我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用自动复制(预览版)简化从 Amazon S3 向亚马逊 Redshift 的数据提取
数据摄取是将数据从源系统获取到 Amazon Redshift 的过程。这可以通过使用众多基于亚马逊云科技的ETL工具之一来完成,例如亚马逊云科技
现在,SQL 用户可以使用亚马逊 Redshift 自动复制预览功能,通过简单的 SQL 命令轻松地将数据从亚马逊 S3 提取到亚马逊 Redshift。当 Amazon Redshift 自动复制在指定 Amazon S3 路径中检测到新文件时,就会触发复制语句并开始加载数据。这也确保了最终用户在源数据可用后不久就能在 Amazon Redshift 中获得最新数据。
这篇文章向您展示了当源文件位于 Amazon S3 上时,如何使用简单的 SQL 命令轻松地在 Amazon Redshift 中使用自动复制来构建连续文件采集管道。此外,我们还向您展示如何使用复印作业启用自动复制、如何监控作业、注意事项和最佳实践。
亚马逊 Redshift 中的自动复制功能概述
亚马逊 Redshift 中的自动复制功能通过一个简单的 SQL 命令简化了从 Amazon S3 自动加载数据的过程。您可以通过创建复印任务来启用亚马逊 Redshift 自动复制。拷贝作业是一个数据库对象,用于存储、自动执行和重用存放在 S3 文件夹中的新建文件的 COPY 语句。
下图说明了这个过程。

复印任务有以下好处:
- 数据分析师等 SQL 用户现在可以自动从 Amazon S3 加载数据,无需构建管道或使用外部框架
- 复制任务提供从 Amazon S3 位置持续和增量的数据采集,无需实施自定义解决方案
- 此功能不收取任何额外费用
-
通过附加 JOB C RE ATE 参数,可以将现有的 COPY 语句转换为拷贝 作业 - 它可以跟踪所有加载的文件并防止数据重复
- 它可以使用简单的 SQL 语句和任何 JDBC 或 ODBC 客户端轻松进行设置
先决条件
要开始使用自动复制预览,您需要满足以下先决条件:
-
一个
亚马逊云科技 账户 -
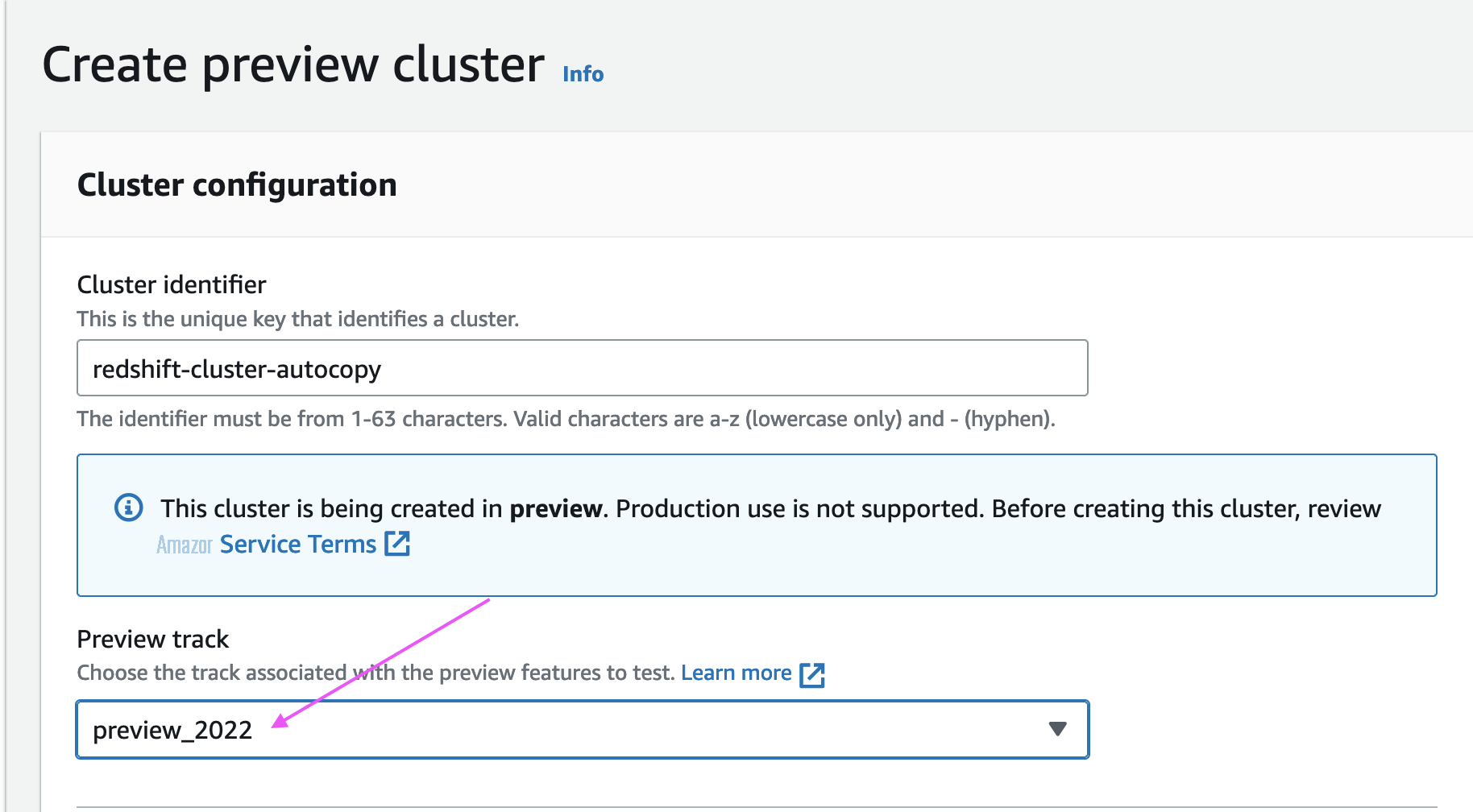
维护轨迹为 PREVIEW_2022 的亚马逊 Redshift 集群

Amazon S3 提供的 Amazon Redshift 自动复制支持可预览以下
你可以参考 SQL 笔记本
设置复印作业
在本节中,我们演示如何将文件从 Amazon S3 自动加载到 Amazon Redshift 中的数据。使用现有的
JOB CRE
ATE 参数来执行一次性设置,实现自动文件摄取。参见以下代码:
默认情况下,在复印作业上启用自动提取。
自动从单一数据源提取
使用复制作业,您可以通过创建一个任务并指定包含数据的 S3 对象的路径来自动从单个数据源提取。S3 对象路径可以引用一组具有相同密钥前缀的文件夹。
在此示例中,我们每天加载多个文件,其中包含美国所有商店的销售交易。每天的销售交易都会加载到 Amazon S3 中各自的文件夹中。

每个文件夹都包含多个 gzip 压缩文件。

以下代码创建了
store_sales 表
:
接下来,我们创建拷贝作业,自动将 gzip 压缩文件加载到 store_sales 表中 :
创建复制任务时,它会自动将位于命令中指定的 S3 对象路径中的现有 gzip 压缩文件加载到 store_sales 表中。
让我们运行一个查询,获取美国所有门店的每日销售交易总额:
显示的产出分别来自
2002-12-31
和
2003-01-0
1出售的交易。

第二天,增量销售交易数据将加载到同一 S3 对象路径中的新文件夹。

当新文件到达相同的 S3 对象路径时,复制任务会自动以增量方式将未处理的文件加载到
store_sales
表中。
2003-01-02
的所有新销售交易 都将自动提取,可以通过运行以下查询进行验证:

自动从多个数据源提取
我们还可以从多个数据源加载亚马逊 Redshift 表。使用发布/订阅模式(其中多个 S3 存储桶将数据填充到 Amazon Redshift 表中)时,您必须为每个源/目标组合维护多个数据管道。借助 COPY 命令中的新参数,可以自动执行此操作,从而高效地处理数据加载。
在以下示例中,
Customer_1
文件夹包含绿色出租车公司的销售数据,Cu
stomer_2 文件夹包含 Red Cab Comp
any 的销售数据。我们可以使用带有 JOB 参数的 COPY 命令来自动执行此摄取过程。

以下屏幕截图显示了存储在文件中的示例数据。每个文件夹都有相似的数据,但针对不同的客户。

在本示例中,这些文件的目标是亚马逊 Redshift 表 cab_sales_data。
定义目标表
cab_sales_data
:
您可以定义两个复印任务,如以下代码所示,以处理和监控来自不同客户的销售数据的摄取,在本例中为 Customer_1 和
这些作业监控
Customer_
2。
Customer_1
和
Customer_2
文件夹,并加载此处添加的所有新文件。
为每个客户分配了自己的
供应商 ID
,如以下输出所示:

手动运行复印作业
在某些情况下,拷贝作业可能需要暂停,这意味着它需要停止寻找新文件,例如,修复数据源中损坏的数据管道。
在这种情况下,可以使用 COPY JOB ALTER 命令将 “自动” 设置为 “关闭”,也可以使用 “自动关闭” 创建新的拷贝作业。设置此设置后,自动复制将不再寻找新文件。
如果需要,用户可以手动调用 COPY JOB,如果发现任何新文件,它将完成工作并进行提取。
运行拷贝作业
您可以使用以下命令在现有复印作业中禁用 “AUTO ON”:
拷贝作业更改
自动关闭
下表比较了常规复制语句和新的自动复制作业之间的语法和数据重复。
| . | Copy | Auto-Copy Job (preview) |
| Syntax |
COPY
<table-name>
|
COPY
<table-name>
|
| Data Duplication | If it is run multiple times against the same S3 folder, it will load the data again, resulting in data duplication. | It will not load the same file twice, preventing data duplication. |
对于复印作业预览,将扩展对其他数据格式的支持。
复印作业的错误处理和监控
拷贝任务会持续监视任务创建期间指定的 S3 文件夹,并在创建新文件时执行提取。在 S3 文件夹下创建的新文件只加载一次,以避免数据重复。
默认情况下,如果特定文件存在任何数据或格式问题,则拷贝作业将无法提取带有加载错误的文件,并将详细信息记录到系统表中。拷贝作业将保持
AUTO O
N 状态,包含新的数据文件,并将继续忽略先前失败的文件。
Amazon Redshift 提供以下系统表供用户根据需要监控复印任务或对其进行故障排除:
-
列出复印作业
-使用
SYS_COPY_JOB 列出存储在数据库中的所有复印作业:

-
获取复印作业摘要
-使用 SYS_LO它显示了已由复印作业处理的所有文件的汇总指标。AD_HISTORY 视图通过指定 copy_ job_id 来获取复印作业操作的汇总指标。

-
获取复印作业的详细信息
-使用
STL_LOAD_COM M ITS 获取复印作业处理的每个文件的状态和详细信息:

-
获取拷贝作业的异常详细信息
-使用
STL_LOAD_ERROR S 获取 未能从拷贝作业中提取的文件的详细信息:

文案作业最佳实践
在拷贝任务中,当检测到新文件并提取(自动或手动)时,Amazon Redshift 会存储文件名,当使用相同文件名创建新文件时,不会运行此特定任务。
以下是使用拷贝作业处理文件时的推荐最佳做法:
-
为复印作业中的每个文件使用唯一的文件名(例如,
2022-10-15-batch-1.csv)。 -
但是,你可以使用相同的文件名,只要它来自不同的复印作业:- job_Customera_Sales — s3://redshift-blogs/sales/customerA/2022-10-15-sales.csv job_Customerb_Sales — s3://redshift-blogs/sales/customerB/2022-10-15-sales.csv
- 不要更新文件内容。不要重写现有文件。现有文件中的更改不会反映到目标表中。拷贝作业不会获取更新或被覆盖的文件,因此请确保将它们重命名为新的文件名以供复印作业获取。
- 如果您需要提取已由复印作业处理过的文件,请运行常规的 COPY 语句(不是作业)。(没有复印任务的 COPY 不会跟踪已加载的文件。)例如,这在您无法控制文件名且收到的初始文件失败的情况下很有用。下图显示了本例中的典型工作流程。

- 如果您想重置文件跟踪历史记录并重新开始,请删除并重新创建复印作业。
复印作业注意事项
在预览期间,使用自动复制时需要考虑以下主要事项:
- 必须使用空的 S3 文件夹(没有现有文件)创建拷贝作业
-
不支持以下功能:-
MAXERROR 参数 -
清单文件 -
基于密钥的访问控制 -
列式数据格式 (Par quet、ORC、RCFile、SequenceFile
-
有关自动复制预览的其他注意事项的更多详细信息,请参阅
客户反馈
“通用电气宇航使用亚马逊云科技分析和Amazon Redshift来提供关键业务见解,从而推动重要的业务决策。通过支持从 Amazon S3 自动复制,我们可以构建更简单的数据管道,将数据从 Amazon S3 转移到 Amazon Redshift。这加快了我们的数据产品团队访问数据和向最终用户提供见解的能力。我们花更多的时间通过数据增加价值,而在集成上花费更少的时间。”
— 通用电气航空航天 高级首席数据架构师 Alcuin Weidus
结论
这篇文章演示了如何使用自动复制预览功能将数据从 Amazon S3 自动加载到 Amazon Redshift。这项新功能有助于使 Amazon Redshift 数据提取比以往任何时候都更容易,并允许 SQL 用户使用简单的 SQL 命令访问最新数据。
作为分析师或 SQL 用户,您可以开始使用简单的 SQL 命令将数据从 Amazon S3 提取到 Redshift,无需第三方工具或自定义实施即可访问最新数据。
作者简介
 Jason Pedreza
是 亚马逊云科技 的分析专家解决方案架构师,具有处理千兆字节数据的数据仓库经验。在加入 亚马逊云科技 之前,他在亚马逊建立了数据仓库解决方案。他专门研究亚马逊 Redshift,帮助客户构建可扩展的分析解决方案。
Jason Pedreza
是 亚马逊云科技 的分析专家解决方案架构师,具有处理千兆字节数据的数据仓库经验。在加入 亚马逊云科技 之前,他在亚马逊建立了数据仓库解决方案。他专门研究亚马逊 Redshift,帮助客户构建可扩展的分析解决方案。
 Nita Shah
是总部位于纽约的 亚马逊云科技 的分析专家解决方案架构师。她构建数据仓库解决方案已有 20 多年,专门研究亚马逊 Redshift。她专注于帮助客户设计和构建架构良好的企业级分析和决策支持平台。
Nita Shah
是总部位于纽约的 亚马逊云科技 的分析专家解决方案架构师。她构建数据仓库解决方案已有 20 多年,专门研究亚马逊 Redshift。她专注于帮助客户设计和构建架构良好的企业级分析和决策支持平台。
 亚马逊云科技 的技术产品经理
Eren Baydemir
在开发面向客户的产品方面拥有 15 年的经验,目前在 Amazon Redshift 团队中专注于数据湖和文件摄取主题。他是DataRow的首席执行官兼联合创始人,该公司于2020年被亚马逊收购。
亚马逊云科技 的技术产品经理
Eren Baydemir
在开发面向客户的产品方面拥有 15 年的经验,目前在 Amazon Redshift 团队中专注于数据湖和文件摄取主题。他是DataRow的首席执行官兼联合创始人,该公司于2020年被亚马逊收购。
 Eesha Kumar
是 亚马逊云科技 的分析解决方案架构师。他与客户合作,帮助他们使用 亚马逊云科技 平台和工具构建解决方案,从而实现数据的商业价值。
Eesha Kumar
是 亚马逊云科技 的分析解决方案架构师。他与客户合作,帮助他们使用 亚马逊云科技 平台和工具构建解决方案,从而实现数据的商业价值。
 萨@@
蒂什·萨蒂亚
是亚马逊 Redshift 的高级产品工程师。他是一位狂热的大数据爱好者,他与全球客户合作以取得成功并满足他们的数据仓库和数据湖架构需求。
萨@@
蒂什·萨蒂亚
是亚马逊 Redshift 的高级产品工程师。他是一位狂热的大数据爱好者,他与全球客户合作以取得成功并满足他们的数据仓库和数据湖架构需求。

*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。