我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊云科技和 Coiled 扩展算法交易的回溯测试
回测在算法交易中起着至关重要的作用。企业利用 XGBoost 进行回溯测试来建立预测模型,根据历史数据预测市场走势。但是,训练 XGBoost 模型的计算成本很高,而且很快就会成为瓶颈,尤其是在处理大型历史数据集时。
这篇博客文章展示了量化交易公司如何使用 Dask 分发 XGBoost 模型训练,以及如何使用 Coiled 在亚马逊云科技上在数百个 Amazon Elastic Compute Cloud(EC2)实例上扩展计算。公司使用 Coiled 和亚马逊云科技来增加回测吞吐量,因此研究人员专注于制定和测试交易策略,而不是管理云基础设施。
背景
量化交易公司开发算法模型以生成财务见解并高效执行交易。回测包括根据历史数据运行交易策略以评估表现,然后再将其部署到实时市场。这需要大量的模型训练和模拟,因此高效的计算必不可少。
企业依赖 XGBoost,这是一个开源梯度提升库,广泛用于股票价格预测、投资组合优化和财务风险评估。XGBoost 高度准确、可扩展,能够处理复杂的功能交互。
这些公司中有许多采用了传统市场数据之外的替代数据来源,例如宏观经济指标、人口趋势和社会影响指标,以提高预测准确性。处理这些多样化的大型数据集时会出现挑战,这些数据集通常达到 TB 级,需要强大的计算基础设施来进行快速的模型训练。
但是,在太字节大小的数据集上训练模型存在挑战。这些计算需要高内存和处理能力,企业发现其现有基础设施不足以满足竞争性交易策略所需的速度和规模。
使用 XGBoost、Dask 和 Coiled 在亚马逊云科技上进行回溯测试的分布式模型训练
为了克服这些挑战,量化交易公司采用了结合 XGBoost、Dask 和 Coiled 的分布式工作流程,为回测和模型训练提供了 Python 原生的可扩展解决方案。以下各节介绍如何将这些工具组合在一起,对大型数据集进行财务模拟。
使用 XGBoost 进行预测建模
Python 是量化金融的主导语言,因为其强大的数据科学库生态系统,包括 XGBoost。XGBoost 的效率来自于以迭代方式构建决策树,每棵新树都会完善前一棵树的预测。与 Dask 集成后,计算可以分布在多个节点上,从而提高速度和可扩展性。
使用 Dask 进行分布式模型训练
Dask 将数据分成小块,并行训练独立模型,然后在下一次训练迭代之前汇总所有机器上的结果。这使企业能够以单节点计算所需时间的一小部分时间进行大规模回测。
以下是如何在 Dask 集群上使用 XGBoost 在单台计算机上本地运行模型训练和推理的示例:
使用 Coiled 在亚马逊云科技上进行大规模回测
随着数据集大小的增长,即使是使用 Dask 的单机设置也达到了极限。财务模型需要更多的内存和计算能力,因此可扩展的云基础设施必不可少。借助面向 Python 开发人员的计算平台 Coiled,量化交易公司只需几行代码即可在亚马逊云科技上扩展 EC2 实例。Coiled 管理亚马逊云科技基础设施,因此量化人员专注于评估交易策略,而不是监控 EC2 实例。以下架构图(图 1)显示了 Coiled 如何位于用户的本地环境和亚马逊云科技云环境之间。
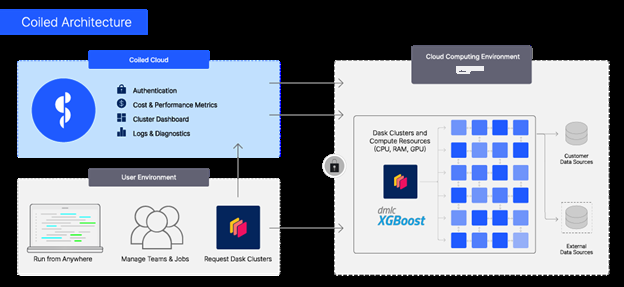 图 1 — Coiled 允许用户从本地环境中访问亚马逊云科技的计算规模。
图 1 — Coiled 允许用户从本地环境中访问亚马逊云科技的计算规模。
替换上面代码片段中的 LocalCluster,公司可以在数百个亚马逊云科技实例上分配工作负载:
深入了解 Coiled 基础设施,有一些功能可以帮助在亚马逊云科技上启动集群:
- 使用 n_workers 启动所需的 EC2 实例。
- 在任何亚马逊云科技区域进行部署,以优化该区域的数据访问权限。
- 利用 spot_with_fallback,利用打折的亚马逊 EC2 竞价型实例节省成本。
- 使用包同步功能自动将本地 Python 包复制到远程集群。你不必担心创建 Docker 镜像。
- 将本地亚马逊云科技凭证安全地转发到远程集群,这样您就可以轻松访问 Amazon S3 等亚马逊云科技资源。
定量分析师通常在内存中从数百千兆字节到数十 TB 的数据集上训练模型。
集群硬件指标
在本节中,我们将介绍 Coiled 仪表板中提供的典型模型训练工作流程的硬件指标。
在此示例中,客户正在使用 300 个 EC2 m6i.xlarge 实例运行回测工作流程,该工作流程花了大约 6 分钟。m6i.xlarge 实例在内存和计算之间取得了良好的平衡,具有 16 GiB 的内存和 4 个 vCPU。他们的团队将并行运行其中许多模型训练工作负载,一次最多 20 个,这极大地提高了回测吞吐量。
使用 XGBoost 进行模型训练依赖于 Dask 工作人员之间的大量通信,因为他们在集群中共享中间模型训练输出。在计算生命周期内,工作人员发送和接收了 21.4 TB 的数据(图 2)。在计算过程中,数据传输速率达到 188 Gb/s(图 3)。
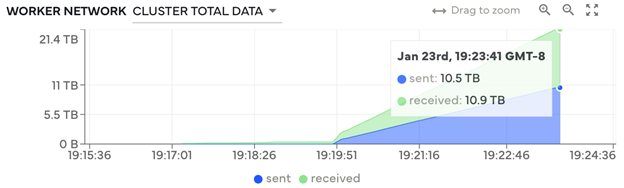 图 2 — 计算期间发送和接收的累积数据。XGBoost 模型训练需要员工之间的沟通,以便工作人员共享中间结果。在计算过程中,亚马逊云科技 EC2 上的 Dask 可以协调 21 TB 的数据。
图 2 — 计算期间发送和接收的累积数据。XGBoost 模型训练需要员工之间的沟通,以便工作人员共享中间结果。在计算过程中,亚马逊云科技 EC2 上的 Dask 可以协调 21 TB 的数据。
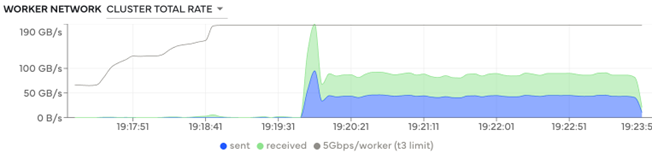 图 3 — 整个集群的数据传输速率达到 188 GB/s。
图 3 — 整个集群的数据传输速率达到 188 GB/s。
工作人员使用 Amazon Elastic Block Store(EBS)将中间结果写入磁盘,计算期间存储在磁盘上的总数据达到 1.09 TB(图 4)。
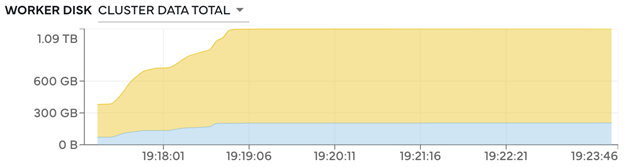 图 4 — 典型模型训练工作负载过程中存储到磁盘的累积群集数据。Coiled 集群磁盘上存储的数据总量达到 1.09 TB。
图 4 — 典型模型训练工作负载过程中存储到磁盘的累积群集数据。Coiled 集群磁盘上存储的数据总量达到 1.09 TB。
为了降低云成本,用户通常会利用竞价型实例。在此工作流程中,大约三分之一的实例是竞价型实例(图 5)。
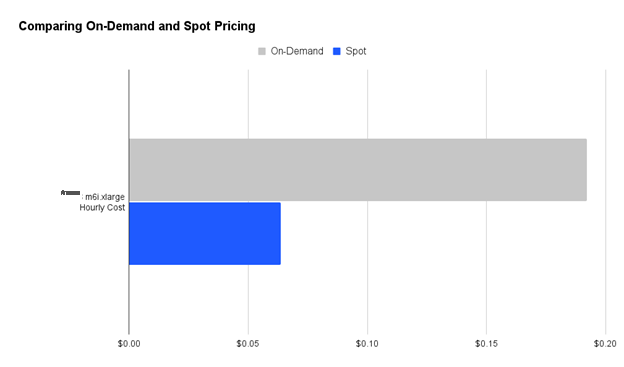
图 5 — m6i.xlarge 亚马逊云科技 EC2 实例的按需定价与现货定价。与按需实例相比,竞价型实例通常便宜 2-3 倍。
如果这些实例不可用,Coiled 将自动将其替换为按需实例,以便工作负载不受干扰地运行。
计算完成后,集群将自动关闭,以避免不必要的计算成本。
结论
通过整合 XGBoost、Dask 和 Coiled,量化交易公司可以有效地扩展其回测工作流程,以处理太字节级的数据集。这些工具的组合增强了预测建模,将训练时间从几天缩短到几分钟,并降低了云成本。
Coiled 的自动云扩展使公司能够专注于完善交易策略,而不是基础设施管理。借助简单的 Python 环境同步、竞价型实例支持和灵活的亚马逊云科技部署,企业可以加快团队发展并轻松扩展计算规模。
这种可扩展的方法使公司能够增强其算法交易策略,整合越来越复杂的数据集,并在不牺牲性能的情况下进行大量的回测。要详细了解如何将此解决方案复制到您的用例中,请查看 Amazon Marketplace 上的 Coiled。

Alket Memushaj
Alket Memushaj 在亚马逊云科技金融服务市场开发团队担任首席架构师。Alket 负责资本市场的技术战略,与合作伙伴和客户合作,在整个交易生命周期中将应用程序部署到亚马逊云科技云中,包括市场连接、交易系统以及交易前和交易后的分析和研究平台。

Sarah Johnson
莎拉·约翰逊是 Coiled 的产品营销经理,她帮助数据团队在云端扩展 Python 工作流程。凭借人口健康研究背景和数据从业者的实践经验,她了解大规模使用数据所面临的现实挑战。

Simon Panek
西蒙·帕内克是亚马逊云科技的合作伙伴解决方案架构师。他专注于涉及物联网 (IoT) 的解决方案,支持亚马逊云科技合作伙伴构建新的可扩展解决方案,以更好地为多个行业的客户提供服务。凭借制造、工程和工商管理经验,他一直在寻找新颖的解决方案。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。