我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
数据产品组合管理的艺术与科学
这篇文章是专门讨论实用数据网格实现艺术和科学的系列文章中的第一篇(要了解数据网格的概述,请阅读原始白皮书

葛根
葛根——或葛根()——原产于日本和中国东南部。它于 1876 年首次引入美国东南部,是侵蚀控制的有前途的解决方案,现在它代表了一个关于意想不到的后果的警示故事,因为葛根的生长速度超过了从原生草到树木系统的所有物种,使它们免受光合作用所需的阳光照射,最终导致物种灭绝和生物多样性的丧失。Kudzu 的故事有力地比喻了在没有完全理解或理解其使用方式的情况下实施数据网格架构的危险和后果。当非托管的伪数据产品(伪装成数据产品但未能履行与之相关的众多义务的共享数据的方法)的 “Kudzu” 使真实数据产品的本地生态系统不堪重负时,根除成本高昂且容易失败,可能造成大量精力和资源的浪费,也可能浪费大量时间。
沙漠
20世纪30年代,当葛根占领南方时,大规模毁林造成的荒漠化使中西部地区不堪重负,大片土地变得贫瘠,居民被迫离开并寻找其他地方谋生。同样,过于严格的数据治理做法要么根本阻止数据产品扎根,要么过于激进地削减数据(毁林),随着时间的推移,可能会造成 “数据沙漠”,促使组织内数据的生产者和消费者将目光投向其他地方以满足他们的数据需求。同时,非结构化的数据网格管理方法如果没有设想应该存在哪些类型的产品以及如何确保这些产品得到开发,则很有可能因为简单的忽视而产生同样的效果。这是由于人们普遍认为数据网格是一种数据策略,即数据网格实际上是自我组织的,这意味着一旦有了机会,组织内的数据所有者就会承担与发布高质量数据产品相关的责任和义务。实际上,数据生产者的工作往往吃力不讨好,如果没有明确的激励策略,随着生产者和消费者去其他地方寻找工作所需的数据,组织最终可能会陷入数据沙漠,从而造成更多的数据治理问题。
盆景
盆景(盆景)是一种艺术形式,起源于一种名为盆景(盆景)的中国古代传统,后来被禅宗佛教的极简主义教义塑造成我们今天所知道和认可的实践。Bonsai的耐心实践为避免葛根的混乱以及组织数据沙漠幽灵所需的概念和流程提供了有用的类比。盆景艺术家会仔细观察树木产生的自然生成的花蕾,鼓励那些能增加树木整体美感的花蕾,同时修剪那些与邻居不相处的花蕾。同样的想法同样适用于数据网格中的数据产品——通过鼓励那些为我们的数据网格增加价值的数据产品的发展和采用,并持续精简那些没有增加价值的数据产品,我们可以最大限度地提高数据网格实现的价值和可持续性。同样,盆景艺术家必须在他们对树形的视野与对他们选择合作的物种的自然特征和与生俱来的结构的尊重之间取得平衡——忽视树木的生物学将对树木的寿命以及艺术本身的质量造成灾难性的后果。同样,寻求成功实施数据网格战略的组织在实施过程中必须尊重其组织的性质和结构(法律、政治、商业、技术)。
在为实施可持续数据网格运营模型而提出的关键功能中,与我们在本文后面描述的问题最相关的功能是数据产品组合管理。
数据产品组合管理概述
就其本质而言,数据网格架构非常适合在联邦组织内实施,具有分散的数据所有权以及实体或业务部门之间的明确法律、监管或商业界限。但是,同样的组织特征使数据网格架构变得有价值,也使它们有可能变成葛根或数据沙漠的双重噩梦之一。
要定义组织数据网格的形状和性质,需要回答一些关键问题,包括但不限于:
- 组织内的关键数据域是什么?这些领域需要哪些关键数据产品来解决当前的业务问题?在绘制域图的同时,我们如何迭代这个发现过程以增加价值?
- 谁是我们组织中的消费者,哪些逻辑、监管、物理或商业界限可能将他们与生产者及其数据产品区分开来?
- 我们如何鼓励去中心化组织中开发和维护关键数据产品?
- 我们如何根据其 SLA 监控数据产品,确保在出现故障时发出警报和升级,从而保护组织免受不良数据的侵害?
- 我们如何让那些拥有正确技能、正确工具和正确心态的自主生产者和消费者的人真正希望(并能够)更多地拥有独立发布数据作为产品并负责任地消费数据的所有权?
- 数据产品的生命周期是什么?何时创建新的数据产品,允许谁创建它们?数据产品何时被弃用,谁应对其消费者造成的后果负责?
- 在数据产品的背景下,我们如何定义 “风险” 和 “价值”,以及如何衡量这一点?谁有责任为给定数据产品的存在辩护?
要回答诸如此类的问题并进行相应的规划,组织必须实施数据产品组合管理 (DPPM)。DPPM 不是凭空存在的,就其本质而言,DPPM 与业务能力管理和项目组合管理等企业架构实践密切相关并相互依存。因此,在某种程度上,DPPM 本身也可以被视为一种企业架构实践。
作为企业架构业务部门,DPPM 负责其实施,其职权范围应适当地是全球和跨职能的。对于拥有 CDO 或同等中央数据职能的组织,这可能在 CDO 办公室内部,也可能是没有 CDO 或同等中央数据职能的组织中的企业架构团队。
DPPM 的目标

DPPM 的目标可以概括如下:
- 保护价值 — DPPM 通过制定、实施和执行框架来衡量数据产品对组织目标的客观贡献,从而保护组织数据战略的价值。示例可能包括相关的收入、节省或运营损失的减少。在数据产品生命周期的早期,可以通过替代指标来衡量,包括采用率(消费者数量)和活动水平(发布、与消费者的互动等)。在追求这一目标的过程中,DPPM 能力负责与业务互动,持续确定数据作为产品可以增加价值并相应调整交付优先顺序。本文稍后将探讨衡量价值和对数据产品进行优先排序的策略。
- 管理风险 — 所有数据产品都会给组织带来风险——因不采用而浪费金钱和精力的风险、与不当使用相关的运营损失风险,以及数据产品无法满足可用性、完整性或质量要求的风险。如果低质量或无人监督的数据产品激增,这些风险就会加剧。DPPM 力求在个人和综合的基础上了解和衡量这些风险。这是一个特别具有挑战性的目标,因为构成与特定数据产品的存在相关的风险主要由其消费者决定,并且可能会随着时间的推移而发生变化(尽管像熵一样,只会增加)。
- 指南演变 — DPPM 的最终目标是指导数据产品格局的演变,以实现总体组织数据目标,例如相互排斥或共同详尽的领域和数据产品、识别和实现产品定义的单线程所有权,或者灵活纳入新的数据源和创建产品以实现战术或战略业务目标。本文稍后将探讨管理数据网格演变以及根据组织目标评估数据产品的一些原则。
DPPM 面临的挑战
在本节中,我们将探讨DPPM的一些挑战,以及应对其中一些挑战的务实方法。
婴儿期
数据网格作为一个概念还相对较新。因此,与用于构建和管理数据网格架构的实用运营模型相关的标准化程度很低,也无法访问完全开箱即用的参考运营模型、框架或工具来支持 DPPM 实践。
DPPM 的某些元素由不同的工具支持(例如,一些数据目录包含有助于衡量价值的基本社区功能),但不是以整体方式提供的。随着时间的推移,与DPPM相关的流程的标准化很可能会成为商品化的副作用,其推动力是新服务的普及和采用,这些服务承担并自动化了更多与网状监管相关的无差别繁重工作。但是,与此同时,采用数据网格架构的组织在很大程度上要依靠自己的设备来有效地操作这些架构。
抵抗
民主最纯粹的表现形式是无政府状态,组织越是联邦化(本身就是选择数据网格架构的支持因素),对任何形式的集中治理的阻力就越大。这对于 DPPM 来说是一个挑战,因为在某种程度上,它必须汇集在一个地方。正如盆景艺术家知道整棵树的愿景一样,无论单个域或数据产品多么广泛地联合和自治,都必须有统一的愿景和指导数据网格演变的能力。
但是,在这一点与尊重组织的自然形态(和文化)的需求之间取得平衡,需要实施DPPM的组织考虑如何以不与组织现实相冲突的方式进行实施。例如,这可能意味着 DPPM 可能需要在多个层面上进行——至少在数据域内,可能在业务部门内,然后通过相应的数据委员会、公会或其他将利益相关者聚集在一起的结构在企业层面进行。所有这些都使有效执行 DPPM 所需的流程和协作变得复杂。
成熟度
数据网格架构,因此也就是 DPPM,都假设组织内部的数据成熟度相对较高——明确的数据策略、对数据所有权和管理的理解、管理数据使用的原则和政策,以及组织内部围绕数据的中到高级别的教育和培训。组织内部缺乏数据成熟度,或者企业架构功能薄弱或不成熟,将在实施任何数据网格架构时面临重大障碍,更不用说强大而有用的DPPM实践了。
但是,实际上,各组织的数据成熟度并不统一。即使在看似成熟度低的组织中,也往往有一些团队更成熟,参与的意愿也更高。通过倾向于这些团队并首先通过他们展示价值,然后使用他们作为传播者,组织可以获得成熟度,同时更早地从数据网格策略的优势中受益。
以下各节从人员、流程和技术的角度探讨了DPPM的实施,并描述了数据产品的关键特征(范围、价值、风险、独特性和适用性),以及它们与数据网格实践的关系。
人们
为了有效实施DPPM,组织中的各种利益相关者可能需要以一种或另一种身份参与。下表列出了一些关键角色,但这些角色如何以及是否与自己的角色和职能对应取决于各个组织。
| Function | RACI | Role | Responsibility | |
| Senior Leadership | A | Chief Data Officer | Ultimately accountable for organizational data strategy and implementation. Approves changes to DPPM principles and operating model. Acts as chair of, and appoints members to, the data council. | |
| . | R | Data Council** | Stakeholder body representing organizational governance around data strategy. Acts as steering body for the governance of DPPM as a practice (KPI monitoring, maturity assessments, auditing, and so on). Approves changes to guidelines and methodologies. Approves changes to data product portfolio (discussed later in this post). Approves and governs centrally funded and prioritized data product development activities. | |
| Enterprise Architecture | AR | Head of Enterprise Architecture | Responsible for development and enforcement of data strategy. Accountable and responsible for the design and implementation of DPPM as an organizational capability. | |
| . | R | Domain Architect | Responsible for the implementing screening, data product analysis, periodic evaluation, and optimal portfolio selection practices. Responsible for the development of methodologies and their selection criteria. | |
| Legal & Compliance | C | Legal & Compliance Officer | Consults on permissibility of data products with reference to local regulation. Consults on permissibility of data sharing with reference to local regulation or commercial agreements. | |
| . | C | Data Privacy Officer | Consults on permissibility of data use with reference to local data privacy law. Consults on permissibility of cross-entity or border data sharing with reference to data privacy law. | |
| Information Security | RC | Information Security Officer | Consults on maturity assessments (discussed later in this post) for information security-relevant data product capabilities. Approves changes to data product technology architecture. Approves changes to IAM procedures relating to data products. | |
| Business Functions | A | Data Domain Owner | Ultimately accountable for the appropriate use of domain data, as well as its quality and availability. Accountable for domain data products. Approves changes to the domain data model and domain data product portfolio. | |
| c | R | Data Domain Steward | Responsible for implementing data domain responsibilities, including operational (day-to-day) governance of domain data products. Approves use of domain data in new data products, and performs regular (such as yearly) attestation of data products using domain data. | |
| . | A | Data Owner | Ultimately accountable for the appropriate use of owned data (for example, CRM data), as well as its quality and availability. | |
| . | R | Data Steward | Responsible for implementing data responsibilities. Approves use of owned data in new data products, and performs regular (such as yearly) attestation of data products using owned data. | |
| . | AR | Data Product Owner | Accountable and responsible for the design, development, and delivery of data products against their stated SLOs. Contributes to data product analysis and portfolio adjustment practices for own data products. | |
** 数据委员会通常由来自各职能部门(数据域所有者)、企业架构和首席数据官或同等职位的常驻代表组成。
进程
下图说明了与 DPPM 相关的战略、战术和运营实践。这篇文章更详细地探讨了实施这些做法的一些注意事项,尽管它们的具体解释和实施取决于个别组织。
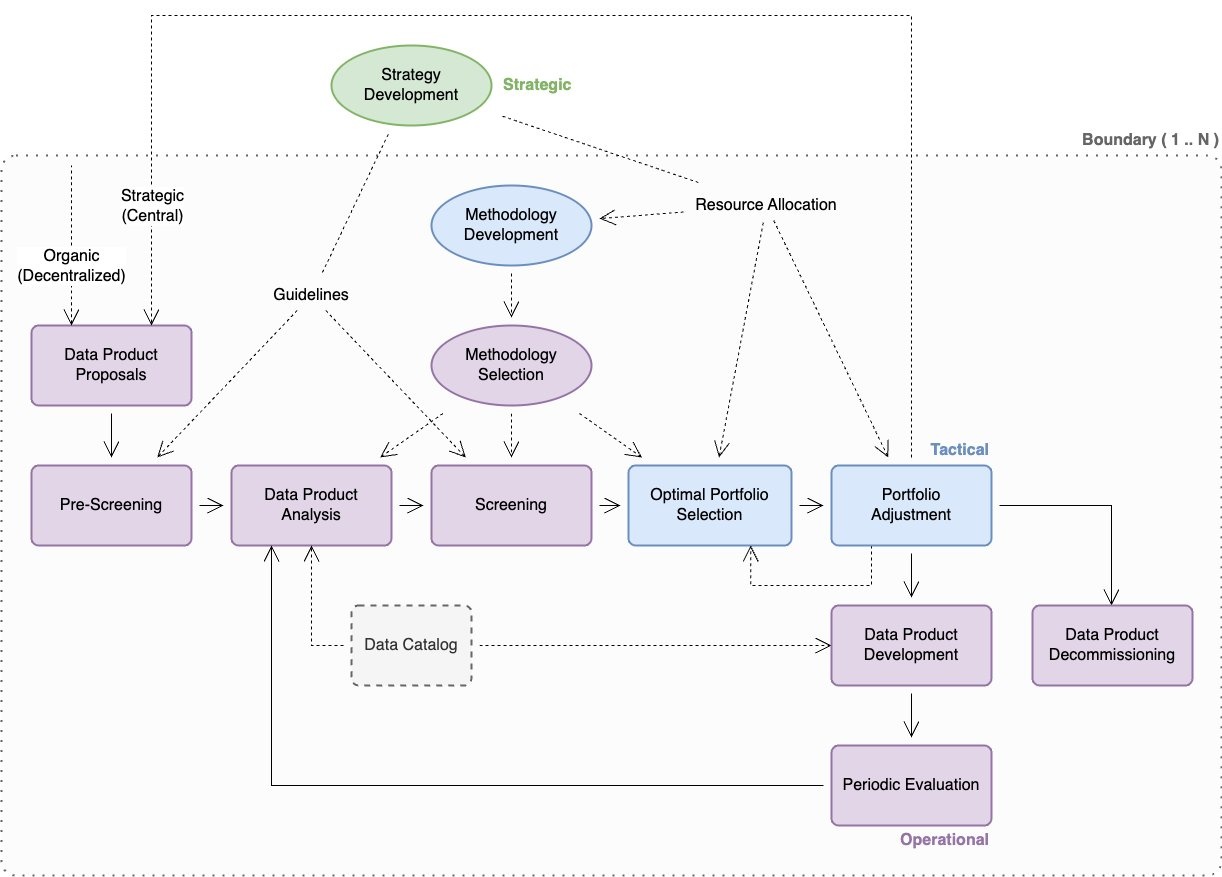
边界
阅读本节时,请务必记住边界的影响,尽管战略制定可以确立为一种全球惯例,但DPPM内部的其他实践必须尊重相关的组织边界(本质上可能是物理、地理、运营、法律、商业或监管边界)。在某些情况下,边界的存在可能需要在每个相关边界内重复部分或全部战术和作战实践。例如,一家在北美拥有财产和意外伤害法人实体且在德国拥有人寿实体的保险公司可能需要在每个实体内单独实施DPPM。
策略制定
这种做法涉及回答与整体数据网格策略相关的问题,包括:
- 数据网格的总体范围(数据域、参与实体等)
- 参与实体在定义和实现数据网格方面的自由度(例如,网格网格与单个网格)
- 与数据网相关的活动和能力的责任分配(民主化程度)
- 定义和记录管理数据网格的关键绩效指标 (KPI)(例如风险和价值)
- 治理运营模式(包括这种做法)
主要可交付成果包括:
- 有关数据产品预筛选和筛选的操作流程的组织指南
- 明确定义的关键绩效指标,可指导方法的开发和选择,用于数据产品分析、筛选和最佳投资组合选择等实践
- 分配组织资源(人员、预算、时间),以实施围绕方法开发、最佳投资组合选择和投资组合调整的战术流程
关键注意事项
在本节中,我们将讨论战略制定的一些关键注意事项。
数据网格结构
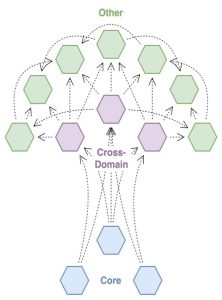
此图说明了数据网格中数据产品与网格本身结构之间的类似关系。
以下注意事项与筛选、数据产品分析和最佳投资组合选择有关。
- 主干(核心数据产品) — 核心数据产品是那些对组织运作能力至关重要的产品,大多数其他数据产品都源自这些产品。这些可能是实施关键业务活动时使用的数据产品,也可能是与监管报告和风险管理等关键流程相关的数据产品。这些数据产品的组织治理通常更倾向于可用性和数据准确性,而不是敏捷性。
- 分支(跨域数据产品) — 跨域数据产品代表最常见的数据跨域用例(例如,将客户数据与产品数据结合起来)。这些数据产品可以广泛用于各种业务职能,以支持报告和分析,并在较小程度上支持运营流程。由于这些数据产品可能消耗各种来源,因此组织治理可能倾向于在敏捷性与可靠性之间采取平衡的观点,接受一定程度的风险作为回报,因为他们能够适应数据源的变化。数据产品版本控制可以缓解与变更相关的风险。
- Leaf(其他所有内容) — 这些是数据网格中可能出现的无数数据产品,要么是支持各个团队和用例的永久补充,要么是填补数据空白或支持限时计划的临时数据产品。由于这些数据产品的数量可能很高,风险通常仅限于单个流程或组织的一小部分,因此组织治理通常倾向于轻描淡写,可能更愿意通过指导方针和最佳实践进行治理,而不是通过积极参与数据产品生命周期进行治理。
数据产品与数据定义
下图说明了如何在整个数据产品谱系中定义和继承数据定义。
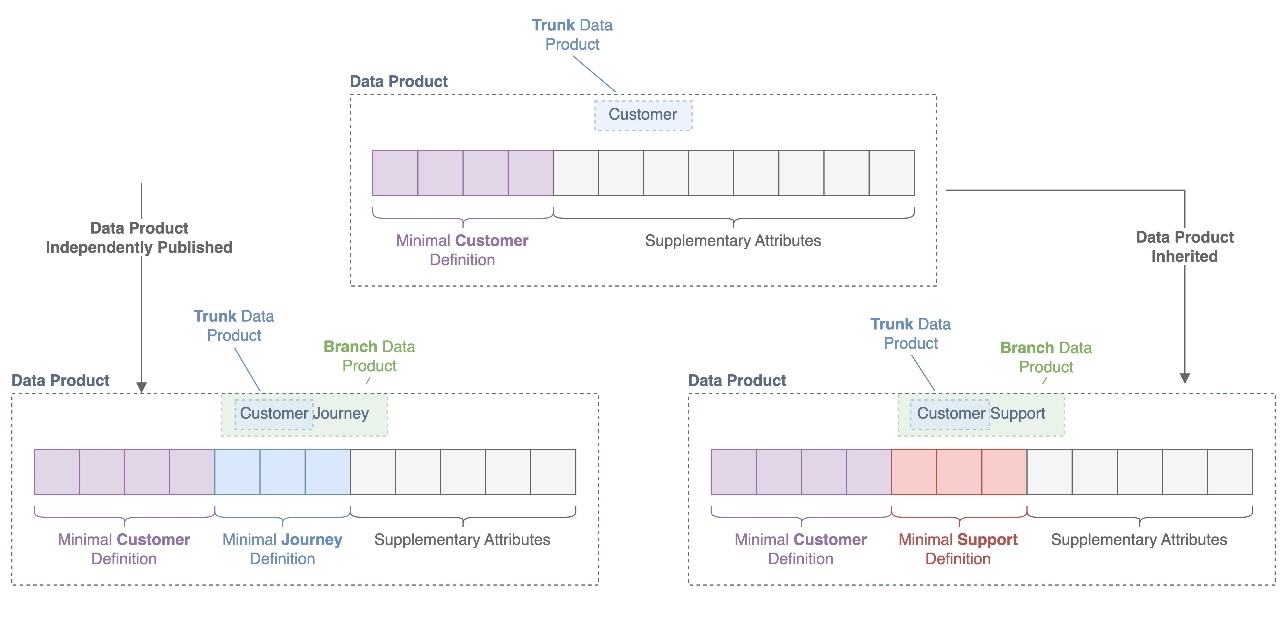
在数据网格架构中,数据产品可以相互继承数据(一种数据产品在其数据管道中消耗另一种数据产品),也可以独立发布同一域内(或与之相关的数据)。例如,客户数据产品可以由客户支持数据产品继承,而另一个客户旅程数据产品可以直接发布来自独立来源的客户相关数据。如果不对域数据属性的使用和发布方式应用任何标准,则即使在同一个数据域内的数据产品也可能失去互操作性,因为很难或不可能将它们组合在一起用于报告或分析目的。
为了防止这种情况,区分数据产品和数据定义可能很有用。通常,组织将选择单线程所有者(通常是数据所有者或管理员,或域数据所有者或管理员),负责为数据域中常见和可重复使用的数据实体定义最低限度的数据定义。例如,负责销售和营销数据域的数据所有者可以将客户数据产品识别为域内可重复使用的数据实体,并发布最低限度的数据定义,所有客户相关数据的生成者都必须将其纳入其数据产品中,以确保与客户数据关联的所有数据产品均可互操作。
作为其数据产品分析活动的一部分,DPPM可以协助识别和生成数据定义,并强制将其纳入数据产品开发监督中。
服务管理思维
这些注意事项与数据产品分析、定期评估和方法选择有关。
数据产品是提供给组织或外部提供给客户和合作伙伴的服务。因此,将诸如ITIL之类的服务管理框架与ITIL成熟度模型相结合,以用于评估数据产品对其范围和受众的适用性,以及描述应构成任何数据产品运营模型的角色、流程和可接受的技术,可能是有意义的。
在运营层面,实施每种做法所需的利益相关者可能会根据数据产品的范围而变化。例如,核心数据产品的发布管理实践可能需要数据委员会的参与,而团队数据产品的相同做法可能只涉及团队或职能负责人。为了避免造成决策瓶颈,组织应努力最大限度地减少每种情况下的利益相关者数量,并尽可能将重点放在单线程所有者身上。
下表提出了功能的子集以及如何将其应用于不同范围的数据产品。每个范围都包括建议的目标成熟度级别,介于 1 到 5 之间。(1 = 初始,5 = 优化)
| Target Maturity | Data Product Scope . | |||
| 4 – 5 | 3 – 4 | 2 – 3 | 2 | |
| Capability |
Core
|
Cross-Domain
|
Function / Team
|
Personal
|
| Information Security Management | X | X | X | X |
| Knowledge Management | X | X | X | . |
| Release Management | X | X | X | . |
| Service-Level Management | X | X | X | . |
| Measurement and Reporting | X | X | . | . |
| Availability Management | X | X | . | . |
| Capacity and Performance Management | X | X | . | . |
| Incident Management | X | X | . | . |
| Monitoring and Event Management | X | X | . | . |
| Service Validation and Testing | X | X | . | . |
方法论的制定
这种做法涉及制定具体、客观的框架、指标和流程,以衡量数据产品价值和风险。由于不同产品的风险和价值背后的驱动因素不一定相同,因此可能需要开发几种方法或变体。
主要可交付成果包括:
- 明确定义的框架,用于衡量数据产品的风险和价值,以及确定数据产品的最佳组合
- 与价值和风险相关的运营上可行、可衡量的指标
关键注意事项
评估数据产品的一个关键考虑因素是消费者价值或风险与独特性。下图说明了消费者如何驱动数据产品的价值和风险。
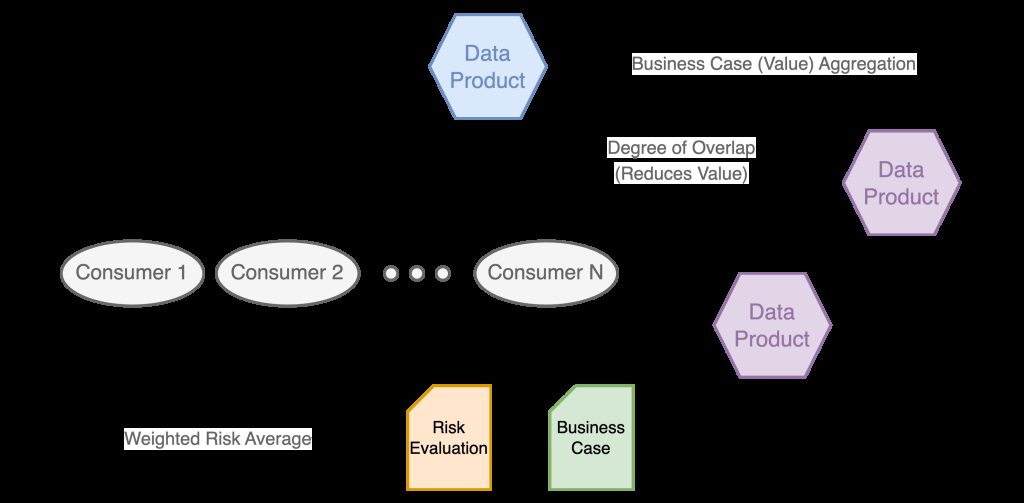
数据产品本身并不存在风险或增加价值,而是以综合方式间接构成消费者创造的风险和价值。
在以消费者为中心的价值和风险模型中,消费者治理可确保所有数据的使用都符合以下要求:
- 与证明数据使用合理性的商业案例相关(例如,新业务、通过业务流程自动化降低成本等)
- 定期参照与用例相关的风险进行评估(例如,监管报告)
然后,将与关联数据产品相关的价值和风险以聚合形式计算。如果组织已经跟踪与数据相关的用例,无论是作为数据隐私治理的一部分还是作为访问批准过程的副产品,这些现有系统和数据库都可以重复使用或扩展。
相反,当数据产品相互重叠时,它们对组织的价值就会相应降低,因为数据产品之间的冗余意味着资源的使用效率低下,并增加了与数据质量管理相关的组织复杂性。
为了确保该模型在操作上可行(参见方法开发的关键交付成果),考虑简单的汇总可能就足够了,而不是试图在产品或用例层面计算价值和风险归因。
最佳投资组合选择
这种做法涉及确定哪种数据产品组合(现有、新的或潜在的)最能满足组织当前和已知的未来需求。这种做法从数据产品分析和数据产品提案以及其他企业架构实践(例如业务架构)中获取意见,并考虑数据债务和价值实现时间之间的权衡,以及其他考虑因素,例如数据产品之间的冗余,以确定永久和临时数据产品在任何给定时间点的最佳组合。
由于随着时间的推移,组织中的数据产品数量可能会变得很大,因此将启发式方法应用于最佳投资组合选择问题可能会很有用。例如,在季度投资组合审查期间考虑核心和跨域数据产品(主干和分支机构),而每年对其他数据产品(离开)进行审计可能就足够了。
主要可交付成果包括:
- 数据网格的目标状态定义,包括所有相关的数据产品
- 指明投资组合调整业务所使用的组织优先事项
关键注意事项

以下是有关数据产品半衰期的关键注意事项:
- 长期或战略数据产品 ——这些数据产品可以满足组织的长期需求,通常与各个领域的关键源系统相关联,并支撑整体数据策略。随着时间的推移,随着组织数据网格的成熟,长期数据产品应构成网格的大部分。
- 有时限的数据产品 ——这些数据产品填补了数据策略中的空白,使组织能够抓住数据机会,直到核心数据产品可以更新。这方面的一个例子可能是在合并和收购交易以及收购后的背景下创建和使用的数据产品,以便在进行中期和长期应用程序整合之前,为报告和商业情报提供一致的数据。有时限的数据产品被视为数据债务,应进行相应的管理。
-
目的驱动的数据产品 — 这些数据产品的
用途狭窄、有限。以目的为导向的数据产品可能有时限,也可能没有时限,但其特点主要是事先知道的严格消费者。这方面的示例可能包括:
- 为支持业务部门之间的记录系统协调而开发 的数据产品(例如,使用单独的 CRM 系统对保险业务线之间的客户记录进行重复
- 数据删除)专为监控其他数据产品(数据质量、更新频率等)而创建
投资组合调整
这种做法实施可行性分析、规划和项目管理,以及与最佳投资组合变更相关的沟通和组织变更管理活动。作为这种做法的一部分,将对当前数据产品组合和目标数据产品组合进行差距分析,并准备一系列必要行动和估计的时间和精力,以供组织审查。在此期间,数据产品可能会被标记为用于开发(满足需求的新数据产品)、更改、合并(将两个或更多数据产品合并为一个数据产品)或弃用。可能需要对最佳投资组合选择和投资组合调整进行几次迭代,才能在最佳性和实施可行性之间找到适当的平衡。
主要可交付成果包括:
- 当前数据产品组合和目标数据产品组合之间的差距分析,以及拟议的补救活动
- 与所需变更相关的高级别项目计划和工作或预算评估,供相关利益相关者(例如数据委员会)批准
数据产品提案
这种做法负责组织内部对新数据产品或对现有数据产品进行更改的请求的收集和优先排序。其实施可以根据组织内现有的需求管理流程进行调整或由其管理。
关键交付品包括针对新数据或现有数据产品的需求登记册,包括有关源系统、属性、已知用例、拟议的数据产品所有者和建议的组织优先事项的元数据。
方法选择
这种做法与在数据产品分析、筛选和最佳投资组合选择过程中识别和应用最合适的方法(例如价值和风险)有关。为数据产品(或整个投资组合)的类型、成熟度和范围选择合适的方法是避开 “葛根” 网格或 “数据沙漠” 的关键要素。
关键交付品包括可重复使用的选择标准,用于在数据产品分析、筛选和最佳投资组合选择期间将方法映射到数据产品。
预先筛选
这种可选做法主要是一种机制,通过提供简单的自助服务应用程序来评估数据产品,从而避免在相对昂贵的数据产品分析实践中不必要的时间和精力。一个例子可能包括自动批准属于个人数据产品分类的数据产品,只需要请求者证明他们将遵守管理此类数据产品的指南的相关部分。
主要交付品包括用于根据指南对数据产品进行自助评估的工具和清单,以及批准的数据产品的自动注册。
数据产品分析
这种做法包括指导方针、方法以及与数据产品(如果有)相关的元数据(对照 SLO 的性能、服务管理指标、与其他数据产品的重叠程度),以了解与单个数据产品相关的价值和风险,以及当前和目标能力成熟度之间的差距,以及对已发布产品定义和标准的遵守情况。
关键交付品包括特定数据产品的调查结果摘要,包括相关价值、风险和成熟度指标的分数,以及需要补救的运营差距和后续步骤(修复、增强、停用等)的建议。
放映
这种可选做法是一种降低最佳投资组合选择复杂性的机制,方法是确保尽早将未能实现价值或风险目标或被确定为组织中已有的其他数据产品多余的数据产品排除在考虑范围之外。
关键交付品包括应计划移除(直接停用)的数据产品清单。
数据产品开发
这种做法不是直接在DPPM下进行的,而是部分由投资组合调整业务进行管理,并可能受作为DPPM一部分制定的标准的约束。在DPPM的背景下,这种做法主要与确保根据作为投资组合调整一部分商定的规格开发数据产品有关。
关键交付品包括项目管理以及软件或服务开发交付品和工件。
数据产品停用
这种做法管理数据产品的停用,以及相关时将受影响的消费者迁移到新的或其他数据产品。非管理地停用数据产品,尤其是下游消费者的数据产品,可能会威胁整个数据网格的稳定性,并对业务功能产生重大影响。
关键交付品包括退役计划,包括利益相关者评估和签署、时间表、受影响消费者的迁移计划以及撤出策略。
定期评估
这种做法管理数据网格定期审查的日程安排和实施,无论是整体审查还是数据产品层面,主要是一种项目管理活动。
主要可交付成果包括:
- 年度审查日历,已发布并提供给所有数据产品所有者和受影响的利益相关者
- 项目管理可交付成果和文物,包括已对每种数据产品进行评估的证据
科技
尽管 DPPM 中的大多数实践并不严重依赖技术和自动化,但有效实施 DPPM 需要一些关键的支持应用程序和服务:
- 数据目录 — DPPM 交付的核心是组织数据目录。除了提供组织内存在哪些数据产品的透明度外,数据目录还可以提供有关数据产品(实施投资组合调整的关键)与组织采用数据产品之间的数据谱系的关键见解。数据目录还可用于捕获和提供任何给定数据产品的已记录和已实现的 SLO,并通过使用业务术语表帮助识别数据产品之间的冗余。
- 服务管理 — 在数据产品管理背景下使用的服务管理解决方案(例如ServiceNow)通过捕获和跟踪事件、问题、请求和其他数据产品指标,为数据产品的适用性提供了重要的见解。
- 需求管理 — 需求管理解决方案支持自助服务实施和自动化数据产品提案和预筛选活动,以及与选择和开发数据产品相关的优先排序活动。
结论
尽管这篇文章侧重于在数据网格环境中实现 DPPM,但这种能力(例如数据产品思考)并不是数据网格架构所独有的。此处概述的做法可以在任何规模上实践,以确保组织内部数据的生成和使用始终符合其当前和未来的需求,以一致的方式实施治理,并确保组织可以使用 Bonsai 而不是葛根。
有关数据网格和数据管理的更多信息,请参阅以下内容:
-
如何解锁数据的全部价值?像产品一样管理它 -
数据网格移动
在接下来的文章中,我们将介绍数据网格运营模型的其他方面,包括数据网格监督和数据产品所有者的服务管理模型。
作者简介
 Maximilian Mayrh ofer
是一名首席解决方案架构师,在 亚马逊云科技 金融服务欧洲、中东和非洲市场进入团队工作。他在私人银行和资产管理领域的数字化转型方面拥有超过12年的经验。在业余时间,他是科幻小说的狂热读者,喜欢抱石。
Maximilian Mayrh ofer
是一名首席解决方案架构师,在 亚马逊云科技 金融服务欧洲、中东和非洲市场进入团队工作。他在私人银行和资产管理领域的数字化转型方面拥有超过12年的经验。在业余时间,他是科幻小说的狂热读者,喜欢抱石。
 法里斯·哈达德 是
AABG Strategic Pursuits团队的数据与洞察主管。他帮助企业成功实现数据驱动。
法里斯·哈达德 是
AABG Strategic Pursuits团队的数据与洞察主管。他帮助企业成功实现数据驱动。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。