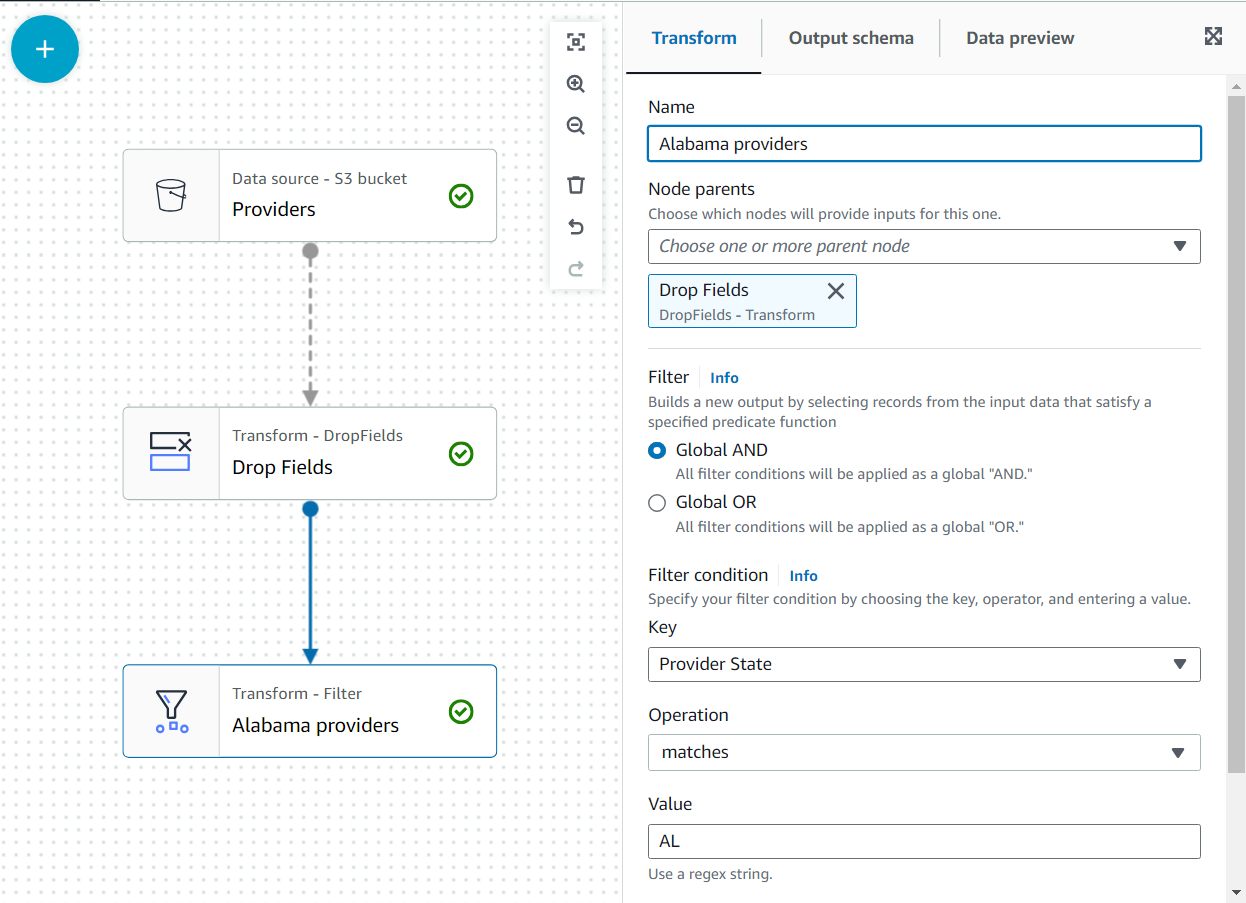
-
添加第二个来源(新的 S3 来源),并将其命名为
阿拉巴马州声称。 - 要输入 S3 URL ,请在单独的浏览器选项卡上打开 DataBrew,在导航窗格中选择数据集,然后在表格上复制 阿拉巴马州索赔 表中显示的位置 (复制以 s3://开头的文本,而不是关联的 http 链接)。然后返回可视化作业,将其粘贴为 S3 URL ;如果正确,您将在 输出架构 选项卡中看到列出的数据字段。
- 选择 CSV 格式并像使用其他来源一样推断架构。
-
作为该源的子项,在 “
添加节点
” 菜单中搜索
配方, 然后选择 “ 数据准备配方 ” 。
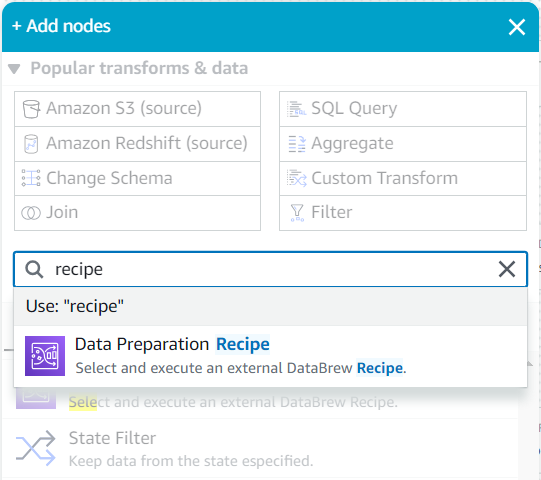
-
在这个新节点的属性中,为其命名 C
laim cleanup recipe, 然后选择你之前发布的配方和版本。 -
您可以在此处查看配方步骤,并在需要时使用指向 DataBrew 的链接进行更改。
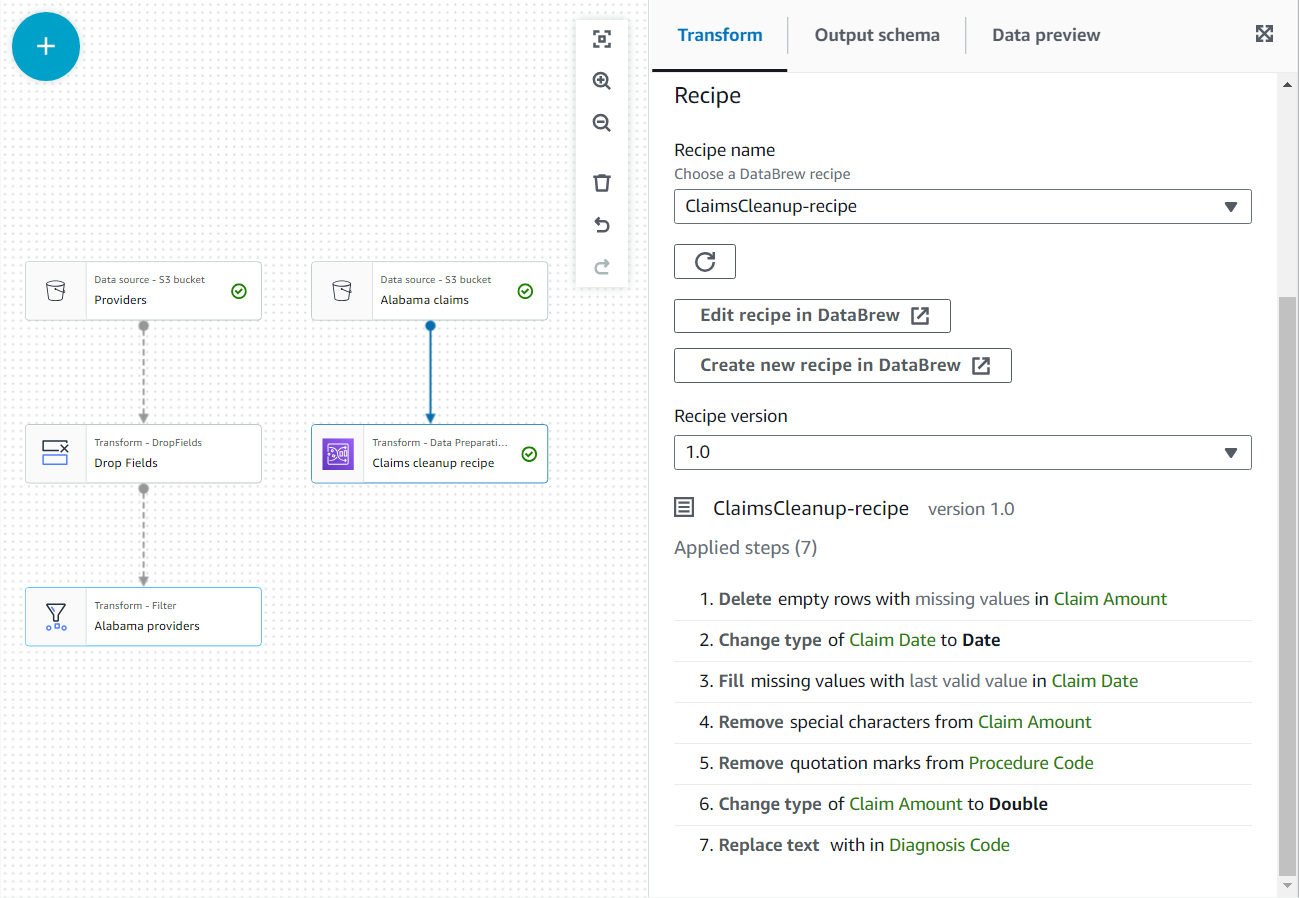
- 添加一个 Join 节点并选择 阿拉巴马州提供商 和 索赔清理配方 作为父节点。
- 添加一个等于两个来源提供商 ID 的连接条件。
- 最后一步,添加一个 S3 节点作为目标(注意搜索时列出的第一个是源节点;确保选择列为目标的版本)。
- 在节点配置中,保留默认格式 JSON 并输入任务角色有权写入的 S3 URL。
此外,在目录中将数据输出作为表格提供。
- 在 数据目录更新选项 部分中,选择第二个选项在 数据目录中 创建表,然后在后续运行时更新架构并添加新分区 ,然后选择您有权创建表的数据库。
-
将
alabama_claim s 指定为名称,然后选择 C laim Dat e 作为分区键(这是为了说明目的;如果以后不添加更多数据,像这样的小表实际上并不需要分区)。
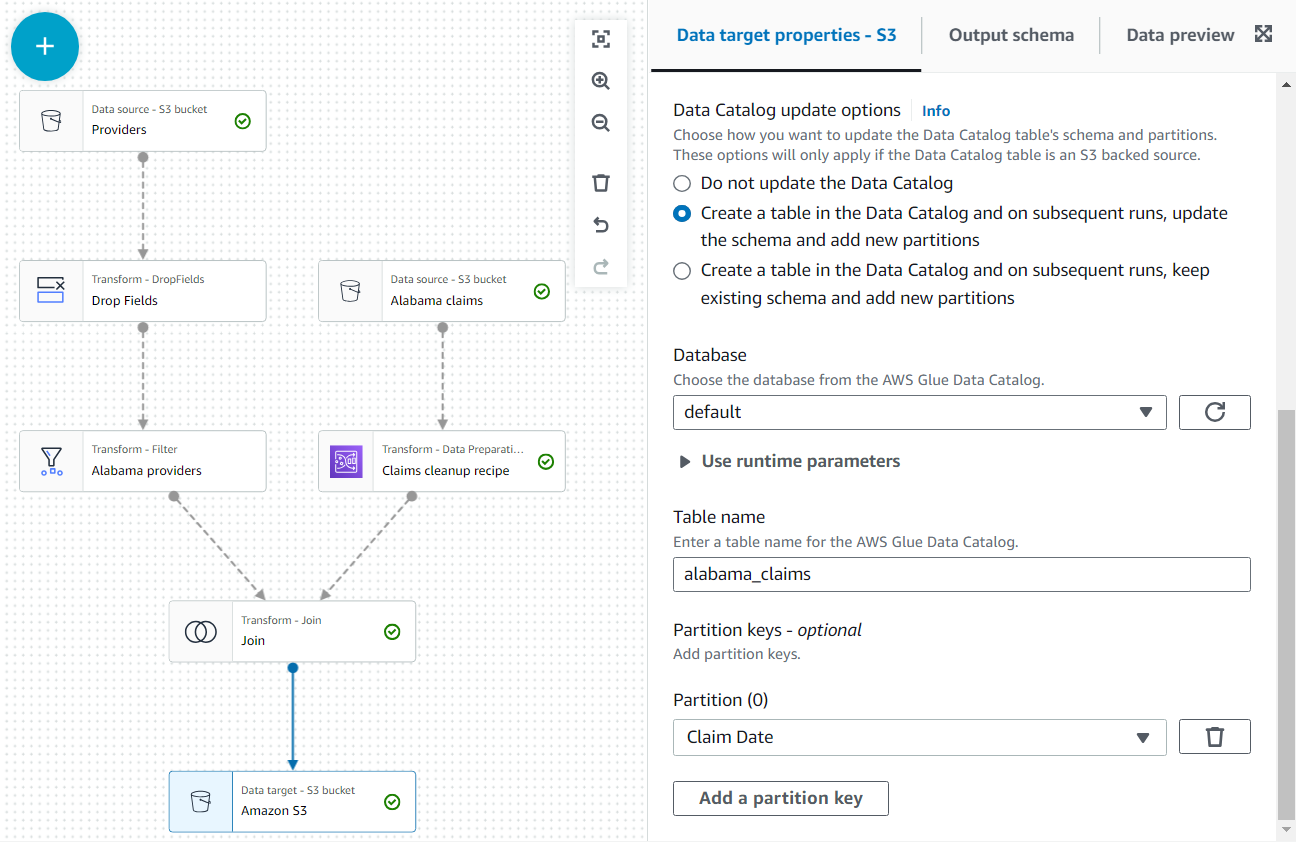
- 现在你可以保存并运行作业。
- 在 “ 运行 ” 选项卡上,您可以使用作业 ID 链接跟踪流程并查看详细的作业指标。
这项工作应该需要几分钟才能完成。
- 任务完成后,导航到 Athena 控制台。
-
在所选数据库 中搜索表
alabama_claims,然后使用快捷菜单选择 “ 预览表” ,这将在表 上运行简单的 SELECT* SQL 语句。
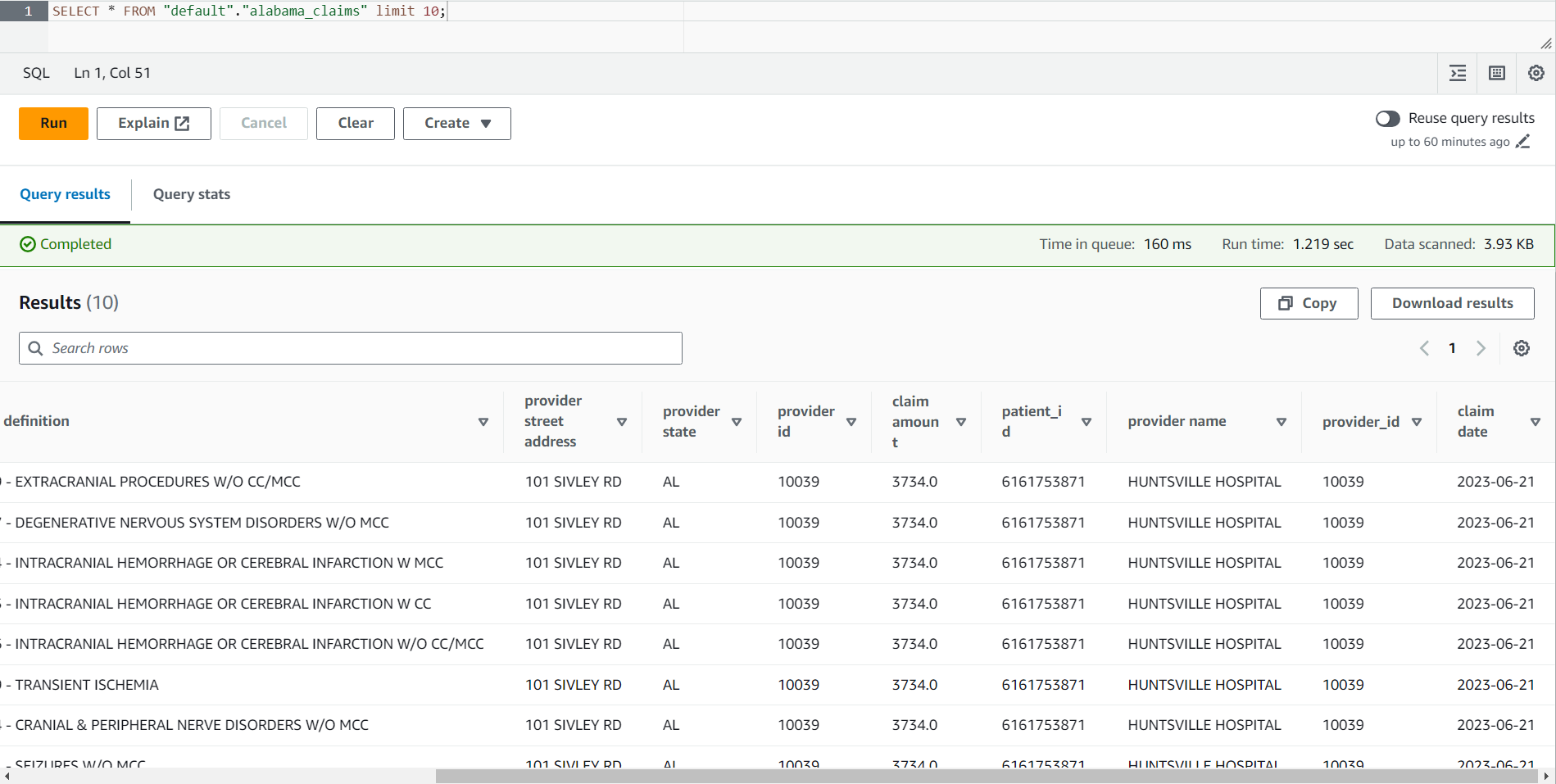
你可以在任务结果中看到,数据是由DataBrew配方清理的,并通过加入亚马逊云科技 Glue Studio来丰富的。
Apache Spark 是运行在 亚马逊云科技 Glue Studio 上创建的任务的引擎。使用Spark UI生成的事件日志,您可以查看有关作业计划和运行的见解,这可以帮助您了解作业的表现和潜在的性能瓶颈。例如,对于针对大型数据集的此作业,您可以使用它来比较在进行联接之前明确筛选提供者状态所产生的影响,或者确定添加自动平衡转换以提高并行度是否有好处。
默认情况下,该作业会将 Apache Spark 事件日志存储在
s3://aws-glue-assets--/SparkHistoryLogs/
清理
如果您不再需要此解决方案,则可以删除在 Amazon S3 上生成的文件、任务创建的表、DataBrew 配方和 亚马逊云科技 Glue 任务。
结论
在这篇文章中,我们展示了如何使用 亚马逊云科技 DataBrew 使用提供的交互式编辑器来构建配方,然后在 亚马逊云科技 Glue Studio 可视 ETL 作业中使用已发布的食谱。我们提供了一些在准备数据和向 亚马逊云科技 Glue Catalog 表中提取数据时所需的常见任务示例。
此示例在可视化作业中使用了单个配方,但可以在ETL流程的不同部分使用多个配方,也可以在多个作业中重复使用相同的配方。
这些 亚马逊云科技 Glue 解决方案允许您有效创建易于构建和维护的高级 ETL 管道,所有这些都无需编写任何代码。您可以立即开始创建将这两种工具结合在一起的解决方案。
作者简介
 米哈伊尔·斯米尔诺夫
是 亚马逊云科技 Glue 团队的高级软件开发工程师,也是 亚马逊云科技 Glue DataBrew 开发团队的一员。工作之余,他的兴趣包括学习弹吉他和与家人一起旅行。
米哈伊尔·斯米尔诺夫
是 亚马逊云科技 Glue 团队的高级软件开发工程师,也是 亚马逊云科技 Glue DataBrew 开发团队的一员。工作之余,他的兴趣包括学习弹吉他和与家人一起旅行。
 贡萨洛·埃雷罗斯
是 亚马逊云科技 Glue 团队的高级大数据架构师。他常驻爱尔兰都柏林,通过基于 亚马逊云科技 Glue 的大数据解决方案帮助客户取得成功。在业余时间,他喜欢棋盘游戏和骑自行车。
贡萨洛·埃雷罗斯
是 亚马逊云科技 Glue 团队的高级大数据架构师。他常驻爱尔兰都柏林,通过基于 亚马逊云科技 Glue 的大数据解决方案帮助客户取得成功。在业余时间,他喜欢棋盘游戏和骑自行车。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。