我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 亚马逊云科技 Lambda SnapStart 更快地启动
本博客由 亚马逊云科技 Lambda 高级产品经理 Tarun Rai Madan、亚马逊云科技 Lambda 高级首席工程师迈克·丹尼洛夫和 EC2 副总裁/杰出工程师 Colm Maccárthaigh 撰写。
概述
当应用程序启动时,无论是手机上的应用程序还是无服务器的 Lambda 函数,它们都会经历初始化。初始化过程可能因应用程序和编程语言而异,但即使是用最高效的编程语言编写的最小的应用程序,也需要进行某种初始化才能做任何有用的事情。对于 Lambda 函数,
使用 SnapStart,可以在发布函数版本时提前完成函数的初始化。Lambda 拍摄初始化执行环境的内存和磁盘状态的
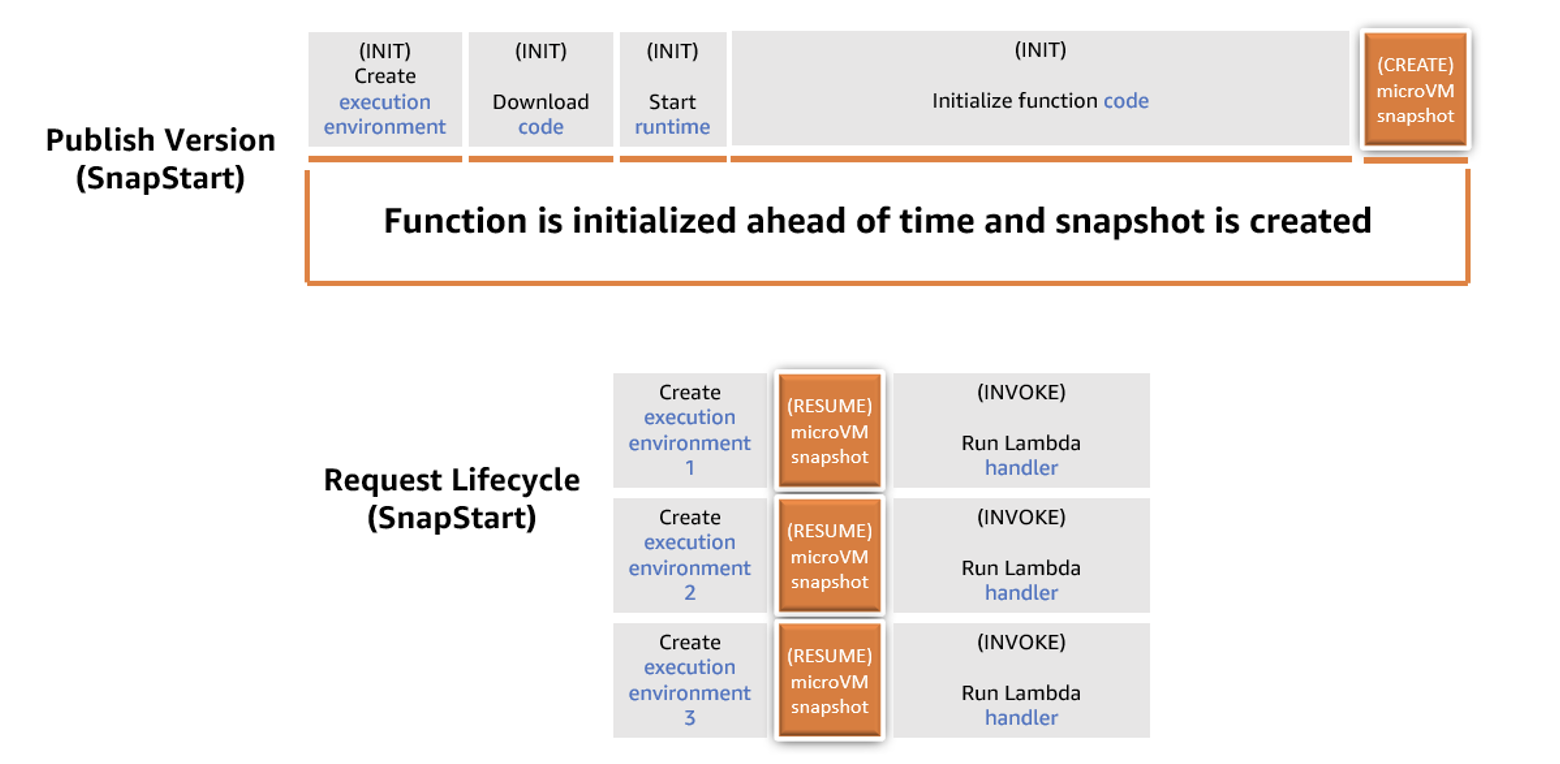
下图比较了非 SnapStart 函数和 SnapStart 函数的冷启动请求生命周期。初始化函数所需的时间被使用 SnapStart 更快的恢复阶段所取代,而初始化函数是导致高启动延迟的主要因素。

非 SnapStart 功能与 SnapStart 功能对比的示意图
非 SnapStart 功能与 SnapStart 功能的请求生命周期
预加载初始化阶段可以显著提高延迟敏感型 Lambda 函数(例如对初始化时间敏感的同步微服务)的启动性能。由于 Java 是一种动态语言,有自己的运行时和垃圾回收器,所以用 Java 编写的 Lambda 函数可能是初始化速度最慢的函数之一。对于需要频繁扩展的应用程序,初始化引入的延迟(通常称为冷启动)可能会给最终用户带来次优体验。现在,使用 SnapStart 可以更快地启动此类应用程序。
通过缩短函数的启动时间,SnapStart 显著减少了在函数扩展时需要创建的执行环境的数量(从而减少了冷启动的数量)。例如,假设您的函数在三秒钟内处理 100 个请求,并且在没有 SnapStart 的情况下冷启动时间为六秒。这需要 Lambda 创建 100 个并发执行环境,从而导致 100 次冷启动。在这种情况下,假设 SnapStart 将冷启动减少到一秒。这将要求 Lambda 仅创建 33 个并发执行环境,在第二个环境中可以处理 33 个请求。然后,相同的 33 个执行环境将在第二和第三秒钟内重复使用来处理剩余的请求。
亚马逊云科技 在
SnapStart 和独特性
Lambda SnapStart 通过重复使用单个初始化的快照来恢复多个执行环境,从而加快应用程序的速度。因此,在初始化期间包含在快照中的独特内容可在执行环境中重复使用,因此可能不再是唯一的。加密软件是将状态唯一性作为关键考虑因素的一类应用程序,它假设随机数确实是随机的(既是随机的,也是不可预测的)。如果在初始化期间将诸如随机种子之类的内容保存在快照中,则会在多个执行环境恢复时重复使用这些内容,并可能生成可预测的随机序列。
为了保持唯一性,您必须在使用 SnapStart 之前验证先前在初始化 期间 生成的任何唯一内容现在都是在初始化 之后 生成的。这包括用于生成伪随机性的唯一 ID、唯一机密和熵。
多个执行环境从共享快照中恢复
SnapStart 生命周期
但是,我们已经实施了一些措施,以使客户更容易保持独特性。
首先,应用程序直接生成这些独特的项目并不常见,也不是最佳做法。不过,值得确认您的应用程序是否正确处理了唯一性。这通常是检查函数的初始化方法中是否存在任何唯一的 ID、密钥、时间戳或 “自制” 熵。
Lambda 提供了 SnapStart
例如,以下 Lambda 函数在初始化期间为每个执行环境创建唯一的日志流。当执行环境重复使用快照时,这个唯一值会被重复使用。
public class LambdaUsingUUID {
private AWSLogsClient logs;
private final UUID sandboxId;
public LambdaUsingUUID() {
sandboxId = UUID.randomUUID(); // <-- unique content created
logs = new AWSLogsClient();
}
@Override
public String handleRequest(Map<String,String> event, Context context) {
CreateLogStreamRequest request = new CreateLogStreamRequest(
"myLogGroup", sandboxId + ".log9.txt");
logs.createLogStream(request);
return "Hello world!";
}
}
当你对前面的代码运行扫描工具时,以下消息有助于识别假定唯一性的潜在实现。解决此类情况的一种方法是将唯一 ID 的生成移到函数的处理方法中。
H C SNAP_START: Detected a potential SnapStart bug in Lambda function initialization code. At LambdaUsingUUID.java: [line 7]许多应用程序使用的最佳做法是依靠系统库和内核来实现唯一性。它们长期以来一直在处理密钥和ID可能被无意中复制的其他情况,例如在分叉或克隆过程中。亚马逊云科技 已与上游内核维护人员和开源开发人员合作,因此现有的保护机制使用 SnapStart 支持的开放标准虚拟机生成 ID ( vmgenid )。 vmgenid 是一种模拟设备,它向内核公开了一个 128 位、加密随机的整数值标识符,并且在所有恢复的 microVM 中具有统计学上的唯一性。
Lambda 包含的
Lambda 的请求 ID 在每次调用中已经是唯一的,可以使用 Lambda 请求对象的 g
其次,如果您确实想在 Lambda 函数初始化阶段直接创建唯一的数据,Lambda 支持
计算启动时长和计费时长
当 Lambda 服务在激活 SnapStart 的情况下在向上扩展时创建新的执行环境时,该函数将从快照中恢复,而不是从头开始初始化。为了帮助计算 SnapStart 的启动时长和计费时长,亚马逊云科技 更新了 CloudWatch 中浮现的指标,将恢复快照所需的时间(还原时长)包括在内,而初始化函数的时间(初始化时长)是单独报告的一部分。使用 SnapStart 时 Lambda 函数的启动时长(或冷启动持续时间)是还原持续时间与代码在函数处理程序中运行时长(持续时间)的总和。
还原时长包括 Lambda 恢复快照、加载运行时 (JVM) 和运行任何 AfterRestore 挂钩所花费的时间。您无需按恢复快照所花费的时间付费。但是,运行时 (JVM) 加载、执行任何 AfterRestore 挂钩和信号准备就绪状态所需的时间将计入计费的 Lambda 函数时长。亚马逊云科技 正在努力在报告的指标中单独显示该计费部分。您还需要为部署或更新函数时发生的一次性初始化以及在处理程序之外声明的任何 BeforeCheckpoint 挂钩的持续时间收费。
为了演示计费结构,我使用了 介绍亚马逊云科技 Lambda SnapStart的
结论
本博客介绍了 SnapStart 如何在幕后优化启动性能,并概述了有关独特性的注意事项。我们还向客户介绍了 亚马逊云科技 Lambda(通过扫描工具和运行时挂钩)提供的新接口,以保持其 SnapStart 功能的独特性。此外,我们还通过示例帮助您了解如何使用 SnapStart 计算启动时长和计费时长。
多项开源工作使SnapStart成为可能,包括鞭炮、Linux、Crac、OpenSSL等。亚马逊云科技 感谢使之成为可能的维护者和开发人员。通过这项工作,我们很高兴推出适用于 Java 的 Lambda SnapStart,我们希望这是众多其他功能中第一款受益于 SnapStart MicroVMS 提供的性能节省和增强安全性的功能。
如需更多无服务器学习资源,请访问
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。