我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Amazon Marketplace 的 AssemblyAI 语音转文本模型开始构建语音智能
随着组织每天收集数千小时的电话、会议和客户互动,语音智能和语音转文本 (STT) 技术已变得至关重要。光靠原始音频并不能推动决策——组织需要情报来大规模地从语音数据中提取价值。语音智能结合了语音识别、自然语言处理 (NLP) 和机器学习 (ML),可将语音数据转化为切实可行的见解。现代 STT 模型可以准确地转录对话,并使用其他工具来分析情绪、检测关键话题并生成自动摘要以获得更深入的见解。语音情报和 STT 技术为多个行业用例提供服务,包括呼叫分析和对话情报、医疗保健文档、客户服务、视频内容优化、法律调查与合规、销售情报和指导等。随着生成式人工智能的出现和模型的改进,这些应用程序对有效 STT 模型的需求持续增长。
AssemblyAI 是亚马逊云科技 Marketplace 的独立软件供应商(ISV),是一家以研究为导向的组织,致力于推动全球语音人工智能技术的发展和普及化。他们成立于 2017 年,已经建立了一个由跨学科研究领导者、科学家和工程师组成的团队,致力于创建超人语音人工智能模型,为语音数据应用开启新的可能性。
AssemblyAI 技术通过简单、便于开发人员的 API 为全球成千上万的客户和成千上万的开发人员提供服务。AssemblyAI 提供全面的语音 AI 功能,包括:
- 核心语音转文本
- 扬声器检测
- 自动语言检测
- 情绪分析
- 章节检测
- 个人身份信息 (PII) 编辑
Universal-2 模型表明了 AssemblyAI 致力于突破语音人工智能可能性的界限。该模型通过解决语音识别中的关键挑战、提高专有名词准确性、格式和大小写以及时间戳生成来实现高精度。AssemblyAI 采用以研究为中心的方法来构建准确、功能强大、易于集成的语音人工智能模型。
这篇文章展示了如何开始使用来自亚马逊云科技 Marketplace AI 的 API,以及如何通过几个步骤调用这些模型 API 来构建初始概念证明(POC)。
解决方案概述
AssemblyAI 的语音转文本服务通过两阶段管道处理音频。第一阶段使用 Universal-2 自动语音识别 (ASR) 模型,这是一个在 1250 万小时的多语言音频数据上训练的 6 亿个参数 Conformer RNN-T 模型。该模型在处理多个扬声器、口音和背景噪音的同时将语音转换为文本。第二阶段使用神经模型进行文本格式化,处理标点符号、大小写和文本标准化等任务,以生成干净、可读的笔录。
除了基本的转录外,客户还可以启用与核心 ASR 流程一起运行的其他情报模型。其中包括用于跟踪谁说了什么的说话人识别、了解情感背景的情感分析、用于自动对对话进行分类的话题检测、用于提取关键点的内容摘要以及用于保持隐私合规性的 PII 编辑。所有这些模型通过相同的 API 接口无缝协同工作。下图显示了高级架构。
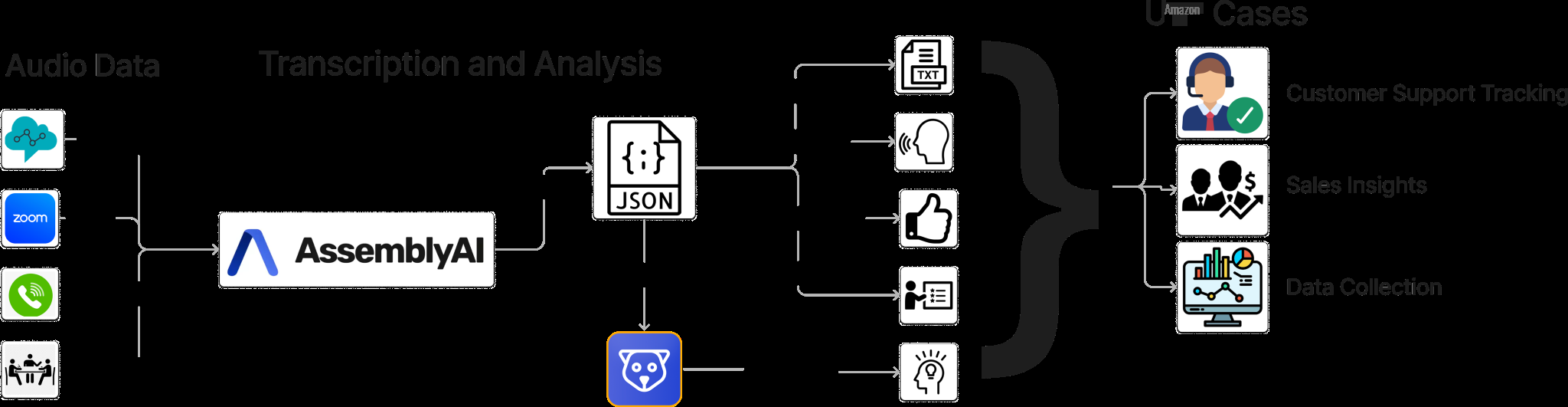
图 1:AssemblyAI 转录时 API 的高级架构图
先决条件
在开始之前,请确保您具备以下先决条件:
- 可以访问 Amazon Simple Storage Service (Amazon S3) 的亚马逊云科技账户。
- AssemblyAI 的 API 可以在 Amazon Marketplace 中购买。你也可以访问 AssemblyAI 的网站申请试用账户。对于试用账户,该账户预先加载了一些积分,客户可以立即使用这些积分进行 POC 测试。
- 成功使用 AssemblyAI 创建帐户后,请确保将 API 密钥保存在安全的地方。
- 执行以下 Python 代码,为解决方案演练中的场景做准备:
!pip install assemblyai
import assemblyai as aai
aai.settings.api_key = "xxxxxxxx" #your AssemblyAI API key解决方案演练
在本节中,我们将深入探讨 AssemblyAI 的 API 可以找到高价值的五个案例。每个案例都附带一个代码片段,读者可以在自己的环境中进行测试。
- 从本地文件转录音频
- 转录来自 Amazon S3 的音频文件
- 扬声器微调
- 自动语言检测
- 个人身份信息编辑
从本地文件转录音频
这是基本设置,其中音频文件位于执行代码的本地存储库中。AssemblyAI API 支持最常见的音频和视频文件格式,例如 mp3、m4a、m4p、wav 或 wma。建议您的音频文件采用其原生格式,无需进行额外的转码或文件转换。有关音频文件格式的更详细讨论,请参阅此 AssemblyAI 博客。从 AssemblyAI 托管的网站上下载公开可用的音频文件并将其保存到本地文件夹。执行以下代码片段来执行转录:
# Transcribe an audio from a local audio file
transcriber = aai.Transcriber()
transcript = transcriber.transcribe("./Audios/ford_clip_trimmed.mp3")
print(transcript.text)结果应类似于以下笔录:
晚上好。去年 1 月 15 日,我向你们的参议员和国会众议员提出了一项使我们的国家独立于外国能源的全面计划。到 1985 年。这样的计划早就该出台了。我们越来越多地听从他人的摆布,因为我们整个经济赖以运转的燃料。以下是不会消失的事实和数字。美国目前约有 37% 的石油需求依赖外国来源。十年后,如果我们什么都不做,如果其他人选择向我们出售,我们将以其他人固定的价格进口一半以上的石油。在两年半的时间里,我们遭受外国石油禁运的脆弱性将是两个冬天前的两倍。现在,我们每年为外国石油支付 250 亿美元。五年前,我们每年仅支付 30 亿美元。五年后,如果我们什么都不做,谁知道还有多少亿美元会流出美国。
转录来自 Amazon S3 的音频文件
在许多组织中,音频数据保存在云存储中,例如 Amazon S3。要转录来自 S3 存储桶的音频文件,AssemblyAI 需要临时访问该文件。要提供这种访问权限,您需要生成一个预签名 URL,这是一个内置临时访问权限的 URL。有关如何生成预签名 URL 的更多详细信息,请参阅使用预签名 URL 共享对象。
执行以下代码片段来执行转录:
import requests
import time
p_url = "S3 pre-signed url"
assembly_key = "xxxxxxxx" #your AssemblyAI API
# Use your AssemblyAI API Key for authorization.
headers = {"authorization": assembly_key, "content-type": "application/json"}
# Specify AssemblyAI's transcription API endpoint.
upload_endpoint = "https://api.assemblyai.com/v2/transcript"
# Use the presigned URL as the `audio_url` in the POST request.
json = {"audio_url": p_url}
# Queue the audio file for transcription with a POST request.
post_response = requests.post(upload_endpoint, json=json, headers=headers)
# Specify the endpoint of the transaction.
get_endpoint = upload_endpoint + "/" + post_response.json()["id"]
# GET request the transcription.
get_response = requests.get(get_endpoint, headers=headers)
# If the transcription has not finished, wait util it has.
while get_response.json()["status"] != "completed":
get_response = requests.get(get_endpoint, headers=headers)
time.sleep(5)
# Once the transcription is complete, print it out.
print(get_response.json()["text"])扬声器微调
扬声器分频是音频的关键组成部分,因为它解决了确定说话者身份以及他们在录音中何时说话的挑战。这种功能对于各种任务至关重要,例如提高笔录的清晰度和结构、实现高级分析以及实现个性化和自定义。
执行以下代码片段来执行转录:
config = aai.TranscriptionConfig(speaker_labels=True)
transcriber = aai.Transcriber(config=config)
FILE_URL = "https://github.com/AssemblyAI-Examples/audio-examples/raw/main/20230607_me_canadian_wildfires.mp3"
transcript = transcriber.transcribe(FILE_URL)
# Extract all utterances from the response
utterances = transcript.utterances
# For each utterance, print its speaker and what was said
for utterance in utterances:
speaker = utterance.speaker
text = utterance.text
print(f"Speaker {speaker}: {text}")以下记录显示了此示例的部分结果:
发言人 A:加拿大数百场野火产生的烟雾正在触发空气质量警报,从缅因州到马里兰州再到明尼苏达州的天际线呈灰色且烟雾弥漫。在某些地方,空气质量警告包括待在室内的警告。我们想更好地了解这里发生了什么以及为什么,所以我们给约翰·霍普金斯大学环境健康与工程系副教授彼得·德卡洛打了电话。早上好,教授。
发言者 B:早上好。
发言人 A:那么,目前导致这一轮野火影响了这么多遥远地区的人的状况究竟是什么呢?
发言人 B:嗯,有几件事。这个季节已经非常干燥了,而我们在美国受到打击的事实是因为有几个天气系统基本上是在将加拿大野火产生的烟雾引导到大西洋中部和东北部,然后将烟雾投到那里。
发言人 A:那么在这片雾霾中,是什么让它有害呢?而且我认为这是有害的。
自动语言检测
自动语言检测是音频分析的另一个重要功能,因为它使系统能够更准确、更高效地处理和解释口头内容。通过启用多语言支持和特定语言的自定义,它可以增强许多应用程序中的用户体验。执行以下代码片段来执行转录:
config = aai.TranscriptionConfig(language_detection=True)
transcriber = aai.Transcriber(config=config)
FILE_URL = "https://assembly.ai/news.mp4"
transcript = transcriber.transcribe(FILE_URL)
transcript.json_response['language_code']此示例中的输出很短:en。
有关支持语言的完整列表,请参阅支持的语言文档。
个人身份信息编辑
安全始终是亚马逊云科技的头等大事,对于 AssemblyAI 来说也是如此。AssemblyAI 提供的个人身份信息编辑功能可以帮助维护敏感信息的隐私和安全,从而使客户可以在不构成法律和监管风险的情况下构建安全可信的应用程序。用户可以通过配置设置控制他们想要保留哪种类型的敏感数据,例如信用卡号、电子邮件地址和电话号码,如以下代码片段所示。
config = aai.TranscriptionConfig()
config.set_redact_pii(
# What should be redacted
policies=[
aai.PIIRedactionPolicy.credit_card_number,
aai.PIIRedactionPolicy.email_address,
aai.PIIRedactionPolicy.location,
aai.PIIRedactionPolicy.person_name,
aai.PIIRedactionPolicy.phone_number,
],
# How it should be redacted
substitution=aai.PIISubstitutionPolicy.hash,
)
transcriber = aai.Transcriber(config=config)
# Use your own audio file which contains some fake PII info for testing
FILE_URL = "https://example.org/audio.mp3"
transcript = transcriber.transcribe(FILE_URL)
print(transcript.text)AssemblyAI 提供了本文未涵盖的其他几种产品,包括用于实时转录的流媒体 API 和用于使用大型语言模型(LLM)从笔录中提取下游见解的 LeMur。有关更多详细信息,请参阅 AssemblyAI 文档。
结论
AssemblyAI 致力于为开发人员构建高质量的 API 平台,以利用人工智能转换和理解语音数据,从而创造创新的产品和服务。他们的语音转文本模型解决了关键的转录挑战。AssemblyAI 的最新 Universal-2 模型侧重于解决影响现实世界语音人工智能工作流程的最后一英里问题,例如提高字母数字和稀有单词的准确性。
了解有关 Universal-2 进展的更多信息:阅读 AssemblyAI 博客
查看 AssemblyAI 与竞争对手的对比情况:查看基准测试
深入了解 Universal-2 背后的研究:探索研究
你可以通过访问 AssemblyAI 在亚马逊云科技 Marketplace 的清单或在 AssemblyAI 网站上创建账户来开始使用 AssemblyAI 的 API。
作者简介
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。