我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 SageMaker 对数千个机器学习模型进行大规模训练和推断
随着机器学习 (ML) 在各行各业中变得越来越普遍,各组织发现需要训练和提供大量机器学习模型以满足客户的不同需求。特别是对于软件即服务 (SaaS) 提供商而言,高效且经济地训练和服务数千种模型的能力对于在快速变化的市场中保持竞争力至关重要。
训练和服务数千个模型需要强大且可扩展的基础架构,而这正是
在这篇文章中,我们将探讨如何使用 SageMaker 功能,包括
用例:能源预测
在这篇文章中,我们扮演一家独立软件供应商公司的角色,通过跟踪他们的能源消耗和提供预测来帮助他们的客户变得更具可持续性。我们公司有 1,000 名客户,他们希望更好地了解自己的能源使用情况,并就如何减少对环境的影响做出明智的决定。为此,我们使用合成数据集并基于P
生成的数据集中有三个特征:
- customer_id — 这是每个客户的整数标识符,范围从 0 到 999。
- 时间戳 — 这是一个日期/时间值,表示测量能耗的时间。时间戳是在代码中指定的开始日期和结束日期之间随机生成的。
- 消耗 — 这是一个浮动值,表示能耗,以任意单位计量。消费值在 0—1,000 之间随机生成,具有正弦曲线的季节性。
解决方案概述
为了高效地训练和服务数千个 ML 模型,我们可以使用以下 SageMaker 功能:
-
SageMaker 处理 — SageMaker 处理是一项完全托管的数据准备服务,使您能够对输入数据执行数据处理和模型评估任务。您可以使用 SageMaker Processing 将原始数据转换为训练和推理所需的格式,也可以对模型进行批量和在线评估。 -
SageMaker 训练作业 -您可以使用 SageMaker 训练作业根据各种算法和输入数据类型训练模型,并指定训练所需的计算资源。 -
SageMaker MME — 多模型端点使您能够在单个端点上托管多个模型,从而使用单个 API 轻松提供来自多个模型的预测。SageMaker MME 可以通过减少提供来自多个模型的预测所需的端点数量来节省时间和资源。MME 支持托管支持 CPU 和 GPU 的模型。请注意,在我们的场景中,我们使用了 1,000 个模型,但这不是服务本身的限制。
下图说明了解决方案架构。
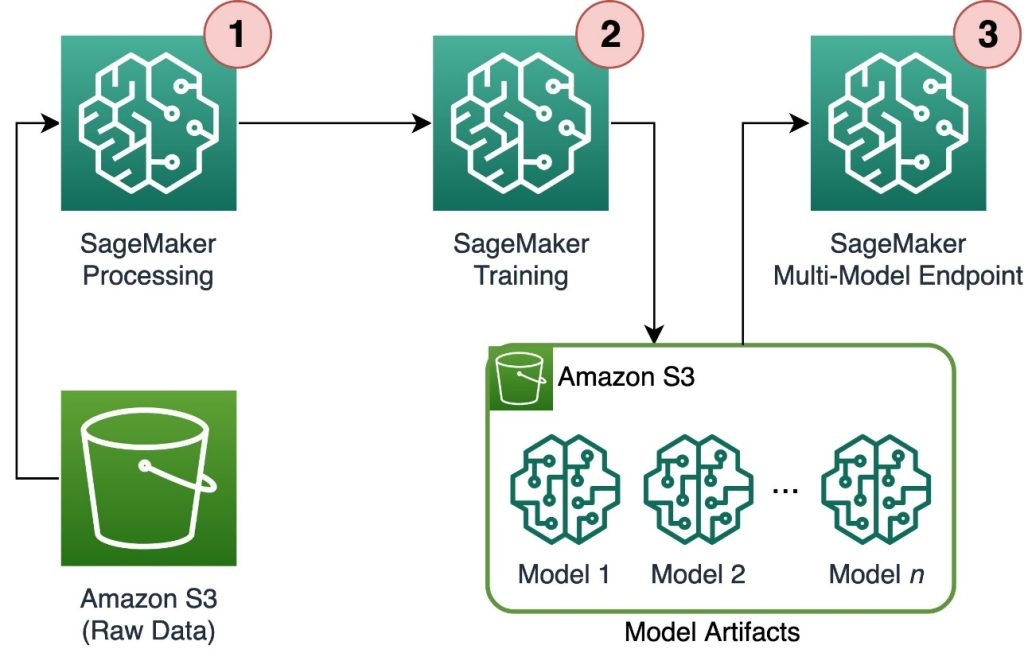
工作流程包括以下步骤:
-
我们使用 SageMaker Processing 来预处理数据,为每个客户创建一个单个 CSV 文件,并将其存储在
亚马逊简单存储服务 (Amazon S3)中。 -
SageMaker 训练作业配置为读取 SageMaker 处理作业的输出并以循环方式将其分发给训练实例。请注意,这也可以通过
亚马逊 SageMaker Pipelines 来实现。 - 模型工件由训练任务存储在 Amazon S3 中,并直接由 SageMaker MME 提供服务。
将训练扩展到数千个模型
通过 SageMaker Python SDK 中 T
分布
参数,可以扩展成千上万个模型的训练,该参数允许您为训练作业指定数据的分布方式。
分布
参数有三个选项:
sh
完全复制 、shardedbys3Key 和 sh
Record。
ardedB
y
ardedBys3Key
选项意味着训练数据由 S3 对象密钥分片,每个训练实例都会收到唯一的数据子集,从而避免重复。在 SageMaker 将数据复制到训练容器后,我们可以读取文件夹和文件结构,从而为每个客户文件训练一个唯一的模型。以下是示例代码片段:
每个 SageMaker 训练作业都会存储保存在训练容器的
/opt/ml/model 文件夹中的模型
,然后将其存档到
model.tar.gz
文件中,然后在训练任务完成后将其上传到 Amazon S3。高级用户还可以使用 SageMaker Pipelines 自动执行此过程。通过同一个训练作业存储多个模型时,SageMaker 会创建一个包含所有训练模型
的 model.tar.gz
文件。这意味着,为了为模型提供服务,我们需要先解压缩存档。为了避免这种情况,我们使用
/
checkpoints。这些检查点可用于稍后恢复训练,也可以用作在端点上部署的模型。有关 SageMaker 训练平台如何管理训练数据集、模型构件、检查点以及 亚马逊云科技 云存储和 SageMaker 中训练作业之间输出的存储路径的高级摘要,请参阅训练数据
以下代码在包含训练逻辑的
train.py
脚本中使用虚构的
model.save ()
函数:
使用 SageMaker MME 将推理扩展到数千个模型
SageMaker MME 允许您同时提供多个模型,方法是创建一个端点配置,其中包括要提供的所有模型的列表,然后使用该端点配置创建端点。无需每次添加新模型时都重新部署终端节点,因为该端点将自动为指定 S3 路径中存储的所有模型提供服务。这是通过
以下代码片段显示了如何使用 SageMaker Python SDK 创建 MME:
当 MME 上线时,我们可以调用它来生成预测。调用可以在任何 亚马逊云科技 开发工具包中完成,也可以使用 SageMaker Python 开发工具包完成,如以下代码片段所示:
调用模型时,模型最初从 Amazon S3 加载到实例上,这可能会导致调用新模型时出现冷启动。常用模型缓存在内存和磁盘中,以提供低延迟推断。
结论
SageMaker 是一个强大且经济实惠的平台,用于训练和服务数千个 ML 模型。其功能,包括 SageMaker 处理、训练任务和 MME,使组织能够高效地大规模训练和提供数千个模型,同时还受益于使用 亚马逊云科技 云基础设施所带来的节省成本的优势。要了解有关如何使用 SageMaker 训练和提供数千个模型的更多信息,请参阅
作者简介
 Davide Gallitelli 是欧洲
、中东和非洲地区的人工智能/机器学习专业解决方案架构师。他常驻布鲁塞尔,与比荷卢经济联盟各地的客户紧密合作。他从很小的时候就是一名开发人员,7岁开始编程。他在大学开始学习人工智能/机器学习,从那以后就爱上了它。
Davide Gallitelli 是欧洲
、中东和非洲地区的人工智能/机器学习专业解决方案架构师。他常驻布鲁塞尔,与比荷卢经济联盟各地的客户紧密合作。他从很小的时候就是一名开发人员,7岁开始编程。他在大学开始学习人工智能/机器学习,从那以后就爱上了它。
 Maurits de Groot
是总部位于阿姆斯特丹的亚马逊网络服务的解决方案架构师。他喜欢研究与机器学习相关的话题,并且偏爱初创公司。在业余时间,他喜欢滑雪和打壁球。
Maurits de Groot
是总部位于阿姆斯特丹的亚马逊网络服务的解决方案架构师。他喜欢研究与机器学习相关的话题,并且偏爱初创公司。在业余时间,他喜欢滑雪和打壁球。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。