我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
亚马逊云科技 Glue Studio 中的十种全新视觉变换
亚马逊云科技 Glue Studio
这篇文章中将演示的新转换包括:串联、拆分字符串、数组到列、添加当前时间戳、将行旋转到列、将列取消透视到行、查找、分解数组或映射到列、派生列和自动平衡处理。
解决方案概述
在这个用例中,我们有一些带有股票期权操作的 JSON 文件。我们希望在存储数据之前进行一些转换以使其更易于分析,我们还想生成单独的数据集摘要。
在此数据集中,每行代表期权合约的交易。 期权是提供在规定的到期日之前以固定价格(称为 行使价)买入或卖出股票的权利(但不提供义务 )的金融工具。
输入数据
数据遵循以下架构:
- 订单编号 — 唯一的 ID
- 符号 — 通常基于几个字母的代码,用于标识发行标的股票的公司
- 工具 — 标识买入或卖出的特定期权的名称
- 货币 — 表示价格的 ISO 货币代码
- 价格 — 购买每份期权合约所支付的金额(在大多数交易所中,一张合约允许您买入或卖出 100 股股票)
- 交易所 — 期权交易中心或交易场所的代码
- 已售出 — 卖出 交易时分配用于填写卖出订单的合约数量清单
- 买入 — 买入 交易时分配用于填写买入订单的合约数量清单
以下是为这篇文章生成的合成数据示例:
ETL 要求
这些数据具有许多独特的特征,这些特征通常在较旧的系统中找到,这些特征使数据更难使用。
以下是 ETL 要求:
- 仪器名称包含有价值的信息,供人类理解;我们希望将其标准化为单独的列以便于分析。
-
买入 和卖出的属性 是相互排斥的;我们可以将它们合并成包含合约编号的单列,另一列表示合约是按此顺序买入还是卖出。 - 我们希望保留有关单个合同分配的信息,但要保留为单独的行,而不是强迫用户处理一组数字。我们可以将数字相加,但我们会丢失有关订单如何成交的信息(表明市场流动性)。相反,我们选择对表格进行非标准化,使每行都有单个数量的合约,将具有多个数字的订单拆分成单独的行。在压缩的列格式中,应用压缩时,这种重复项的额外数据集大小通常很小,因此使数据集更易于查询是可以接受的。
- 我们想为每只股票的每种期权类型(看涨期权和看跌期权)生成交易量汇总表。这表明了每只股票和整个市场的市场情绪(贪婪与恐惧)。
- 为了实现整体交易摘要,我们希望为每项操作提供总计,并使用近似的兑换参考将货币标准化为美元。
- 我们想添加这些转换发生的日期。例如,可以参考何时进行货币兑换,这可能会很有用。
根据这些要求,这项工作将产生两项产出:
- 包含每个品种和类型的合约数量摘要的 CSV 文件
-
在进行指示的转换后,用于保存订单历史记录的目录表
先决条件
您将需要自己的 S3 存储桶才能遵循此用例。要创建新的存储桶,请参阅
生成合成数据
要关注这篇文章(或自己尝试此类数据),你可以合成生成这个数据集。以下 Python 脚本可以在安装了 Boto3 并可以访问亚马逊 S
要生成数据,请完成以下步骤:
- 在 亚马逊云科技 Glue Studio 上,使用 Python shell 脚本编辑器 选项创建新任务 。
-
为作业命名,然后在
作业详细信息
选项卡上,为 Python 脚本选择
合适的角色 和名称。 - 在 作业详细信息 部分中,展开 高级属性 并向下滚动到 作业参数 。
-
输入名为
--bucket的参数, 并将要用于存储示例数据的存储桶的名称分配为该值。 - 在 亚马逊云科技 Glue shell 编辑器中输入以下脚本:
- 运行作业,然后等待 “运行” 选项卡上显示为成功完成(应该只需要几秒钟)。
每次运行都会生成一个 JSON 文件,该文件在指定的存储桶下有 1,000 行,前缀为 transfor
msblog/inputdat
a/。如果您想使用更多输入文件进行测试,则可以多次运行作业。
合成数据中的每一行都是代表一个 JSON 对象的数据行,如下所示:
创建 亚马逊云科技 Glue 可视化作业
要创建 亚马逊云科技 Glue 可视化作业,请完成以下步骤:
- 前往 亚马逊云科技 Glue Studio,使用 带有空白画布的 Visual 选项创建任务 。
-
在
任务 详情 选项卡 上编辑 无标题任务,为其命名并分配适合 亚马逊云科技 Glue 的 角色 。 -
添加 S3 数据源(您可以将其命名为 JS
ON 文件源)并输入存储文件的 S3 网址(例如,s3:///transflos blog/inputdata/ ),然后选择 JSON 作为数据格式。 - 选择 推断架构 , 使其根据数据设置输出架构。
在这个源节点上,你将继续链接变换。添加每个转换时,请确保所选节点是最后添加的节点,以便将其指定为父节点,除非说明中另有说明。
如果您没有选择正确的父项,则可以随时通过选择该父项并在配置窗格中选择另一个父项来编辑该父项。
对于添加的每个节点,您将在 “ 转换 ” 选项卡上为其指定一个特定的名称(因此节点用途如图所示)和配置。
每次转换更改架构(例如,添加新列)时,都需要更新输出架构,使其对下游转换可见。你可以手动编辑输出架构,但使用数据预览来编辑输出架构更实用、更安全。
此外,这样你就可以验证转换是否按预期进行。为此,请在选择转换的情况下打开 “
数据预览
” 选项卡,然后启动预览会话。验证转换后的数据看起来符合预期后,转到
输出架构
选项卡,然后选择
使用数据预览架构
自动更新架构。
当您添加新的转换类型时,预览可能会显示一条关于缺少依赖项的消息。发生这种情况时,选择 “ 结束会话 ”, 然后开始一个新节点,这样预览就会选择新的节点。
提取仪器信息
让我们首先处理有关仪器名称的信息,将其标准化为在生成的输出表中更易于访问的列。
-
添加一个
Split String
节点并将其命名为
SplitInstrument ,它将使用空格正则表达式来标记乐器列:\ s+(在这种情况下,单个空格即可,但这种方式更灵活,视觉效果更清晰)。 -
我们希望保持原始乐器信息不变,因此请为拆分数组输入一个新的列名:instr
ument_arr。

-
添加一个 A
rray To
Columns 节点并将其 命名为 Instr
ument columns,将刚刚创建的数组列转换为新字段 ,符号除外,我们已经有了相应的列。 -
选择列 instrum
ent_arr,跳过第一个标记,让它提取输出列月、日、年、strike_price,使用索引2、3、4、5、6(逗号后面的空格是为了便于阅读,它们不会影响配置)。

提取的年份仅用两位数表示;如果他们只使用两位数,让我们权宜之计假设是在本世纪。
-
添加
“ 派生列”
节点并将其命名为
四位数年份。 -
输入
年份作为派生列,使其覆盖,
然后输入以下 SQL 表达式:当长度(年)= 2 时 大小写 THEN ('20' || 年) 否则年结束

为方便起见,我们创建了一个
expiration_dat
e 字段,用户可以将其作为最后一次行使该选项的日期的参考。
-
添加 “
连接列” 节点并将其命名为 “
生成到期日期 ”。 -
将新列命名为
expiration_date ,选择年、月和日列 (按此顺序),并使用连字符作为间隔。
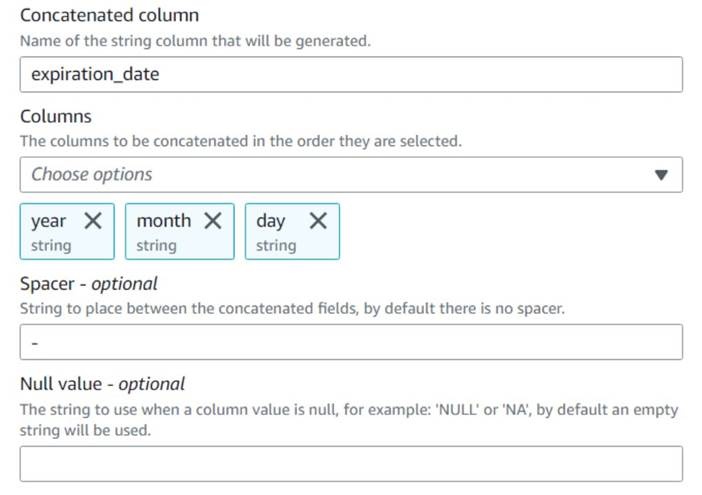
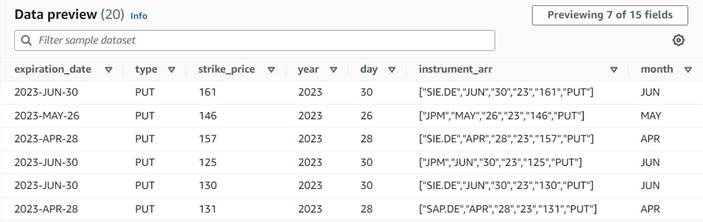
到目前为止的图表应该与以下示例类似。
到目前为止,新列的数据预览应与以下屏幕截图类似。
标准化合约数量
数据中的每一行都表示买入或卖出的每种期权的合约数量以及成交订单的批次。在不丢失有关各个批次的信息的情况下,我们希望将每个金额放在单独的行中,具有单个金额值,而其余信息则在生成的每行中复制。
首先,让我们将金额合并为一列。
-
添加 “
取消透视列成行
” 节点,并将其命名为
Unpivot操作。 -
选择
买入和卖出给 unpivot 的列,并将名称和价值分别存储在名为 “行动” 和 “合约” 的列 中。
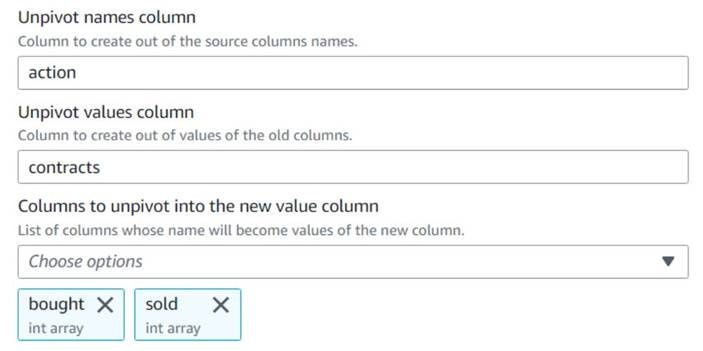
请注意,在预览中,转换后新的列合同仍然 是一个数字数组。
-
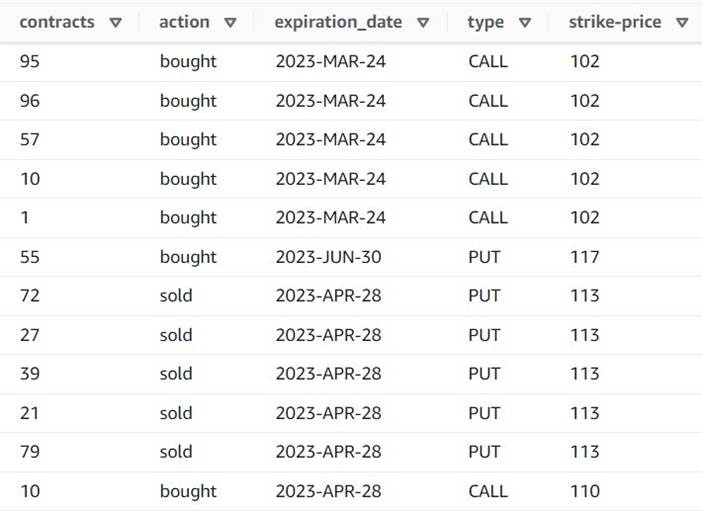
将名为 “
爆炸合约” 的分
解数组或地图添加到 行中 。 -
选择
合约列并输入合约作为新列来覆盖它(我们不需要保留原始数组)。
现在,预览显示每行只有一个
合同
金额,其余字段相同。
这也意味着
order_id
不再 是唯一密钥。对于您自己的用例,您需要决定如何对数据进行建模以及是否要进行非规范化。

以下屏幕截图是迄今为止转换后新列的样子的示例。
创建汇总表
现在,您可以创建一个汇总表,其中包含每种类型和每个股票代码的合约交易数量。
为了举例说明,让我们假设处理的文件属于某一天,因此此摘要向企业用户提供了有关当天市场兴趣和情绪的信息。
-
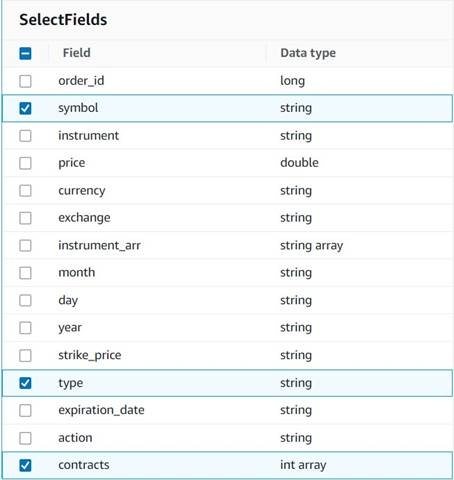
添加
“选择字段
” 节点,然后选择以下列作为摘要保留:
品种 、类型和合约。
-
添加 “将
行 转成列”
节点,并将其命名为 “
透视摘要” 。 -
使用
sum聚合在合约列上, 然后选择转换类型列。

通常,您会将其存储在某个外部数据库或文件中以供参考;在本示例中,我们将其另存为 CSV 文件在 Amazon S3 上。
-
添加
自动平衡处理
节点并将其命名为
单一输出文件。 -
尽管这种转换类型通常用于优化并行度,但这里我们使用它来将输出简化为单个文件。因此, 在分区数配置中输入
1。

-
添加 S3 目标并将其命名
为 CSV 合同摘要。 - 选择 CSV 作为数据格式,然后输入允许任务角色存储文件的 S3 路径。
现在,作业的最后一部分应该看起来像下面的示例。
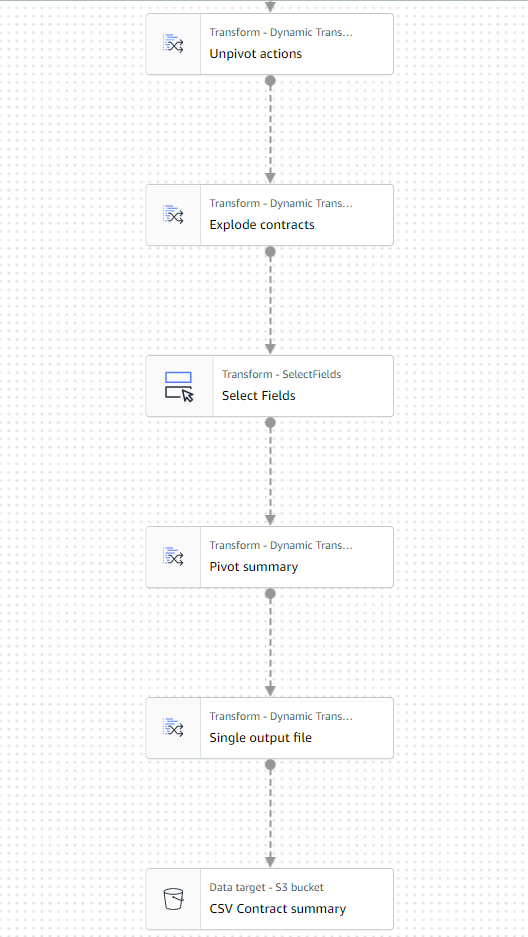
-
保存并运行作业。使用 “
运行
” 选项卡检查它何时成功完成。
尽管没有该扩展名,但您仍会在该路径下找到一个名为 CSV 的文件。下载后你可能需要添加扩展程序才能将其打开。
在可以读取 CSV 的工具上,摘要应类似于以下示例。
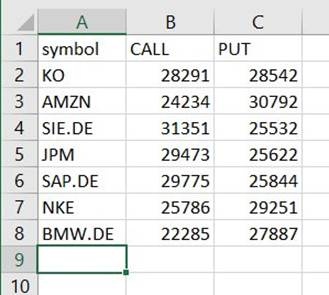
清理临时列
为了准备将订单保存到历史表中以供将来分析,让我们清理一下在此过程中创建的一些临时列。
-
添加一个
Drop Fiel
ds 节点,将 Explode 合约节点选为其父节点(我们正在分支数据管道以生成单独的输出)。 -
选择要删除的字段:instrument_arr、月、日和年。
其余部分我们想保留,以便将它们保存在我们稍后创建的历史表中。
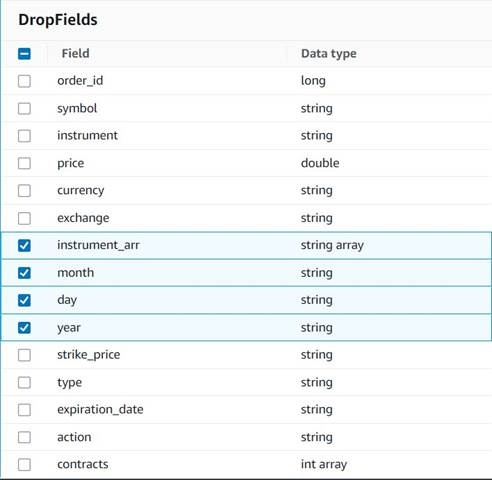
货币标准化
这些合成数据包含对两种货币的虚构操作,但在真实的系统中,你可以从世界各地的市场获得货币。将处理的货币标准化为单一参考货币非常有用,这样就可以轻松地对它们进行比较和汇总以进行报告和分析。
我们使用
- 在使用 亚马逊云科技 Glue 的同一区域打开雅典娜主机。
-
运行以下查询,通过设置 Athena 和 亚马逊云科技 Glue 角色均可读取和写入的 S3 位置来创建表。此外,您可能希望将表存储在与
默认数据库不同的数据库中 (如果这样做,请在提供的示例中相应地更新表限定名称)。 -
在表格中输入一些转换示例:
插入到默认的.exchange_rates 值中('美元',1.0),('欧元',1.09),('英镑',1.24); -
现在,您应该能够使用以下查询查看表格:从 de
fault.exchange _rates 中选择*
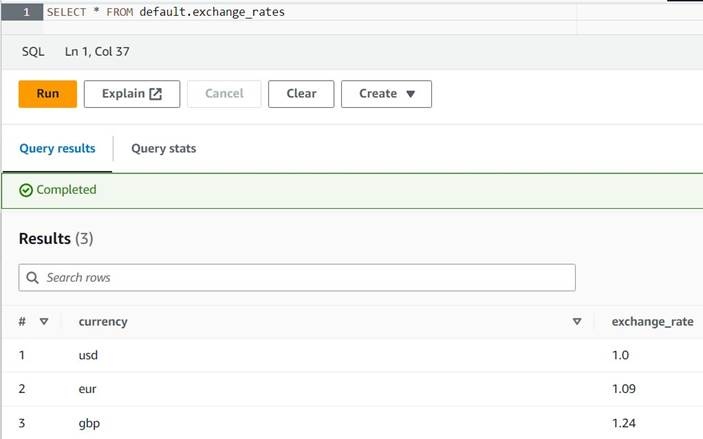
-
返回 亚马逊云科技 Glue 可视化作业,添加一个
查找
节点(作为
Drop Fields 的子节点 )并将其命名为汇率。 -
使用
货币作为密钥输入您刚才创建的表的限定名称,然后选择要使用的exchange_rate 字段。
由于该字段在数据和查找表中的命名相同,因此我们可以只输入名称货币,无需定义映射。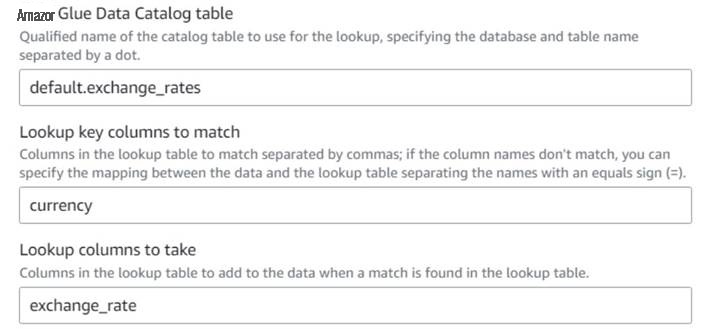
-
添加一个
“ 派生列”
节点并将其命名为 T
otal(美元)。 -
将派生列命名
为 total_usd 并使用以下 SQL 表达式:
舍入(合约 x 价格 x 汇率,2)

-
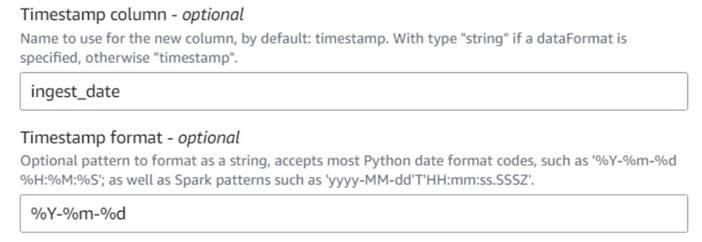
添加 “
添加当前时间戳
” 节点并将该列命名为 in
gest_date。 -
使用
%y-%m-%d格式 作为时间戳(出于演示目的,我们只使用日期;如果你愿意,你可以将其设置得更精确)。
保存历史订单表
要保存历史订单表,请完成以下步骤:
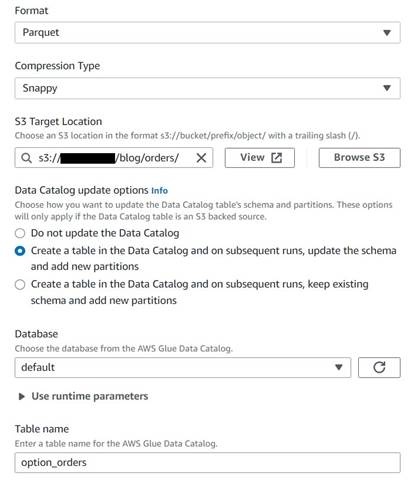
-
添加 S3 目标节点并将其
命名为订单表。 - 使用快速压缩配置 Parquet 格式,并提供用于存储结果的 S3 目标路径(与摘要分开)。
- 选择在 数据目录中 创建表,然后在后续运行时更新架构并添加新分区 。
-
输入目标数据库和新表的名称,例如:o
ption_orders。
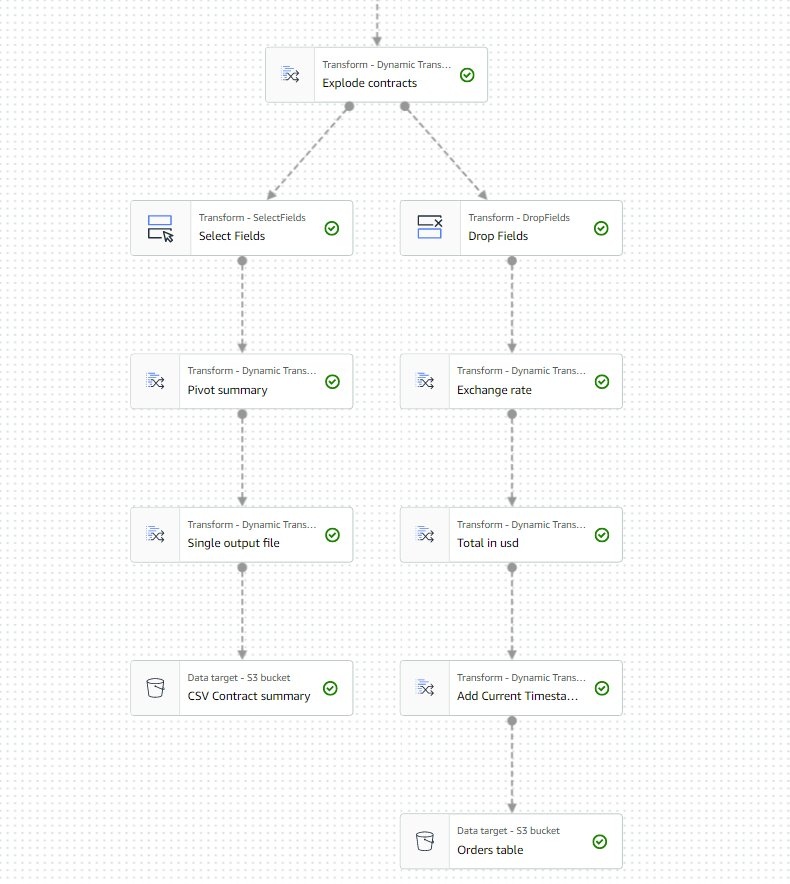
现在,示意图的最后一部分应该与下图类似,两个分支分别代表两个单独的输出。
成功运行作业后,您可以使用像 Athena 这样的工具通过查询新表来查看作业生成的数据。你可以在 Athena 列表中找到该表,然后选择 “ 预览表 ”, 或者直接运行 SELECT 查询(将表名更新为你使用的名称和目录):
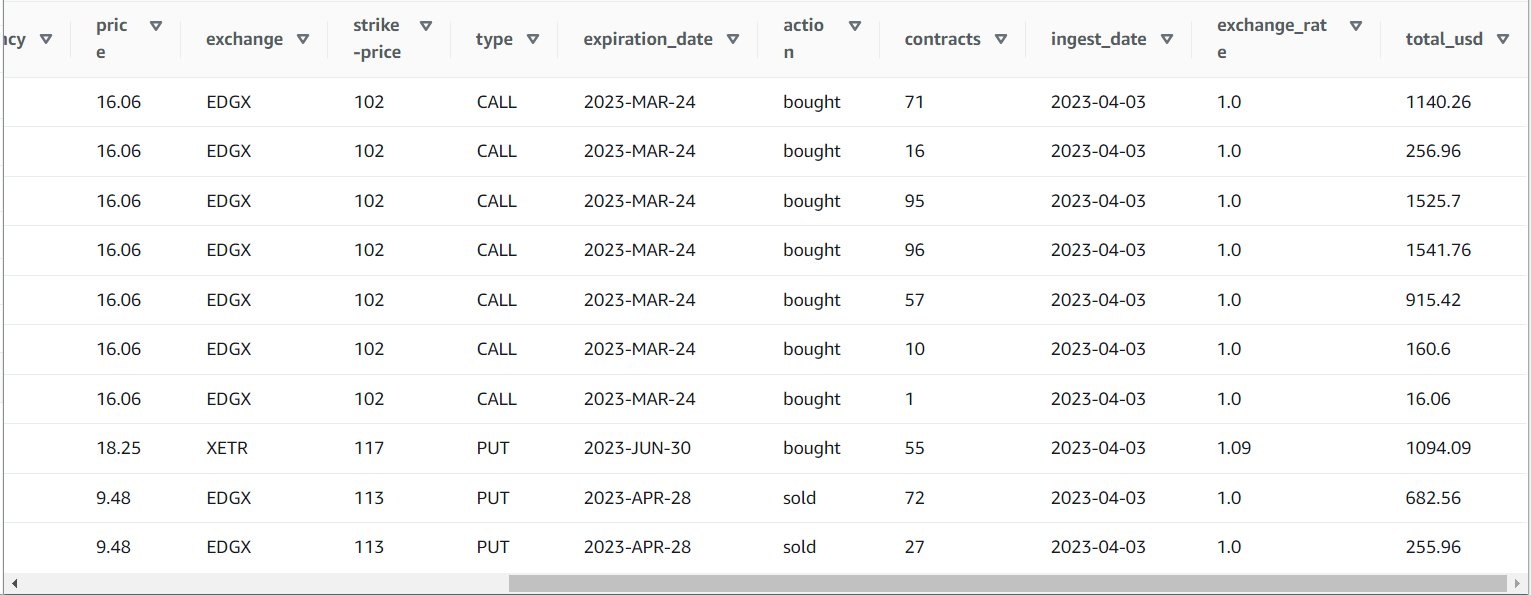
从默认值中选择 *。option_orders 限制 10
您的表格内容应与以下屏幕截图类似。
清理
如果您不想保留此示例,请删除您创建的两个任务、Athena 中的两个表以及存储输入和输出文件的 S3 路径。
结论
在这篇文章中,我们展示了 亚马逊云科技 Glue Studio 中的新转换如何帮助您以最低配置进行更高级的转换。这意味着您可以实现更多 ETL 用例,而无需编写和维护任何代码。新的转换已经在 亚马逊云科技 Glue Studio 上线,因此您现在可以在视觉工作中使用新的转换。
作者简介
 贡萨洛·埃雷罗斯
是 亚马逊云科技 Glue 团队的高级大数据架构师。
贡萨洛·埃雷罗斯
是 亚马逊云科技 Glue 团队的高级大数据架构师。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。