我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用带有并行加载和筛选选项的 亚马逊云科技 DMS 加快数据库迁移速度
有些迁移可能需要很长时间,因为它们有很大的表。但是, 并行加载和筛选等亚马逊云科技
亚马逊云科技 DMS 是一项数据迁移服务,具有支持同构和异构数据库迁移的强大功能。亚马逊云科技 DMS 提供并行加载和筛选选项,以最佳方式加载数据。它还有助于减少数据加载时间。
在这篇文章中,我们将演示如何使用 亚马逊云科技 DMS
并行满载
- 使用 partitions-auto 加载所有现有的表分区或视图分区,或者使用分区列表类型仅加载带有指定分区数组的选定分区
- 使用子分区自动类型加载所有现有的表或视图子分区(仅限 Oracle 端点)
- 通过指定指定列的范围类型,使用列值边界加载您定义的表、视图或集合区段
但是,重要的是要知道在哪里使用分区自动而不是分区列表,范围是一个不错的选择,以及这些设置的可能组合。
自动分区
当我们使用带有 partitions-auto 类型的并行加载选项时,每个表、视图、集合分区(或分段)或子分区都会自动分配给自己的线程。让我们看看如何使用分区自动来优化数据加载。
例如,我们 在 Oracle 中有一个包含 2.58 亿行的表
SALES_HIST,在 sales_
year 列上定义了五个分区:
我们在任务设置中使用了以下不带并行负载的配置,并测量了数据加载时间的性能:
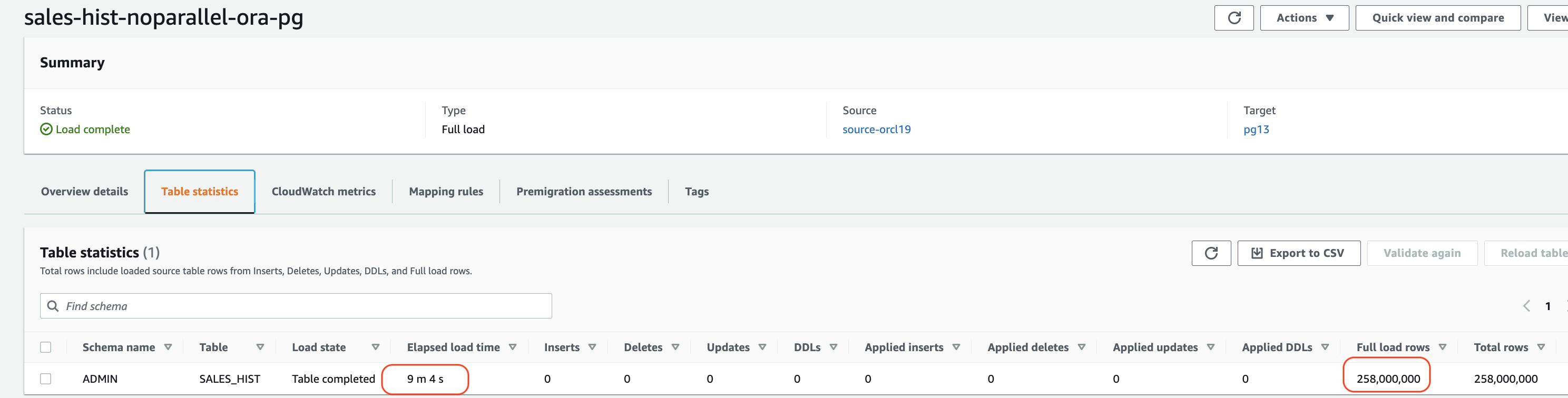
以下屏幕截图显示我们的任务花了大约 9 分钟。
然后,我们使用类型为 partition-auto 修改了并行加载任务中的表设置。以下代码是我们更新后的任务设置 JSON:
如以下屏幕截图所示,新任务花了 6 分钟才迁移相同数量的行。
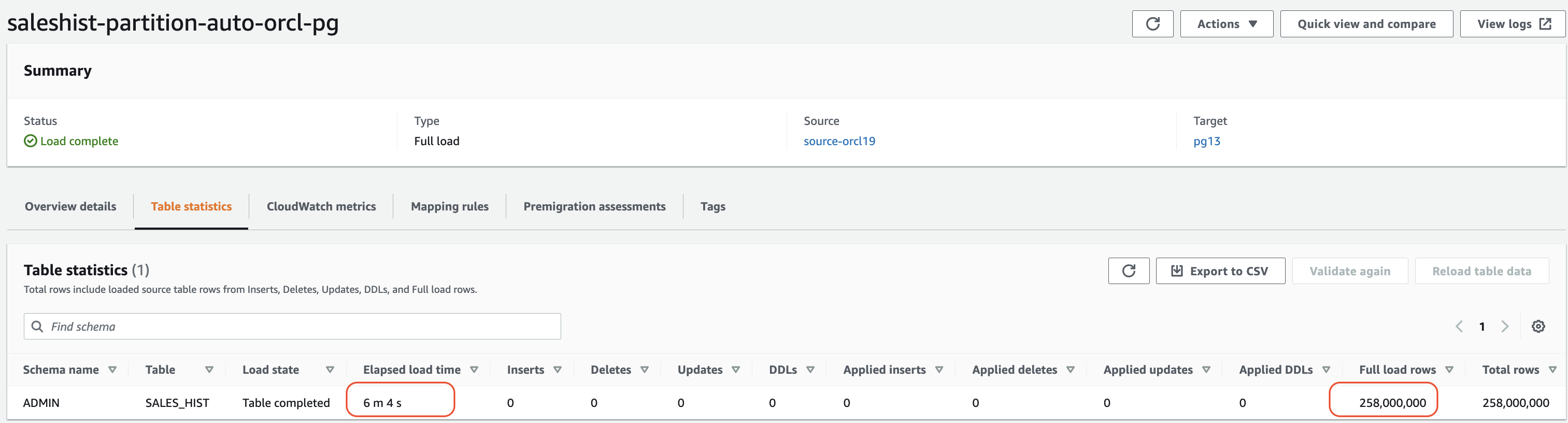
让我们仔细看看
S_HIST
表有五个分区并行加载数据。

亚马逊云科技 建议您不要使用具有并行加载功能的单个任务加载大量大型集合。亚马逊云科技 DMS 通过 m
axFullloadSubTasks 任务设置参数的值限制资源争用以及并行加载的分段数量,该参数的最
大值为 49。
有关 CloudWatch 日志记录的更多信息,请参阅
分区列表
为了克服并行加载的这个问题,亚马逊云科技 DMS 提供了另一种并行加载分区的选项:分区列表。
使用 partitions-list,只能并行加载表或视图的指定分区,这与 partition-auto 不同,在分区中,所有分区都是并行加载的。同样,您指定的每个分区都分配给自己的线程。
让我们看看如何使用分区列表并通过为 SALES_HIST 表应用分区列表来优化数据加载。
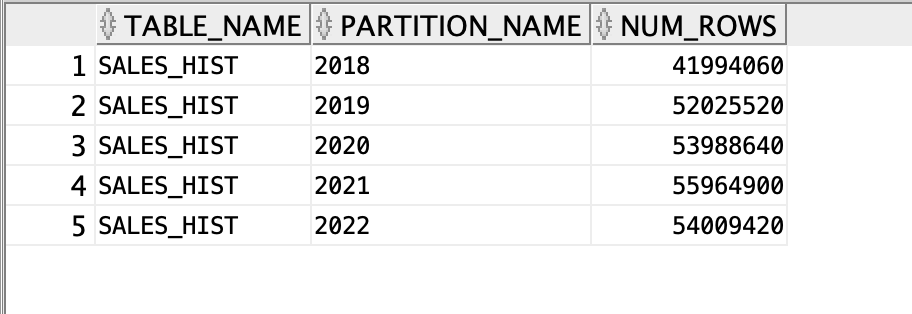
以下查询显示了如何将行分配给 SALE
S_H
IST 表中的每个分区:
在此测试中,我们创建了三个不同的任务,并将 SALE
S_HIST
表的所有分区分配给每个任务。
因此,任务 s
aleshist-partion-list-2018 年加载了两个分区(2018 年和 2019 年),任务 saleshist
-partion-list-
2020-2021 加载了两个分区(2020 年和 2021 年),任务 saleshist-partition-list-2022 加载了分区 202
2。
我们为每项任务使用了以下任务设置:
以下屏幕截图显示了每项任务的输出。
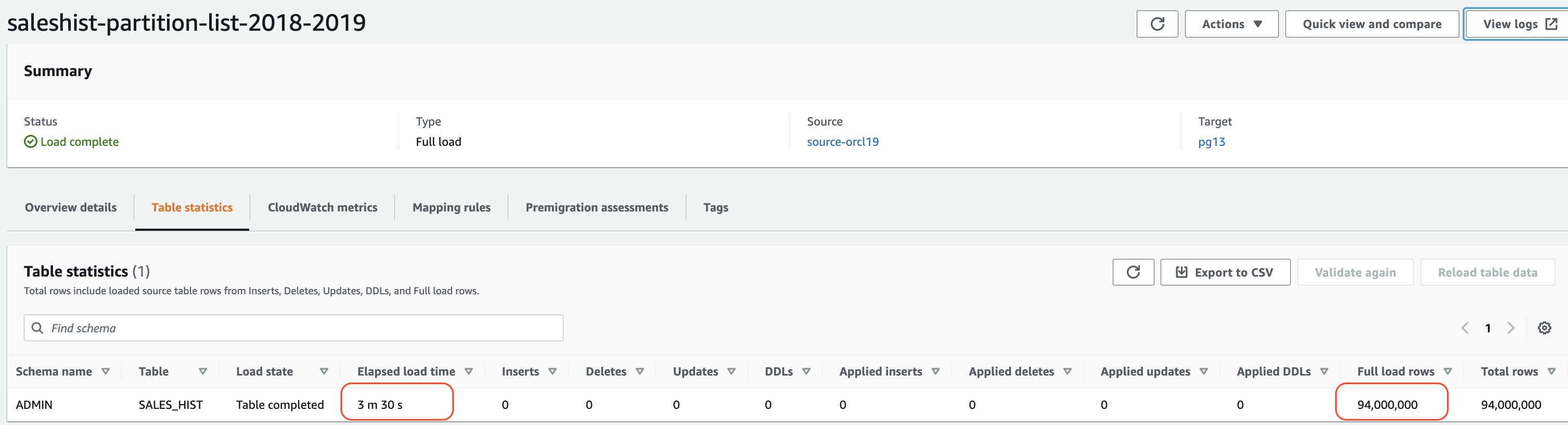
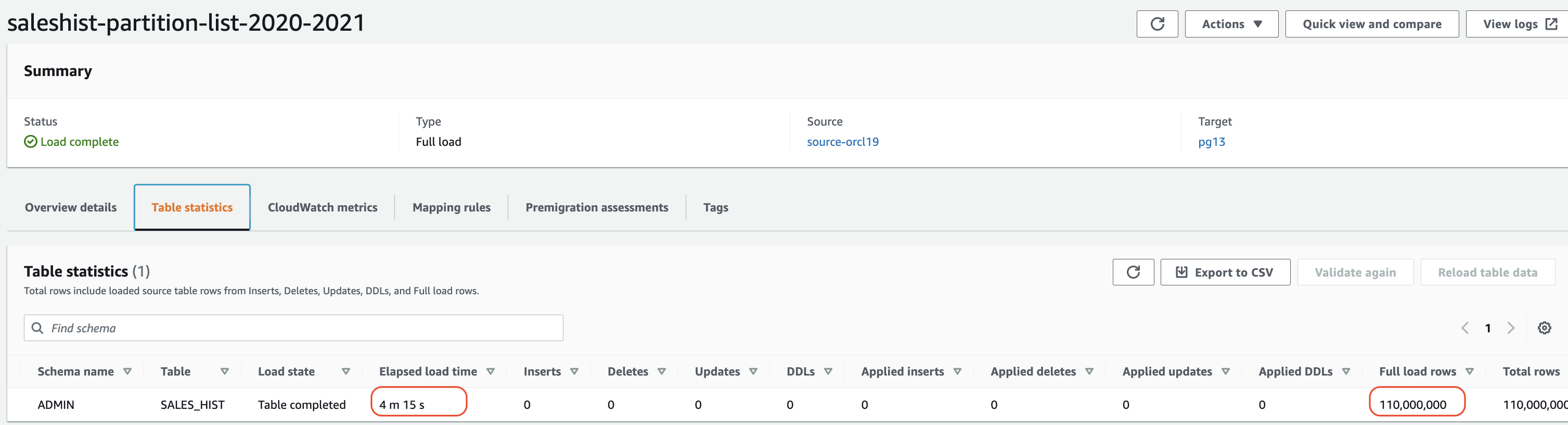
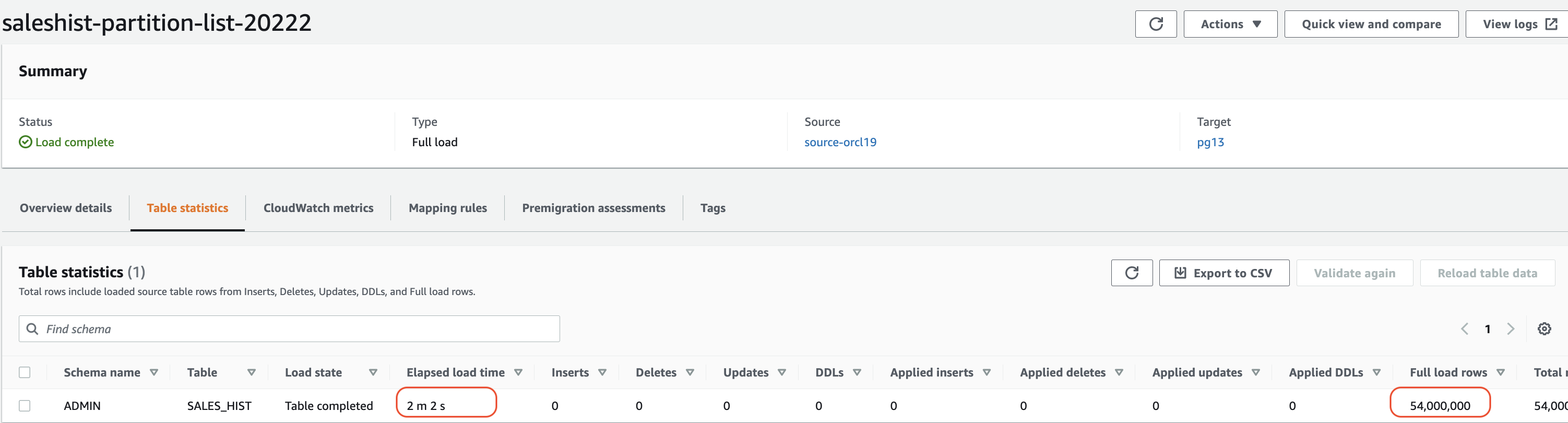
第二个任务的最大时间约为 4 分钟,这意味着我们使用分区列表创建三个任务,在短短 4 分钟内加载了所有五个分区。
你可以考虑将分区列表用于以下用例:
- 单个表有大量分区
- 你不想移动所有分区
范围
假设你有没有分区的巨大表格。如何使用并行加载来高效加载数据?
我们使用具有并行负载的范围加载我们的
SALES_HIST
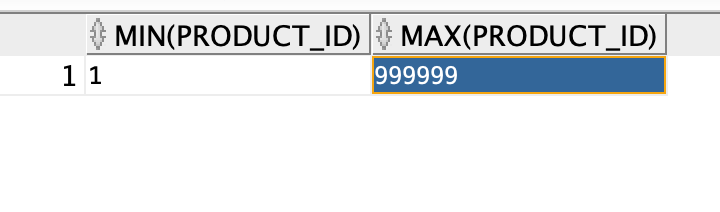
表。为此,我们首先需要知道哪一列是创建边界的好选择。使用唯一的索引列始终是个好主意。
在本例中,我们有 product_id 列,它是唯一的,在 SALES_HIST 表中建立了 索引。
首先,让我们找到该列的最小值和最大值:
通过在任务中指定类型范围,我们使用
PRODUCT_ID
创建了 10 个边界:
以下屏幕截图显示,亚马逊云科技 DMS 在 5 分钟内加载了表,与没有并行加载相比,我们的加载时间缩短了近 50%。
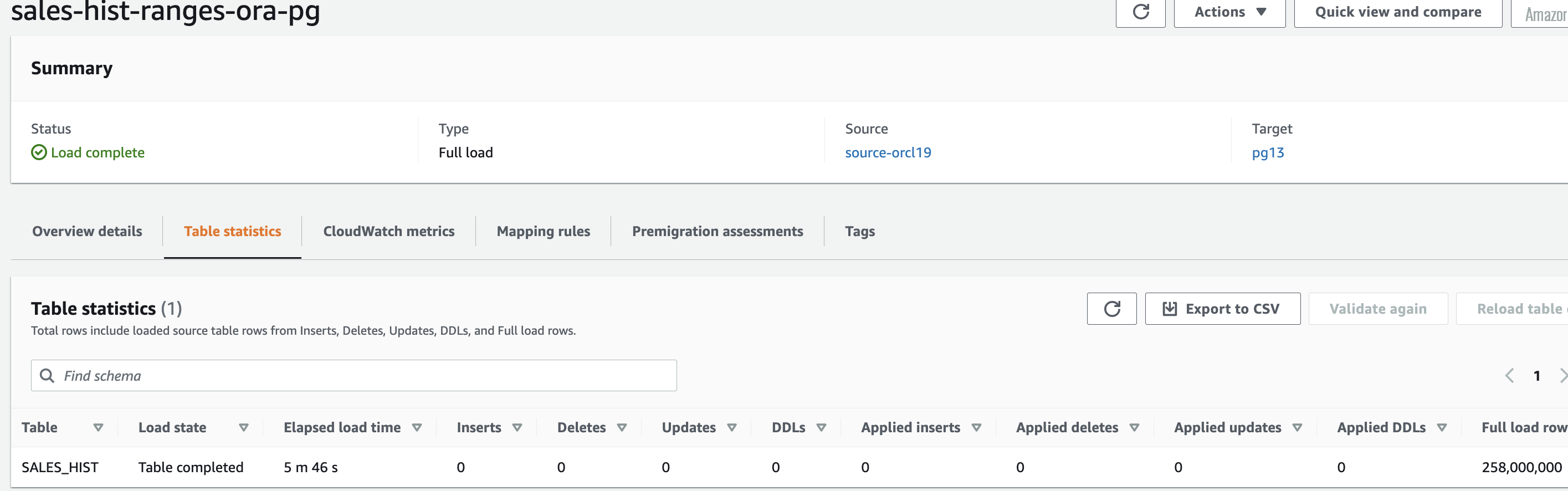
让我们仔细看看 亚马逊云科技 DMS 如何使用范围来加载数据。在这种情况下,亚马逊云科技 DMS 创建了 10 个分段,每个分段对应一个边界,并使用以下 WHERE 子句并行加载行:
-
segment1 加载产品 ID <=100000 的 行 -
segment2 加载
PRODUCT_ID <=200000 的行以及分段 1 以外的行 -
segment3 加载 PRODUCT
_ID <=300000 的行以及分段 1 和分段 2 以外的行,依此类推
CloudWatch 日志显示我们有 10 个线程(为每个边界分配一个线程)。
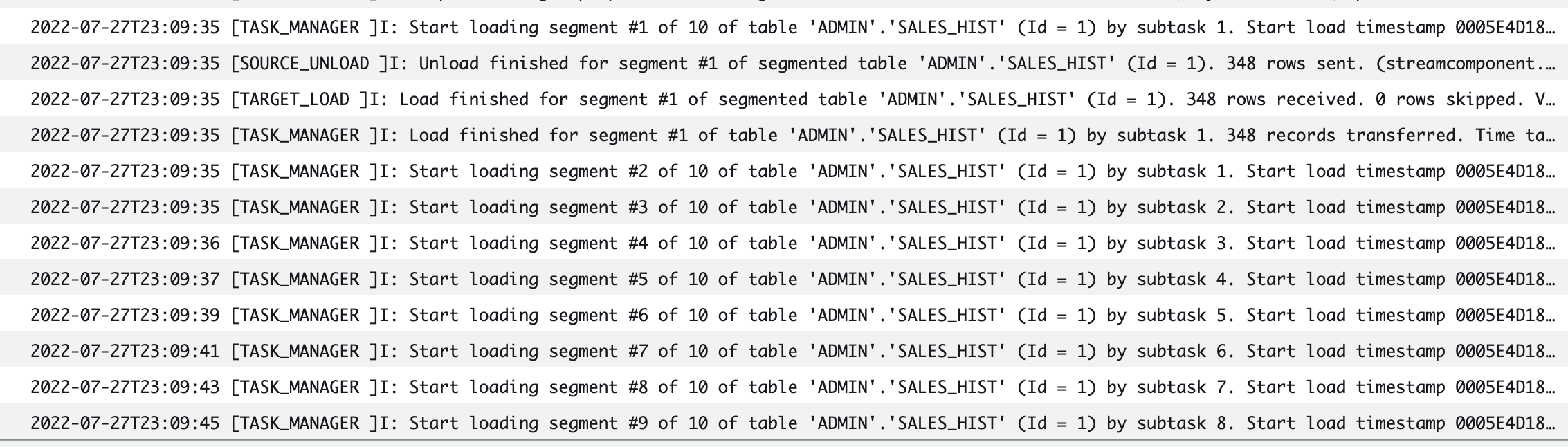
亚马逊云科技 DMS 范围选项允许您并行加载大型表的数据,即使没有分区。
使用范围时,应考虑以下几点:
- 如果可能,请使用主键或唯一索引列以避免重复
- 避免记录分布不均匀;如果可能,请使用范围列在不同范围之间均匀分配记录
- 您最多可以指定 10 列
- 您不能使用列来定义具有以下 亚马逊云科技 DMS 数据类型的分段边界:双精度、浮点数、BLOB、CLOB 和 NCLOB
- 指定索引列可以提高性能
- 您可以使用范围创建多个任务以提高性能
行过滤器
有时,即使使用了并行加载的所有选项,我们也无法获得最佳的数据加载性能。在这种情况下,我们应该怎么做?
亚马逊云科技 DMS 提供了
SALES_HIST
有超过 1.5 亿行,为了提高性能,我们希望将此表拆分为多个任务。首先,我们需要找到一个有效的过滤器来分解表格。将表格按相同的行数分解总是一个好主意。
让我们选择 SALES_YEAR 列来创建筛选行。
我们使用 SALE
S_
YEAR 列在每个分区上使用筛选运算符将表分成三个任务 ,并为每项任务使用以下任务设置:
使用过滤器时请考虑以下几点:
- 过滤器列应始终有索引。
- 尽量将表格分成相同数量的行。
- 仅对不可变列应用过滤器,这些列在创建后不会更新。
- 使用 CloudWatch 日志监控您的复制实例,不要使复制实例和源服务器负担过重。复制实例的最大配额为 100 个任务。
结论
在这篇文章中,我们分享了一些使用并行加载和筛选选项提高 亚马逊云科技 DMS 满载性能和缩短数据加载时间的最佳实践。如果您有任何反馈或问题,请在评论中留言。
作者简介
 Ashar Abb
a s 是亚马逊网络服务的数据库专业架构师。他加快了客户向 亚马逊云科技 的数据库迁移速度。他专门研究数据库,拥有 20 多年的经验。
Ashar Abb
a s 是亚马逊网络服务的数据库专业架构师。他加快了客户向 亚马逊云科技 的数据库迁移速度。他专门研究数据库,拥有 20 多年的经验。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。