我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用带有动态 SQS 目标的目标跟踪扩展 ASG
这篇博客文章由 亚马逊云科技 WWCO ProServe 高级云应用程序架构师 Wassim Benhallam 和 EC2 灵活计算高级专家解决方案架构师 Rajesh Kesaraju 撰写。
基于
这篇文章 以
挑战
这篇文章解决的主要挑战是,在 MPD 随时间推移而变化的情况下,应用程序无法兑现其可接受/目标延迟。这里的延迟是指消耗和完全处理任何队列消息所需的时间。
举一个例子,客户使用工作人员层处理用户在 100 秒的目标延迟内上传的图像文件(例如调整大小、调整大小或转换)。工作线程层由配置有目标跟踪策略的 Auto Scaling 组组成。为了实现前面提到的目标延迟,客户假设每张图像可以在一秒钟内处理完毕,并配置扩展策略的目标值,使每个实例的平均图像积压量保持在大约 100 张图像。
在第一周,客户向 Amazon SQS 队列提交 1000 张图像进行处理,每张图片需要一秒钟的处理时间。因此,Auto Scaling 组可扩展到 10 个实例,每个实例在 100 秒内处理 100 张图像,从而实现 100 秒的目标延迟。
在第二周,买家提交了 1000 张 稍大的图片进行处理。由于图像的处理持续时间随其大小而变化,因此每张图像需要两秒钟才能处理。与第一周一样,Auto Scaling 组扩展到 10 个实例,但这次每个实例在 200 秒内处理 100 张图像,这是第一轮所需的两倍。因此,应用程序无法在其可接受的延迟内处理后一幅图像。
因此,在任何延迟敏感型应用程序中,MPD 可能会发生变化,挑战都很常见。处理持续时间随输入数据大小而变化的应用程序特别容易受到此问题的影响。这包括图像处理、文档处理、计算作业等。
解决方案概述
在深入研究解决方案之前,让我们简要回顾一下目标跟踪策略的扩展指标及其相应的目标值。目标跟踪扩展策略的工作原理是调整容量,使扩展指标保持在或接近指定的目标值。在响应 Amazon SQS 待办事项列表时,

考虑到可接受的 BPI 方程,如果我们要以相同的可接受延迟处理这些消息,则较长的 MPD 要求我们使用较小的目标值,反之亦然。因此,我们在此处提出的解决方案的工作原理是监控一段时间内的平均 MPD,并根据观察到的 MPD 变化动态调整 Auto Scaling 组的目标跟踪策略(可接受的 BPI)的目标值。这使扩展策略能够适应平均 MPD 随时间推移的变化,从而使应用程序能够遵守其可接受的延迟。
解决方案架构
为了演示如何在实践中实现上述方法,我们整理了一个示例架构,重点介绍了所涉及的服务(见下图)。我们还使用 亚马逊云科技
Amazon SQS 队列用于累积用于处理的消息,而 Auto Scaling 组实例负责轮询队列并处理收到的所有消息。为此,启动模板定义了一个引导脚本,该脚本允许群组的实例在首次启动时下载并执行 Python 代码。Python 代码使用来自 Amazon SQS 队列的消息,并通过在消息正文中指定的 MPD 持续时间内休眠来模拟消息的处理。处理完每条消息后,该实例将 MPD 作为
![]()
图 1:架构图显示 亚马逊云科技 SAM 模板部署的组件。
为了启用扩展,Auto Scaling 组配置了目标跟踪扩展策略,该策略将 BPI 指定为扩展指标,并使用用户提供的初始目标值。
另一方面,扩展策略的目标值由 “目标设置器” Lambda 函数更新,该函数每 30 分钟使用另一个 EventBridge 速率表达式调用一次。要计算新的目标值,Lambda 函数只需取用户定义的可接受延迟值与从相应的 CloudWatch 指标中查询的当前平均 MPD 的比率,如前面的等式 (1) 所示。
最后,为了帮助您快速测试此解决方案,还提供了 “测试 Lambda” 的 Lambda 函数,可用于将消息发送到 Amazon SQS 队列,处理时长由您选择。这是在每条消息的正文中指定的。您可以使用不同的 MPD 调用此 Lambda 函数(通过修改相应的环境变量),以验证 Auto Scaling 组如何响应扩展。还部署了 CloudWatch 控制面板,使您能够随时跟踪关键扩展指标。其中包括队列中可见的消息数量、Auto Scaling 组中在役实例的数量、MPD 和 BPI 与可接受的 BPI 的对比。
解决方案测试
为了演示实际解决方案及其对应用程序延迟的影响,我们进行了两项测试,您可以按照存储库自述文件(存储
测试 1 和测试 2 的比较
由于测试 2 消息的处理时间是测试 2 的两倍,因此 Auto Scaling 组启动的实例数是测试 1(延迟)的两倍,尝试处理所有消息。下图显示,在测试 1 中处理所有 50 条消息的总时间为 9 分钟,而测试 2 中处理的总时间为 10 分钟。相比之下,如果我们使用静态/固定可接受的 BPI 为 12,则在测试 2 中总共有四个实例可以运行,因此处理所有消息所需的时间是测试 1 的两倍(约 20 分钟)。这证明了在处理来自 Amazon SQS 队列的消息时使用动态扩展目标的价值,尤其是在 MPD 容易随时间推移而变化的情况下。
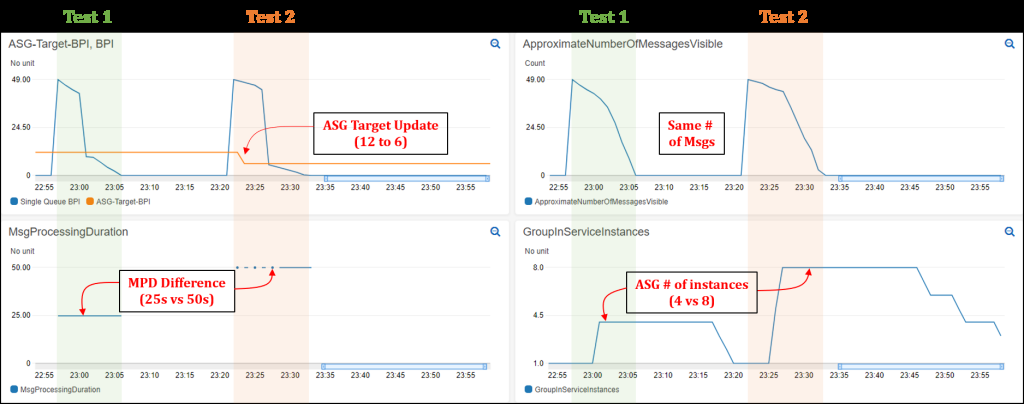
图 2:显示自动扩展组扩展测试结果的 CloudWatch 控制面板(测试 1 和 2)。
Auto Scaling 群组的推荐最佳实践
本节重点介绍我们在部署和使用 Auto Scaling 群组时建议采用的一些关键最佳实践。
使用 EC2 竞价型实例降低成本
Amazon SQS 有助于构建松散耦合的应用程序架构,同时在应用程序的各个层/组件之间提供可靠的异步通信。如果工作节点未能在 Amazon SQS 消息可见性超时内处理消息,则该消息将返回到队列,另一个工作节点可以接收并处理该消息。这使得 Amazon SQS 支持的应用程序在设计上具有容错能力,因此非常适合 EC2 竞价型实例。EC2 竞价型实例是 亚马逊云科技 云中的备用计算容量,与按需价格相比,您可以享受大幅折扣。
使用基于属性的实例选择最大化容量
使用最近发布的
以下示例配置创建了一个具有基于属性的实例选择的 Auto Scaling 组:
AutoScalingGroupName: 'my-asg' # [REQUIRED]
MixedInstancesPolicy:
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: 'lt-0537239d9aef10a77'
Overrides:
- InstanceRequirements:
VCpuCount: # [REQUIRED]
Min: 2
Max: 4
MemoryMiB: # [REQUIRED]
Min: 2048
InstancesDistribution:
SpotAllocationStrategy: 'capacity-optimized'
MinSize: 0 # [REQUIRED]
MaxSize: 100 # [REQUIRED]
DesiredCapacity: 4
VPCZoneIdentifier: 'subnet-e76a128a,subnet-e66a128b,subnet-e16a128c'
结论
从测试结果中可以看出,这种方法演示了 Auto Scaling 组如何遵守用户提供的可接受的延迟限制,同时适应 MPD 随时间推移而发生的变化。这是可能的,因为平均 MPD 会被监控并作为 CloudWatch 指标定期更新。反过来,它会持续用于更新群组目标跟踪策略的目标值。此外,我们还介绍了适用于该用例的其他Auto Scaling组最佳实践,包括使用竞价型实例来降低成本,以及使用基于属性的实例选择来简化相关实例类型的选择。
有关自动扩展组扩展选项的更多信息,请访问
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。