我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
在亚马逊 EKS 上从 100 个容器扩展到 10,000 个
这篇文章由 OLX Autos 的 Nikhil Sharma 和 Ravishen Jain 共同撰写
简介
在 OLX Autos,我们在本土内部开发者平台 (IDP) ORION 上并行运行 100 多个非生产(非生产)环境,用于不同的用例。ORION 在亚马逊
在这篇文章中,我们将向您展示我们如何将适用于 ORION 的主机 Amazon EKS 集群从 100 个扩展到 10,000 多个容器。
关于 OLX Autos
OLX Autos IDP — 猎户座
我们的技术团队已经建立了一个名为ROADSTER的平台,该平台上有多种业务流,例如汽车交易、融资和分类广告。考虑到汽车市场不断变化、竞争激烈的性质,该平台背后的关键原则是超快的速度、模块化、弹性以及对尖端技术的关注。Roadster 托管在亚马逊 EKS 上。
随着我们的扩展,新功能的快速交付仍然是一项关键挑战。降低工程师的复杂性并提高他们的效率是我们关注的主要目标之一。我们的工程师必须为不同的用例创建多个非产品 Roadster 环境。用例范围从展示实验性功能演示、运行自动化测试用例到在新市场推出Roadster不等。Roadster 环境需要多个微服务和数据库,它们在业务用例中相互交互。
创建和维护环境既消耗时间又消耗资源。我们通过构建内部开发者平台(IDP)(ORION)来应对这一挑战,该平台提供了一个中央平台来解决创建新的Roadster环境的问题。
解决方案概述
下图显示了 ORION 的架构:
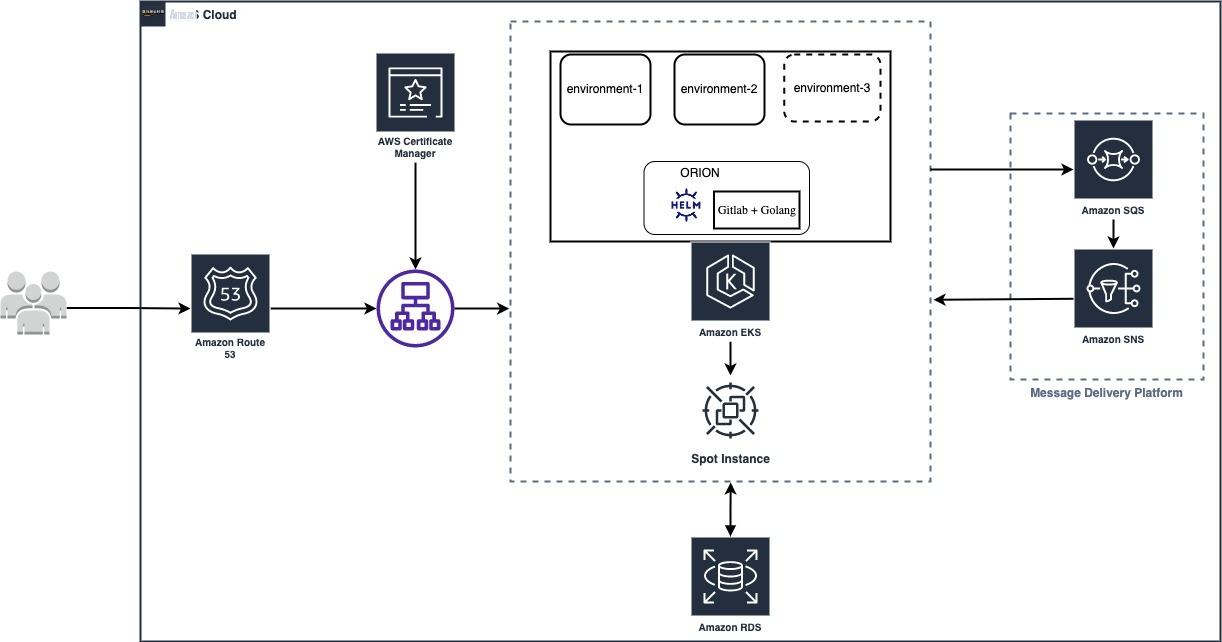
猎户座的目标是:
- 通过提供服务、工具、文档和见解的无缝集成,降低复杂性并专注于卓越的开发者体验。
- 让开发人员能够以最少的点击量创建 Roadster 平台,从而消除对其他团队的依赖。
ORION的关键功能之一是只需点击几下即可提供Roadster环境。
使用亚马逊 EKS for IDP
Roadster 已完全集装箱化,并且已经在亚马逊 EKS 上运行了多年。对于 ORION 来说,亚马逊 EKS 是一个显而易见的选择。ORION 支持创建新的敞篷跑车环境。使用 ORION,我们在单个 Amazon EKS 集群上支持 100 多个并发环境。
下图显示了亚马逊 EKS 集群上 ORION 控制的规模:

扩展挑战和解决方案概览
随着我们团队中采用ORION的增加,它带来了许多有趣的扩展挑战。
DNS 解析延迟高
经典 ndots 挑战赛
亚马逊 EKS 中的默认 ndot 值为 5。根据 DNS 标准,如果域名的点数 (.) 等于 ndot 值或末尾有点 (.),则该域名被视为完全限定域名 (FQDN)。在对不是 FQDN 的域名进行 DNS 查询时,core-dns 会遍历所有搜索路径,直到找到成功为止。
如果你从 pod 中查询 amazon.com,那么 core-dns 会查询:
[amazon.com.default.svc.cluster.local,
amazon.com.svc.cluster.local,
amazon.com.cluster.local,
亚马逊。]
按此顺序,直到成功。
我们从亚马逊 EKS 集群 上的一个节点在亚马逊上执行了 nslookup ,结果出现了 7 个 DNS 问题(5 个虚假的 DNS 查询、1 个 ipv4、1ipv6 DNS 查询)。
以下屏幕截图显示了亚马逊上的 nslookup 命令的输出。grep 问题的数量显示 DNS 查询的数量,grep NXDOMAIN 的计数显示由于虚假 DNS 查询而导致的错误数量:
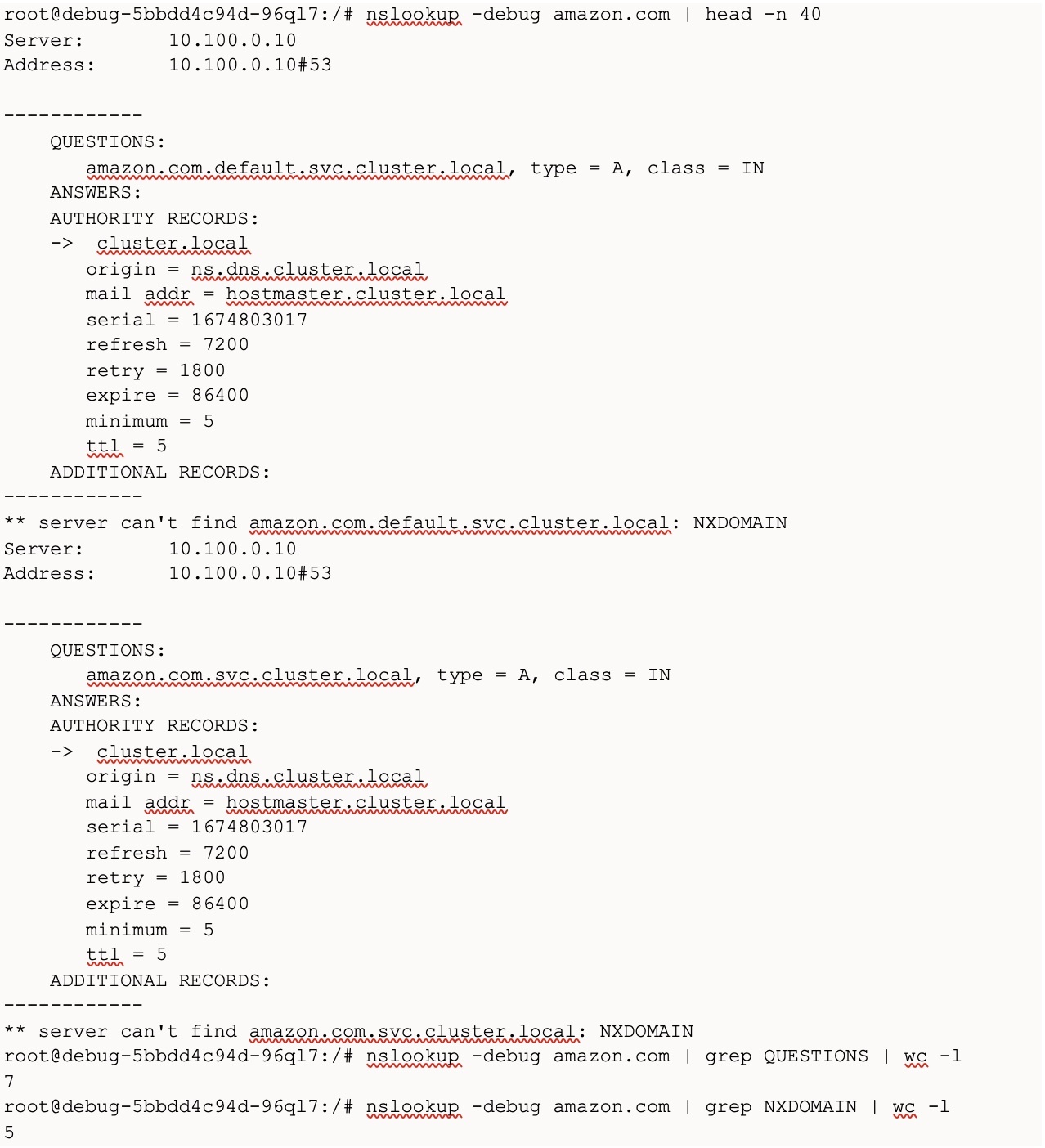
随着 OLX Autos 规模的扩大,来自服务间通信的网络呼叫增加了许多倍。这导致了大量 DNS 查询。ndot 值为 5 使问题恶化了 5 次,导致核心 dns 崩溃,从而频繁出现 DNS 解析错误。这
由于 CPU 节流,响应时间长
最初,我们对 pod 设置
通过在末尾添加一个点来解析
在 DNS 名称中添加一个点使其成为 FQDN,解析器无需遍历搜索路径。这减少了 DNS 调用的数量。
我们在 “亚马逊” 上执行了 nslookup。(即,在末尾添加一个点)。这将 DNS 问题从 7 个减少到 2 个,其中 NXDOMAIN 错误为 0。这减少了我们的core-dns服务器上的70%以上的查询,并提高了性能。
以下屏幕截图显示了上述更改后在 “amazon.com。” 上的 nslookup 命令的输出:

我们正在调用的 http 调用端点是通过环境变量配置的。我们在环境变量中这些 HTTP 端点的末尾添加了一个点。
DNS 缓存可进一步改进
上述更改大大减少了 core-dns 服务器上的 DNS 查询;但是,随着 OLX Autos 的扩展,我们仍然运行了大量 DNS 查询,从而导致了更高的延迟。我们推出了由 K8s 社区 支持的
下图显示了带有 DNS 缓存和不使用 DNS 缓存的应用程序响应时间:

IP 饥饿和 VPC CNI 插件
IP 的数量取决于节点的实例类型。有关每个网络每种接口类型的 IP 地址的详细列表,请参阅此
这意味着,对于每个类型为 c5.9xlarge 的节点,它会从 VPC 池中保留 58 个 IP(即每个 ENI 上有 29 个),即使该工作节点上没有运行 Pod。
默认配置导致我们的 VPC 中的 IP 不足,并导致无法向 Amazon EKS 集群添加更多节点。它还导致未能在VPC中启动新的亚马逊云科技资源,例如亚马逊
VPC CNI 插件的默认行为可以通过以下参数来配置,这些参数控制每个节点分配的 IP 数量:
- MINIMUM_IP_TARGET 是在每个节点上分配的最少 IP 数。
- WARM_IP_TARGET 是 每个节点 上未使用 IP 的最大数量。
- WARM_ENI_TARGET 控制连接到实例的弹性网络接口 (ENI) 的数量。
WARM_IP_TARGET 配置可最大程度地减少未使用的 IP
最初,我们非常激进,配置了 WARM_IP_TARGET= 1,这将只保留一个 IP。
当我们在集群上执行以下命令时,输出显示了该节点上所有可用和分配的 IP:
下图显示了该命令的结果:
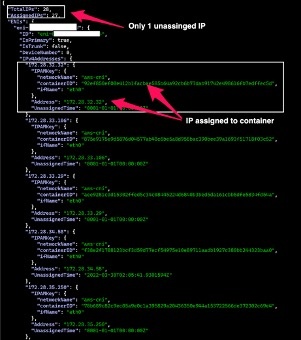
该配置解决了 IP 不足的问题;但是,它导致了另一个问题。由于只保留了一个额外的 IP 地址(即 WARM_IP_TARGET=1 ),因此 每当调度多个 Pod 时, 都需要分配多个 IP,这会触发 IP 分配的争用条件。Pod 必须等待 VPC CNI 插件为工作节点分配更多 IP。在此期间,我们看到了诸如— 无法为容器分配 IP 地址 以及 DataStore 没有可用的 IP 地址 之类的错误。
下图显示了工作节点上来自 /var/log/aws-routed-eni/ipamd.log 的日志:
用于优化 IP 预分配的 MINIMUM_IP_TARGET 配置
为了修复这个问题,我们将 MINIM UM_IP_TA RGET 设置为每个节点上 预期的 pod 数量。设置此数字时,应同时考虑您的工作负载以及集群中运行的多个守护程序集。设置 WARM_IP_TARGET= 1 和 M INIM UM_IP_TARGET= [预期的吊舱数量] 修复了 IP 匮乏问题 。
使用 100% Spot 时会遇到挑战
托管 ORION 的亚马逊 EKS 集群在
现货不可用
我们必须确保在竞价型实例不可用的情况下,业务不会中断。尽管 ORION 适用于非产品用例,但我们承受不起中断的代价。我们使用了不同的 CPU、内存配置相似的实例类型(例如,m5.2xlarge、m5a.2xlarge、m5d.2xlarge、m5ad.2xlarge 和 m4.2xlarge)。除此之外,如果竞价容量不可用,我们还使用优先级扩展器和集群自动扩展器来回退按需容量。
我们使用了以下 Kubernetes 配置:
为了采用这种方法,我们为竞价和按需实例创建了节点组。我们决定采用命名惯例,即名称包含 Spot 的节点组具有竞价型实例,而名称包含按需的节点组具有按需实例。使用命名模式为每个节点组配置了优先级,如前面的示例所示。我们将 Spot 节点组设置为高度优先级。它确保集群自动扩缩器首先从 Spot 节点组启动节点。如果没有足够的竞价容量可用,则集群自动缩放器将回退到按需节点组。我们将集群自动扩缩器的超时时间(即最大节点配置时间)从默认的 15 分钟更改为 10 分钟。
我们计划探索
现场终止处理
我们正在使用自我管理的节点组。我们需要妥善处理亚马逊 EC2 的终止。我们使用
尽量减少容量浪费
我们使用的是多个节点组,每个节点组由提供大致相似容量的实例类型组成。我们创建了由 m5a.xlarge、m4.xlarge、m5.xlarge 和 m5d.xlarge 实例类型组成的 xlarge 节点组,因为每种类型都提供 4 个 vCPU 和 16Gib 内存。同样,我们为 9xLarge 实例类型创建了另一个 9xLarge。我们希望确保我们不会为较小的工作负载启动更大的实例。我们使用集群自动缩放
以下屏幕截图显示了集群自动缩放器的相关配置:
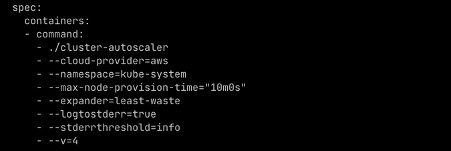
expander 的默认值为 随 机 ,它将集群自动扩缩器配置为随机启动来自任何节点组的节点。除此之外,我们还使用了 Cloudability 监控所有资源的成本,NewRelic 监控了所有工作负载的使用情况。我们使用这两个数据点来调整每个应用程序的资源大小。
处理高优先级工作负载
在我们的设置中,托管 ORION 的 Amazon EKS 集群还托管了我们的
我们通过使用 pod 优先级解决了这个问题。我们创建了具有非常 高优先级值的高优先级非抢占式 pod 优先级类,并将其分配给管道运行器 pod。这确保了管道 pod 始终可用,即使调度器必须驱逐一些其他容器来容纳它们。虽然我们通常使用浪费最少的容量扩展器,但如果实例容量不足,我们会改用优先级扩展器。
以下是用于创建 高 优先级非抢占式优先级类的 Kubernetes 配置:
以下是使用 高优先级非抢占优先级类 的 pod 配置 :
结论
在这篇文章中,我们向您展示了我们如何将适用于 ORION 的主机 Amazon EKS 集群从 100 个扩展到 10,000 多个容器。ORION使OLX Autos工程师能够专注于构建业务就绪功能,这些功能对于OLX Autos向新国家和新业务的扩张至关重要。由于创建新环境更容易,工程师不必彼此共享环境,这提高了敏捷性并解锁了效率。Amazon EKS 帮助 OLX 高效地管理资源,使用即时优先的方法降低了基础设施成本。
以下是我们从经验中学到的重要经验:
- 通过使用 FQDN(以点结尾的域名)和 DNS 缓存,我们将应用程序延迟从 3000 毫秒的峰值降低到 50 毫秒以内(提高了约 98%)。
- VPC CNI 插件的默认行为经过优化,可提高容器创建过程中的效率,因此会屏蔽大量 IP 地址。我们优化了配置以防止 IP 短缺。
-
竞价型实例的折扣高达90%,非常适合开发环境。我们使用优先级扩展器来获得可靠的容量,使用最低成本的扩展器来最大限度地减少浪费,并使用
aws-node-termination-handle(NTH)来实现节点的平稳终止 。这些功能使得 Spot 开发成为一个引人注目的选择。 - 我们使用优先级类来自定义 pod 调度,并确保 Amazon EKS 不会耗尽高优先级工作负载的容量。

Nikhil Sharma,OLX
Nikhil Sharma 是 OLX 的平台工程经理。在长达十多年的职业生涯中,他曾研究过多个领域的各种技术领域,涉及网络、DNS、TLS、容器、Kubernetes 和系统性能的问题无穷无尽。他是一位狂热的读者,热爱旅行,是一位诗人,也是一位健身爱好者。目前,他领导OLX的平台团队。

Ravishen Jain,OLX
Ravishen Jain 是 OLX 的平台工程师。他对容器化的迷恋激发了他在K8s原生技术方面的精湛技巧,他是一位经验丰富的全栈开发人员,也是设计和构建K8s原生可扩展应用程序领域的活跃开源贡献者。在他目前的职位上,他正在构建和管理 OLX Autos 内部开发者平台,即 ORION。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。