我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用汇总、多维数据集和分组集等新的 SQL 结构简化 Amazon Redshift 中的在线分析处理 (OLAP) 查询
我们不断投资,通过简化 SQL 结构和添加新的运算符来简化 Redshift 的分析。现在,我们添加了 ROLLUP、CUBE 和 GROUPING SETS SQL 聚合扩展,以便在单个语句中执行多个聚合操作,并轻松地在查询中包含小计、总计和小计集合。
在这篇文章中,我们将讨论如何使用这些扩展来简化您在 Amazon Redshift 中的查询。
解决方案概述
在线分析处理 (OLAP) 是当今数据和业务分析师的有效工具。它可以帮助您在单一管理平台中查看不同聚合级别的关键任务指标。分析师可以使用 OLAP 聚合来分析购买模式,方法是按人口统计、地理和心理数据对客户进行分组,然后汇总数据以寻找趋势。这可能包括分析购买频率、购买间隔时间以及购买物品的类型。此类分析可以深入了解客户偏好和行为,可用于为营销策略和产品开发提供信息。例如,数据分析师可以查询数据以显示一个电子表格,该电子表格显示公司7月份在美国销售的特定类型的产品,将收入数字与9月份相同产品的收入数字进行比较,然后查看同期美国其他产品销售的比较。
传统上,业务分析师和数据分析师使用一组 SQL UNION 查询来实现所需的详细程度和汇总级别。但是,编写和维护可能非常耗时且麻烦。此外,使用这种方法可以实现的详细级别和汇总级别是有限的,因为它要求用户为每个不同的详细级别和汇总级别编写多个查询。
许多客户正在考虑从支持 OLAP GROUP BY 条款的其他数据仓库系统迁移到 Amazon Redshift。为了使迁移过程尽可能顺畅,Amazon Redshift 现在支持汇总集、多维数据集和分组集。这将允许更顺畅地迁移 OLAP 工作负载,同时最大限度地减少重写。最终,这将加快和简化向Amazon Redshift的过渡。业务和数据分析师现在可以编写一个 SQL 来完成多个 UNION 查询。
在接下来的部分中,我们将使用来自 TPC-H 数据集的供应商余额数据样本作为运行示例,演示 ROLLUP、CUBE 和 GROUPING SETS 扩展的使用。该数据集由不同地区和国家的供应商账户余额组成。我们将演示如何查找每个国家级别、地区级别的账户余额小计和总计,以及两者的组合。所有这些分析问题都可以由业务用户通过运行简单的单行 SQL 语句来回答。除聚合外,这篇文章还演示了如何将结果追溯到参与生成小计的属性。
数据准备
要设置用例,请完成以下步骤:
- 在 Amazon Redshift 控制台的导航窗格中,选择 编辑器,然后选择 查询编辑 器 v2 。
查询编辑器 v2 将在新的浏览器选项卡中打开。
- 创建供应商样本表并插入示例数据:
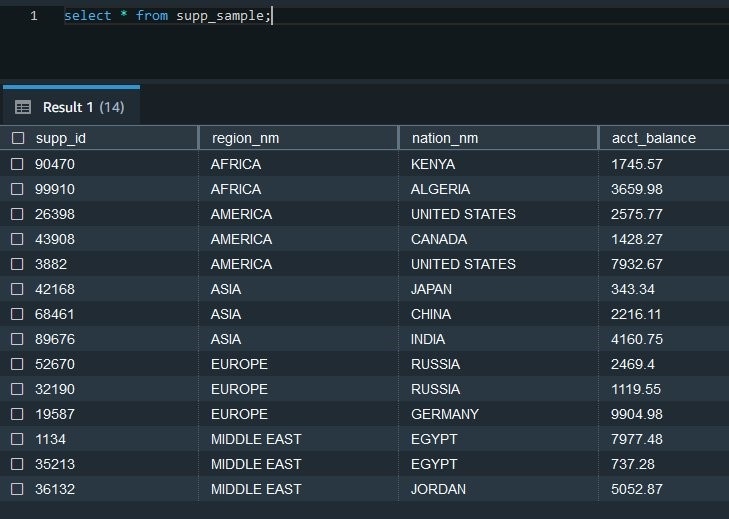
我们从在 TPC-H 数据集上运行的以下查询的结果中抽取了样本。您可以使用以下查询并获取示例记录来尝试本文中描述的 SQL 语句:
让我们在使用分组集、汇总和多维数据集扩展名运行 SQL 之前查看示例数据。
s
upp_sample
表包含来自世界各地不同国家和地区的供应商账户余额。以下是属性定义:
- supp_id — 每个供应商的唯一标识符
- region_nm — 供应商运营的地区
- nation@@ _nm — 供应商运营所在的国家
- acct_balance — 供应商的未清账户余额
分组集
GROUPING SETS 是一个 SQL 聚合扩展,用于在单个语句中按一列或多列对查询结果进行分组。您可以使用分组集来代替使用不同的 GROUP BY 键执行多个 SELECT 查询,然后合并(合并)它们的结果。
在本节中,我们将介绍如何找到以下内容:
- 每个地区的账户余额合计
- 每个国家的账户余额合计
- 两次汇总的合并结果
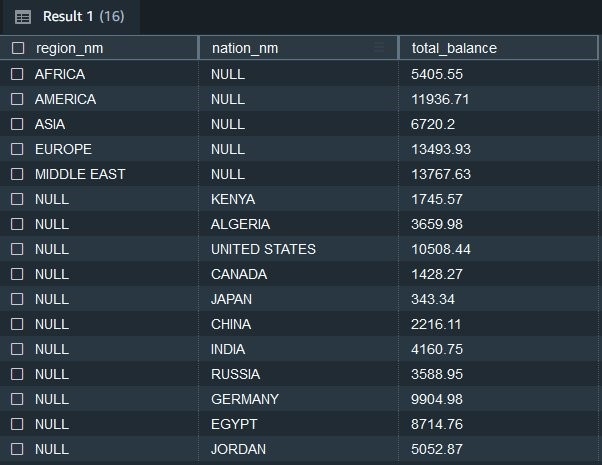
使用分组集运行以下 SQL 语句:
如以下屏幕截图所示,结果集包括按region_nm排列的账户余额,然后是nation_nm,然后将这两个结果合并为一个输出。
汇总
ROLLUP 函数生成多个分组级别的聚合结果,从最详细的级别开始,然后聚合到下一级别。它按代表小计的特定列和额外行对数据进行分组,并假定 GROUP BY 列之间存在层次结构。
在本节中,我们将介绍如何找到以下内容:
- 地区_nm和nation_nm的每种组合的账户余额
- 每个区域的汇总账户余额_nm
- 所有地区的累计账户余额
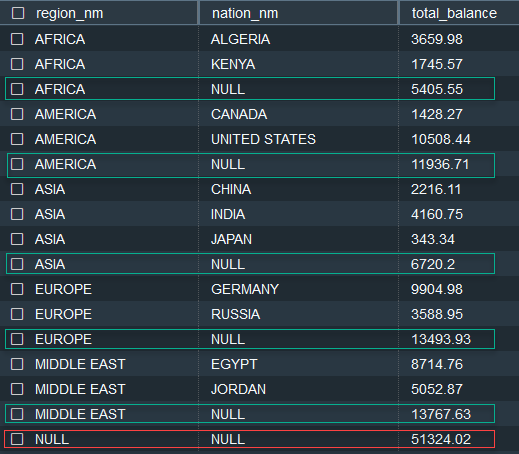
使用 ROLLUP 使用以下 SQL 语句:
以下结果显示了从 region_nm 和 nation_nm 的每种组合开始的汇总值, 并
按从 nation_nm
到
region_nm
的层次结构中向上汇总。
具有 region_nm 值 和
nation_nm
值为 NULL 的行 表示该地区的小计(用绿色标记)。
region_nm 和 nati
on_nm 均为空值的行 具有总计,即所有地区的
累计账户余额(以红色标记)。
ROLLUP 在结构上等同于以下分组集查询:
您可以使用分组集重写前面的汇总查询。但是,对于这个用例,使用 ROLLUP 是一个更简单易读的结构。
立方体
CUBE 按提供的列对数据进行分组,除了分组行之外,还返回额外的小计行,这些行代表分组列的所有级别的总计。CUBE 返回与 ROLLUP 相同的行,同时为 ROLLUP 未涵盖的每种分组列组合添加额外的小计行。
在本节中,我们将介绍如何找到以下内容:
-
每个国家的账户余额小计_nm -
每个 region_nm 的账户余额小计 -
每组 region_nm 和 nation_nm 组合的账户余额小计 - 所有地区的账户总余额
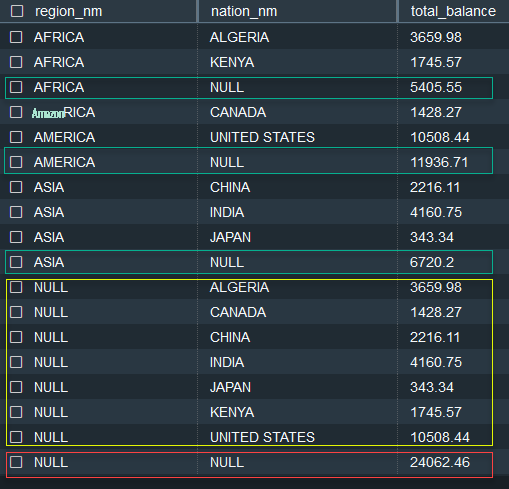
使用 CUBE 运行以下 SQL 语句:
在前面的查询中,我们添加了一个过滤器来限制结果以便于解释。您可以在测试中移除此筛选条件以查看所有区域的数据。
在以下结果集中,您可以看到区域级别的小计(用绿色标记)。这些小计记录与 ROLLUP 生成的记录相同。此外,CUBE生成了每个国家_nm的小计(用黄色标记)。最后,您还可以看到查询中提到的所有三个区域的总计(用红色标记)。
CUBE 在结构上等同于以下 GROUPING SETS 查询:
您可以使用分组集重写前面的多维数据集查询。但是,对于这种用途,使用 CUBE 是一种更简单易读的结构。
空值
NULL 是参与 GROUPING SET、ROLLUP 和 CUBE 的列中的有效值,它不与为满足返回元组架构而显式添加到结果集的空值进行汇总。
让我们创建一个订单示例表,其中包含有关订购商品、商品描述和商品数量的详细信息:
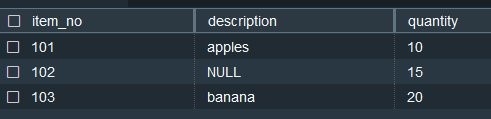
我们使用以下 ROLLUP 查询按商品编号和描述汇总数量:
在以下结果中,
item_no
102 有两行输出。用绿色标记的行是输入中的实际数据记录,用红色标记的行是由 ROLLUP 函数添加的小计记录。
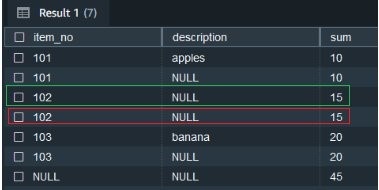
这表明输入中的空值与 SQL 聚合扩展添加的 NULL 值是分开的。
分组和分组_ID 函数
分组指示 “分组依据” 列表中的某列是否被聚合。如果元组在 expr 上分组,则分组 (expr) 返回 0;否则返回 1。GROUPING_ID(expr1、expr2、...、exprn)返回位图的整数表示形式,该位图由分组(expr1)、分组(expr2)、...、GROUPING(exprn)组成。
此功能可以帮助我们清楚地了解聚合粒度,对数据进行切片和切片,并在业务用户进行分析时应用过滤器。还为生成的聚合提供了可审计性。
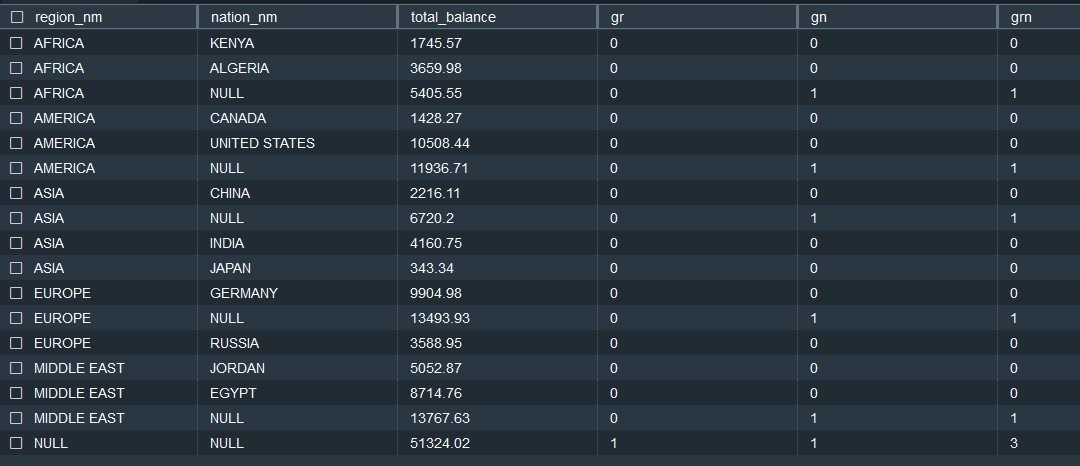
例如,让我们使用前面的 supp_sampe 表。以下 ROLLUP 查询使用了分组和分组_ID 函数:
在以下结果集中,在 nation_nm 处汇总的行具有 1 个 gn 值。这表明 total_balance 是该地区所有 nation_nm 值的汇总值。最后一行的 gr 值为 1。它表明 total_balance 是包括所有国家的地区层面的汇总值。grn 是位图的整数表示形式(二进制中的 11 转换为整数表示的 3)。
绩效评估
性能通常是一个关键因素,我们希望确保在 Amazon Redshift 中提供性能最高的 SQL 功能。我们在不同大小(5 节点 ra3-4XL、2 节点 ra
我们从 3 TB 的公共数据集中加载了供应商、地区和国家文件,并在这三个表的基础上创建了一个视图,如以下代码所示。此查询联接三个表以创建统一的记录。连接的数据集用于性能评估。
我们使用分组集、多维数据集和汇总运行了以下示例 SELECT 查询,并在下表中捕获了性能指标。
汇总:
| Cluster | Run 1 in ms | Run 2 in ms | Run 3 in ms |
| 5-node-Ra3-4XL | 120 | 118 | 117 |
| 2-node-Ra3-4XL | 405 | 389 | 391 |
| 2-node-Ra3-XLPLUS | 490 | 460 | 461 |
立方体:
| Cluster | Run 1 in ms | Run 2 in ms | Run 3 in ms |
| 5-node-Ra3-4XL | 224 | 215 | 214 |
| 2-node-Ra3-4XL | 412 | 392 | 392 |
| 2-node-Ra3-XLPLUS | 872 | 798 | 793 |
分组集:
| Cluster | Run 1 in ms | Run 2 in ms | Run 3 in ms | |
| 5-node-Ra3-4XL | 210 | 198 | 198 | |
| 2-node-Ra3-4XL | 345 | 328 | 328 | |
| 2-node-Ra3-XLPLUS | 675 | 674 | 674 | |
当我们对 ROLLUP 和 CUBE 运行相同的一组查询并使用 UNION ALL 运行时,我们看到 ROLLUP 和 CUBE 功能的性能有所提高。
| Cluster | CUBE (run in ms) | ROLLUP (run in ms) | UNION ALL (run in ms) |
| 5-node-Ra3-4XL | 214 | 117 | 321 |
| 2-node-Ra3-4XL | 392 | 391 | 543 |
| 2-node-Ra3-XLPLUS | 793 | 461 | 932 |
清理
要清理资源,请删除您在关注本文中的示例时创建的表和视图。
结论
在这篇文章中,我们讨论了在 Amazon Redshift 中添加的新聚合扩展 ROLLUP、CUBE 和 GROUPING SETS。我们还讨论了一般用例、实现示例和性能结果。您可以使用这些新的 SQL 聚合扩展来简化现有的聚合查询,并在未来的开发中使用它们来构建更简化、更易读的查询。如果您有任何反馈或问题,请将其留在评论部分。
作者简介
 Satesh Sonti
是一位来自亚特兰大的高级分析专家解决方案架构师,专门构建企业数据平台、数据仓库和分析解决方案。他在为全球银行和保险客户构建数据资产和领导复杂数据平台项目方面拥有超过16年的经验。
Satesh Sonti
是一位来自亚特兰大的高级分析专家解决方案架构师,专门构建企业数据平台、数据仓库和分析解决方案。他在为全球银行和保险客户构建数据资产和领导复杂数据平台项目方面拥有超过16年的经验。
 季燕珠
是亚马逊 Redshift 团队的产品经理。在成为产品经理之前,她曾在亚马逊 Redshift 团队担任软件工程师。她对如何构建面向客户的Amazon Redshift功能有着丰富的经验,并且始终将客户的需求视为第一要务。在她的个人生活中,燕珠喜欢绘画、摄影和打网球。
季燕珠
是亚马逊 Redshift 团队的产品经理。在成为产品经理之前,她曾在亚马逊 Redshift 团队担任软件工程师。她对如何构建面向客户的Amazon Redshift功能有着丰富的经验,并且始终将客户的需求视为第一要务。在她的个人生活中,燕珠喜欢绘画、摄影和打网球。
 Dinesh Kumar
是一名数据库工程师,在数据库、数据仓库和分析领域拥有十多年的工作经验。工作之余,他喜欢尝试不同的美食,也喜欢与家人和朋友共度时光。
Dinesh Kumar
是一名数据库工程师,在数据库、数据仓库和分析领域拥有十多年的工作经验。工作之余,他喜欢尝试不同的美食,也喜欢与家人和朋友共度时光。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。